 利用TRansformer進行端到端的目標檢測及跟蹤
利用TRansformer進行端到端的目標檢測及跟蹤
現存的用檢測跟蹤的方法采用簡單的heuristics,如空間或外觀相似性。這些方法,盡管其共性,但過于簡單,不足以建模復雜的變化,如通過遮擋跟蹤。
1
簡要
多目標跟蹤(MOT)任務的關鍵挑戰是跟蹤目標下的時間建模。現存的用檢測跟蹤的方法采用簡單的heuristics,如空間或外觀相似性。這些方法,盡管其共性,但過于簡單,不足以建模復雜的變化,如通過遮擋跟蹤。所以現有的方法缺乏從數據中學習時間變化的能力。

在今天分享中,研究者提出了第一個完全端到端多目標跟蹤框架MOTR。它學習了模擬目標的長距離時間變化。它隱式地執行時間關聯,并避免了以前的顯式啟發式方法。MOTR建立在TRansformer和DETR之上,引入了“跟蹤查詢”的概念。每個跟蹤查詢都會模擬一個目標的整個跟蹤。逐幀傳輸和更新,以無縫地執行目標檢測和跟蹤。提出了時間聚合網絡(Temporal aggregation network)結合多框架訓練來建模長期時間關系。實驗結果表明,MOTR達到了最先進的性能。
2
簡單背景
多目標跟蹤(MOT)是一種視覺目標檢測,其任務不僅是定位每一幀中的所有目標,而且還可以預測這些目標在整個視頻序列中的運動軌跡。這個問題具有挑戰性,因為每一幀中的目標可能會在pool environment中被遮擋,而開發的跟蹤器可能會受到長期和低速率跟蹤的影響。這些復雜而多樣的跟蹤方案在設計MOT解決方案時帶來了重大挑戰。
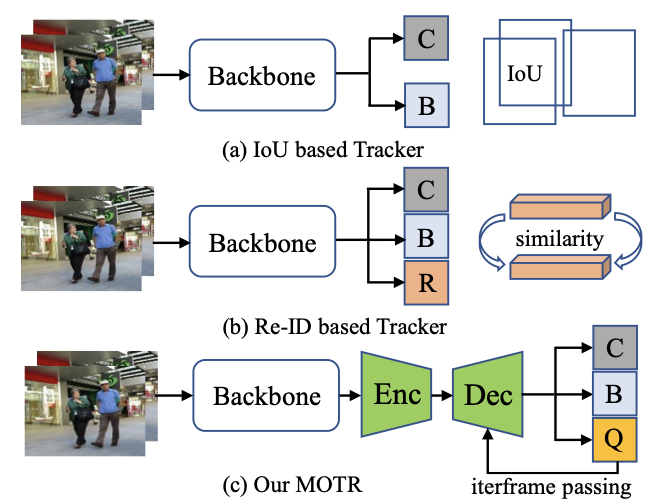
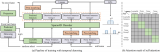
對于基于IoU的方法,計算從兩個相鄰幀檢測到的檢測框的IoU矩陣,重疊高于給定閾值的邊界框與相同的身份相關聯(見上圖(a))。類似地,基于Re-ID的方法計算相鄰幀的特征相似性,并將目標對與高相似性相關起來。此外,最近的一些工作還嘗試了目標檢測和重識別特征學習的聯合訓練(見上圖(b))。
由于DETR的巨大成功,這項工作將“目標查詢”的概念擴展到目標跟蹤模型,在新框架中被稱為跟蹤查詢。每個跟蹤查詢都負責預測一個目標的整個跟蹤。如上圖(c),與分類和框回歸分支并行,MOTR預測每一幀的跟蹤查詢集。
3
新框架分析
最近,DETR通過采用TRansformer成功地進行了目標檢測。在DETR中,目標查詢,一個固定數量的學習位置嵌入,表示一些可能的實例的建議。一個目標查詢只對應于一個使用bipartite matching的對象。考慮到DETR中存在的高復雜性和慢收斂問題,Deformable DETR用多尺度deformable attention取代了self-attention。為了展示目標查詢如何通過解碼器與特征交互,研究者重新制定了Deformable DETR的解碼器。
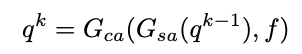
