 基于鯤鵬處理器的高性能計算實踐
基于鯤鵬處理器的高性能計算實踐
我國在高性能計算領域取得了顯著進步,天河二號和神威太湖之光先后登頂Top500國際超算排行榜,2016、2017年連續獲得戈登貝爾HPC應用大獎。在“十四五”規劃中,我國在高性能計算領域將繼續貫徹“國產替代”戰略,新一代E級超級計算機都將采用國產處理器。
然而,目前國內高校還沒有采用國產處理器的校級計算平臺。這主要有以下三個原因:①基于國產處理器的計算平臺在使用習慣上與目前X86 CPU集群差異很大,用戶不習慣;②目前主流計算軟件都是基于X86處理器開發,在國產處理器上需要重新編譯與適配;③許多計算軟件的應用尚未針對國產處理器進行性能調優,運行速度無法保證。
為應對上述用戶操作難、應用部署難、運行速度慢這三個挑戰,我們開展了以下工作:
1)通過掛載統一文件系統和作業調度系統,將不同的計算設備融合在統一的并行文件系統之上,為用戶提供一致的體驗;
2)利用容器快速部署面向ARM集群的高性能計算應用,以模塊和鏡像形式向用戶提供預編譯軟件;
3)對于預編譯的應用軟件,進行了正確性校驗及性能調優。
本文將介紹上海交通大學采用華為鯤鵬920處理器建設的校級計算平臺,該平臺是國內高校建設的首個基于國產ARM處理器的計算集群(以下簡稱ARM集群)。這臺ARM集群與原有的X86 CPU集群、GPU集群共享一套并行文件系統,采用Infiniband網絡高速互聯,實踐了統一數據基座的理念。
我們這個工作有兩個創新點:
1)針對使用異構處理器、異構互聯網絡的多個計算集群,提出了一套新的網絡拓撲方案,使得這些計算集群可以共享同一并行文件系統;
2)率先在華為ARM集群上完成多個常用高性能計算應用的正確性校驗與性能調優,有力推動了國產高性能計算平臺的軟件生態建設。
上海交通大學校級高性能計算平臺于2013年建設了第一期,當時采用的是Intel Xeon處理器、XeonPhi協處理器和NVIDIA GPU加速器的混合計算架構,計算能力位列2013年11月Top500榜單第138位。2019年學校啟動二期建設,分別建設了基于Intel Xeon處理器面向高性能計算的同構集群和基于NVIDIA GPU加速器面向人工智能計算的異構集群。2020年我校建設第3套計算集群,采用了華為鯤鵬920處理器。
1. 背景介紹
1.1 計算節點
ARM集群共配置100個計算節點,每個節點搭載雙路128核鯤鵬920處理器,配有192 GB DDR4 2933內存。華為鯤鵬920采用7納米芯片制程工藝,基于ARMv8微架構,具體參數規格參見表1。
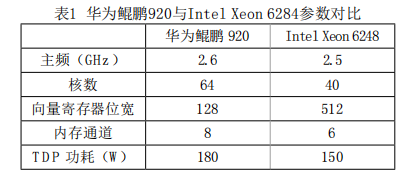
相比主流的Intel Xeon 6248處理器,華為鯤鵬920的核數和內存通道更多,因此提供了更高的并發度和內存訪問帶寬。但在向量化位寬上,鯤鵬920為Intel主流處理器的1/4。基于以上特征,鯤鵬920更加適合訪存密集型應用的計算
1.2 高速互聯網絡
上海交大校級計算平臺中的Intel CPU集群采用的是Intel 100 Gbps Omini-Path高速互聯網絡,GPU集群和ARM集群則采用Mellanox 100 Gbps Infiniband EDR高速互聯網絡。作為目前兩大主流高速互聯網絡,其通信協議提供了一種基于交換的架構,由處理器節點之間、處理器節點和存儲節點之間的點對點雙向串行鏈路構成。
1.3 文件系統
校級計算平臺采用Lustre并行文件系統,它是一種基于對象的并行文件系統,具有高可用、高性能、高可擴展性等特點,可以為大規模計算集群提供兼容POSIX的統一文件系統接口。其在Linux操作系統上運行,并采用客戶端-服務端模式的網絡架構。Lustre的服務端由一組服務器組成,用于提供元數據服務和對象存儲服務;客戶端則是Lustre文件系統的訪問接口,可以掛載Lustre文件系統。Lustre各節點服務器之間使用Lnet高速網絡協議互聯。
1.4 作業調度系統
校級計算平臺部署了CentOS7.6操作系統,在這套Linux系統上,我們掛載了SLURM作業調度系統。SLURM是一個開源、容錯、高度可擴展的集群管理和作業調度系統,作為集群工作負載管理器,它有三個關鍵功能:①它在一段時間內為用戶分配對資源(計算節點)的獨占和/或非獨占訪問,以便他們可以執行工作;②它提供了一個框架,用于在分配的節點集上啟動,執行和監視工作(通常是并行作業);③它通過管理待處理工作的隊列來仲裁資源爭用。
2. 系統設計 2.1 網絡拓撲設計
ARM集群網絡接入的整體思路類似于CPU+GPU異構集群,所有ARM節點接入Infiniband交換機實現節點間的互聯,后通過路由節點(LNet Router)橋接至OmniPath網絡,做到Infiniband和OmniPath兩種異構網絡之間的互通。
