 ChatGPT的朋友們:大語言模型經典論文
ChatGPT的朋友們:大語言模型經典論文
要說2023刷屏最多的詞條,ChatGPT可以說是無出其右。到最近的GPT-4,技術的革新儼然已呈現破圈之勢,從學術圈到工業界再到資本圈,同時也真切逐步影響到普通人的日常生活與工作。
坦白來講,對于大語言模型生成相關的工作,個人長期以來持保守態度,認為這個方向更多的是一種深度學習的理想追求。現在看小丑竟是我自己,也許優秀的工作正是需要對理想狀態的持續追求,才叫優秀的工作。
言歸正傳,本系列打算跟風討論一下關于ChatGPT相關技術,主要內容分為三部分,也會分為三篇文章:
1、經典論文精讀 【this】:通過本文閱讀可以了解ChatGPT相關經典工作的大致思路以及各個時期的關鍵結論;
2、開源實現技術 【soon】:總結最近幾個月開源工作者們follow ChatGPT的主要方向和方法;
3、自然語言生成任務的前世今生和未來 【later】:大語言模型之外,談談自然語言生成的“傳統”研究方向與未來暢想。
因為相關技術發展迅速,三部分內容也會定期更新。本文主要為第一部分經典論文學習,而相關的工作眾多(如圖),一一閱讀并不現實,因此本文選擇持續性最高的OpenAI系列和Google系列,以及近期影響力比較大的LLaMA,最后是中文適配比較好的GLM和ChatGLM。
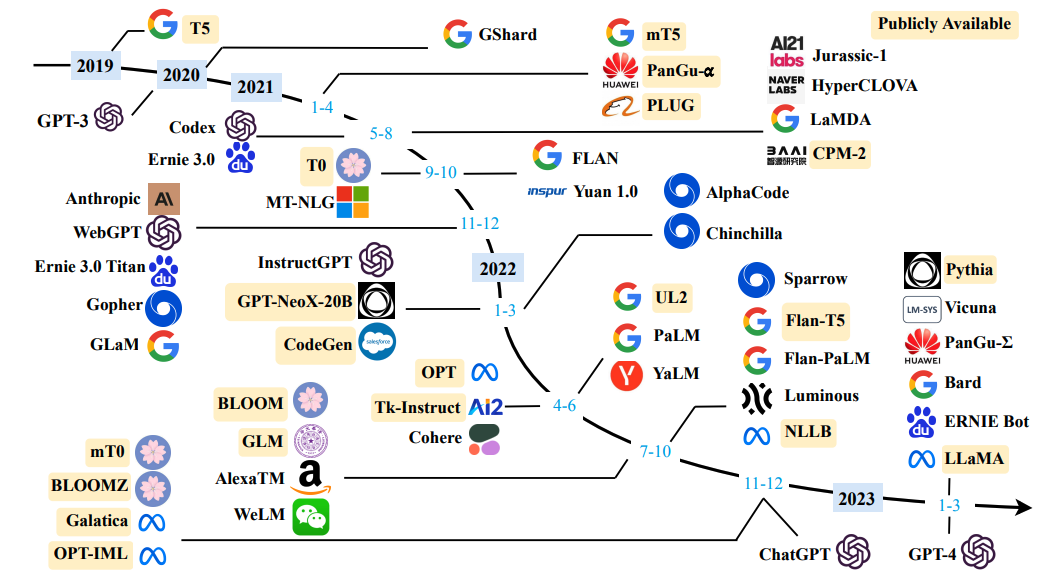
此外,本文閱讀需要一定的NLP基礎概念,比如知道什么是BERT和Transformer、什么是Encoder-Decoder架構、什么是預訓練和微調,什么是語言模型等。
OpenAI 系列
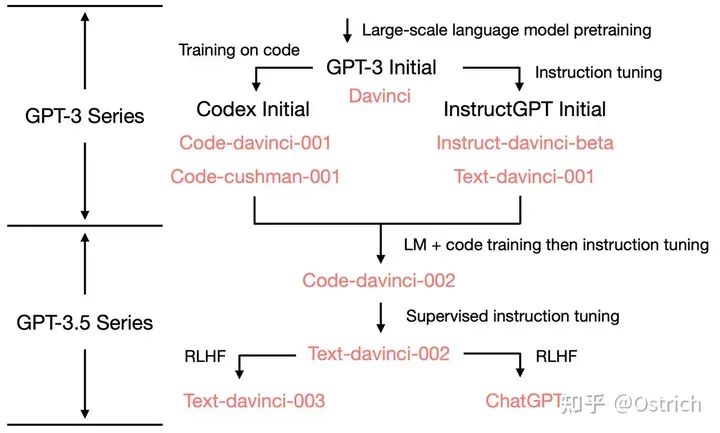
本節目標是通過OpenAI系列論文閱讀細窺ChatGPT的主要原理,其先進的工作脈絡可以概括為下圖。從依賴往上追溯需要了解Codex 和 instructGPT、再往上是GPT-3、繼而也需要了解GPT-2和GPT-1。(GPT-4暫時簡單地看作是Plus版本的GPT-3.5,而且增加了多模態數據的處理能力,等更多的細節公開后再作討論)
GPT-1
論文鏈接:《Improving Language Understanding by Generative Pre-Training》
動機
任務目標和BERT一致(但在BERT之前),希望通過大規模無標注數據進行預訓練,下游任務微調的方式解決經典NLP任務,緩解有監督任務數據收集成本高的問題。GPT-1雖然不是第一個使用預訓練-微調架構的工作,但也是使用Transformer-Decoder做相關任務的很早期工作了。
方案概述
-
模型結構:Transformer的Decoder部分
-
訓練方法:自回歸的生成方式進行語言模型預訓練,判別式的結構進行下游任務微調。
一些細節
-
預訓練:
-
Loss:經典的語言模型訓練目標,將無標注的樣本庫表示為token 序列集合 U = {u_1, ...., u_n},最大化下面的似然估計。即通過一段話的前面的token,預測下一個token,其中k為上下文窗口。
-
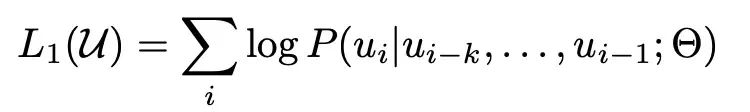
-
-
模型:使用多層Transformer decoder建模P,簡化的公式表達如下。W_e為token embedding矩陣,W_p為位置向量矩陣,通過多層transformer block,最后每個token通過transformer block成為編碼后的向量h_n,最后經過一個線性層+softmax,即為下一個token的預測分布。
-
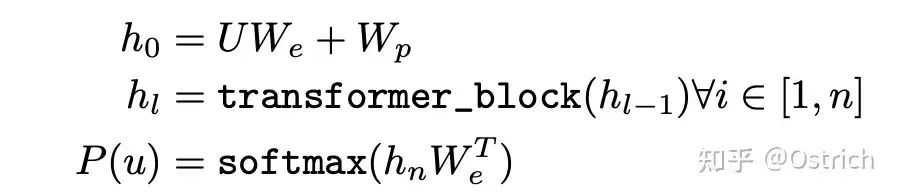
-
-
數據:早期數據并沒有非常夸張,GPT-1的主要數據有兩個:
-
BooksCorpus dataset:包括7000多本未發表的書籍;
-
1B Word Benchmark(可選)。
-
-
-
微調:
-
模型改動:通過增加特殊token作為輸入的開始[Start]和結束[Extract]等,以結束[Extract]的隱層輸出接入全連接層,并進行下游的分類和其他變種任務。如圖所示:
-
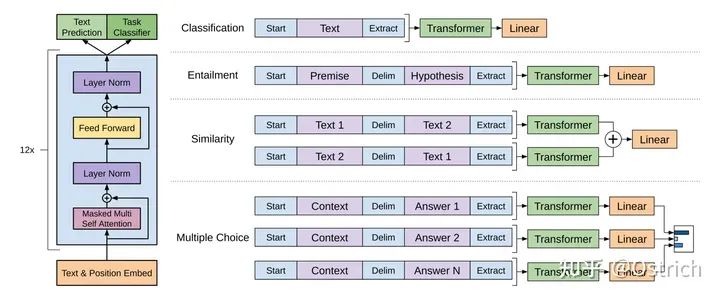
-
-
loss:
-
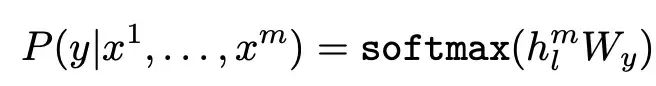
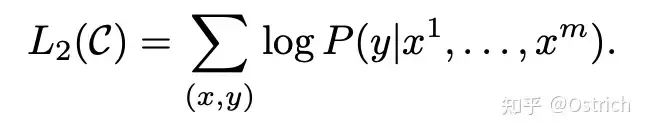
-
-
小細節:微調過程中,在下游任務目標基礎上,加入預訓練目標,效果更好。
-
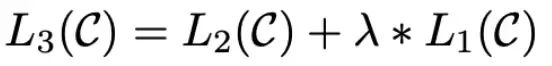
