 RT-DETR用114FPS實現54.8AP遠超YOLOv8
RT-DETR用114FPS實現54.8AP遠超YOLOv8
最近,基于Transformer的端到端檢測器(DETR)已經取得了顯著的性能。然而,DETR的高計算成本問題尚未得到有效解決,這限制了它們的實際應用,并使它們無法充分利用無后處理的好處,如非最大值抑制(NMS)。
本文首先分析了現代實時目標檢測器中NMS對推理速度的影響,并建立了端到端的速度基準。為了避免NMS引起的推理延遲,作者提出了一種實時檢測Transformer(RT-DETR),這是第一個實時端到端目標檢測器。
具體而言,設計了一種高效的混合編碼器,通過解耦尺度內交互和跨尺度融合來高效處理多尺度特征,并提出了IoU感知的查詢選擇,以提高目標查詢的初始化。
此外,本文提出的檢測器支持通過使用不同的解碼器層來靈活調整推理速度,而不需要重新訓練,這有助于實時目標檢測器的實際應用。
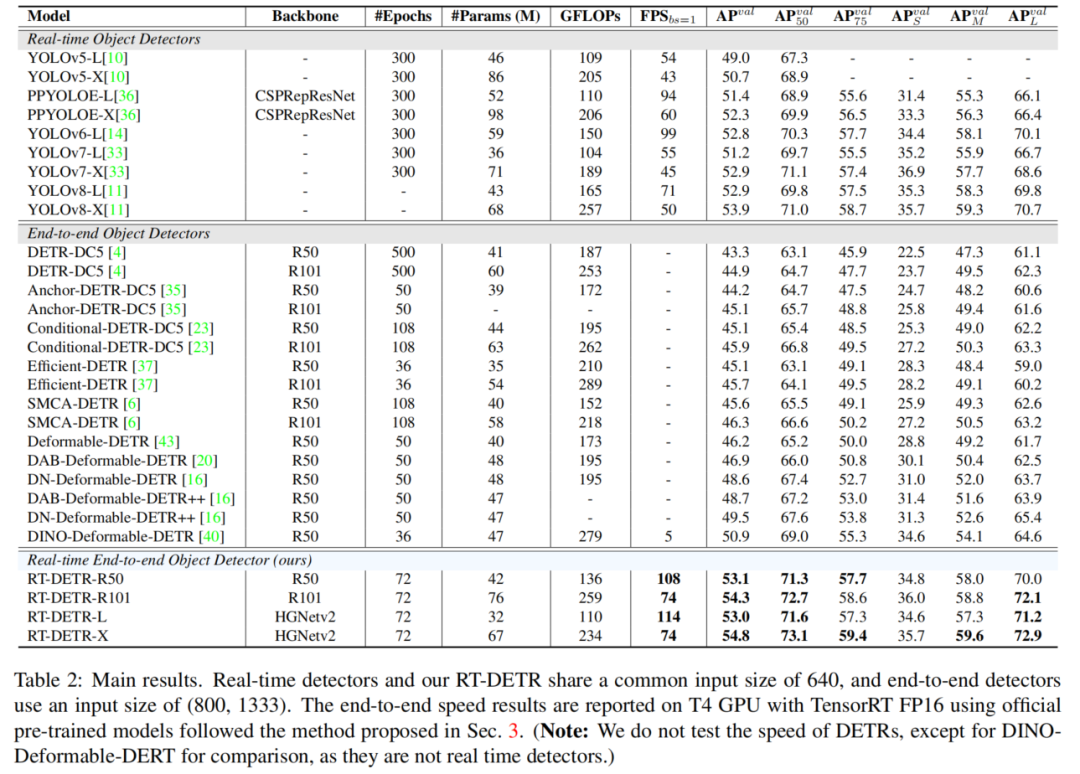
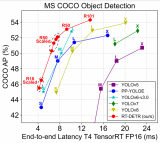
RTDETR-L在COCO val2017上實現了53.0%的AP,在T4 GPU上實現了114 FPS,而RT-DETR-X實現了54.8%的AP和74 FPS,在速度和精度方面都優于相同規模的所有YOLO檢測器。
此外,RTDETR-R50實現了53.1%的AP和108 FPS,在精度上比DINO-Deformable-DETR-R50高出2.2%的AP,在FPS上高出約21倍。
1、簡介
目標檢測是一項基本的視覺任務,涉及識別和定位圖像中的目標。現代目標檢測器有兩種典型的體系結構:
基于CNN
基于Transformer
在過去的幾年里,人們對基于CNN的目標檢測器進行了廣泛的研究。這些檢測器的架構已經從最初的兩階段發展到一階段,并且出現了兩種檢測范式,Anchor-Base和Anchor-Free。這些研究在檢測速度和準確性方面都取得了重大進展。
基于Transformer的目標檢測器(DETR)由于消除了各種手工設計的組件,如非最大值抑制(NMS),自提出以來,受到了學術界的廣泛關注。該架構極大地簡化了目標檢測的流水線,實現了端到端的目標檢測。
實時目標檢測是一個重要的研究領域,具有廣泛的應用,如目標跟蹤、視頻監控、自動駕駛等。現有的實時檢測器通常采用基于CNN的架構,在檢測速度和準確性方面實現了合理的權衡。然而,這些實時檢測器通常需要NMS進行后處理,這通常難以優化并且不夠魯棒,導致檢測器的推理速度延遲。
