 從FPGA說起的深度學習:任務并行性
從FPGA說起的深度學習:任務并行性
這是新的系列教程,在本教程中,我們將介紹使用 FPGA 實現深度學習的技術,深度學習是近年來人工智能領域的熱門話題。
在本教程中,旨在加深對深度學習和 FPGA 的理解。
用 C/C++ 編寫深度學習推理代碼
高級綜合 (HLS) 將 C/C++ 代碼轉換為硬件描述語言
FPGA 運行驗證
從這篇文章中,我們將從之前創建的網絡模型中提取并行性,并確認處理速度得到了提高。首先,我們檢查當前模型的架構,并考慮什么樣的并行化是可性的。
并行化方法研究
當前模型架構的框圖如下所示。限于篇幅省略了maxpool2d和relu。
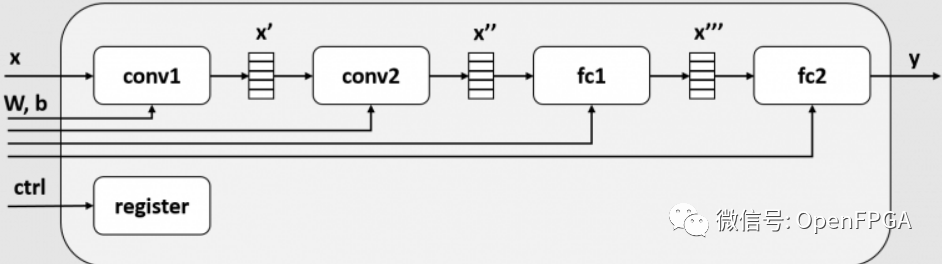
在這個模塊中,conv1、conv2、fc1、fc2都是作為不同的模塊實現的。FPGA內部的SRAM在每一層之間插入一個緩沖區(x', x'', x''' ),這個緩沖區成為每一層的輸入和輸出。此后,每一層(conv1、conv2、fc1、fc2)被稱為一個任務。
順序處理(基線)
下圖顯示了使用該模塊對 3 幀圖像執行推理處理時的執行時間可視化。
每個任務的執行時間以推理模塊的實際運行波形為準,是conv2>conv1>fc1>fc2的關系。在該模塊中,conv1、conv2、fc1和fc2作為單獨的任務實施,但是這些任務一次只能運行一個(后面會解釋原因)。因此,如果將conv1、conv2、fc1、fc2各層的執行時間作為最終的執行時間,則這3幀圖像的t0, t1, t2, t3處理時間為3 * (t0 + t1 + t2 + t3)

任務并行度
假設我們可以修復這些任務并發運行。這種情況下的執行時間如下所示,多個任務可以同時處理不同的幀。

提取并行性使多個任務可以同時運行,稱為任務并行化。在這個過程中,conv2的執行時間占主導地位,所以3幀的處理時間為t0 + 3 * t1 + t2 + t3。
理想的任務并行度
最后,我們考慮可以理想地執行任務并行化的模式。如上所述,如果只提取任務并行性,最慢的任務就會成為瓶頸,整體處理速度會受到該任務性能的限制。因此,最有效的任務并行是所有任務都具有相同的執行時間。

在這種情況下,處理時間t0 + 3 * t1 + t2 + t3保持不變,但t0 = t1 = t2 = t3調整了每個任務的執行時間,從而提高了性能。在本課程中,實現這種加速的技術被稱為循環并行化和數據并行化。這兩種并行度提取方法將在下一篇文章中介紹。
任務并行化
在本文中,第一個目標是執行任務并行化。
由于這次創建的模塊中有多個任務,貌似已經可以并行處理了,但在實際波形中并不是這樣。之所以不能并行化,是因為作為x', x'', x'''任務間接口的buffer()不能被多個任務同時使用。對于任務并行化,任務之間的接口必須可以同時被兩個或多個任務讀寫。
在這個模塊x'中,任務級并行化是通過在任務之間使用乒乓緩沖區來實現的。乒乓緩沖區有兩個緩沖區,一個用于寫入,一個用于讀取。帶有乒乓緩沖器的框圖如下所示:
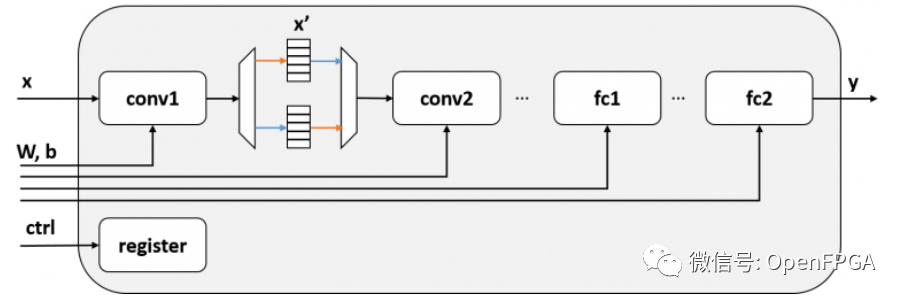 帶有乒乓緩沖器的推理模塊
帶有乒乓緩沖器的推理模塊
如果以這種方式配置電路,存儲 conv1 輸出的緩沖區和 conv2 從中讀取輸入的緩沖區是分開的,因此 conv1 和 conv2 可以同時運行。雖然圖中省略了,但所有層都可以通過雙緩沖conv2 <-> fc1,fc1 <-> fc2同時操作。
要在 RTL 中實現這一點,準備兩個緩沖區并實現切換機制會很麻煩,但在 Vivado/Vitis HLS 中,只需添加一些 pragma 即可實現這種并行化。
代碼更改
對于此任務并行化,我們需要添加以下三種類型的編譯指示。