結果與討論
-
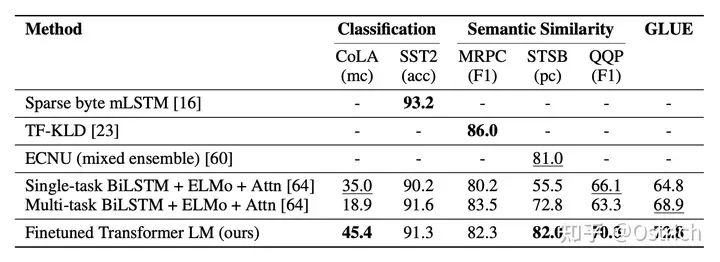
主要驗證方法:文章主要是通過下游任務的效果進行策略的有效性驗證,通過一些經典任務數據集。結論來看,在不少數據集上都還有著不錯的效果,以分類為主的數據集為例,如圖所示。可以看到,這時的對比項還沒有BERT的蹤影。
GPT-2
論文鏈接:《Language Models are Unsupervised Multitask Learners》
動機
GPT-1之后不久,BERT出現,刷榜各種任務。GPT-1嘗試增加模型大小,但在預訓練+微調的訓練框架下,仍打不過同參數大小的BERT;但研究還得繼續,嘗試換個打法,以Zero-Shot作為賣點,效果不錯。
方案概述
GPT-2實現Zero-Shot的方法在現在看來比較簡單:將所有的NLP任務統一看作是p(output|input)的建模,而如果統使用一個足夠容量的模型實現,還要告訴模型需要完成什么任務,這時建模目標可以表達為p(output|input, task)。
對于統一大模型的選擇,網絡結構與GPT-1相同,使用方式也很自然:task和input均使用自然語言的方式作為輸入交給GPT,模型繼續一步步地預測下一個最大可能的token,直到結束。如翻譯任務:模型輸入“翻譯中文到英文,原文‘我愛深度學習’”,模型輸出“I love deep learning.”。又如閱讀理解任務,模型輸入“回答問題,內容‘xxx’, 問題‘xxx?’”,模型輸出問題的答案。
沒錯,就是早期的Prompting方法(其實也不是最早的)。這么做的依據則是考慮到訓練數據集里有大量的Prompt結構的語料,可以使模型學到遇到類似的提示語后需要生成什么。

一些細節
-
訓練數據:為了支持多任務的Zero-Shot,需要模型盡可能看更多,盡可能豐富的數據,數據收集的目標也是如此。要點如下:
-
開源Common Crawl,全網網頁數據,數據集量大,且足夠豐富,但存在質量問題,故而沒有直接使用;
-
自建了WebText數據集,網頁數據,主打一個干凈高質量:只保留被人過濾過的網頁,但人過濾成本很高,這里的方法是只要Reddit平臺(類似國內的貼吧,社交分享平臺)中被用戶分享的站外鏈接,同時要求帖子至少3個karma(類似點贊?)。可以認為被分享的往往是人們感興趣的、有用的或者有意思的內容。
-
WebText最終包括4500w鏈接,后處理過程:1、提取網頁內容后;2、保留2017年以后的內容;3、去重;4、啟發式的清理,得到800w+的文檔,約40GB;4、剔除維基百科文檔,避免與下游測試數據重疊(因為很多測試任務包括了維基百科數據,話說其他數據沒有重疊嗎?)。
-
-
模型:沿用GPT結構,但在模型特征輸入編碼、權重初始化、詞典大小、輸入長度、batch size等方面做了一些調整,主要是升級。
結論與討論
-
主要結論:
-
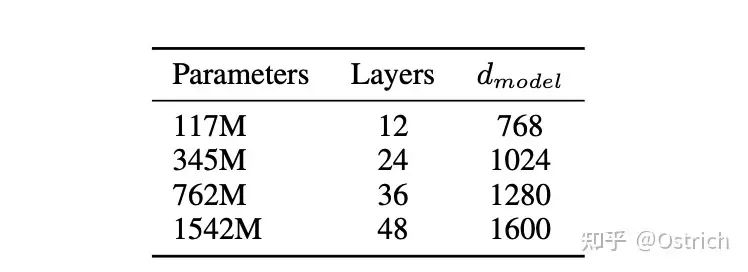
文章嘗試了四種大小的模型,其中117M對應了Bert-base(和GPT-1),345M對應和Bert-large參數量,最大的模型1542M(15億參數)。
-
-
-
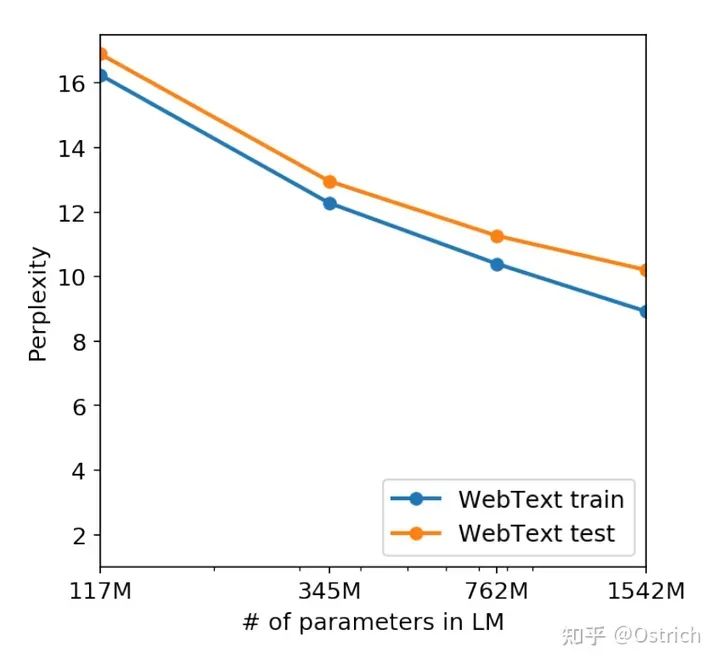
模型的選擇使用WebText的5%作為驗證數據,實驗發現所有大小的模型仍然是欠擬合狀態,隨著訓練時間的增加,在驗證集上的效果仍然可以繼續提升。
-
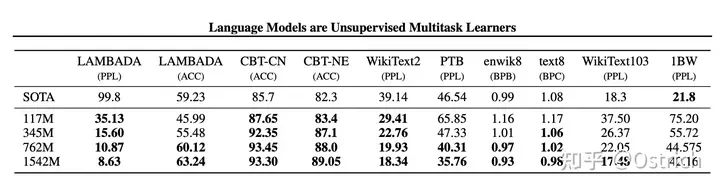
當然,在大多數Zero-Shot任務集合上也如愿取得了當時最好的結果:
-
-
次要結論:在多數任務上,模型容量和核心指標的關系,可以發現隨著模型容量的增加,效果不斷變強。15億參數看上去沒有達到瓶頸,也就是說繼續提升模型容量,效果能到什么程度極具想象力。(也就有了后續GPT-3的大力出奇跡)
-
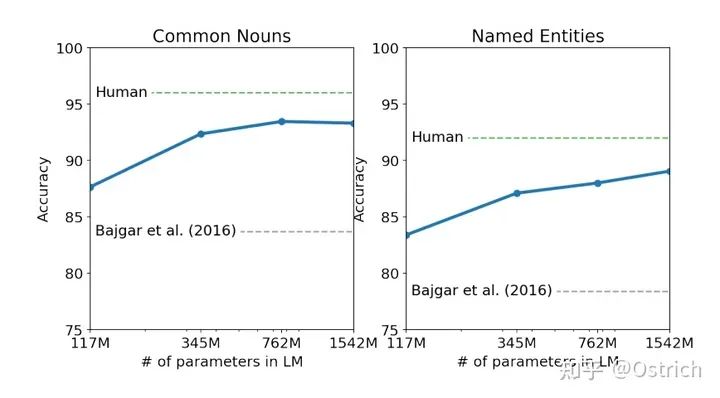
Children’s Book Test任務:
-
-
-
Winograd Schema Challenge任務:
-
-
-
其他Zero-Shot任務
-
-
-
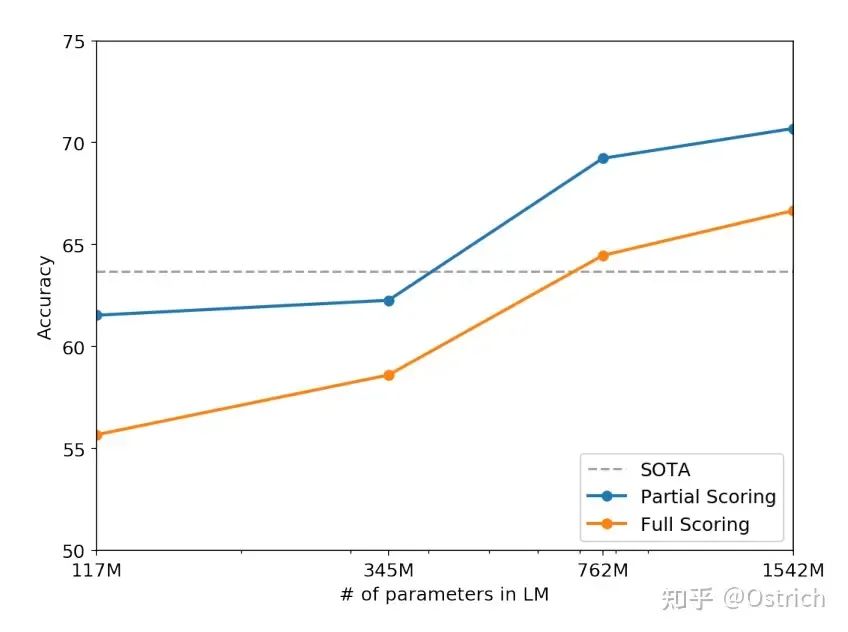
語言模型預訓練集和驗證集的效果(perplexity困惑度越小越好)
-
GPT-3
論文鏈接:《Language Models are Few-Shot Learners》
動機
BERT出來之后,雖然預訓練+微調架構取得了驚人的效果(GPT系列短期比不了了),但這種微調有很多限制:
-
微調需要更多的領域數據,標注成本高,一些特殊任務更是難上加難(如糾錯、寫作、問答等)。
