 MLPerf 3.0最新發榜,戴爾AI和邊緣服務器拿下歷史最好成績
MLPerf 3.0最新發榜,戴爾AI和邊緣服務器拿下歷史最好成績

北美時間4月5日,全球權威 AI 基準測試 MLPerf 3.0 最新結果正式公布,戴爾新一代AI與邊緣計算服務器取得有史以來最好成績:
數據中心賽道,戴爾新一代GPU服務器PowerEdge XE9680斬獲3項第一、9項第二;
邊緣計算賽道,戴爾PowerEdge XR系列邊緣計算服務器拿下10項第一。
恭喜戴爾!
MLPerf由ML Commons聯盟組織,是全球最知名、參與度最高的AI計算基準測試,包含Training(訓練)和Inference(推理)兩大領域。MLPerf選擇AI各個熱門領域的經典模型,在滿足技術規范前提下(如訓練精度、延遲等),對各大廠商的硬件、軟件和服務的訓練和推理性能提供公平的評估。
最新公布的AI推理基準測試MLPerf Inference v3.0,包含圖像分類ResNet-50、目標檢測RetinaNet、醫療圖像3D U-Net、語音識別RNN-T、自然語言處理BERT-Large、推薦系統DLRM等6個模型賽道,匯集了來自全球25個廠商超過6700條性能數據,以及2400條性能功耗數據。
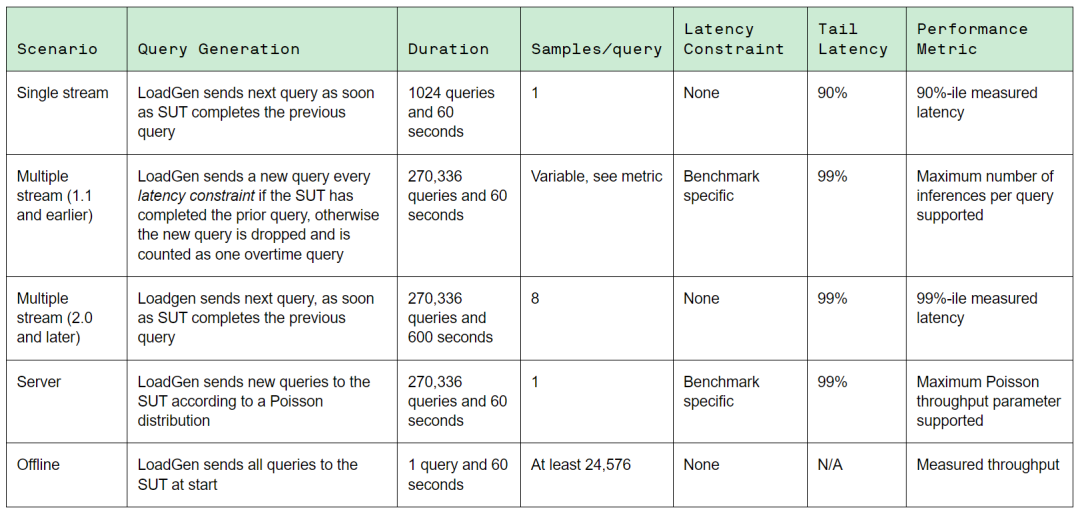
MLPerf Inference v3.0的AI業務場景
在此次MLPerf Inference v3.0測試中,戴爾提交了27種不同的服務器配置,共計255項測試數據。產品涵蓋PowerEdge XE9680、R750xa、XR7620、XR5610等型號,參測的GPU型號包括NVIDIA H100、A100、A30、L4、T4、A2以及高通AI加速卡等,具有廣泛的選型參考性。
數據中心賽道表現
在MLPerf Inference最受關注的數據中心基準測試(Datacenter closed)中,戴爾16G PowerEdge服務器XE9680首次亮相便斬獲優異成績。
8卡H100配置的PowerEdge XE9680參加了12項測試,所有測試成績均位居前2,其中在RetinaNet Server(目標檢測)、RetinaNet Offine(目標檢測)和RNN-T Server(語音識別)三個項目賽道皆拿下第1名的最優成績。