#pragmaHLSdataflow #pragmaHLSstable #pragmaHLSinterfaceap_ctrl_chain
在解釋每個pragma的作用之前,我先inference_dataflow展示一下新增函數的源代碼。與第五篇中的inference_top函數重疊的部分省略。
60voidinference_dataflow(constfloatx[kMaxSize],
61constfloatweight0[kMaxSize],constfloatbias0[kMaxSize],
62constfloatweight1[kMaxSize],constfloatbias1[kMaxSize],
63constfloatweight2[kMaxSize],constfloatbias2[kMaxSize],
64constfloatweight3[kMaxSize],constfloatbias3[kMaxSize],
65floaty[kMaxSize]){
66#pragmaHLSdataflow
67#pragmaHLSinterfacem_axiport=xoffset=slavebundle=gmem0
...
76#pragmaHLSinterfacem_axiport=yoffset=slavebundle=gmem9
77#pragmaHLSinterfaces_axiliteport=xbundle=control
...
86#pragmaHLSinterfaces_axiliteport=ybundle=control
87#pragmaHLSinterfaces_axiliteport=returnbundle=control
88#pragmaHLSinterfaceap_ctrl_chainport=returnbundle=control
89
90#pragmaHLSstablevariable=x
91#pragmaHLSstablevariable=weight0
92#pragmaHLSstablevariable=bias0
93#pragmaHLSstablevariable=weight1
94#pragmaHLSstablevariable=bias1
95#pragmaHLSstablevariable=weight2
96#pragmaHLSstablevariable=bias2
97#pragmaHLSstablevariable=weight3
98#pragmaHLSstablevariable=bias3
99#pragmaHLSstablevariable=y
100
101dnnk::inference(x,
102weight0,bias0,
103weight1,bias1,
104weight2,bias2,
105weight3,bias3,
106y);
107}
第66 行添加#pragma HLS dataflow的 pragma使inference_dataflow這些內部函數之間的接口成為乒乓緩沖區并啟用任務并行化。第 101 行調用的函數dnnk::inference是下面的函數,它通過第 20 行的#pragma HLS inline編譯指示在函數內inference_dataflow內嵌展開。因此,諸如 conv2d, relu的函數符合任務并行化的條件,它們的接口 ( x1, x2, ...) 是一個乒乓緩沖區。
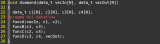