-
微調在小數據量下表現好,很可能只是過擬合。很多任務說是超過人類,實際上是夸大了實際表現(模型并不是根據知識和推理去做任務,并不智能)。
-
以人類的學習習慣對比,在人類有了足夠的知識后(預訓練),并不需要再看大量的監督數據才能做任務(對應微調),而只需要看少量樣例即可。
文章認為,雖然微調現在效果確實打不過,但追求不微調仍然是值得的。方法嘛,延續GPT-2最后的結論,更大的模型、更多的數據、prompt更多的信息(In-Context learning)。
方案簡述
主要與GPT-2相比:
-
沿用GPT-2的模型和訓練方法,將模型大小升級到175B(1750億的參數量 vs 15億),這個175B的模型叫GPT-3;
-
不同于BERT/GPT-1模型使用下游任務微調進行效果驗證,也不同于GPT-2僅僅使用Zero-Shot進行驗證,GPT-3主要驗證其In-Context learning的能力(可能認為是不微調,不梯度更新的方式,看通過prompt和幾個例子作為輸入,來完成具體任務的能力)。
-
GPT-3也不是不能微調,以后會做一些工作來看看微調的表現(這里說的也就是后面的Codex、InstructGPT和ChatGPT等工作了)。
一些細節
-
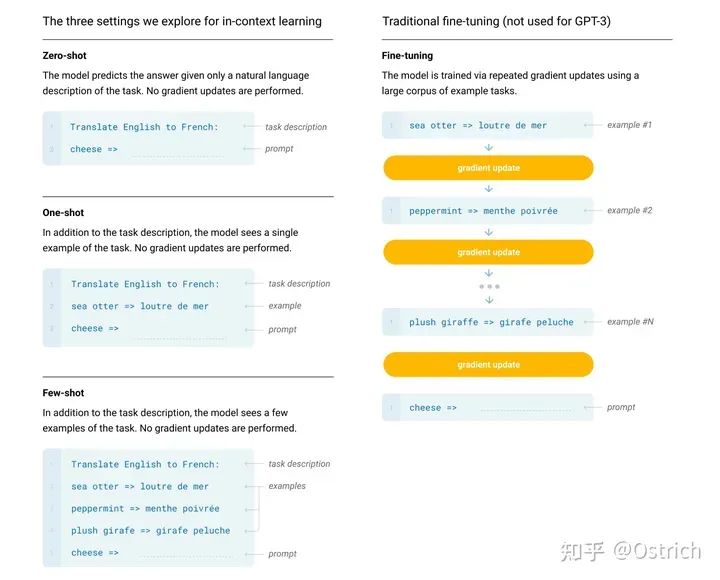
模型訓練方式:前面提到了,相對GPT-2沒有創新,就是更大模型、更多更豐富的數據、更長的訓練時間,不止于Zero-Shot,還做One-Shot和Few-Shot任務(這里的x-Shot是不微調模型的,也就是所謂的In-Context learning,而在預訓練階段沒有特殊操作),如圖。
-
模型:沿用了GPT-2的結構,在模型初始化、歸一化、Tokenization做了一些優化,另外也“抄”了一些類似Sparse Transformer的優點(總之是加了一些同期一些被驗證有效的操作,或自己驗證有效的小操作)。為了驗證模型容量帶來的效果,文章訓練了多種大小的模型,最大的175B的叫GPT-3。為了訓練大模型,還做了一些模型并行和提效的工作(其實這部分也比較重要,但是沒有展開說)。模型大小參數,以及同期一些工作的訓練資源開銷對比如圖:
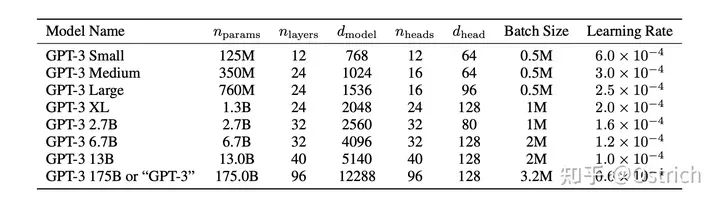
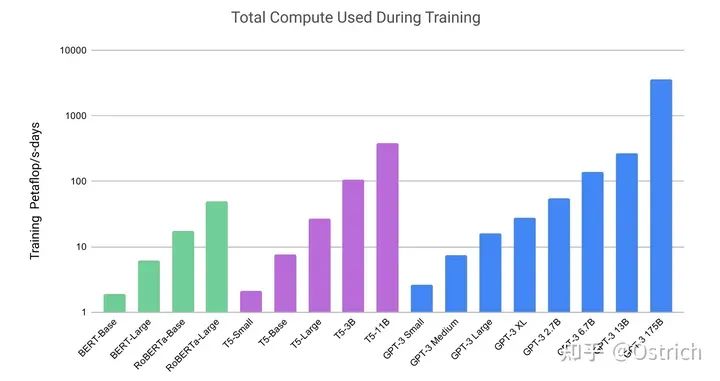
-
訓練數據準備:
-
文章發現,模型增大之后,引入一些臟數據的負向影響沒這么大了。因此,相比于GPT-2,GPT-3開始使用Common Crawl數據集了,但是做了一些清洗工作:1、保留與高質量數據集類似的內容(使用一些相似或判別的方法);2、去重;
-
最后把清洗后的Common Crawl數據和已有的高質量數據集合并在一起,得到訓練數據集,并進行不同權重的采樣使用:
-
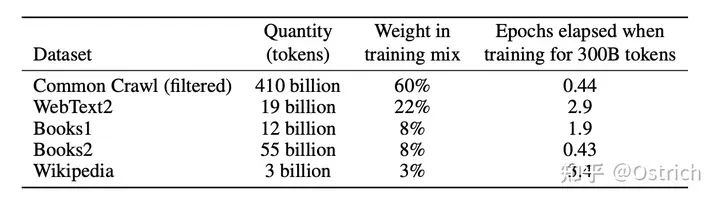
-
模型訓練過程:
-
大模型可以使用更大的batch size,但是需要小一點的Learning rate;根據梯度的噪音尺度,動態調整batch size;為了防止大模型OOM,使用了全方位的模型并行,微軟提供了硬件和軟件的支持。
-
結論與討論
-
主要結論:整體效果不錯,在各種數據集上做了對比,NLU相關任務,GPT-3表現不錯(個別數據集還超過了有監督微調的方式);在QA、翻譯、推理等任務上還欠點火候,距離監督微調模型差距明顯;生成任務基本可以做到人難分辨。如,幾個主要的任務:
-
SuperGLUE:理解任務為主
-
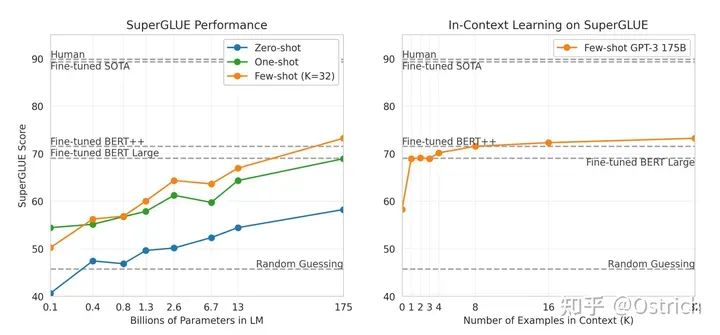
-
-
Winogrande:推理任務為主
-
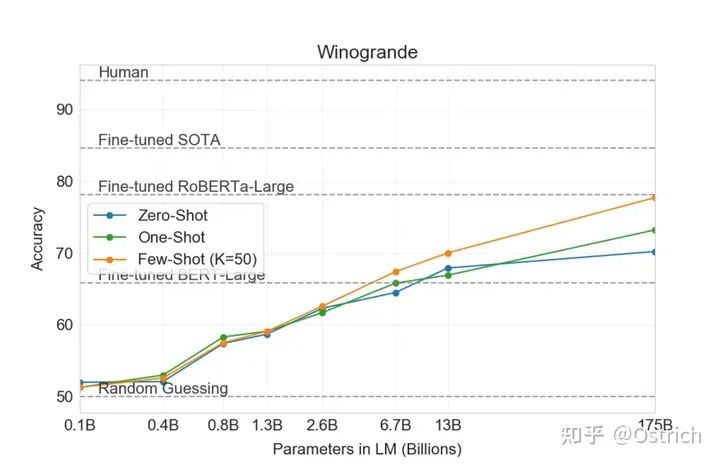
-
-
TriviaQA:閱讀理解任務為主
-
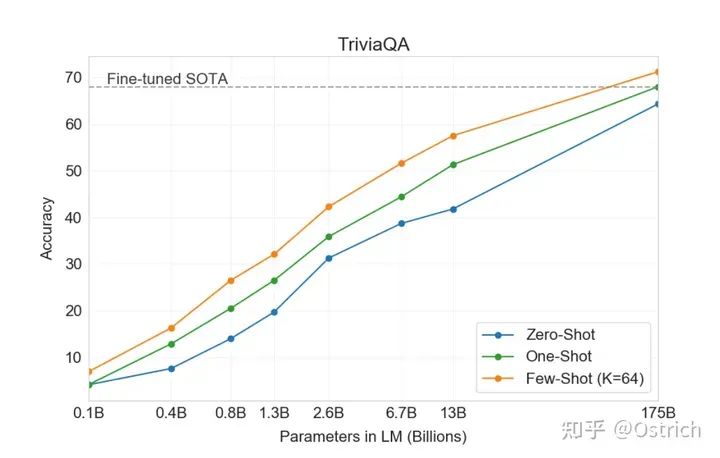
-
次要結論:
-
從主要結論曲線,可以明顯發現,few-shot比zero-shot效果好,模型越大越好(廢話),而且175B好像也沒到極限,模型更大效果可能還會繼續上升。
-
另一個數據顯示,模型越大,loss下降空間越大,當前版本最大的模型,仍然沒有收斂(黃色曲線);另一個不樂觀的趨勢是隨著Loss的逐步降低,算力的ROI(投入產出比)也在逐漸降低。
-
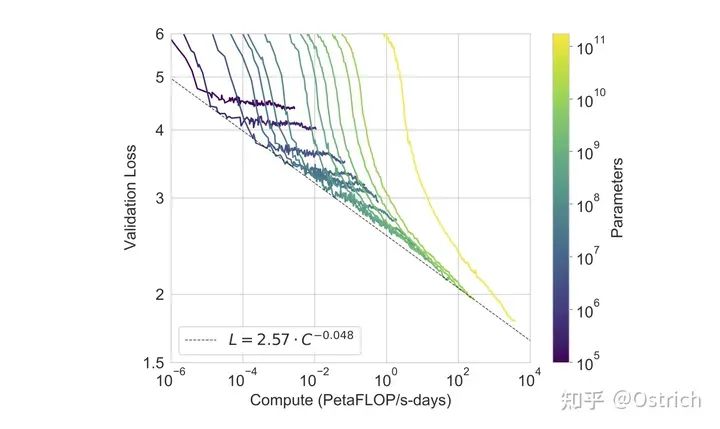
-
-
因為模型生成效果真假難辨,文章也著重討論了模型的偏見、不道德以及不當用途的問題,因此也決定不開源(OpenAI走上CloseAI之路)!
