 什么是 NVLink?
什么是 NVLink?
NVLink 是加速系統中 GPU 和 CPU 處理器的高速互連技術,推動數據和計算加速得出可執行結果。
加速計算是一項曾經只有政府研究實驗室中才有的高性能計算能力。如今,它已成為主流技術。
銀行、汽車制造商、工廠、醫院、零售商等機構需要處理和理解的數據日益增加,他們現在正在采用 AI 超級計算機來處理這些堆積如山的數據。
這些強大、高效的系統如同一條條“超級計算高速公路”。它們在多條并行路徑上同時傳輸數據和計算,可以瞬間得出可執行結果。
GPU 和 CPU 處理器是“公路”沿途的資源,而快速互連通道是通往它們的“匝道”。NVLink 是加速計算互連通道的黃金標準。
那么,什么是 NVLink?
NVLink 是 GPU 和 CPU 之間的高速連接通道。它由一個強大的軟件協議組成,通常通過印在計算機板上的多對導線實現,可以讓處理器以閃電般的速度收發共享內存池中的數據。
如今,第四代 NVLink 連接主機和加速處理器的速度高達每秒 900GB/s。
這是傳統 x86 服務器的互連通道——PCIe 5.0 帶寬的 7 倍多。由于每傳輸 1 字節數據僅消耗 1.3 皮焦,因此 NVLink 的能效是 PCIe 5.0 的 5 倍。
NVLink 的歷史
NVLink 最初作為 NVIDIA P100 GPU 的互連通道推出,之后便與每一代新的 NVIDIA GPU 架構同步發展。

