") 從BLIP-2到SAM視覺語義金字塔+ChatGPT
從BLIP-2到SAM視覺語義金字塔+ChatGPT
8G GPU顯存即可以運(yùn)行
代碼鏈接(已開源):h
https://github.com/showlab/Image2Paragraph
動機(jī):
怎么把圖片表示成高質(zhì)量文本一直是個熱門的問題。傳統(tǒng)的思路Show,and Tell 等 Image Caption和Dense Caption 等都是依賴大量的人工標(biāo)注。首先依靠諸如亞馬遜AMT( 亞非拉大兄弟們)等標(biāo)注平臺給每張圖一人寫一段描述。其中添加了一系列規(guī)則,諸如名詞數(shù)目,顏色等等。通常用一句簡短的話來描述一張圖。
然而,這種樸素的標(biāo)記思路造成了嚴(yán)重的One-to-many問題。如一張圖對應(yīng)很多文本。由于圖片和文本之間信息的不對稱性,在這類數(shù)據(jù)上訓(xùn)練的結(jié)果很容易陷入平凡解。(Pretrain中也經(jīng)常遇到的問題)
而LLM(大語言模型)尤其是ChatGPT展現(xiàn)出來的邏輯能力讓人望塵莫及。我們驚訝發(fā)現(xiàn), 把Bounding Box 和 Object信息給到GPT4, GPT4很自然的能推理出物體之間的位置關(guān)系,甚至想像出物體之間的聯(lián)系。
因此一個很自然的想法就是, 用GPT4對每張圖生成高信息量的段落,F(xiàn)rom One-to-many to one-to-one
做法:
低階語義抽取:
Image Caption, Dense Caption, Object Detection, Segement Anything 等等統(tǒng)一當(dāng)成視覺理解組件。
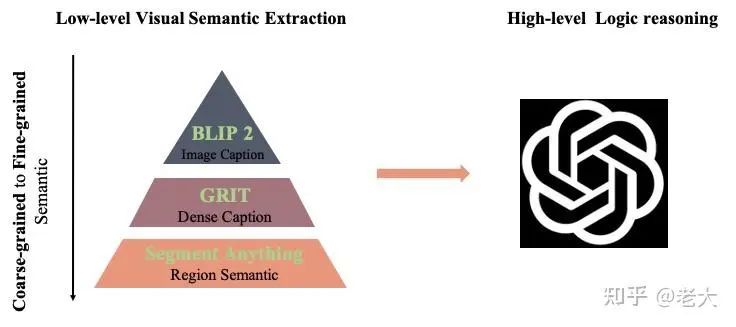
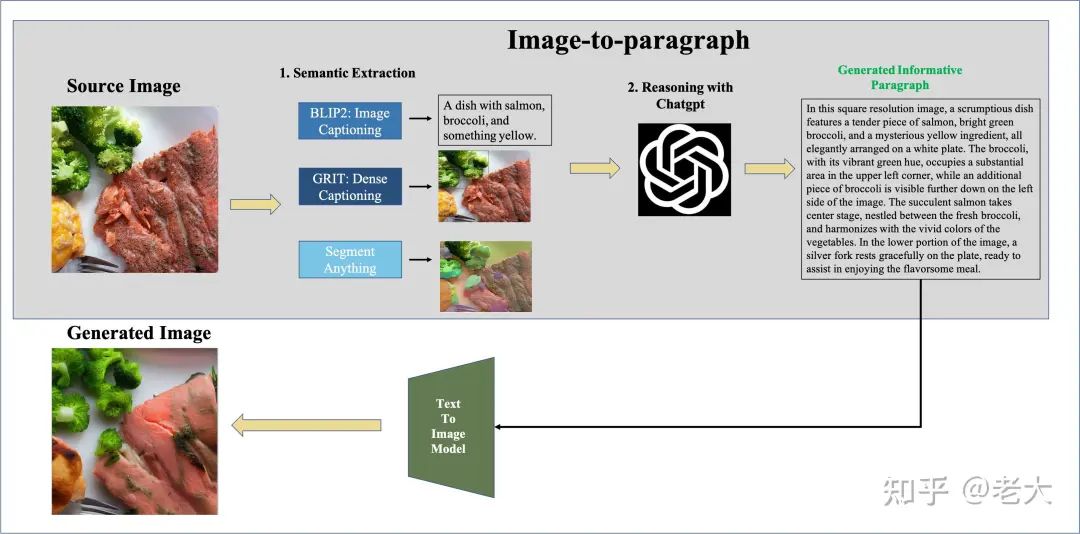
如圖所示,首先用BLIP2 得到一張圖的Coars-grained Caption信息。再用 GRIT得到Dense Caption信息,最終用Segment Anything 去得到Fine- grained Region-level Semantic.
高階推理:
把金字塔視覺語義給到ChatGPT,讓ChatGPT去推理物體之間的關(guān)系和物體的物質(zhì)信息等,最終生成一個高質(zhì)量Unique的文本段落。
可視化:
最后對生成的段落,放進(jìn)Control Net生成一張重構(gòu)的圖。
實驗:
最后是一些運(yùn)行結(jié)果:
對生成的段落用ControlNet生成新圖片。