-
Codex
論文鏈接:《Evaluating Large Language Models Trained on Code》
動機
GPT-3論文里提到,GPT可以微調但放在未來搞,Codex就是微調工作之一。任務是GPT模型在代碼生成方向做微調的探索,算是一個應用方向的論文。
方案簡述
具體地,Codex是利用代碼注釋生成代碼。訓練數據從github上獲取,主要為python語言。為了驗證模型效果,Codex做了一個新的數據集(164個原始代碼問題,可以認為一些經典的leetcode題、面試題),通過單元測試的方式驗證生成代碼的正確性。
最終Codex可以取得28%的測試通過率(GPT-3只能解決0%);如果允許重復采樣生成多個結果,選擇100個,可以達到70%的通過率(想想自己能通過多少)。經過一些rerank策略,通過率直逼80%。
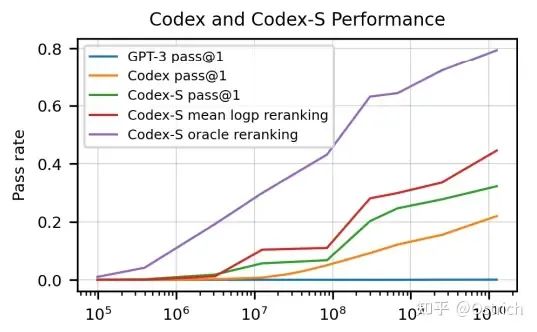
一些細節
-
驗證集準備:因為之前沒有現成的評測代碼生成的驗證集,文章自己設計了一個HumanEval。并使用pass@k作為評測指標(生成k個結果中有一個能通過就算通過,然后算通過率)。考慮生成代碼的安全性不可控,需要使用一個sandbox環境運行(崩了也沒事)。HumanEval的樣例數據如下,包括代碼注釋和標準答案:
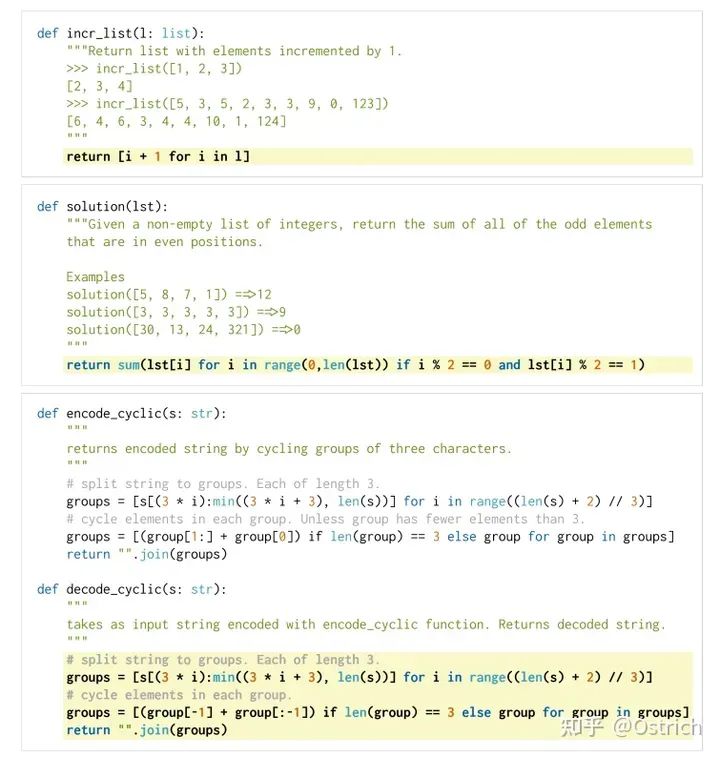
-
訓練數據:截止到2020年5月,涉及540萬的Github倉庫,包括179GB的Python文件,文件大小小于1MB。做了一些過濾,主要過濾項是自動生成的代碼、平均行長度大于100、最大行長度大于1000、包含一定比例數字等。最后數據集大小159GB。
-
模型:考慮生成任務,利用GPT系列的預訓練模型應該會有好處,選擇了13B的GPT模型作為主模型,進行微調。值得一提的是,利用預訓練的GPT微調并不優于使用代碼數據從頭訓練(應該是因為數據量已經足夠大了),但是使用微調收斂更快。模型細節:
-
參數配置和GPT-3差不多;基于代碼數據特點,做了特別的tokenizer,最終少了30%的token;sample數據時使用特別的停止符(' class'、' def'等),保證sample代碼的完整性;
-
結論與討論
-
主要結論:
-
不同的參數調整,和采樣數量,顯著影響生成代碼的通過率。
-
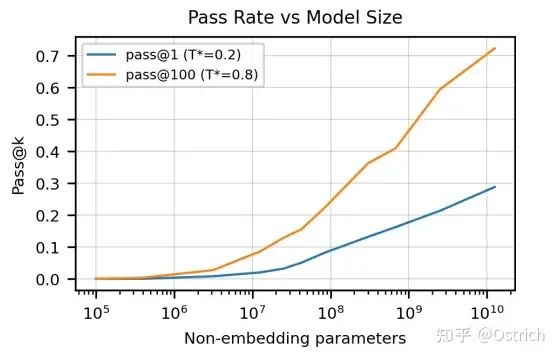
-
-
如果只選一個答案,使用一些模型輸出指標,如最大mean log-probability,可以比隨機選擇效果更好;用借助先驗知識的單元測試進行代碼選擇,可以取得理論上的最好效果(Oracle)。
-
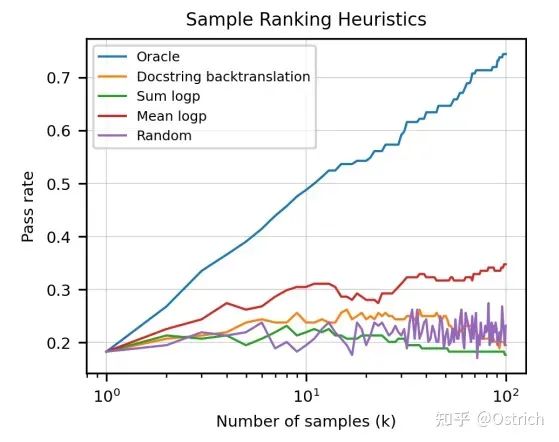
-
次要結論:因為效果還可以,趨勢上看模型更大看上去效果還會提升,文章最后討論了一下對于機器會寫代碼的擔憂(自我優化最可怕);另外代碼中也不出意外的有歧視、道德的偏見。(這個大概源自代碼里也有人口吐芬芳,代碼命名帶Fxxk,有人的地方就有偏見)。
InstructGPT
論文鏈接:《Training language models to follow instructions with human feedback》
動機
GPT的另一種微調探索,使用用戶指令和偏好答案來微調GPT模型,讓模型生成的內容更符合用戶的意圖,更真實、更有用(Alignment,對齊過程)。這么做的出發點是面向一種經典的應用場景,用戶給一條指令聲明意圖,期望模型生成有用、無害的內容,但使用大量網頁數據訓練的大語言模型GPT無法直接滿足這種訴求,因此需要微調。
方案簡述
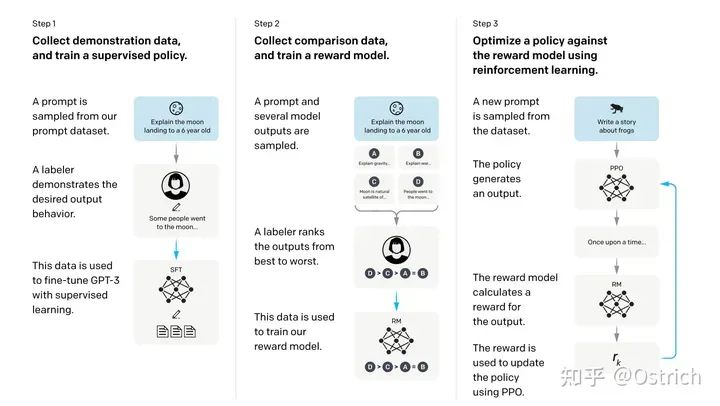
指令微調的過程分為三步(RLHF,Reinforcement Learning from Human Feedback),如下圖:
1、準備一批prompt(來源標注人員手寫、OpenAI API請求);對于這批prompt,標注人員手寫期望的答案,用這份prompt+answer數據微調GPT-3生成模型,這里叫做supervised policy;
2、使用微調后的模型,根據更多的prompt生成答案(一次prompt多次采樣生成個答案),這時外包只要標注生成內容的相對順序即可;用這份標注數據訓練一個reward模型(RM模型),輸入prompt和answer,模型輸出一個打分(這里同樣是使用GPT模型)。
3、采樣更多的prompt,使用強化學習的方式,繼續訓練生成模型,強化學習的reward使用第2步的模型打分。
第2和3步是一個持續迭代的過程,即,第3步訓練出的更好的生成模型(policy)可以用來收集更多具有相對順序標簽的數據,這些數據則用來訓練新的RM模型(即步驟2),繼而再訓練新的生成模型(對應步驟3)。大多數的相對順序標注數據來自于步驟1,一部分來自于步驟2和3的迭代。
此外這篇文章并不是第一個使用該方法的工作,前面還有一篇《Learning to summarize from human feedback》,使用類似三步方法做摘要任務。同樣是OpenAI的工作,體現了工作的持續性,而非一蹴而就,靈感也不是說有就有。
一些細節
-
數據收集過程
-
冷啟動階段:通過部分人工標注的prompt+answer數據,監督訓練得到的早期版本InstructGPT;豐富階段:部署試用版本在線服務,收集更多更豐富的真實用戶prompt。本工作并未使用線上正式環境的服務用戶數據,試用版本的數據將用于數據標注和模型訓練,也提前告知了用戶;
-
收集到的prompt根據最長公共前綴做了去重;
-
每個用戶最多200條prompt,避免模型迎合個別用戶偏好;訓練集、驗證集和測試集,不包括相同用戶(強調用戶維度的泛化能力);
-
過濾prompt中與個人身份相關的信息,同樣是避免模型學到用戶特征;
-
早期版本InstructGPT的訓練數據是由外包手寫的prompt和答案,冷啟prompt包括3類:1、任意常見任務問題,追求任務的豐富性;2、同一類prompt寫多個query和答案;3、模仿真實用戶的prompt請求;
