") 機(jī)器學(xué)習(xí)算法學(xué)習(xí)之特征工程2
機(jī)器學(xué)習(xí)算法學(xué)習(xí)之特征工程2
縮放和歸一化
縮放和歸一化是特征工程中的重要步驟,以確保特征具有類似的比例和范圍。這可以幫助改善一些機(jī)器學(xué)習(xí)算法的性能,并使優(yōu)化過程更快。以下是用于縮放和歸一化的一些常見技術(shù):
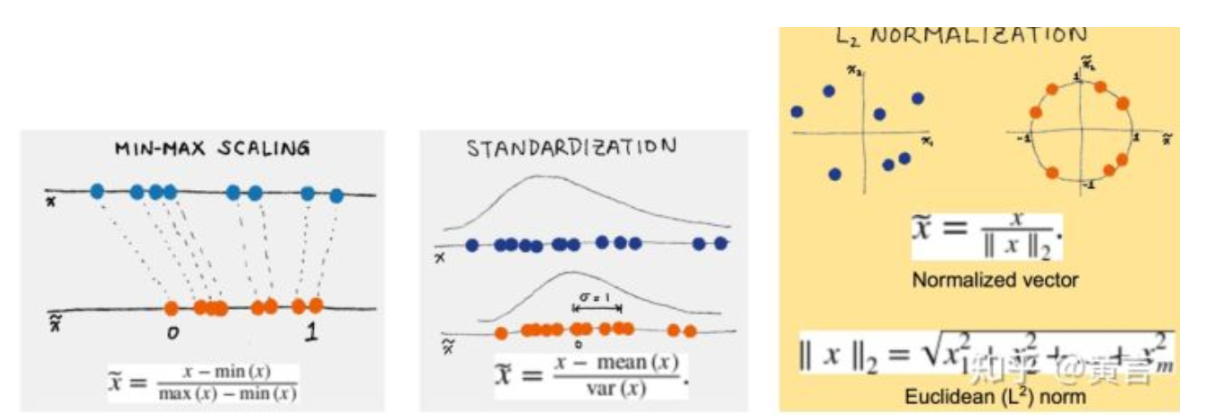
1.標(biāo)準(zhǔn)化:標(biāo)準(zhǔn)化將特征縮放,使其具有零均值和單位方差。這通過從每個(gè)值中減去均值,然后將其除以標(biāo)準(zhǔn)差來完成。結(jié)果值將具有零均值和單位方差。
以下是使用 scikit-learn 的標(biāo)準(zhǔn)化示例:
from sklearn.preprocessing import StandardScaler
# Create a StandardScaler object
scaler = StandardScaler()
# Fit and transform the data
X_scaled = scaler.fit_transform(X)
2.最小-最大縮放:最小-最大縮放將特征縮放到一個(gè)固定的范圍,通常在0和1之間。這通過從每個(gè)值中減去最小值,然后除以范圍來完成。
以下是使用 scikit-learn 的最小-最大縮放示例:
from sklearn.preprocessing import MinMaxScaler
# Create a MinMaxScaler object
scaler = MinMaxScaler()
# Fit and transform the data
X_scaled = scaler.fit_transform(X)

Fig.4 — Standardization and Normalization
3.魯棒縮放:魯棒縮放與標(biāo)準(zhǔn)化類似,但它使用中位數(shù)和四分位距代替均值和標(biāo)準(zhǔn)差。這使得它對數(shù)據(jù)中的異常值更加魯棒。
以下是使用 scikit-learn 的魯棒縮放示例:
from sklearn.preprocessing import RobustScaler
# Create a RobustScaler object
scaler = RobustScaler()
# Fit and transform the data
X_scaled = scaler.fit_transform(X)
4.歸一化:歸一化將每個(gè)觀測值縮放為單位范數(shù),這意味著每個(gè)特征值的平方和為1。這對于某些需要所有樣本具有類似比例的算法非常有用。
以下是使用 scikit-learn 進(jìn)行歸一化的示例:
from sklearn.preprocessing import Normalizer
# Create a Normalizer object
scaler = Normalizer()
# Fit and transform the data
X_scaled = scaler.fit_transform(X)
創(chuàng)建新特征
創(chuàng)建新特征是特征工程中的一個(gè)重要步驟,它涉及從現(xiàn)有數(shù)據(jù)中創(chuàng)建新的變量或列。這可以幫助捕捉特征之間的復(fù)雜關(guān)系并提高模型的準(zhǔn)確性。
以下是創(chuàng)建新特征的一些技術(shù):
1.交互特征:交互特征是通過將兩個(gè)或多個(gè)現(xiàn)有特征相乘來創(chuàng)建的。這可以幫助捕捉特征的聯(lián)合效應(yīng)并揭示數(shù)據(jù)中的新模式。例如,如果我們有兩個(gè)特征,“年齡”和“收入”,我們可以通過將這兩個(gè)特征相乘來創(chuàng)建一個(gè)名為“age_income”的新交互特征。
以下是使用 Python 中的 Pandas 創(chuàng)建交互特征的示例:
import pandas as pd
# create a sample data frame
data = pd.DataFrame({'age': [25, 30, 35],
'income': [50000, 60000, 70000]})
# create a new interaction feature
data['age_income'] = data['age'] * data['income']
# display the updated data frame
print(data)
2.多項(xiàng)式特征:多項(xiàng)式特征是通過將現(xiàn)有特征提高到更高的冪來創(chuàng)建的。這可以幫助捕捉特征之間的非線性關(guān)系并提高模型的準(zhǔn)確性。例如,如果我們有一個(gè)特征“年齡”,我們可以通過將這個(gè)特征平方來創(chuàng)建一個(gè)新的多項(xiàng)式特征稱為“age_squared”。
