 算法時空復雜度分析實用指南2
算法時空復雜度分析實用指南2
計算平均時間復雜度最常用的方法叫做「聚合分析」,思路如下 :
給你一個空的MonotonicQueue,然后請你執行N個push, pop組成的操作序列,請問這N個操作所需的總時間復雜度是多少?
因為這N個操作最多就是讓O(N)個元素入隊再出隊,每個元素只會入隊和出隊一次,所以這N個操作的總時間復雜度是O(N)。
那么平均下來,一次操作的時間復雜度就是O(N)/N = O(1),也就是說push和pop方法的平均時間復雜度都是O(1)。
類似的,想想之前說的數據結構擴容的場景,也許N次操作中的某一次操作恰好觸發了擴容,導致時間復雜度提高,但總的時間復雜度依然保持在O(N),所以均攤到每一次操作上,其平均時間復雜度依然是O(1)。
遞歸算法分析
對很多人來說,遞歸算法的時間復雜度是比較難分析的。但如果你有 框架思維,明白所有遞歸算法的本質是樹的遍歷,那么分析起來應該沒什么難度。
計算算法的時間復雜度,無非就是看這個算法做了些啥事兒,花了多少時間。而遞歸算法做的事情就是遍歷一棵遞歸樹,在樹上的每個節點所做一些事情罷了。
所以:
遞歸算法的時間復雜度 = 遞歸的次數 x 函數本身的時間復雜度
遞歸算法的空間復雜度 = 遞歸堆棧的深度 + 算法申請的存儲空間
或者再說得直觀一點:
遞歸算法的時間復雜度 = 遞歸樹的節點個數 x 每個節點的時間復雜度
遞歸算法的空間復雜度 = 遞歸樹的高度 + 算法申請的存儲空間
函數遞歸的原理是操作系統維護的函數堆棧,所以遞歸棧的空間消耗也需要算在空間復雜度之內,這一點不要忘了。
首先說一下動態規劃算法 ,還是拿前文 動態規劃核心框架中講到的湊零錢問題舉例,它的暴力遞歸解法主體如下:
int dp(int[] coins, int amount) {
// base case
if (amount == 0) return 0;
if (amount < 0) return -1;
int res = Integer.MAX_VALUE;
// 時間 O(K)
for (int coin : coins) {
int subProblem = dp(coins, amount - coin);
if (subProblem == -1) continue;
res = Math.min(res, subProblem + 1);
}
return res == Integer.MAX_VALUE ? -1 : res;
}
當amount = 11, coins = [1,2,5]時,該算法的遞歸樹就長這樣:
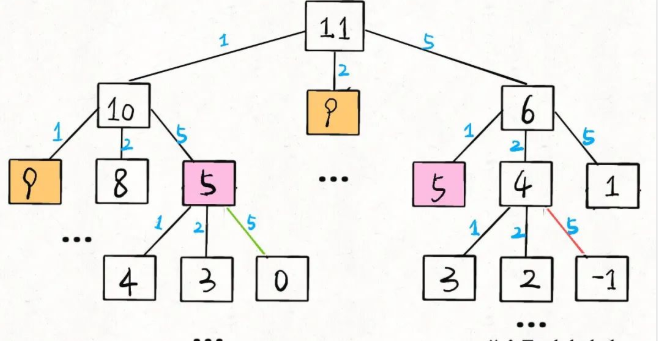
剛才說了這棵樹上的節點個數為O(K^N),那么每個節點消耗的時間復雜度是多少呢?其實就是這個dp函數本身的復雜度。
你看dp函數里面有個 for 循環遍歷長度為K的coins列表,所以函數本身的復雜度為O(K),故該算法總的時間復雜度為:
O(K^N) * O(K) = O(K^(N+1))
當然,之前也說了,這個復雜度只是一個粗略的上界,并不準確,真實的效率肯定會高一些。
這個算法的空間復雜度很容易分析:
dp函數本身沒有申請數組之類的,所以算法申請的存儲空間為O(1);而dp函數的堆棧深度為遞歸樹的高度O(N),所以這個算法的空間復雜度為O(N)。
暴力遞歸解法的分析結束,但這個解法存在重疊子問題,通過備忘錄消除重疊子問題的冗余計算之后,相當于在原來的遞歸樹上進行剪枝:
// 備忘錄,空間 O(N)
memo = new int[N];
Arrays.fill(memo, -666);
int dp(int[] coins, int amount) {
if (amount == 0) return 0;
if (amount < 0) return -1;
// 查備忘錄,防止重復計算
if (memo[amount] != -666)
return memo[amount];
int res = Integer.MAX_VALUE;
// 時間 O(K)
for (int coin : coins) {
int subProblem = dp(coins, amount - coin);
if (subProblem == -1) continue;
res = Math.min(res, subProblem + 1);
}
// 把計算結果存入備忘錄
memo[amount] = (res == Integer.MAX_VALUE) ? -1 : res;
return memo[amount];
}
通過備忘錄剪掉了大量節點之后,雖然函數本身的時間復雜度依然是O(K),但大部分遞歸在函數開頭就立即返回了,根本不會執行到 for 循環那里,所以可以認為遞歸函數執行的次數(遞歸樹上的節點)減少了,從而時間復雜度下降。
剪枝之后還剩多少節點呢?根據備忘錄剪枝的原理,相同「狀態」不會被重復計算,所以剪枝之后剩下的節點數就是「狀態」的數量,即memo的大小N。
所以,對于帶備忘錄的動態規劃算法的時間復雜度,以下幾種理解方式都是等價的:
遞歸的次數 x 函數本身的時間復雜度
= 遞歸樹節點個數 x 每個節點的時間復雜度
= 狀態個數 x 計算每個狀態的時間復雜度
= 子問題個數 x 解決每個子問題的時間復雜度
= O(N) * O(K)
= O(NK)
像「狀態」「子問題」屬于動態規劃類型問題特有的詞匯,但時間復雜度本質上還是遞歸次數 x 函數本身復雜度,換湯不換藥罷了。反正你愛怎么說怎么說吧,別把自己繞進去就行。
備忘錄優化解法的空間復雜度也不難分析:
dp函數的堆棧深度為「狀態」的個數,依然是O(N),而算法申請了一個大小為O(N)的備忘錄memo數組,所以總的空間復雜度為O(N) + O(N) = O(N)。
雖然用 Big O 表示法來看,優化前后的空間復雜度相同,不過顯然優化解法消耗的空間要更多,所以用備忘錄進行剪枝也被稱為「用空間換時間」。
如果你把自頂向下帶備忘錄的解法進一步改寫成自底向上的迭代解法:
int coinChange(int[] coins, int amount) {
// 空間 O(N)
int[] dp = new int[amount + 1];
Arrays.fill(dp, amount + 1);
dp[0] = 0;
// 時間 O(KN)
for (int i = 0; i < dp.length; i++) {
for (int coin : coins) {
if (i - coin < 0) continue;
dp[i] = Math.min(dp[i], 1 + dp[i - coin]);
}
}
return (dp[amount] == amount + 1) ? -1 : dp[amount];
}
該解法的時間復雜度不變,但已經不存在遞歸,所以空間復雜度中不需要考慮堆棧的深度,只需考慮dp數組的存儲空間,雖然用 Big O 表示法來看,該算法的空間復雜度依然是O(N),但該算法的實際空間消耗是更小的,所以自底向上迭代的動態規劃是各方面性能最好的。
接下來說一下回溯算法 ,需要你看過前文 回溯算法秒殺排列組合問題的 9 種變體,下面我會以標準的全排列問題和子集問題的解法為例,分析一下其時間復雜度。
先看標準全排列問題 (元素無重不可復選)的核心函數backtrack:
// 回溯算法計算全排列
void backtrack(int[] nums) {
// 到達葉子節點,收集路徑值,時間 O(N)
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
// 非葉子節點,遍歷所有子節點,時間 O(N)
for (int i = 0; i < nums.length; i++) {
if (used[i]) {
// 剪枝邏輯
continue;
}
// 做選擇
used[i] = true;
track.addLast(nums[i]);
backtrack(nums);
// 取消選擇
track.removeLast();
used[i] = false;
}
}
當nums = [1,2,3]時,backtrack其實在遍歷這棵遞歸樹:

假設輸入的nums數組長度為N,那么這個backtrack函數遞歸了多少次?backtrack函數本身的復雜度是多少?
先看看backtrack函數本身的時間復雜度,即樹中每個節點的復雜度。
對于非葉子節點,會執行 for 循環,復雜度為O(N);對于葉子節點,不會執行循環,但將track中的值拷貝到res列表中也需要O(N)的時間, 所以backtrack函數本身的時間復雜度為O(N) 。
PS:函數本身(每個節點)的時間復雜度并不是樹枝的條數。看代碼,每個節點都會執行整個 for 循環,所以每個節點的復雜度都是
O(N)。
再來看看backtrack函數遞歸了多少次,即這個排列樹上有多少個節點。
第 0 層(根節點)有P(N, 0) = 1個節點。
第 1 層有P(N, 1) = N個節點。
第 2 層有P(N, 2) = N x (N - 1)個節點。
第 3 層有P(N, 3) = N x (N - 1) x (N - 2)個節點。
以此類推,其中P就是我們高中學過的排列數函數。
全排列的回溯樹高度為N,所以節點總數為:
P(N, 0) + P(N, 1) + P(N, 2) + ... + P(N, N)
這一堆排列數累加不好算,粗略估計一下上界吧,把它們全都擴大成P(N, N) = N!, 那么節點總數的上界就是O(N*N!) 。
現在就可以得出算法的總時間復雜度:
遞歸的次數 x 函數本身的時間復雜度
= 遞歸樹節點個數 x 每個節點的時間復雜度
= O(N*N!) * O(N)
= O(N^2 * N!)
當然,由于計算節點總數的時候我們為了方便計算把累加項擴大了很多,所以這個結果肯定也是偏大的,不過用來描述復雜度的上界還是可以接受的。
分析下該算法的空間復雜度:
backtrack函數的遞歸深度為遞歸樹的高度O(N),而算法需要存儲所有全排列的結果,即需要申請的空間為O(N*N!)。 所以總的空間復雜度為O(N*N!) 。
最后看下標準子集問題 (元素無重不可復選)的核心函數backtrack:
// 回溯算法計算所有子集(冪集)
void backtrack(int[] nums, int start) {
// 每個節點的值都是一個子集,O(N)
res.add(new LinkedList<>(track));
// 遍歷子節點,O(N)
for (int i = start; i < nums.length; i++) {
// 做選擇
track.addLast(nums[i]);
backtrack(nums, i + 1);
// 撤銷選擇
track.removeLast();
}
}
當nums = [1,2,3]時,backtrack其實在遍歷這棵遞歸樹:

假設輸入的nums數組長度為N,那么這個backtrack函數遞歸了多少次?backtrack函數本身的復雜度是多少?
先看看backtrack函數本身的時間復雜度,即樹中每個節點的復雜度。
backtrack函數在前序位置都會將track列表拷貝到res中,消耗O(N)的時間,且會執行一個 for 循環,也消耗O(N)的時間, 所以backtrack函數本身的時間復雜度為O(N) 。
再來看看backtrack函數遞歸了多少次,即這個排列樹上有多少個節點。
那就直接看圖一層一層數唄:
第 0 層(根節點)有C(N, 0) = 1個節點。
第 1 層有C(N, 1) = N個節點。
第 2 層有C(N, 2)個節點。
第 3 層有C(N, 3)個節點。
以此類推,其中C就是我們高中學過的組合數函數。
由于這棵組合樹的高度為N,組合數求和公式是高中學過的, 所以總的節點數為2^N :
C(N, 0) + C(N, 1) + C(N, 2) + ... + C(N, N) = 2^N
就算你忘記了組合數求和公式,其實也可以推導出來節點總數:因為N個元素的所有子集(冪集)數量為2^N,而這棵樹的每個節點代表一個子集,所以樹的節點總數也為2^N。
那么,現在就可以得出算法的總復雜度:
遞歸的次數 x 函數本身的時間復雜度
= 遞歸樹節點個數 x 每個節點的時間復雜度
= O(2^N) * O(N)
= O(N*2^N)
分析下該算法的空間復雜度:
backtrack函數的遞歸深度為遞歸樹的高度O(N),而算法需要存儲所有子集的結果,粗略估算下需要申請的空間為O(N*2^N), 所以總的空間復雜度為O(N*2^N) 。
到這里,標準排列/子集問題的時間復雜度就分析完了,前文回溯算法秒殺排列組合問題的 9 種變體中的其他問題變形都可以按照類似的邏輯分析,這些就留給你自己分析吧。
最后總結
本文篇幅較大,我簡單總結下重點:
1、Big O 標記代表一個函數的集合,用它表示時空復雜度時代表一個上界,所以如果你和別人算的復雜度不一樣,可能你們都是對的,只是精確度不同罷了。
2、時間復雜度的分析不難,關鍵是你要透徹理解算法到底干了什么事。非遞歸算法中嵌套循環的復雜度依然可能是線性的;數據結構 API 需要用平均時間復雜度衡量性能;遞歸算法本質是遍歷遞歸樹,時間復雜度取決于遞歸樹中節點的個數(遞歸次數)和每個節點的復雜度(遞歸函數本身的復雜度)。
好了,能看到這里,真得給你鼓掌。需要說明的是,本文給出的一些復雜度都是比較粗略的估算,上界都不是很「緊」,如果你不滿足于粗略的估算,想計算更「緊」更精確的上界,就需要比較好的數學功底了。不過從面試筆試的角度來說,掌握這些基本分析技術已經足夠應對了。
發布評論請先 登錄
相關推薦
時間復雜度為 O(n^2) 的排序算法

基于紋理復雜度的快速幀內預測算法
時間復雜度是指什么
LDPC碼低復雜度譯碼算法研究

圖像復雜度對信息隱藏性能影響分析
如何求遞歸算法的時間復雜度
常見機器學習算法的計算復雜度
算法時空復雜度分析實用指南(上)
算法時空復雜度分析實用指南(下)
如何計算時間復雜度





 工商網監
工商網監
評論