MOTR
在MOTR中,研究者引入了跟蹤查詢和連續查詢傳遞,以完全端到端的方式執行跟蹤預測。進一步提出了時間聚合網絡來增強多幀的時間信息。
DETR中引入的目標(檢測)查詢不負責對特定目標的預測。因此,一個目標查詢可以隨著輸入圖像的變化而預測不同的目標。當在MOT數據集的示例上使用DETR檢測器時,如上圖(a),相同檢測查詢(綠色目標查詢)預測兩個不同幀預測兩個不同的目標。因此,很難通過目標查詢的身份來將檢測預測作為跟蹤值聯系起來。作為一種補救措施,研究者將目標查詢擴展到目標跟蹤模型,即跟蹤查詢。在新的設計中,每個軌跡查詢都負責預測一個目標的整個軌跡。一旦跟蹤查詢與幀中的一個目標匹配,它總是預測目標,直到目標消失(見上圖(b))。
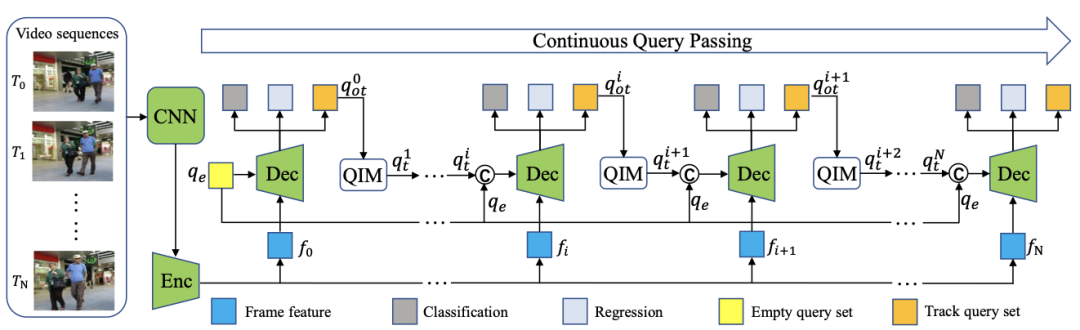
Overall architecture of the proposed MOTR
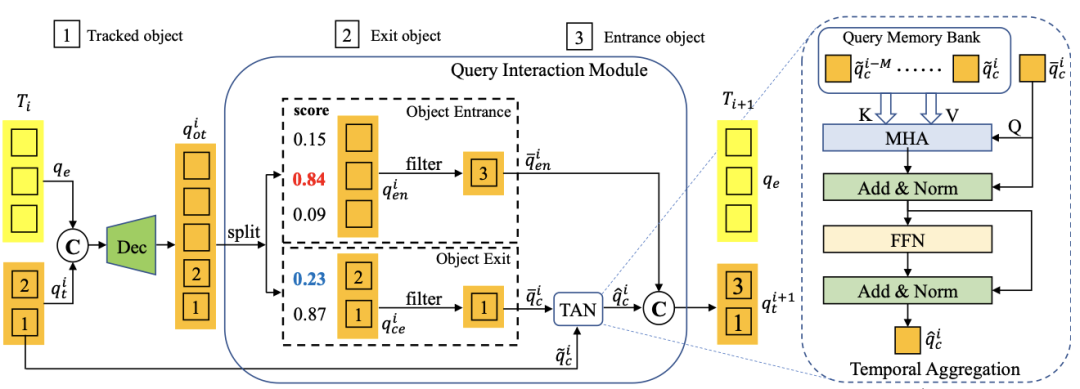
Query Interaction Module
在訓練階段,可以基于對bipartite matching的GTs的監督來實現跟蹤查詢的學習。而對于推斷,研究者使用預測的軌跡分數來確定軌道何時出現和消失。
Overall Optimization
我們詳細描述下MOTR的訓練過程。給定一個視頻序列作為輸入,訓練損失,即track loss,是逐幀計算和逐幀生成的預測。總track loss是由訓練樣本上的所有GT的數量歸一化的所有幀的track loss的總和:
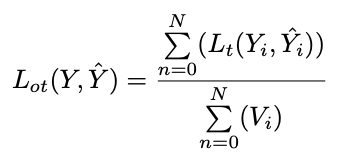
單幀圖像Lt的track loss可表示為:
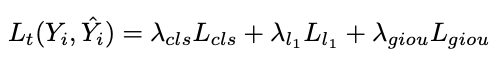
4
實驗
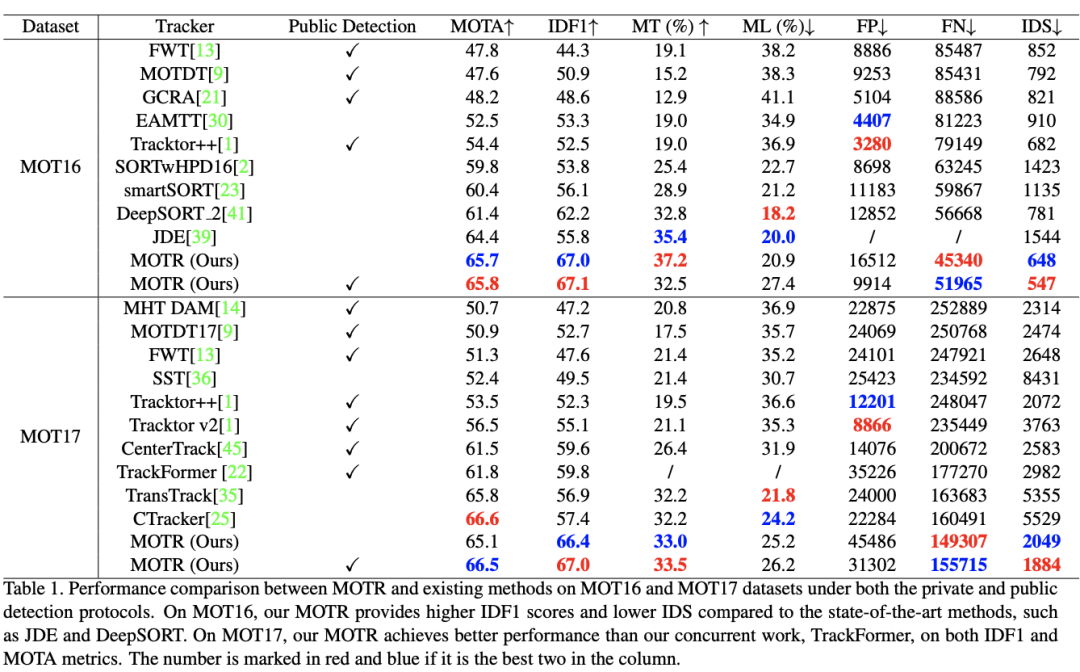
Implementation Details
All the experiments are conducted on PyTorch with 8Tesla V100 GPUs. We use the Deformable-DETR withResNet50 as our basic network. The basic network ispretrained on the COCO detection dataset.We trainour model with the AdamW optimizer for total 200 epochswith the initial learning rate of 2.0 · 10?4. The learning ratedecays to 2.0 · 10?5 at 150 epochs. The batch size is set to1 and each batch contains 5 frames.