以下是使用 Python 中的 Scikit-learn 創(chuàng)建多項(xiàng)式特征的示例:
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
# create a sample data set
X = np.array([[1, 2],
[3, 4]])
# create polynomial features up to degree 2
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
# display the updated feature matrix
print(X_poly)
3.分箱:分箱將連續(xù)值分組為離散類別。這可以幫助捕捉非線性關(guān)系并減少數(shù)據(jù)中異常值的影響。例如,如果我們有一個(gè)特征“年齡”,我們可以通過將年齡分組為不同的類別,例如“0-18”、“18-25”、“25-35”、“35-50”和“50+”,來創(chuàng)建一個(gè)名為“age_group”的新分箱特征。
以下是使用 Python 中的 Pandas 創(chuàng)建分箱特征的示例:
import pandas as pd
# create a sample data frame
data = pd.DataFrame({'age': [20, 25, 30, 35, 40, 45, 50, 55]})
# create bins for different age groups
bins = [0, 18, 25, 35, 50, float('inf')]
labels = ['0-18', '18-25', '25-35', '35-50', '50+']
data['age_group'] = pd.cut(data['age'], bins=bins, labels=labels)
# display the updated data frame
print(data)
處理不平衡數(shù)據(jù)
處理不平衡數(shù)據(jù)是機(jī)器學(xué)習(xí)中的一個(gè)重要方面。不平衡數(shù)據(jù)是指目標(biāo)變量的分布不均勻,其中一個(gè)類別相對于另一個(gè)類別的樣本數(shù)量較少。這可能會(huì)導(dǎo)致模型對多數(shù)類別產(chǎn)生偏差,并且模型可能在少數(shù)類別上表現(xiàn)不佳。一些處理不平衡數(shù)據(jù)的技術(shù)包括:
1.過采樣(Upsampling):過采樣通過對現(xiàn)有樣本進(jìn)行替換性重采樣來為少數(shù)類別創(chuàng)建更多的樣本。可以使用 sklearn.utils 模塊中的 resample 函數(shù)來實(shí)現(xiàn)。
from sklearn.utils import resample
# Upsample minority class
X_upsampled, y_upsampled = resample(X_minority, y_minority, replace=True, n_samples=len(X_majority), random_state=42)
2.降采樣(Downsampling):降采樣通過從多數(shù)類別中刪除一些樣本來平衡分布。可以使用 sklearn.utils 模塊中的 resample 函數(shù)來實(shí)現(xiàn)。
from sklearn.utils import resample
# Downsample majority class
X_downsampled, y_downsampled = resample(X_majority, y_majority, replace=False, n_samples=len(X_minority), random_state=42)
Fig.4 — UnderSampling and OverSampling
3.合成少數(shù)類過采樣技術(shù)(SMOTE):SMOTE 涉及基于現(xiàn)有樣本為少數(shù)類創(chuàng)建合成樣本。這可以使用 imblearn.over_sampling 模塊中的 SMOTE 函數(shù)來完成。
from imblearn.over_sampling import SMOTE
# Use SMOTE to upsample minority class
sm = SMOTE(random_state=42)
X_resampled, y_resampled = sm.fit_resample(X, y)