2018 年,NVLink 首次亮相便被用于連接兩臺超級計算機——Summit 和 Sierra 的 GPU 和 CPU,成為了高性能計算領域的焦點。
這兩套安裝在美國橡樹嶺國家實驗室和美國勞倫斯利弗莫爾國家實驗室的系統正在推動藥物研發、自然災害預測等科學領域的發展。
帶寬翻倍,繼續發展
2020 年,第三代 NVLink 將每個 GPU 的最大帶寬翻倍提高至 600GB/s,每個 NVIDIA A100 Tensor Core GPU 中都有十幾條互連通道。
A100 為全球各地企業數據中心、云計算服務和 HPC 實驗室的 AI 超級計算機提供動力。
如今,一個 NVIDIA H100 Tensor Core GPU 中包含 18 條第四代 NVLink 互連通道。這項技術已承擔了一項新的戰略任務——幫助打造全球領先的 CPU 和加速器。
芯片到芯片互聯
NVIDIA NVLink-C2C 是一種板級互連技術,它能夠在單個封裝中將兩個處理器連接成一塊超級芯片。比如它通過連接兩塊 CPU 芯片,使 NVIDIA Grace CPU 超級芯片具有 144 個 Arm Neoverse V2 核心,為云、企業和 HPC 用戶帶來了高能效性能。
NVIDIA NVLink-C2C 還將 Grace CPU 和 Hopper GPU 連接成 Grace Hopper 超級芯片,將用于處理最棘手的 HPC 和 AI 工作的加速計算能力集合到一塊芯片中。
計劃在瑞士國家計算中心投入使用的 AI 超級計算機 Alps 將是首批使用 Grace Hopper 的計算機之一。這套高性能系統將在今年晚些時候上線,用于處理從天體物理學到量子化學等領域的大型科學問題。
Grace 和 Grace Hopper 還非常適合用于提升高要求云計算工作負載的能效。
例如 Grace Hopper 是最適合用于推薦系統的處理器。這些互聯網的經濟引擎需要快速、高效地訪問大量數據,才能每天向數十億用戶提供數萬億條結果。
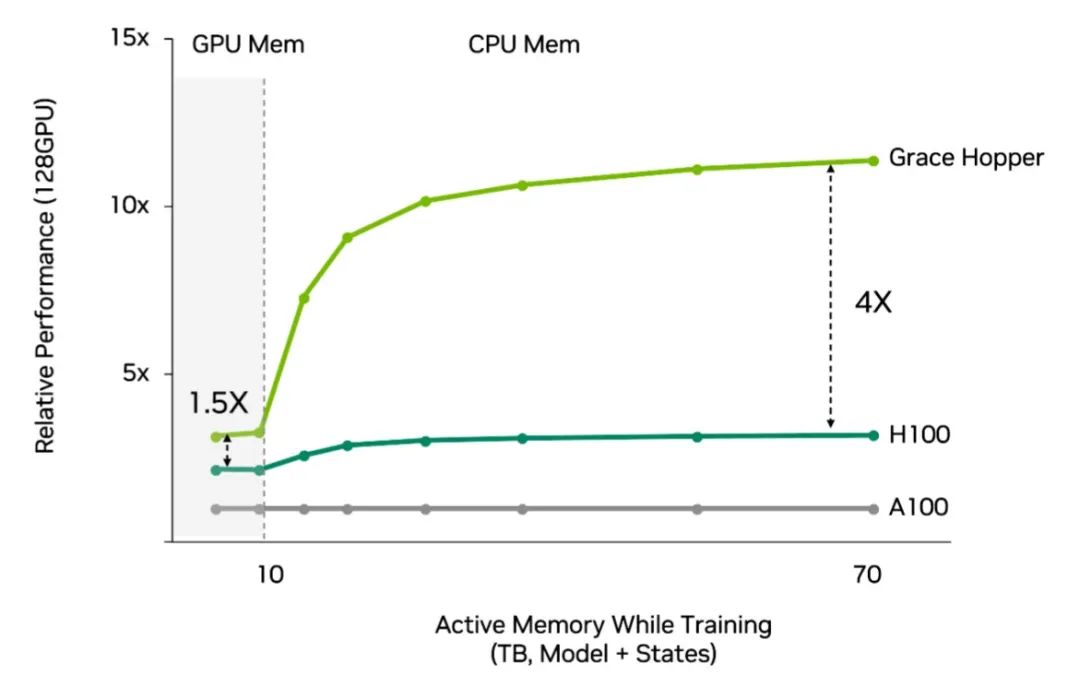
與使用傳統 CPU 的 Hopper 相比,采用 Grace Hopper 的推薦系統的性能提高了 4 倍,并且效率更高。
另外,NVLink 還被用于為汽車制造商提供的強大系統級芯片,包括 NVIDIA Hopper、Grace 和 Ada Lovelace 處理器等。車載計算平臺 NVIDIA DRIVE Thor 將數字儀表板、車載信息娛樂、自動駕駛、泊車等諸多智能功能統一整合到單個架構中。
“樂高式”計算鏈路
NVLink 的作用就像是樂高積木的凸粒和凹槽。它是構建超級系統以處理超大型 HPC 和 AI 工作的基礎。
例如,NVIDIA DGX 系統中的八個 GPU 上的 NVLink 通過 NVSwitch 芯片共享快速、直接的連接。它們共同組成了一個 NVLink 網絡,使服務器中的每一個 GPU 都是一套系統的一部分。
為了獲得更強大的性能,DGX 系統本身可以堆疊成由 32 臺服務器組成的模塊化單元,形成一個強大、高效的計算集群。
用戶可以利用 DGX 內部的 NVLink 網絡與兩者之間的 NVIDIA Quantum-2 InfiniBand 交換以太網,將 32 個 DGX 系統模塊連接成一臺 AI 超級計算機。例如,一臺 NVIDIA DGX H100 SuperPOD 包含 256 個 H100 GPU,可提供最高 1 EXAFLOP 的峰值 AI 性能。
如要進一步提高性能,用戶還可以使用云中的 AI 超級計算機,例如微軟Azure使用數萬個 A100 和 H100 GPU 打造的超級計算機。OpenAI 等團隊正在使用這項服務訓練一些全球最大的生成式 AI 模型。
這再次印證了加速計算的力量。
原文標題:什么是 NVLink?
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3747瀏覽量
90834
原文標題:什么是 NVLink?
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
挑戰英偉達NVLink!英特爾/谷歌等成立聯盟,推出UALink 1.0

分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進
鴻海再獲AI領域大單,獨家供貨英偉達GB200 NVLink交換器
科技巨頭組建“復仇者聯盟”,挑戰英偉達的NVLink技術
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
全面解讀英偉達NVLink技術

什么是NVIDIA?InfiniBand網絡VSNVLink網絡

NVLink的演進:從內部互聯到超級網絡

NVLink技術之GPU與GPU的通信

NVIDIA宣布推出NVIDIA Blackwell平臺以賦能計算新時代
英偉達AI服務器NVLink版與PCIe版有何區別?又如何選擇呢?
深度解讀Nvidia AI芯片路線圖

英偉達推出為中國大陸定制的H20 AI GPU芯片
英偉達和華為/海思主流GPU型號性能參考

英偉達三大AI法寶:CUDA、Nvlink、InfiniBand






 工商網監
工商網監
評論