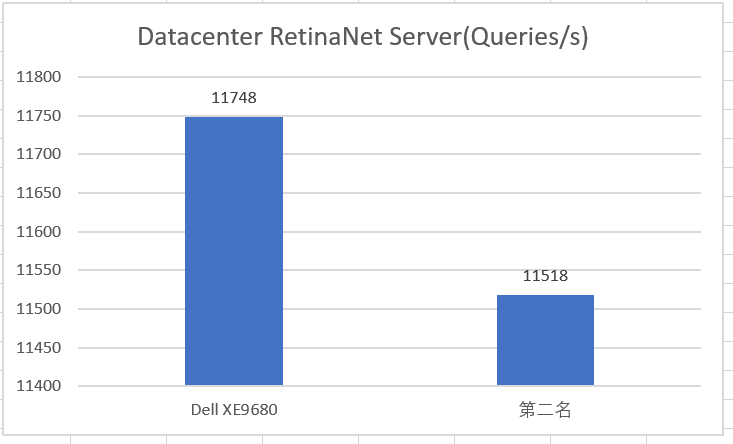
Datacenter RetinaNet Server測試數據
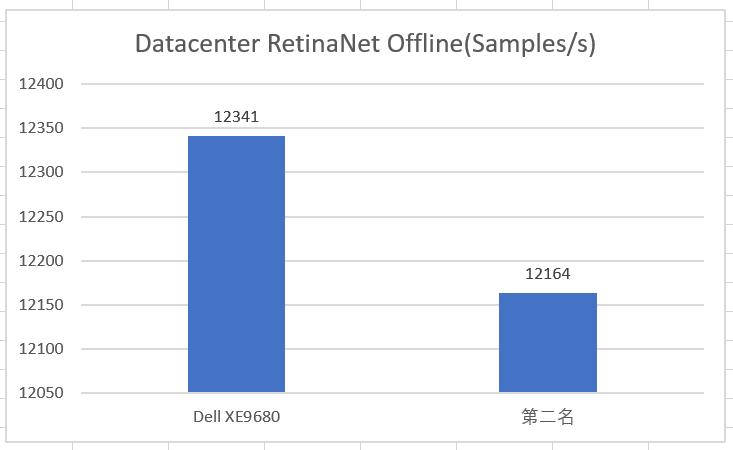
Datacenter RetinaNet Offline測試數據
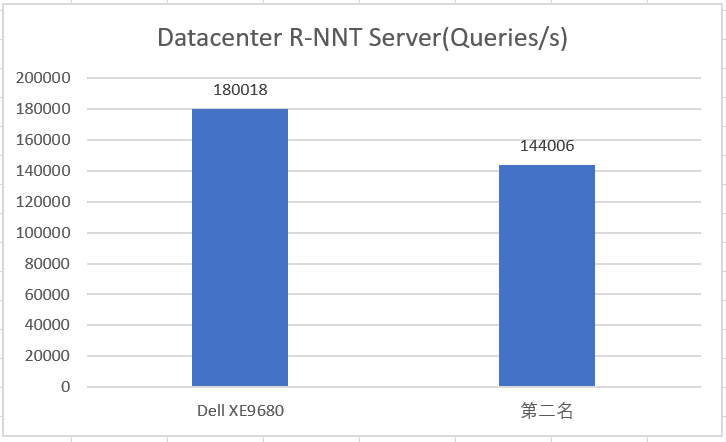
Datacenter R-NNT Server測試數據
同上一期的MLPerf Inference v2.1相比,PowerEdge XE9680將Dell在各個項目的最好成績分別提升了3倍-8.4倍。
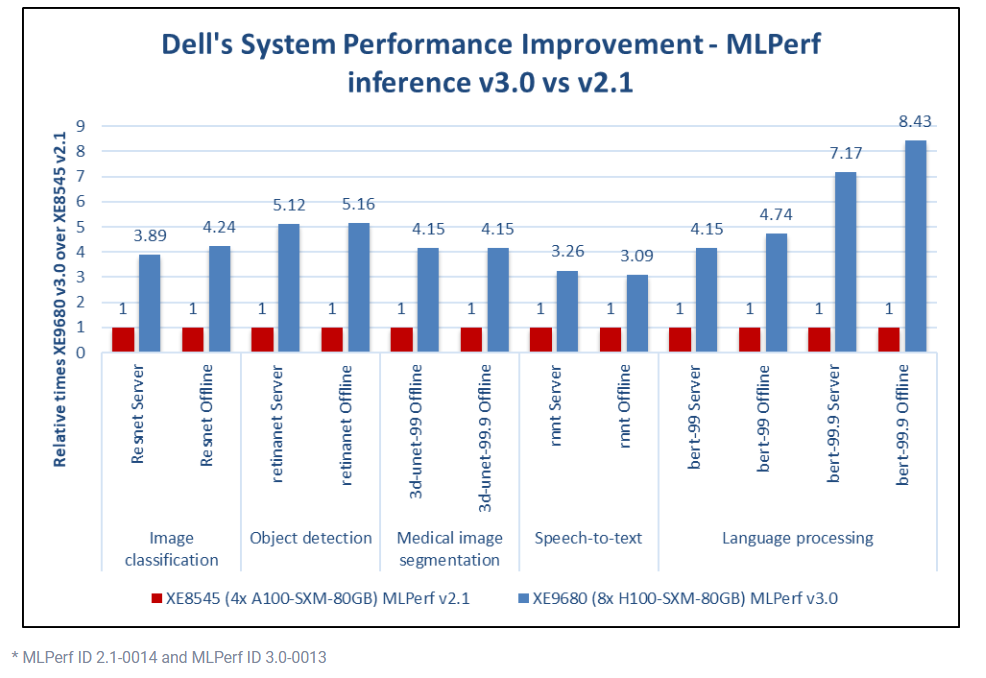
戴爾的MLPerf Inference v3.0
與Inference v2.1成績對比
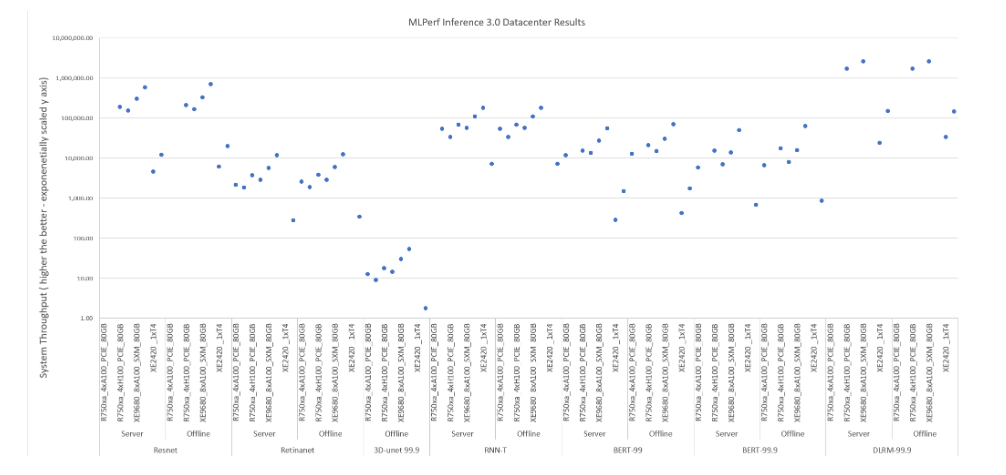
MLPerf Inference v3.0 Datacenter
全部Dell機型測試數據
邊緣計算賽道表現
邊緣計算是MLPerf關注的另一類AI推理的應用場景,有別于數據中心對極致算力的最求,邊緣計算場景對于計算設備部署的環境要求更加多元化,也更加看重計算設備的功耗與成本。因此,在滿足AI計算吞吐和延遲性能要求的前提下,提供更高性價比以及性能功耗比的AI計算解決方案,是戴爾在邊緣AI計算重點關注的內容。
在此次MLPerf Inference v3.0 Edge closed power測試中(主要衡量邊緣AI計算的性能功耗比),戴爾XR系列邊緣計算優化服務器在全部14項測試中取得了10個項目的最佳成績。其中, PowerEdge XR5610邊緣計算優化服務器搭配NVIDIA最新發布的L4 GPU,取得9個項目第一,PowerEdge XR4000搭配NVIDIA A2 GPU,在BERT 99 Offline項目中取得了最佳成績。