最近,由于研究人員在加速訓練收斂和降低優化難度方面的努力,基于Transformer的檢測器取得了顯著的性能。然而,DETR的高計算成本問題尚未得到有效解決,這限制了DETR的實際應用,并導致無法充分利用其優勢。這意味著,盡管簡化了目標檢測流水線,但由于模型本身的計算成本高,很難實現實時目標檢測。
上述問題自然啟發考慮是否可以將DETR擴展到實時場景,充分利用端到端檢測器來避免NMS對實時檢測器造成的延遲。為了實現上述目標,作者重新思考了DETR,并對其關鍵組件進行了詳細的分析和實驗,以減少不必要的計算冗余。
具體而言,作者發現,盡管多尺度特征的引入有利于加速訓練收斂和提高性能,但它也會導致編碼器中序列長度的顯著增加。因此,由于計算成本高,Transformer編碼器成為模型的計算瓶頸。為了實現實時目標檢測,設計了一種高效的混合編碼器來取代原來的Transformer編碼器。通過解耦多尺度特征的尺度內交互和尺度間融合,編碼器可以有效地處理不同尺度的特征。
此外,先前的工作表明,解碼器的目標查詢初始化方案對檢測性能至關重要。為了進一步提高性能,作者提出了IoU-Aware的查詢選擇,它通過在訓練期間提供IoU約束來向解碼器提供更高質量的初始目標查詢。
此外,作者提出的檢測器支持通過使用不同的解碼器層來靈活調整推理速度,而不需要重新訓練,這得益于DETR架構中解碼器的設計,并有助于實時檢測器的實際應用。
本文提出了一種實時檢測Transformer(RT-DETR),這是第一個實時基于Transformer的端到端目標檢測器。RT-DETR不僅在精度和速度上優于目前最先進的實時檢測器,而且不需要后處理,因此檢測器的推理速度不會延遲并保持穩定,充分利用了端到端檢測流水線的優勢。
RT-DETR-L在COCO val2017上實現了53.0%的AP,在NVIDIA Tesla T4 GPU上實現了114 FPS,而RT-DETR-X實現了54.8%的AP和74 FPS,在速度和精度方面都優于相同規模的所有YOLO檢測器。因此,RT-DETR成為了一種用于實時目標檢測的新的SOTA,如圖1所示。
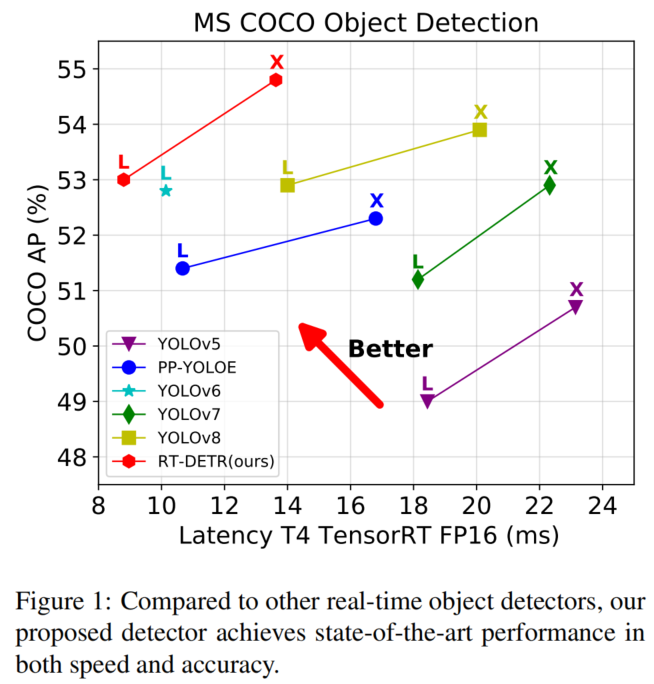
此外,提出的RT-DETR-R50實現了53.1%的AP和108 FPS,而RT-DETR-R101實現了54.3%的AP和74 FPS。其中,RT-DETR50在準確度上優于DINO-Deformable-DETR-R50 2.2%的AP(53.1%的AP對50.9%的AP),在FPS(108 FPS對5 FPS)上優于DINO-Deformable-DETR-R5約21倍。