14staticvoidinference(constfloat*x, 15constfloat*weight0,constfloat*bias0, 16constfloat*weight1,constfloat*bias1, 17constfloat*weight2,constfloat*bias2, 18constfloat*weight3,constfloat*bias3, 19float*y){ 20#pragmaHLSinline ... 34 35//1stlayer 36conv2d(x,weight0,bias0,kWidths[0],kHeights[0],kChannels[0],kChannels[1],3,x1); 37relu(x1,kWidths[0]*kHeights[0]*kChannels[1],x2); 38maxpool2d(x2,kWidths[0],kHeights[0],kChannels[1],2,x3); 39 ... 48 49//4thlayer 50linear(x8,weight3,bias3,kChannels[3],kChannels[4],y); 51}
inference_dataflow從函數的第90行#pragma HLS stable開始,在x, weight0, y輸入/輸出等函數inference_dataflow的入口/出口處自動完成同步。如果不去掉這個同步,兩個進程之間就會產生依賴,比如“上一幀y輸出完成->下一幀x輸入準備好”,多任務就不行了。另請參閱Vivado HLS 官方文檔 ( UG902 ),了解有關穩定陣列部分的詳細說明。
最后,inference_dataflow該函數第88行的pragma修改了外部寄存器接口,使得#pragma HLS interface ap_ctrl_chain port=return該函數可以用于同時處理多個幀。inference_dataflow如果沒有這個 pragma,即使你實現了 ping-pong 緩沖區,主機端也只會嘗試一個一個地執行它們,性能不會提高。
綜合結果確認
可以在檢查綜合時檢查任務并行化是否順利進行。
下面是HLS綜合結果報告,Latency -> Summary一欄列出了整個函數的延遲和執行間隔(Interval)。在這里,整體延遲仍然是所有任務處理時間的總和,但執行間隔的值conv2d_232_U0與第二個卷積層的執行周期數相匹配。該模塊的吞吐量是第二個卷積層執行間隔的倒數。
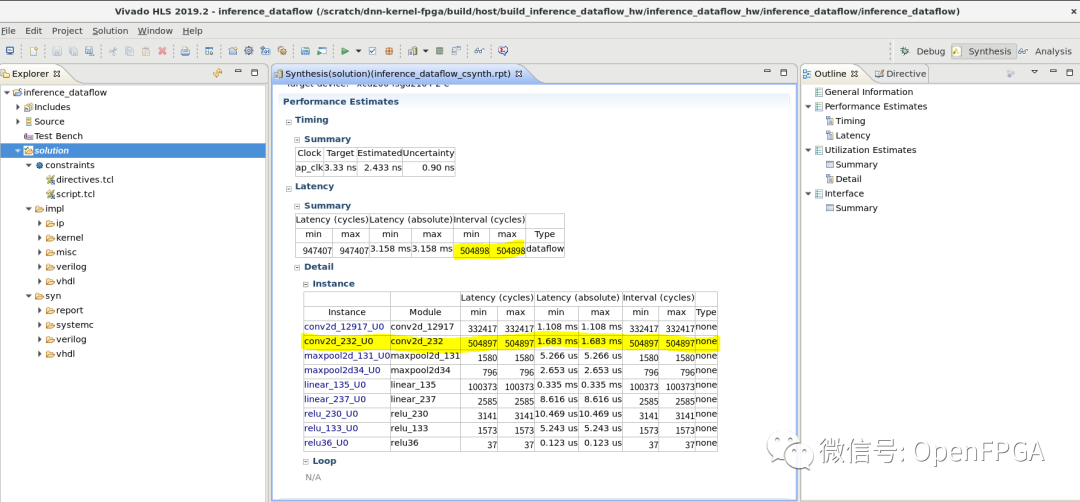
正如本文開頭所解釋的,conv2d_232_U0處理時間成為此任務并行化后電路中的瓶頸。任務并行化的速度提升率為947407 / 504898 = 1.88倍。
通過這種方式,我們能夠確認 HLS 能夠正確實現任務并行化。
總結
在本文中,我們通過提取任務并行性來加速處理。本來conv2占用了一半以上的執行時間,所以提速幅度不到2倍,如果設置為N,最大提速為N倍。
在下一篇文章中,我們將通過對卷積層應用數據并行化和循環并行化來解決每一層處理時間的不平衡。
-
FPGA
+關注
關注
1626文章
21665瀏覽量
601808 -
人工智能
+關注
關注
1791文章
46845瀏覽量
237537 -
C++
+關注
關注
22文章
2104瀏覽量
73488 -
模型
+關注
關注
1文章
3171瀏覽量
48711 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
原文標題:從FPGA說起的深度學習(六)-任務并行性
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于HLS之任務級并行編程
FPGA在人工智能中的應用有哪些?
FPGA做深度學習能走多遠?
Python中的并行性和并發性分析
什么是深度學習?使用FPGA進行深度學習的好處?
算法隱含并行性的物理模型
如何在不需要特殊庫或類的情況下實現C代碼并行性?
從FPGA說起的深度學習:數據并行性






 工商網監
工商網監
評論