* Dell XR5610參加的9個項目分別是ResNet Single Stream、Resnet Multi Stream、RetinaNet Single Stream,、RetinaNet Offline、3D-UNet 99 Single Stream、3D-UNet 99 Offline、3D-UNet 99.9 Offline、RNN-T Single Stream、BERT-99 Single Stream。
PowerEdge XR5610
PowerEdge XR4000
NVIDIA L4是一款單寬GPU加速卡,專為AI視頻和生成式AI用例而設計,較上一代GPU實現了2.7倍的生成式AI性能提升。Dell PowerEdge服務器在今年一季度開始提供對L4的選型支持。
以此次AI Inference v3.0 Edge的測試項目中的圖像分類ResNet-50與自然語言處理BERT-99為例,L4的推理計算性能分別達到T4的2.1倍和2.13倍。而同A10相比,L4絕大多數的規格指標與A10非常接近,功耗卻不到其一半,同時實現了大量成本節約。L4的發布,將成為未來AI推理計算具備高競爭力的GPU選型。
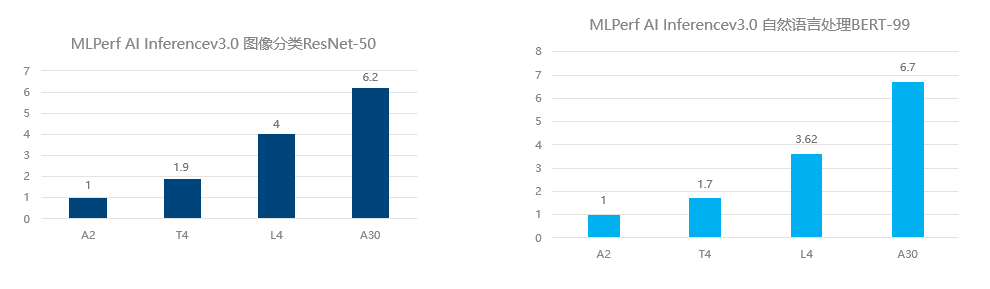
L4與T4 AI推理性能對比
當下,ChatGPT帶動了全球對AI大模型以及基于AI大模型的AIGC(人工智能內容生成)的關注與投資熱潮。與之前的AI小模型相比,以ChatGPT為代表的大規模預訓練模型,參數規模增加了100倍-1000倍。訓練如此龐大的AI大模型需要更大的AI計算集群,以及更多的訓練數據集。
以OpenAI的GPT為例,GPT-3擁有1750億參數,2020年GPT-3發布時訓練該模型使用了超過10000張NVIDIA GPU卡。而根據第三方測算,如果使用1024張A100/A800 GPU訓練GPT-3,仍然需要超過一個月的時間。
隨著AIGC時代的帶來,人工智能產業化對于AI算力的需求將被帶到一個新的高度。在本次MLPerf Inference v3.0測試中取得優異成績的PowerEdge XE9680戴爾專為復雜計算和 AI/ML/DL 以及 HPC 密集型工作負載而構建,可以快速開發、訓練及部署像ChatGPT這樣的大型機器學習模型,助推更多AIGC場景快速落地。