本文的主要貢獻總結如下:
提出了第一個實時端到端目標檢測器,它不僅在準確性和速度上優于當前的實時檢測器,而且不需要后處理,因此推理速度不延遲,保持穩定;
詳細分析了NMS對實時檢測器的影響,并從后處理的角度得出了關于基于CNN的實時檢測器的結論;
提出的IoU-Aware查詢選擇在我們的模型中顯示出優異的性能改進,這為改進目標查詢的初始化方案提供了新的線索;
本文的工作為端到端檢測器的實時實現提供了一個可行的解決方案,并且所提出的檢測器可以通過使用不同的解碼器層來靈活地調整模型大小和推理速度,而不需要重新訓練。
2、相關方法
2.1、實時目標檢測器
經過多年的不斷發展,YOLO系列已成為實時目標檢測器的代名詞,大致可分為兩類:
Anchor-Base
Anchor-Free
從這些檢測器的性能來看,Anchor不再是制約YOLO發展的主要因素。然而,上述檢測器產生了許多冗余的邊界框,需要在后處理階段使用NMS來過濾掉它們。
不幸的是,這會導致性能瓶頸,NMS的超參數對檢測器的準確性和速度有很大影響。作者認為這與實時目標檢測器的設計理念不兼容。
2.2、端到端目標檢測器
端到端目標檢測器以其流線型管道而聞名。Carion等人首先提出了基于Transformer的端到端目標檢測器,稱為DETR(DEtection Transformer)。它因其獨特的特點而備受關注。特別地,DETR消除了傳統檢測流水線中手工設計的Anchor和NMS組件。相反,它采用二分匹配,并直接預測一對一的對象集。通過采用這種策略,DETR簡化了檢測管道,緩解了NMS帶來的性能瓶頸。
盡管DETR具有明顯的優勢,但它存在兩個主要問題:
訓練收斂緩慢
查詢難以優化
已經提出了許多DETR變體來解決這些問題。具體而言,Deformable DETR通過提高注意力機制的效率,加速了多尺度特征的訓練收斂。Conditional DETR和Anchor DETR降低了查詢的優化難度。DAB-DETR引入4D參考點,并逐層迭代優化預測框。DN-DETR通過引入查詢去噪來加速訓練收斂。DINO以之前的作品為基礎,取得了最先進的成果。
盡管正在不斷改進DETR的組件,但本文的目標不僅是進一步提高模型的性能,而且是創建一個實時的端到端目標檢測器。
2.3、目標檢測的多尺度特征