-
經過上面的操作,得到三類數據:1、SFT dataset,訓練集13k prompts(來自于API和標注人員手寫),用來訓練SFT模型;2、RM數據集,訓練集33k prompts(來自于API和標注人員手寫),人工標注生成模型輸出答案的排序,用來訓練RM模型;3、PPO數據集,31k prompts(僅來自于API),不需要人工標注,用來做RLHF fine-tuning。
-
-
prompt特點:
-
真實用戶的prompt指令類型分布和樣例如圖,96%的是英文,但結果發現對其他語言也有泛化能力。
-
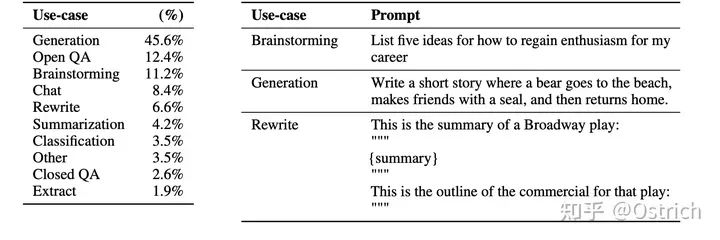
-
數據標注細節(也很關鍵,值得參考):
-
一個外包標注團隊,由40個承包商組成,應該是為了提升標注多樣性,防止模型對標注員風格敏感;
-
對標注人員進行了測試(考試,性格測試),篩選目標是留下那些隊不同群體敏感(宗教、性取向、種族等)、能識別潛在有害內容的標注人員;
-
要求標注人員能夠準確判斷用戶意圖,對于模糊意圖進行跳過;考慮隱含意圖,對于一些潛在、誘導性的臟話、偏見、虛假信息能夠識別;
-
訓練和驗證階段的意圖對齊(alignment)有些許沖突:訓練階段強調生成內容的有用性(helpfulness),驗證階段則關注內容的真實性(truthfulness)和是否有害(harmlessness);
-
標注過程,算法開發和標注人員緊密溝通,為了做到這點,對外包標注人員做了一個入職流程(可能要交社保=_=);
-
為了測試模型對標注人員的泛化能力,留了一部分測試用的標注人員(held-out labelers,真工具人,嚴謹了),這些標注人員產出的數據不用于訓練,而且這些人員沒有經過性格測試;
-
盡管標注任務難度大,但標注人員的標注一致性還可以,訓練標注人員標注一致性72.6 ± 1.5%,測試標注人員一致性77.3 ± 1.3%。
-
-
模型實現:同訓練過程,包括三部分
-
Supervised fine-tuning (SFT):使用標注人員標注的數據,有監督的微調GPT模型,訓了16個epoch, 學習率cosine decay。模型的選擇使用驗證集上的RM模型score(雞生蛋蛋生雞)。值得一提的是,這里SFT模型在驗證集上1個epoch后就overfit了,但是繼續更多的epoch有利于RM score和人的偏好。
-
Reward modeling (RM):
-
模型:同樣是SFT GPT模型結構,不過是另外訓練了一個6B的(175B不穩定,不適合下面的RL訓練),輸入是prompt和生成的內容,pooling后接一個全連接(也許有)輸出一個scalar reward分。
-
Loss函數表示為:
-
-
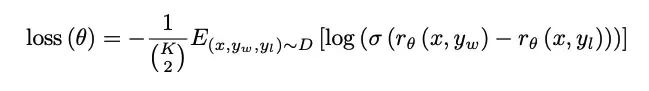
-
-
-
K為是一個prompt模型生成的答案數,標注人員對K個模型進行排序;K為4-9,標9個和4個成本差不多;
-
需要一個bias對reward進行歸一,使其均值為0,方便下游RL使用(這里的bias可以是reword均值,也是RL的常規操作);
-
-
Reinforcement learning (RL),兩個實驗模型:
-
‘PPO’模型:直接使用經典的PPO算法,一種offline的RL算法,目標是最大化模型反饋的reward,同時兼顧online模型和offline模型的KL散度(這里offline模型是SFT模型,online模型是要優化的目標模型,online模型參數會定期同步到offline模型。如果不熟悉RL可以簡單了解其目標即可);模型輸出的reward,由RM打分得到;
-
‘PPO-ptx’模型:PPO+預訓練目標(加這個目標,被驗證可以兼顧公開NLP任務的效果),最終的優化目標,最大化:
-
-
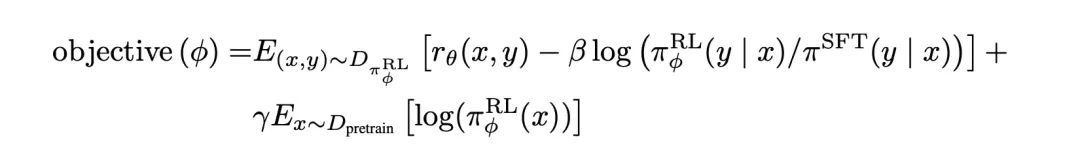
-
驗證方法:評價模型兩方面的能力,1、生成的答案人是不是喜歡;2、經典的NLP任務解決的怎么樣。
-
在API請求的prompt驗證效果:
-
真實分布下采樣prompt做測試集;
-
175B的SFT GPT-3模型作為Baseline;
-
標注人員對各個模型生成的內容打出1-7分的喜歡/認可度;
-
認可度的依據是helpful、honest和harmless,每個維度又有很多細則。
-
-
在開源的NLP數據集,包括兩類:
-
評測安全性、真實性、有害和偏見的數據集;
-
經典NLP任務數據集熵zero-shot的結果,如閱讀理解、問答、摘要等。
-
-
結論與討論
-
主要結論:
-
對于通過API獲得的測試集prompt,RLHF顯出好于baseline:
-
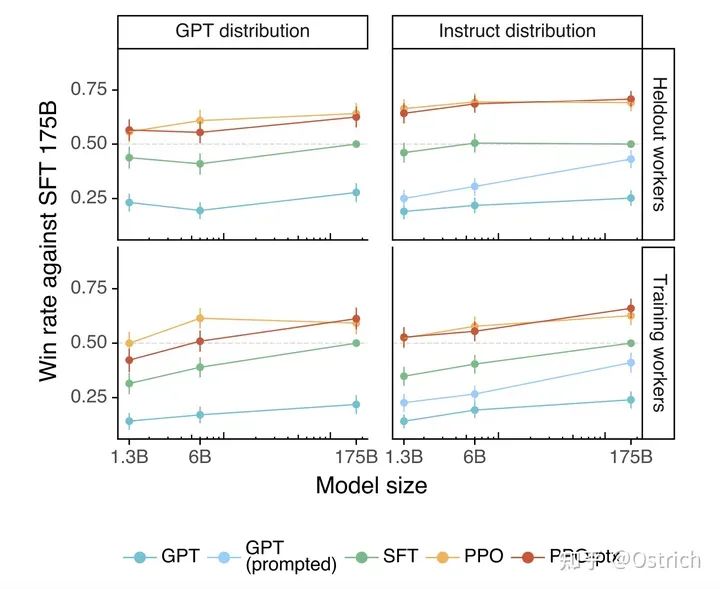
-
-
對比友商模型,也不錯:
-
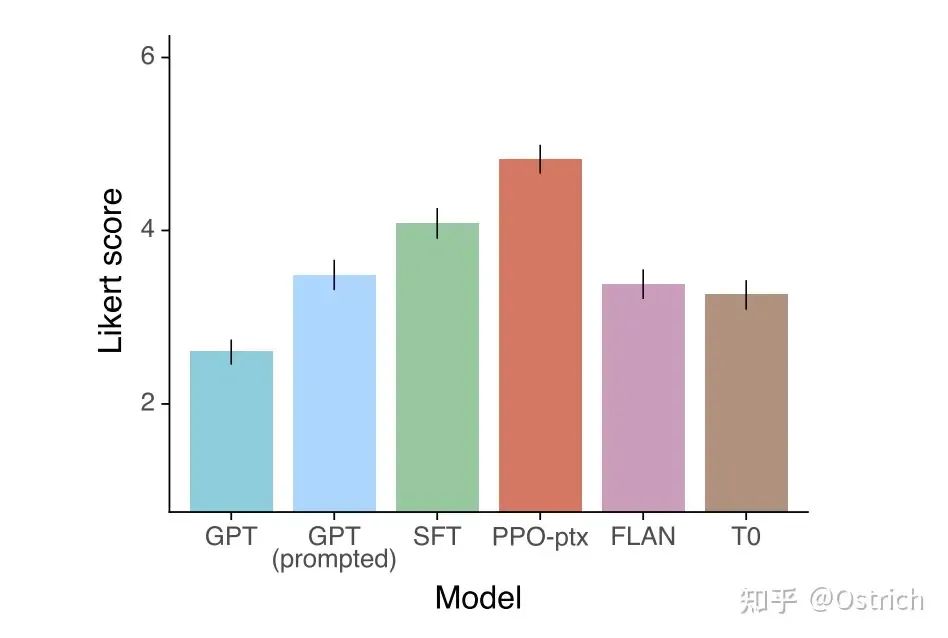
-
次要結論(InstructGPT生成內容的白話評價):
-
標注人員普遍認為InstructGPT生成的內容比GPT-3強很多;
-
InstructGPT模型生成的內容比GPT-3事實性更強(出現事實性錯誤比較少);
-
InstructGPT生成的內容在有害性優于GPT-3,但在偏見方面并沒有強很多;
-
在RLHF微調過程中,由于“對齊稅”的原因,在開源NLP任務表現變差了,但RLHF基礎上增加語言模型的預訓練目標,可以得到兼顧(PPO-ptx)。
-
InstructGPT模型在“held-out”標注人員上也表現出了不錯的泛化性;
-
公開NLP數據集任務上的表現,并不是InstructGPT追求的(ChatGPT才是);
-
InstructGPT模型在RLHF finetuning數據集分布外的prompt同樣具有很好的泛化能力;
-
InstructGPT生成的內容仍然會出現一些簡單的錯誤;
-
ChatGPT
論文沒有,官方博客:《https://openai.com/blog/chatgpt》
OpenAI沒有開放ChatGPT的細節,只有兩段大致方法描述,摘要一下包括:
-