4.類別權(quán)重(Class Weighting):類別權(quán)重將權(quán)重分配給模型中的每個(gè)類別,以考慮不平衡性。可以使用模型中的 class_weight 參數(shù)來實(shí)現(xiàn)。
from sklearn.linear_model import LogisticRegression
# Use class weighting to handle imbalance
clf = LogisticRegression(class_weight='balanced', random_state=42)
clf.fit(X_train, y_train)
5.異常檢測(Anomaly Detection):異常檢測涉及識(shí)別數(shù)據(jù)中的異常值并將其刪除。可以使用 sklearn.ensemble 模塊中的 IsolationForest 函數(shù)來實(shí)現(xiàn)。異常檢測是在數(shù)據(jù)集中識(shí)別與預(yù)期或正常行為顯著偏離的罕見事件或觀測值。在不平衡數(shù)據(jù)的情況下,其中一個(gè)類別的觀測值數(shù)量遠(yuǎn)低于另一個(gè)類別,可以使用異常檢測來識(shí)別和標(biāo)記少數(shù)類別中的罕見觀測值為異常值。這可以幫助平衡數(shù)據(jù)集并提高機(jī)器學(xué)習(xí)模型的性能。
在不平衡數(shù)據(jù)中進(jìn)行異常檢測的一種常見方法是使用聚類等無監(jiān)督學(xué)習(xí)技術(shù),將少數(shù)類別的觀測值基于其相似性聚類成不同的組。不屬于這些聚類之一的少數(shù)類別觀測值可以被標(biāo)記為異常值。
另一種方法是使用單類別分類等監(jiān)督學(xué)習(xí)技術(shù),其中使用多數(shù)類別數(shù)據(jù)訓(xùn)練模型來學(xué)習(xí)數(shù)據(jù)的正常行為。然后將與學(xué)習(xí)到的正常行為顯著偏離的少數(shù)類別觀測值標(biāo)記為異常值。
from sklearn.ensemble import IsolationForest
# Use anomaly detection to handle imbalance
clf = IsolationForest(random_state=42)
clf.fit(X_train)
X_train = X_train[clf.predict(X_train) == 1]
y_train = y_train[clf.predict(X_train) == 1]
6.成本敏感學(xué)習(xí)(Cost-Sensitive Learning):成本敏感學(xué)習(xí)將不同類型的錯(cuò)誤分配不同的成本以考慮不平衡性。可以使用模型中的 sample_weight 參數(shù)來實(shí)現(xiàn)。
在成本敏感學(xué)習(xí)中,模型會(huì)為每個(gè)類別分配一個(gè)成本權(quán)重。這些成本權(quán)重反映了在模型中犯錯(cuò)的代價(jià)。通常,少數(shù)類別的成本權(quán)重比多數(shù)類別的成本權(quán)重高,以強(qiáng)制模型更加關(guān)注少數(shù)類別。這可以通過調(diào)整 sample_weight 參數(shù)來實(shí)現(xiàn)。
from sklearn.tree import DecisionTreeClassifier
# Use cost-sensitive learning to handle imbalance
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train, sample_weight=class_weights)
-
編碼
+關(guān)注
關(guān)注
6文章
915瀏覽量
54650 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8306瀏覽量
131834 -
預(yù)處理
+關(guān)注
關(guān)注
0文章
32瀏覽量
10452
發(fā)布評論請先 登錄
相關(guān)推薦
機(jī)器學(xué)習(xí)算法的特征工程與意義詳解
機(jī)器算法學(xué)習(xí)比較
有感FOC算法學(xué)習(xí)與實(shí)現(xiàn)總結(jié)
機(jī)器學(xué)習(xí)特征工程的五個(gè)方面優(yōu)點(diǎn)
SVPWM的原理與算法學(xué)習(xí)課件免費(fèi)下載
機(jī)器學(xué)習(xí)算法學(xué)習(xí)之特征工程1

機(jī)器學(xué)習(xí)算法學(xué)習(xí)之特征工程3

機(jī)器學(xué)習(xí)的經(jīng)典算法與應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論