現代目標檢測器已經證明了利用多尺度特征來提高性能的重要性,尤其是對于小物體。FPN引入了一種融合相鄰尺度特征的特征金字塔網絡。隨后的工作擴展和增強了這種結構,并被廣泛用于實時目標檢測器。Zhu等人首先在DETR中引入了多尺度特征,提高了性能和收斂速度,但這也導致了DETR計算成本的顯著增加。
盡管Deformable Attention制在一定程度上減輕了計算成本,但多尺度特征的結合仍然會導致較高的計算負擔。為了解決這個問題,一些工作試圖設計計算高效的DETR。Effificient DETR通過初始化具有密集先驗的目標查詢來減少編碼器和解碼器層的數量。Sparse DETR選擇性地更新期望被解碼器引用的編碼器token,從而減少計算開銷。Lite DETR通過以交錯方式降低低級別特征的更新頻率來提高編碼器的效率。盡管這些研究降低了DETR的計算成本,但這些工作的目標并不是將DETR作為一種實時檢測器來推廣。
3、檢測器端到端速度
3.1、分析NMS
NMS是檢測中廣泛采用的后處理算法,用于消除檢測器輸出的重疊預測框。NMS中需要2個超參數:得分閾值和IoU閾值。
特別地,分數低于分數閾值的預測框被直接過濾掉,并且每當2個預測框的IoU超過IoU閾值時,分數較低的框將被丟棄。重復執行此過程,直到每個類別的所有框都已處理完畢。因此,NMS的執行時間主要取決于輸入預測框的數量和兩個超參數。
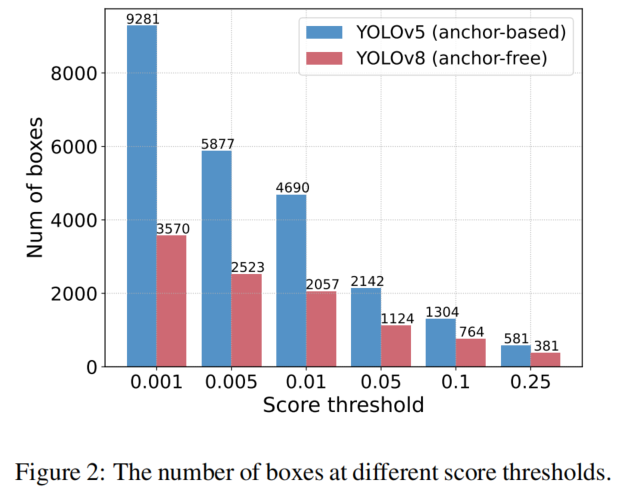
為了驗證這一觀點,作者利用YOLOv5和YOLOv8進行實驗。首先計算在輸出框被相同輸入圖像的不同得分閾值濾波后剩余的預測框的數量。采樣了0.001到0.25的一些分數作為閾值,對兩個檢測器的剩余預測框進行計數,并將其繪制成直方圖,直觀地反映了NMS易受其超參數的影響,如圖2所示。
此外,以YOLOv8為例,評估了不同NMS超參數下COCO val2017的模型準確性和NMS操作的執行時間。
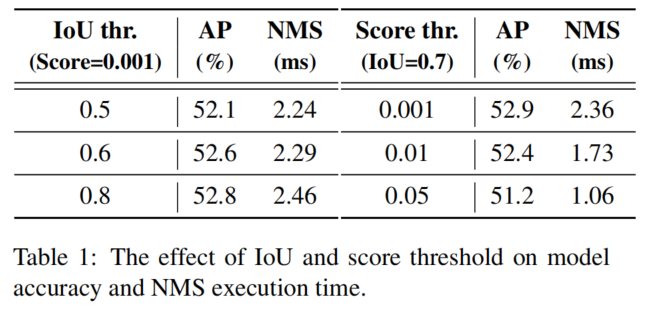
注意,在實驗中采用的NMS后處理操作是指TensorRT efficientNMSPlugin,它涉及多個CUDA內核,包括EfficientNMSFilter、RadixSort、EfficientNMS等,作者只報告了EfficientNMS內核的執行時間。在T4 GPU上測試了速度,上述實驗中的輸入圖像和預處理是一致的。使用的超參數和相應的結果如表1所示。
3.2、端到端速度基準
為了能夠公平地比較各種實時檢測器的端到端推理速度,作者建立了一個端到端速度測試基準。考慮到NMS的執行時間可能會受到輸入圖像的影響,有必要選擇一個基準數據集,并計算多個圖像的平均執行時間。該基準采用COCO val2017作為默認數據集,為需要后處理的實時檢測器添加了TensorRT的NMS后處理插件。