Region-level Semantic:
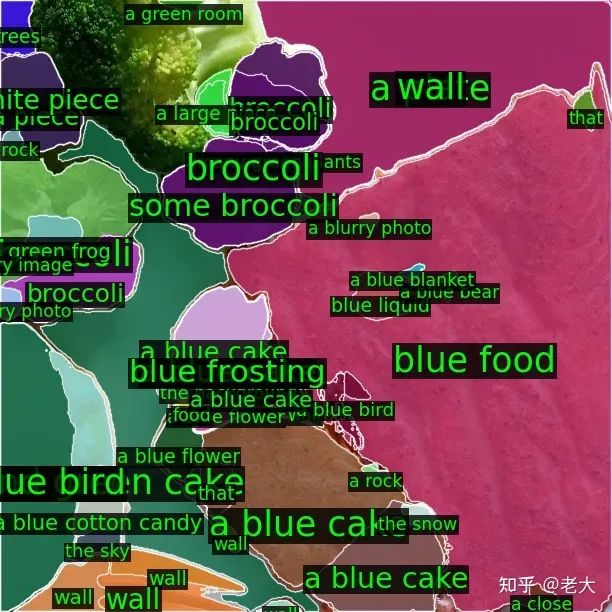
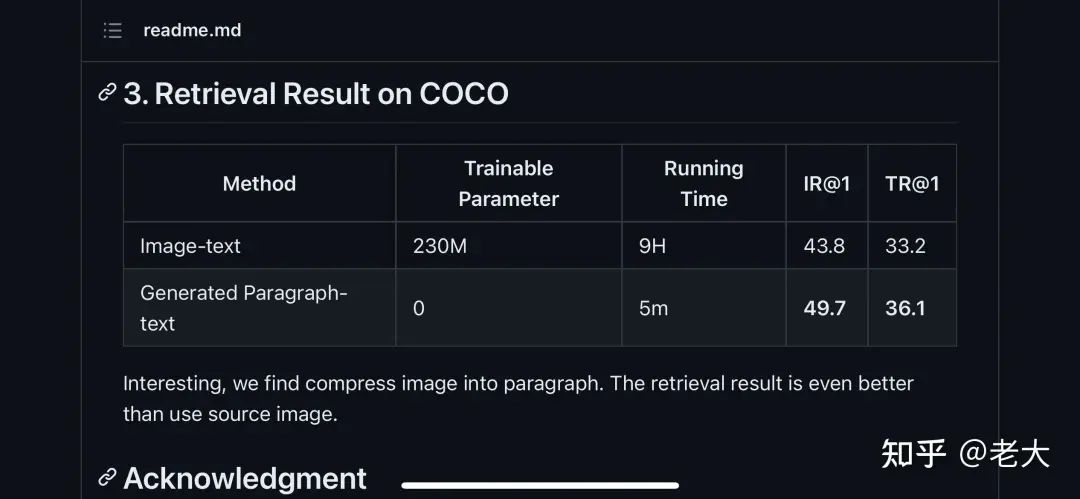
最后有意思的是:
當(dāng)我們把圖片變成文本之后。不需要訓(xùn)練的情況下,檢索效果竟然好與在COCO上 Train的結(jié)果。
一些呼之欲出的問題即將到來:
現(xiàn)有Vision- language Pretrain需不需要新的 Data collection 范式?
現(xiàn)有的Image- Text 數(shù)據(jù)集尤其是Caption數(shù)據(jù)需不需要Refine?
參考:
Show,And Tell.GRIT.ChatGPT.Segment Anything.ControlNet.Blip2.
審核編輯 :李倩
-
SAM
+關(guān)注
關(guān)注
0文章
112瀏覽量
33503 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24649 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1549瀏覽量
7507
原文標(biāo)題:從BLIP-2到SAM視覺語義金字塔+ChatGPT= 把圖片變文本段落, 8G顯存即可Run
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于近似高斯金字塔的視覺注意模型快速算法
基于金字塔模型的地形網(wǎng)格裂縫消除算法
工程師電子制作故事:單片機(jī)控制LED金字塔DIY設(shè)計

圖像金字塔和resize綜合示例_《OpenCV3編程入門》書本配套源代碼
可控特性的金字塔變換

基于梯度方向直方圖與高斯金字塔的車牌模糊漢字識別方法
一種金字塔注意力網(wǎng)絡(luò),用于處理圖像語義分割問題

中國集成電路封裝行業(yè)市場現(xiàn)狀——金字塔的尖頂與基座
如何實現(xiàn)多聚焦圖像融合的拉普拉斯金字塔方法
基于規(guī)范化函數(shù)的深度金字塔模型算法
DIY自制基于51單片機(jī)的LED金字塔






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論