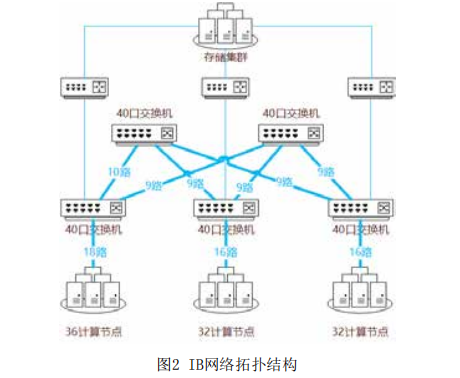
ARM集群的IB網絡包含5臺40口小型交換機和3臺路由節點。其中3臺交換機作為接入層交換機,分出一半端口直接與節點相連;剩余2臺作為核心層交換機,與接入層交換機進行網狀連接。3臺接入層交換機又分別通過對應的路由節點接入存儲集群。節點與交換機之間、交換機與交換機之間每條物理線路支持200Gbps帶寬,整個接入層與計算節點之間合計有10000Gbps通信帶寬;而接入層與核心層之間合計有11000Gbps帶寬。由于IB交換機自帶路由選擇功能,可以確保接入層與交換層的數據流量均勻分攤到每一條等價鏈路上,因此在這個胖樹拓撲結構下,任意兩個節點之間都可以始終確保享有100Gbps的可用通信帶寬。
2.2 共享文件系統掛載
ARM集群掛載Lustre文件系統分為兩個步驟:
步驟一:編譯安裝Lustre客戶端。安裝的Lustre客戶端版本需與服務端適配,因此需要選擇合適的操作系統版本,同時編譯Lustre客戶端過程中指定內核與IB驅動。實踐中,我們采用了ARM架構定制化的CentOS 7.6系統,編譯安裝了2.12.4版本Lustre客戶端。
步驟二:配置lnet路由。對于3組ARM集群節點來說,須賦予不同的LNET標簽(類似不同子網),且與存儲集群、X86超算集群等其它集群不同。之后,分別在存儲服務端、ARM節點和路由節點配置對應的Lnet路由,連通OPA和IB網絡。
經過以上兩個步驟,即可在ARM集群成功掛載Lustre文件系統,從而形成統一的數據基座。
3. 性能調優與驗證
為解決ARM集群運行速度慢的問題,我們選擇了LAMMPS和GATK作為本次應用調優與驗證的算例。這兩款應用2020年在我校X86 CPU集群上占到全年使用機時的35%。
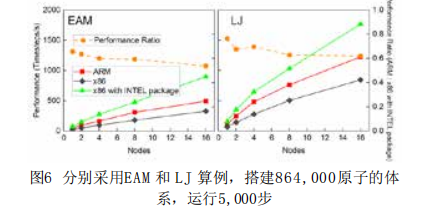
采用LAMMPS的兩個最基本算例EAM和LJ,測試ARM、X86以及X86上加入User-Intel加速包這三種模式,對比1, 2, 4, 8 和16個節點的運行速度(Timesteps/s)。兩個算例EAM和LJ均為864,000原子體系,在NVE系統下運行5,000步。ARM單節點計算速度是Intel主流處理器(不含User-Intel加速包)的2倍,擴展到16個節點仍保持1.5倍的優勢。當X86編譯使用User-Intel加速包后,ARM集群上LAMMPS的計算性能為Intel主流平臺的60%左右。
基于上述由Broad Institute提供的分析流程及相應的測試數據,測試X86和ARM上GATK 4.2的性能。由于在ARM集群上GATK 的HaplotypeCaller模塊缺少Intel為X86開發的GKL加速包(Intel GKL Utils),因此速度下降明顯。而MarkDuplicates及BQSR相關工具未經過底層優化,其在ARM集群上的性能約為x86集群的70%與50%。
為應對ARM集群建設中遇到的用戶操作難、應用部署難以及運行速度慢這三個挑戰,我們提出了一套新的網絡拓撲方案,使得ARM集群可以和現有X86集群可以共享同一并行文件系統,用戶可以實現無差別的數據訪問。另外,還利用Singularity為ARM集群快速部署了30多款常用的高性能計算應用軟件,并對其中使用率最高的LAMMPS和GATK應用進行了性能調優和評估,性能可以達到主流X86集群的60%-70%。ARM集群在2021年暑期面向校內進行試運行,期間整機月平均利用率超過70%。
審核編輯 :李倩
-
處理器
+關注
關注
68文章
19178瀏覽量
229200 -
ARM
+關注
關注
134文章
9057瀏覽量
366875 -
gpu
+關注
關注
28文章
4703瀏覽量
128725
原文標題:基于鯤鵬處理器的高性能計算實踐
文章出處:【微信號:架構師技術聯盟,微信公眾號:架構師技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
香山是什么?“香山” 高性能開源 RISC-V 處理器項目介紹
英偉達發布高性能計算處理器丹佛計劃
華為表示鯤鵬920是目前業界最高性能ARM-based處理器
華為推出基于ARM架構的服務器處理器鯤鵬920
基于NXP QorIQ 64位T1042處理器的高性能計算機
基于T4240多核處理器的高性能計算機產品特點


高性能處理器RK3588數據手冊
鯤鵬Validated認證幫助密碼模塊構建全面的高性能密碼計算服務
面向后E級計算的高性能處理器技術參考和借鑒
Fujitsu、NVIDIA、AMD和Intel高性能處理器架構分析





 工商網監
工商網監
評論