具體來說,根據基準數據集上相應精度的超參數測試檢測器的平均推理時間,不包括IO和內存復制操作。利用該基準測試T4 GPU上基于錨的檢測器YOLOv5和YOLOv7以及Anchor-Free檢測器PP-YOLOE、YOLOv6和YOLOv8的端到端速度。
測試結果如表2所示。
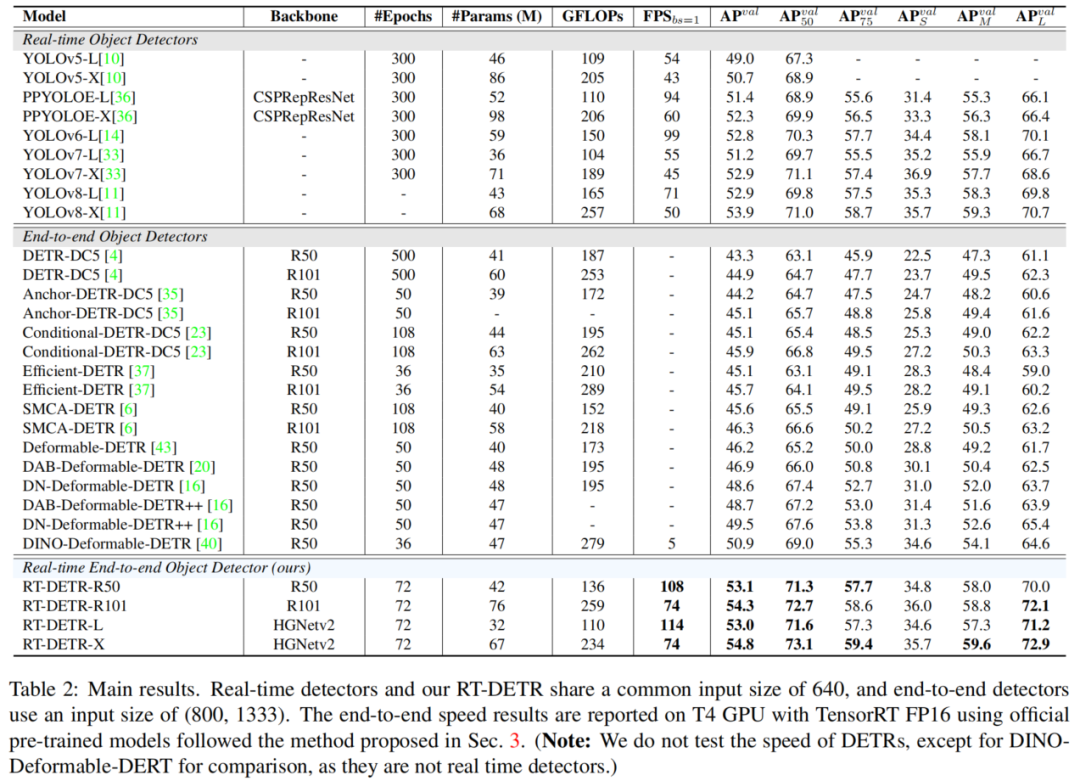
根據結果得出結論,對于需要NMS后處理的實時檢測器,Anchor-Free檢測器在同等精度上優于Anchor-Base的檢測器,因為前者的后處理時間明顯少于后者,這在以前的工作中被忽略了。這種現象的原因是,Anchor-Base的檢測器比Anchor-Free的檢測器產生更多的預測框(在測試的檢測器中是3倍多)。
4、The Real-time DETR
4.1、方法概覽
所提出的RT-DETR由Backbone、混合編碼器和帶有輔助預測頭的Transformer解碼器組成。模型體系結構的概述如圖3所示。
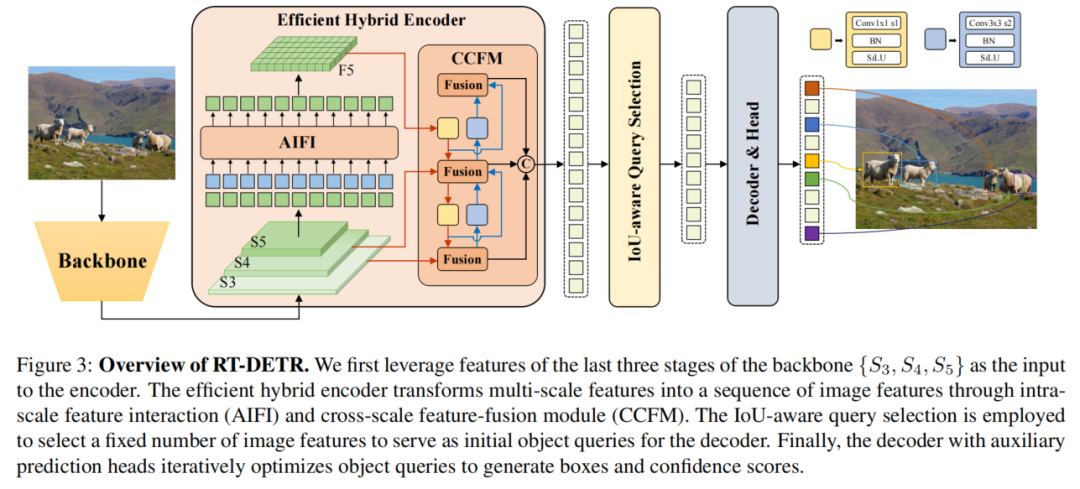
具體來說:
首先,利用Backbone的最后3個階段的輸出特征作為編碼器的輸入;
然后,混合編碼器通過尺度內交互和跨尺度融合將多尺度特征轉換為一系列圖像特征(如第4.2節所述);
隨后,采用IoU-Aware查詢選擇從編碼器輸出序列中選擇固定數量的圖像特征,作為解碼器的初始目標查詢;
最后,具有輔助預測頭的解碼器迭代地優化對象查詢以生成框和置信度得分。
4.2、高效混合編碼器
1、計算瓶頸分析
為了加速訓練收斂并提高性能,Zhu等人建議引入多尺度特征,并提出Deformable Attention機制以減少計算。然而,盡管注意力機制的改進減少了計算開銷,但輸入序列長度的急劇增加仍然導致編碼器成為計算瓶頸,阻礙了DETR的實時實現。
如所述,編碼器占GFLOP的49%,但在Deformable DETR中僅占AP的11%。為了克服這一障礙,作者分析了多尺度Transformer編碼器中存在的計算冗余,并設計了一組變體,以證明尺度內和尺度間特征的同時交互在計算上是低效的。
從包含關于圖像中的對象的豐富語義信息的低級特征中提取高級特征。直觀地說,對連接的多尺度特征進行特征交互是多余的。如圖5所示,為了驗證這一觀點,作者重新思考編碼器結構,并設計了一系列具有不同編碼器的變體。