和InstructGPT的方法大致相同,只是在數據收集上略有不同。ChatGPT使用的對話形式的數據,即多輪prompt和上下文,InstructGPT的數據集也轉換成對話格式合并一起使用。
-
訓練RM模型,使用多個模型生成的結果,隨機選擇模型生成的內容讓標注人員根據內容質量排序,然后借助RM模型進行后續的PPO微調訓練。同樣,這也是一個反復迭代的過程。
更多的細節無了,不過從OpenAI友商Anthropic(創始人也來自OpenAI)的一篇論文能看到更多細節。以OpenAI工作的持續性看,從公司跳槽出去的人,應該也是延續了相關的工作。
讀Anthropic之前,插一段OpenAI的系列工作總結,存個檔。讀了上面的論文,對于這張表的內容應該能夠大致理解(參考):
| 能力 | 模型名 | 訓練方法 | OpenAI API |
| Before GPT-3 | |||
| Pretrain + Fintune like Bert | GPT-1 | Language Modeling + Task Finetune | - |
| Generation+Zero-shot task | GPT-2 | Language Modeling | - |
| GPT-3 Series | |||
| Generation+World Knowledge+In-context Learning | GPT-3 Initial | Language Modeling | Davinci |
| +Follow Human Instruction+generalize to unseen task | Instruct-GPT initial | Instruction Tuning | Davinci-Instruct-Beta |
| +Code Understanding+Code Generation | Codex initial | Training on Code | Code-Cushman-001 |
| GPT-3.5 Series | |||
| ++Code Understandning++Code Generation++Complex Reasoning / Chain of Thought (why?)+long-term dependency (probably) | Current Codex Strongest model in GPT3.5 Series | Training on text + code Tuning on instructions | Code-Davinci-002 (currently free. current = Dec. 2022) |
| ++Follow Human Instruction--In-context learning--Reasoning++Zero-shot generation | Instruct-GPT supervisedTrade in-context learning for zero-shot generation | Supervised instruction tuning | Text-Davinci-002 |
| +Follow human value+More detailed generation+in-context learning+zero-shot generation | Instruct-GPT RLHF More aligned than 002, less performance loss | Instruction tuning w. RLHF | Text-Davinci-003 |
| ++Follow human value++More detailed generation++Reject questions beyond its knowledge (why?) ++Model dialog context --In-context learning | ChatGPT Trade in-context learning for dialog history modeling | Tuning on dialog w. RLHF | - |
可能確實如一些大佬所說,ChatGPT沒有創新,只是一堆策略的疊加,湊出了一個強大的模型;也有人說ChatGPT更多的是工程和算法的結合。不管怎么樣,方法是真work。
Anthropic的Claude
參考論文鏈接:《Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback》
ChatGPT出來不久,Anthropic很快推出了Claude,媒體口徑下是ChatGPT最有力的競爭者。能這么快的跟進,大概率是同期工作(甚至更早,相關工作論文要早幾個月)。Anthropic是OpenAI員工離職創業公司,據說是與OpenAI理念不一分道揚鑣(也許是不開放、社會責任感?)。
一些內測結論:Claude相比ChatGPT更能避免潛在harmful的問題,在代碼生成略為遜色,通用Prompt不分伯仲。從效果上,可能ChatGPT功能性更強,而Claude更為“無害”(或者說,對社會的潛在負面影響更小),這點從參考論文的標題也有所體現。
動機
引入偏好模型和RLHF(人類反饋強化學習)微調大語言模型(可能因為脫離OpenAI,不提GPT-3了),得到一個helpful和harmless的個人助理(類似ChatGPT);這種對齊(Alignment)微調,使預訓練的語言模型在幾乎所有的NLP任務中效果提升顯著,并且可以完成特定的任務技能,如coding、摘要和翻譯等。
方案簡述
其實思路和InstructGPT差不多,三階段的RLHF。不同點在于,1、進行了迭代式的在線模型訓練:模型和RL策略每周使用新的人工反饋數據更新,不斷迭代數據和模型;2、使用對話格式的數據數據;3、更為關注模型的helpful和harmless。
除了模型和策略設計之外,文章重點討論了RLHF的穩定性問題;也對模型校準、目標沖突、OOD(out of distribution)識別等問題做了分析。