PowerEdge XE9680
此外,AI與邊緣的融合是未來AI計算的趨勢之一,越來越多的AI計算負載特別是AI推理計算將會出現在邊緣側。邊緣端IT設備的部署環境千差萬別,有的時候很難像核心數據中心擁有同樣完備的機房環境,可能會面臨更加復雜、惡劣的設備運行環境。
戴爾XR系列服務器對于高溫、低溫、海拔、防塵、抗震的運行環境有更強的適應能力,通過了電信和海事行業標準。機箱深度通常只有通用機架服務器的一半左右,機器外形更加精巧緊湊。
此次參加AI Inference v3.0 Edge項目測試的XR系列服務器,是戴爾科技專為面向邊緣計算場景設計與優化的服務器,此前已發布了XE2420、XR12、XR11、XR4000等產品,今年陸續會有更多新品發布,請大家拭目以待!
-
戴爾
+關注
關注
5文章
621瀏覽量
39942 -
服務器
+關注
關注
12文章
9029瀏覽量
85207 -
AI
+關注
關注
87文章
30239瀏覽量
268479 -
邊緣計算
+關注
關注
22文章
3070瀏覽量
48660 -
邊緣服務器
+關注
關注
0文章
15瀏覽量
2296
原文標題:MLPerf 3.0最新發榜,戴爾AI和邊緣服務器拿下歷史最好成績!
文章出處:【微信號:戴爾企業級解決方案,微信公眾號:戴爾企業級解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
研華科技打造整體邊緣AI服務器解決方案
戴爾11月將推出搭載Blackwell AI芯片的服務器
什么是AI服務器?AI服務器的優勢是什么?
戴爾上調年度業績預期,AI服務器需求強勁推動股價上漲
智能邊緣服務器 --開啟計算新時代

智能邊緣服務器:前沿觸角,掌控未來

凌華智能推出全新AI 邊緣服務器MEC-AI7400 (AI Edge Server)系列
英偉達新業務動向:AI服務器市場的新變局
耐能推出最新的邊緣AI服務器及內置耐能AI芯片的PC設備
中文大模型測評基準SuperCLUE:商湯日日新5.0,刷新國內最好成績

戴爾和鴻海成AI服務器市場主要客戶,驅動市場增長
邊緣計算新篇章:亞馬遜云科技海外服務器服務成就全球創新






 工商網監
工商網監
評論