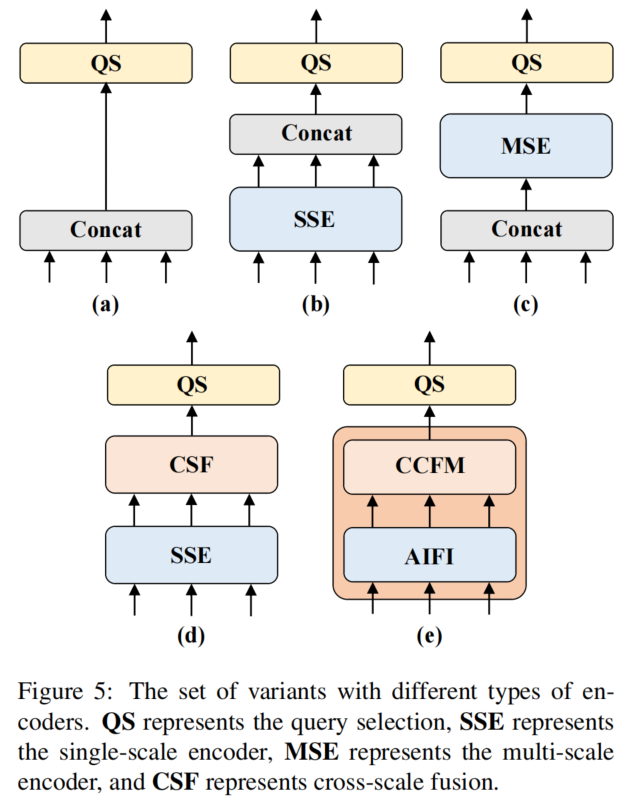
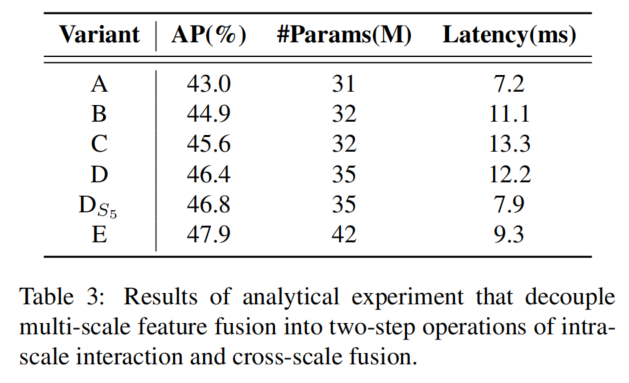
該組變體通過將多尺度特征交互解耦為尺度內交互和跨尺度融合的兩步操作,逐步提高模型精度,同時顯著降低計算成本。首先刪除了DINO-R50中的多尺度變換編碼器作為基線A。接下來,插入不同形式的編碼器,以產生基于基線A的一系列變體,具體如下:
A→ B:變體B插入一個單尺度Transformer編碼器,該編碼器使用一層Transformer Block。每個尺度的特征共享編碼器,用于尺度內特征交互,然后連接輸出的多尺度特征。
B→ C:變體C引入了基于B的跨尺度特征融合,并將連接的多尺度特征輸入編碼器以執行特征交互。
C→ D:變體D解耦了多尺度特征的尺度內交互和跨尺度融合。首先,使用單尺度Transformer編碼器進行尺度內交互,然后使用類PANet結構進行跨尺度融合。
D→ E:變體E進一步優化了基于D的多尺度特征的尺度內交互和跨尺度融合,采用了設計的高效混合編碼器。
2、Hybrid design
基于上述分析,作者重新思考了編碼器的結構,并提出了一種新的高效混合編碼器。如圖3所示,所提出的編碼器由兩個模塊組成,即基于注意力的尺度內特征交互(AIFI)模塊和基于神經網絡的跨尺度特征融合模塊(CCFM)。
AIFI進一步減少了基于變體D的計算冗余,變體D僅在上執行尺度內交互。作者認為,將自注意力操作應用于具有更豐富語義概念的高級特征可以捕捉圖像中概念實體之間的聯系,這有助于后續模塊對圖像中目標的檢測和識別。
同時,由于缺乏語義概念以及與高級特征的交互存在重復和混淆的風險,較低級別特征的尺度內交互是不必要的。為了驗證這一觀點,只對變體D中的進行了尺度內相互作用,實驗結果見表3,見行。與變體D相比,顯著降低了延遲(快35%),但提高了準確性(AP高0.4%)。這一結論對實時檢測器的設計至關重要。
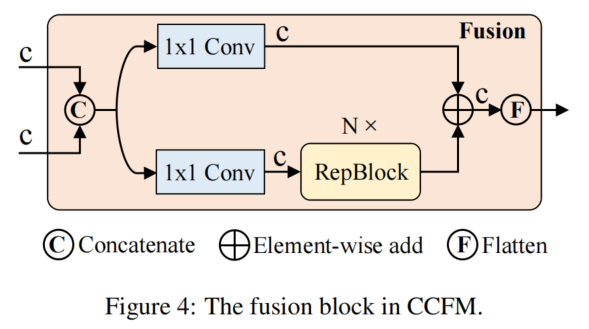
CCFM也基于變體D進行了優化,在融合路徑中插入了幾個由卷積層組成的融合塊。融合塊的作用是將相鄰的特征融合成一個新的特征,其結構如圖4所示。融合塊包含N個RepBlock,兩個路徑輸出通過元素相加進行融合。
可以將這個過程表述如下:
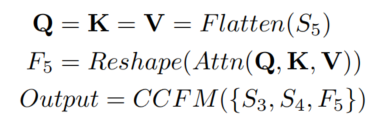
其中表示多頭自注意力,表示將特征的形狀恢復到與相同的形狀,這是的inverse操作。
4.3、IoU-Aware查詢選擇