目標沖突是指helpful和harmless的目標沖突,因為如果模型對所有問題都回答“不知道”,雖然harmless,但是完全不helpful。
一些細節
-
對話偏好數據集:
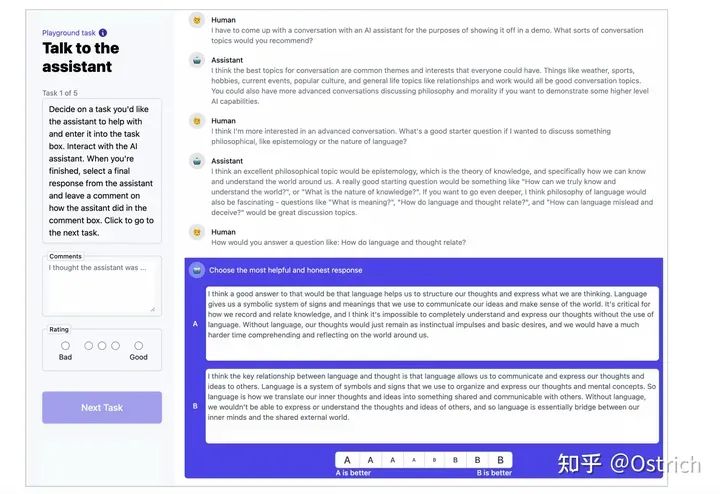
-
收集了一批helpfulness and harmlessness的對話數據集,數據的標注是標注人員和各種52B語言模型在對話標注頁面交互完成。標注頁面如圖;
-
-
-
標注人員在交互頁面與模型進行開放式對話,或者尋求幫助、或者提出指令、或者引導模型輸出有害內容(比如如何成功搶劫)。對于模型輸出的多個答案,標注人員需要在每輪對話標注出哪個更有用或哪個更有害;
-
收集了三份數據,一個來自于初始模型(SFT)、一個來自早期的偏好模型(RM)采樣、最后一個來自人工反饋的在線強化學習模型(周更);
-
開源了三份數據:https://github.com/anthropics/hh-rlhf
-
-
數據收集和模型訓練流程(中間涉及的概念需要讀往期論文,了解即可):
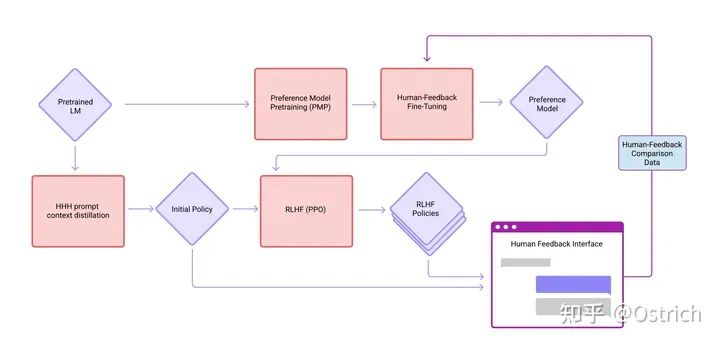
LLaMa與Alpaca
事情發展到現在,有一個小問題,就是模型越來越大,開源越來越少(其實開源了大多數人也玩不了)。首先GPT-3系列模型就很大了,訓練和inference模型都需要大量的顯卡;其次,GPT-3所用的數據也未公開,有算力復現也稍困難,需要自己去盤數據;在GPT-3之后的ChatGPT的閉源程度更甚,可能要進一步考慮商業利益。
在這樣的背景下,前調模型提效以及開放的工作越來越多,近期比較有影響里的當屬Meta AI的LLama和斯坦福基于LLama的Alpaca。前者類似GPT的大語言模型,后者類似ChatGPT。
LLama
論文:《LLaMA: Open and Efficient Foundation Language Models》
代碼:https://github.com/facebookresearch/llama
動機
-
大語言模型相關的工作中,過去的普遍假設是模型越大效果越好。但近期有些工作表明,給定計算資源的前提下,最佳的效果不是由最大的模型實現,而是由更多的數據下相對小的模型實現。而后者對于inference或微調階段更為友好,是更好的追求。
-
相應的,本文的工作是訓練一批模型,實現了更好的效果,同時預測成本低。取得這種效果的一大手段,就是讓模型看到了更多的token。訓練得到的這些模型就是LLama。
方案簡述
LLama的思想比較簡單,在動機里已經大致包括。這項工作的其他特點可以簡述為以下幾點:
-
提供了7B~65B的模型,13B的模型效果可超GPT-3(175B),65B的模型效果直逼谷歌的PaLM(540B);
-
訓練模型只用了開源數據集,trillions of token。
-
多項任務上SOTA,并且開源了所有模型權重。
一些細節
-
訓練數據集(主要是英文,因此中文和中文微調效果堪憂)
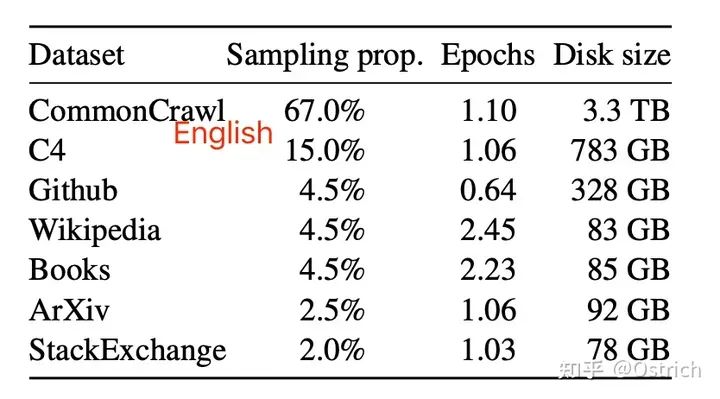
-
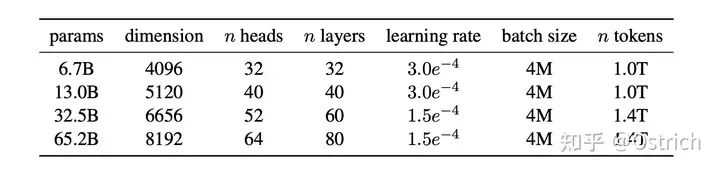
模型容量概況
-
模型結構:
和GPT一樣,同樣是Transformer Decoder架構,沿用了各種工作被驗證有效的小優化(如:Pre-Normalization、SwiGLU激活函數、Rotary Embedding、AdamW優化器等)。同時也做了一些訓練效率上的優化,包括模型實現上以及模型并行上的優化。
-
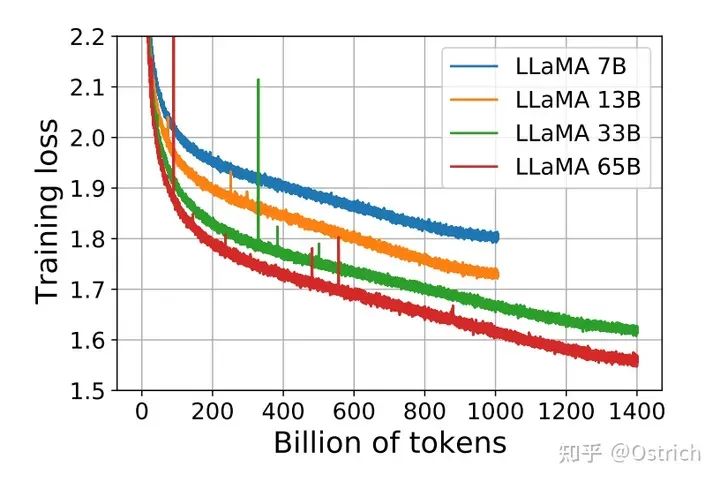
訓練過程:7B和13B的模型在1T的token上進行訓練;33B和65B的模型則在1.4T的token上進行了訓練。
結論與討論
-
LLama對標GPT,主要在Zero-Shot和Few-Shot任務上進行了驗證;同時考慮指令微調是現在的流行應用之一,因此也在指令微調任務做了驗證。
-
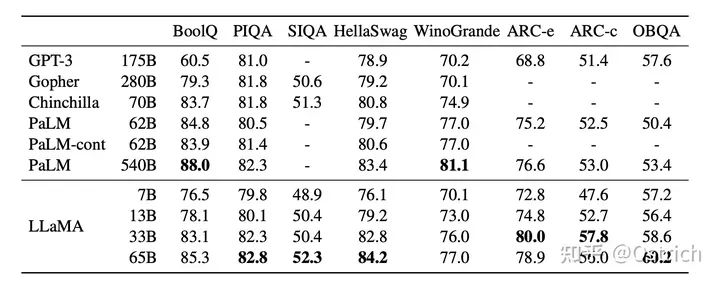
Zero-Shot
-
-
-
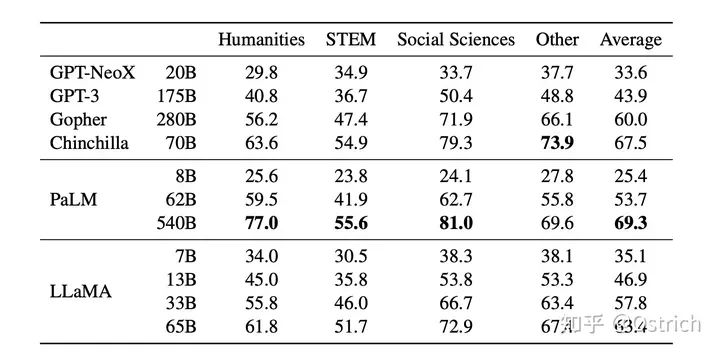
Few-Shot
-
-
-
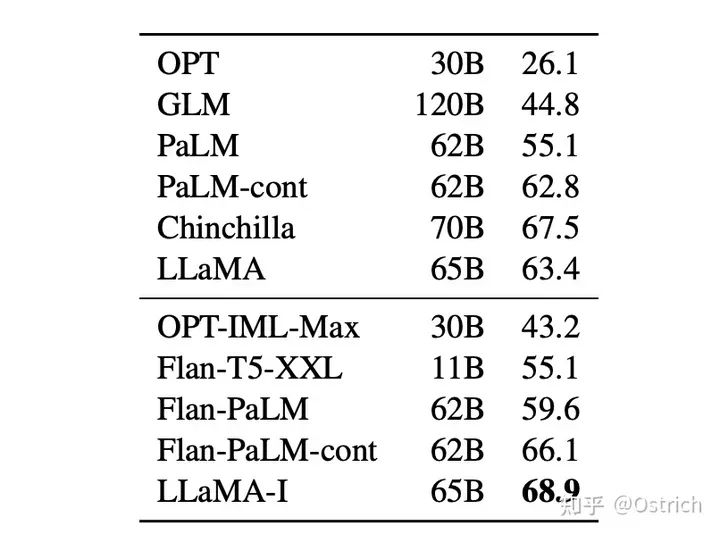
指令微調(主要和谷歌的Flan系列做對比):
-
Alpaca
文章:https://crfm.stanford.edu/2023/03/13/alpaca.html
代碼:https://github.com/tatsu-lab/stanford_alpaca
動機
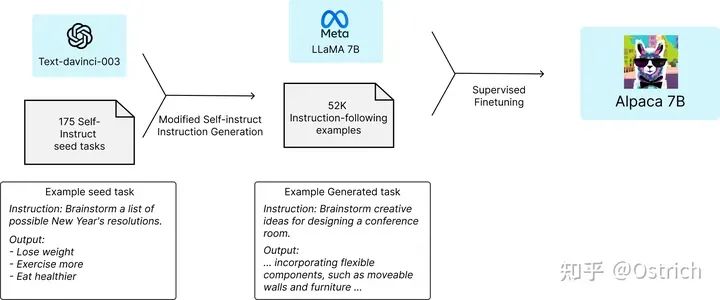
前面可以看到,GPT-3.5、ChatGPT、Claude以及Bing Chat等指令微調模型被驗證效果拔群,但仍存在生存內容虛假、帶偏見和惡意等問題。為了加快這些問題的解決,需要學術屆(窮老師、學生、公司)的加入一起研究,但是GPT-3.5這些模型大且閉源。
前陣子LLama發布,給了希望。所以基于LLama做指令微調得到了Alpaca模型,效果和GPT-3.5差不多,而且簡單、復現成本低。
方案簡述
-
窮人搞指令微調,需要兩個前提:1、參數量小且效果好的預訓練語言模型;2、高質量的指令訓練數據。
-
這兩個前提,現在看上去可以方便滿足:1、LLama模型7B模型,可以接受;2、通過現有的強語言模型可以自動生產訓練數據(準備prompt,調用GPT-3.5系列的OpenAI api)。
一些細節
-
訓練方式:使用指令微調的方式,在LLama 7B模型上訓練;訓練數據規模為5.2萬,來源是對OpenAI GPT-3.5 API的調用(花費500美元);微調過程在8張 80G A100s顯卡訓練3小時(使用云計算服務,花費100美元)。訓練過程如圖。
結論和討論
目前開放了:測試Demo、訓練數據集、訓練數據的生成過程、訓練代碼;預訓練的權重未來開放(可能考慮一些外因);
-
Demo: aninteractive demofor everyone to try out Alpaca.