The effect of multi-frame continuous query passing on solving ID switch problem. When the length of video sequence is setto two (top), the objects that are occluded will miss and switch the identity. When improving the video sequence length from two to five(bottom), the track will not occur the ID switch problem with the help of enhanced temporal relation.

審核編輯:劉清
-
解碼器
+關注
關注
9文章
1131瀏覽量
40676 -
檢測器
+關注
關注
1文章
860瀏覽量
47651 -
MOT
+關注
關注
0文章
18瀏覽量
6943
原文標題:利用TRansformer進行端到端的目標檢測及跟蹤(附源代碼)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
連接視覺語言大模型與端到端自動駕駛

智己汽車“端到端”智駕方案推出,老司機真的會被取代嗎?
端到端InfiniBand網絡解決LLM訓練瓶頸

Mobileye端到端自動駕駛解決方案的深度解析

恩智浦完整的Matter端到端解決方案

周光:不是真“無圖”,談何端到端

小鵬汽車發布國內首個量產上車的端到端大模型
小鵬汽車發布端到端大模型
佐思汽研發布《2024年端到端自動駕駛研究報告》

理想汽車自動駕駛端到端模型實現

移動協作機器人的RGB-D感知的端到端處理方案
Sparse4D-v3:稀疏感知的性能優化及端到端拓展





 工商網監
工商網監
評論