DETR中的目標查詢是一組可學習的嵌入,這些嵌入由解碼器優化,并由預測頭映射到分類分數和邊界框。然而,這些目標查詢很難解釋和優化,因為它們沒有明確的物理意義。后續工作改進了目標查詢的初始化,并將其擴展到內容查詢和位置查詢(Anchor點)。其中,Effificient detr、Dino以及Deformable detr都提出了查詢選擇方案,它們的共同點是利用分類得分從編碼器中選擇Top-K個特征來初始化目標查詢(或僅位置查詢)。然而,由于分類得分和位置置信度的分布不一致,一些預測框具有高分類得分,但不接近GT框,這導致選擇了分類得分高、IoU得分低的框,而分類得分低、IoU分數高的框被丟棄。這會削弱探測器的性能。
為了解決這個問題,作者提出了IoU-Aware查詢選擇,通過約束模型在訓練期間為具有高IoU分數的特征產生高分類分數,并為具有低IoU得分的特征產生低分類分數。因此,與模型根據分類得分選擇的Top-K個編碼器特征相對應的預測框具有高分類得分和高IoU得分。
將檢測器的優化目標重新表述如下:
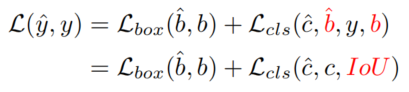
其中和表示預測和GT,和。和分別表示類別和邊界框。將IoU分數引入分類分支的目標函數(類似于VFL),以實現對正樣本分類和定位的一致性約束。
有效性分析
為了分析所提出的IoU感知查詢選擇的有效性,在val2017上可視化了查詢選擇所選擇的編碼器特征的分類分數和IoU分數,如圖6所示。
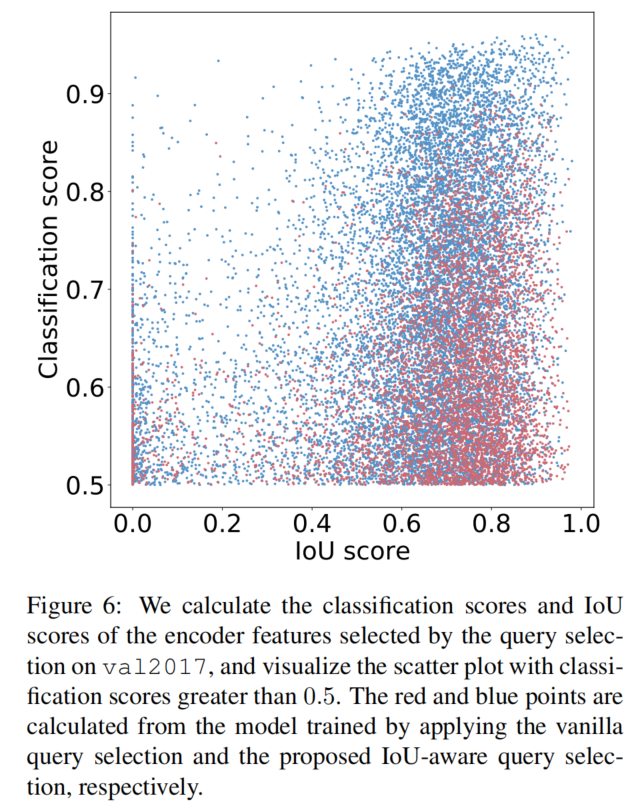
具體來說,首先根據分類得分選擇前K個(在實驗中K=300)編碼器特征,然后可視化分類得分大于0.5的散點圖。紅點和藍點是根據分別應用普通查詢選擇和IoU感知查詢選擇訓練的模型計算的。點越靠近圖的右上角,對應特征的質量就越高,即分類標簽和邊界框更有可能描述圖像中的真實對象。
根據可視化結果發現最引人注目的特征是大量藍色點集中在圖的右上角,而紅色點集中在右下角。這表明,使用IoU感知查詢選擇訓練的模型可以產生更多高質量的編碼器特征。
此外,還定量分析了這兩類點的分布特征。圖中藍色點比紅色點多138%,即分類得分小于或等于0.5的紅色點更多,這可以被視為低質量特征。然后,分析分類得分大于0.5的特征的IoU得分,發現IoU得分大于0.5時,藍色點比紅色點多120%。
定量結果進一步表明,IoU感知查詢選擇可以為對象查詢提供更多具有準確分類(高分類分數)和精確定位(高IoU分數)的編碼器特征,從而提高檢測器的準確性。