-
Data:52K demonstrationsused to fine-tune Alpaca.
-
Data generation process: the code forgenerating the data.
-
Training code: forfine-tuningthe model using the Hugging Face API.
未來可能的方向(不包括優化推理能力,也許這些還是要留給有錢人):
-
模型驗證:更加系統嚴格的對模型進行評估,會從HELM(Holistic Evaluation of Language Models)開始,檢驗模型的生成和指令對其能力;
-
模型的安全性:更全面的評估模型的風險性;
-
理解模型(可解釋):研究模型學到的是什么?基模型的選擇有什么學問?增加模型參數帶來的是什么?指令數據最關鍵的是什么?有沒有其他的收集數據的方法?
GLM與ChatGLM
LLama雖好,但更多的是使用英文數據集,但在中文上表現不佳。同樣指令微調后在中文場景下上限應該也比較低。因此在中文上,有必要有自己的一條研究方向,當前影響力比較高的開源版本屬清華的GLM和ChatGLM。
GLM和ChatGLM相關的介紹比較多,下面摘抄部分內容對其進行簡單了解。
GLM
論文:
-
《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》
-
《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》
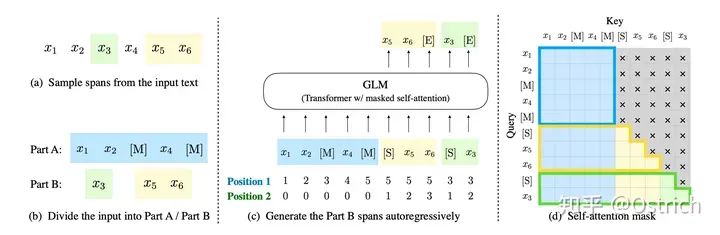
方案簡述
GLM-130B是在GPT-3之后,清華的大語言模型方向的嘗試。不同于 BERT、GPT-3 以及 T5 的架構,GLM-130B是一個包含多目標函數的自回歸預訓練模型。
一些細節
GLM-130B在2022年8月開放,有一些獨特的優勢:
-
雙語:同時支持中文和英文。
-
高精度(英文):在公開的英文自然語言榜單 LAMBADA、MMLU 和 Big-bench-lite 上優于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
-
高精度(中文):在7個零樣本 CLUE 數據集和5個零樣本 FewCLUE 數據集上明顯優于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
-
快速推理:首個實現 INT4 量化的千億模型,支持用一臺 4 卡 3090 或 8 卡 2080Ti 服務器進行快速且基本無損推理。
-
可復現性:所有結果(超過 30 個任務)均可通過我們的開源代碼和模型參數復現。
ChatGLM
文章:https://chatglm.cn/blog
代碼:https://github.com/THUDM/ChatGLM-6B
方案簡介
ChatGLM參考ChatGPT 的設計思路,在千億基座模型 GLM-130B中注入了代碼預訓練,通過有監督微調(Supervised Fine-Tuning)等技術實現人類意圖對齊。
為與社區一起更好地推動大模型技術的發展,清華同時開源 ChatGLM-6B模型。ChatGLM-6B 是一個具有62億參數的中英雙語語言模型。通過使用與 ChatGLM(http://chatglm.cn)相同的技術,ChatGLM-6B 初具中文問答和對話功能,并支持在單張 2080Ti 上進行推理使用。
一些細節
ChatGLM-6B 有如下特點:
-
充分的中英雙語預訓練:ChatGLM-6B 在 1:1 比例的中英語料上訓練了 1T 的 token 量,兼具雙語能力。
-
優化的模型架構和大小:吸取 GLM-130B 訓練經驗,修正了二維 RoPE 位置編碼實現,使用傳統FFN結構。6B(62億)的參數大小,也使得研究者和個人開發者自己微調和部署 ChatGLM-6B 成為可能。
-
較低的部署門檻:FP16 半精度下,ChatGLM-6B 需要至少 13GB 的顯存進行推理,結合模型量化技術,這一需求可以進一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消費級顯卡上。
-
更長的序列長度:相比 GLM-10B(序列長度1024),ChatGLM-6B 序列長度達 2048,支持更長對話和應用。
-
人類意圖對齊訓練:使用了監督微調(Supervised Fine-Tuning)、反饋自助(Feedback Bootstrap)、人類反饋強化學習(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人類指令意圖的能力。輸出格式為 markdown,方便展示。
因此,ChatGLM-6B 具備了一定條件下較好的對話與問答能力。ChatGLM-6B 也有相當多已知的局限和不足:
-
模型容量較小:6B 的小容量,決定了其相對較弱的模型記憶和語言能力。在面對許多事實性知識任務時,ChatGLM-6B 可能會生成不正確的信息;她也不擅長邏輯類問題(如數學、編程)的解答。
-
可能會產生有害說明或有偏見的內容:ChatGLM-6B 只是一個初步與人類意圖對齊的語言模型,可能會生成有害、有偏見的內容。
-
較弱的多輪對話能力:ChatGLM-6B 的上下文理解能力還不夠充分,在面對長答案生成,以及多輪對話的場景時,可能會出現上下文丟失和理解錯誤的情況。
-
英文能力不足:訓練時使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示時,回復的質量可能不如中文指示的回復,甚至與中文指示下的回復矛盾。
-
易被誤導:ChatGLM-6B 的“自我認知”可能存在問題,很容易被誤導并產生錯誤的言論。例如當前版本模型在被誤導的情況下,會在自我認知上發生偏差。即使該模型經過了1萬億標識符(token)左右的雙語預訓練,并且進行了指令微調和人類反饋強化學習(RLHF),但是因為模型容量較小,所以在某些指示下可能會產生有誤導性的內容。
小結
到這里還是低谷了工作量,寫吐了,谷歌系列的幾個工作,還是得單獨一篇才能完結。與OpenAI的工作類似,谷歌同樣產出了對標GPT-3和InstructGPT之類的模型,也包括了T5系列的Encoder-Decoder結構的大語言模型,而且并不是簡單的Follow。
另一方面3、4月份,廣大的開源工作者們也是百花齊放,在類ChatGPT的應用方向做出了很多探索工作,包括訓練數據、模型、以及訓練方法的探索與開源。在訓練效率方向上,也出現了ChatGLM+Lora、LLama+Lora等進一步降低訓練成本的工作。
這部分的內容也將在后面進行總結式的介紹和更新,也期待在這段時間里有更多優秀的工作誕生。對于文章中內容中的不正之處,也歡迎指正交流~。
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
深度學習
+關注
關注
73文章
5493瀏覽量
120998 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507
原文標題:ChatGPT的朋友們:大語言模型經典論文一次讀到吐
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
名單公布!【書籍評測活動NO.34】大語言模型應用指南:以ChatGPT為起點,從入門到精通的AI實踐教程
朋友們幫忙啊
fpga學習群,歡迎朋友們加入
PCB技術交流群 262600057 pcb菜鳥們的天堂 做PCB的朋友們值...
請問下朋友們,Matched Net Lengths到底該設置成多少呢??
實驗室的朋友們看過
科技大廠競逐AIGC,中國的ChatGPT在哪?
ChatGPT浪潮下,看中國大語言模型產業發展






 工商網監
工商網監
評論