4.4、Scaled RT-DETR
為了提供RT-DETR的可擴展版本,將ResNet網替換為HGNetv2。使用depth multiplier和width multiplier將Backbone和混合編碼器一起縮放。因此,得到了具有不同數量的參數和FPS的RT-DETR的兩個版本。
對于混合編碼器,通過分別調整CCFM中RepBlock的數量和編碼器的嵌入維度來控制depth multiplier和width multiplier。值得注意的是,提出的不同規模的RT-DETR保持了同質解碼器,這有助于使用高精度大型DETR模型對光檢測器進行蒸餾。這將是一個可探索的未來方向。
5、實驗
5.1、與SOTA比較
5.2、混合編碼器的消融實驗研究
5.3、IoU感知查詢選擇的消融研究
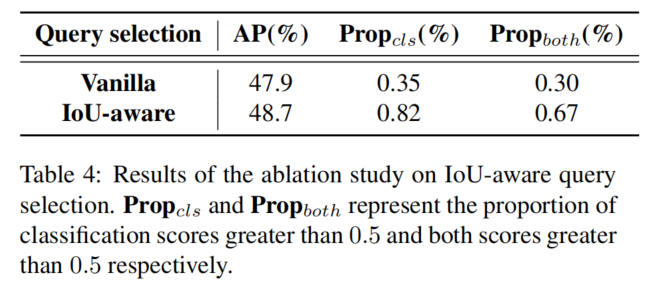
5.4、解碼器的消融研究
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3599瀏覽量
134181 -
檢測器
+關注
關注
1文章
860瀏覽量
47654 -
FPS
+關注
關注
0文章
35瀏覽量
11967 -
NMS
+關注
關注
0文章
9瀏覽量
6021
原文標題:YOLO超快時代終結了 | RT-DETR用114FPS實現54.8AP,遠超YOLOv8
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
簡單聊聊目標檢測新范式RT-DETR的骨干:HGNetv2
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

介紹RT-DETR兩種風格的onnx格式和推理方式
AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型

教你如何用兩行代碼搞定YOLOv8各種模型推理

三種主流模型部署框架YOLOv8推理演示
如何修改YOLOv8的源碼
YOLOv8實現任意目錄下命令行訓練
基于OpenVINO Python API部署RT-DETR模型
基于OpenVINO C++ API部署RT-DETR模型
基于OpenVINO C# API部署RT-DETR模型
基于YOLOv8的自定義醫學圖像分割

基于OpenCV DNN實現YOLOv8的模型部署與推理演示
OpenVINO? Java API應用RT-DETR做目標檢測器實戰





 工商網監
工商網監
評論