 圖像語義分割的概念與原理以及常用的方法
圖像語義分割的概念與原理以及常用的方法
1、圖像語義分割的概念
1.1圖像語義分割的概念與原理
圖像語義分割可以說是圖像理解的基石性技術,在自動駕駛系統(具體為街景識別與理解)、無人機應用(著陸點判斷)以及穿戴式設備應用中舉足輕重。我們都知道,圖像是由許多像素(Pixel)組成,而「語義分割」顧名思義就是將像素按照圖像中表達語義含義的不同進行分組(Grouping)/分割(Segmentation)。


圖像語義分割的意思就是機器自動分割并識別出圖像中的內容,比如給出一個人騎摩托車的照片,機器判斷后應當能夠生成右側圖,紅色標注為人,綠色是車(黑色表示back ground)。
2、目前常用的算法
2.1 前 DL 時代的語義分割
從最簡單的像素級別“閾值法”(Thresholding methods)、基于像素聚類的分割方法(Clustering-based segmentation methods)到“圖劃分”的分割方法(Graph partitioning segmentation methods),在深度學習(Deep learning, DL)“一統江湖”之前,圖像語義分割方面的工作可謂“百花齊放”。在此,我們僅以“Normalized cut” [1]和“Grab cut” [2]這兩個基于圖劃分的經典分割方法為例,介紹一下前DL時代語義分割方面的研究。
2.1.1 Normalized Cut圖像分割
在Deeplearning技術快速發展之前,就已經有了很多做圖像分割的技術,其中比較著名的是一種叫做“Normalized cut”的圖劃分方法,簡稱“ N-cut ”。
Normalized cut (N-cut)方法是基于圖劃分(Graph partitioning)的語義分割方法中最著名的方法之一,于 2000 年 Jianbo Shi 和 Jitendra Malik 發表于相關領域頂級期刊 TPAMI。通常,傳統基于圖劃分的語義分割方法都是將圖像抽象為圖(Graph)的形式 G=(V,E) (V 為圖節點,E 為圖的邊),然后借助圖理論(Graph theory)中的理論和算法進行圖像的語義分割。常用的方法為經典的最小割算法(Min-cut algorithm)。不過,在邊的權重計算時,經典 min-cut 算法只考慮了局部信息。如下圖所示,以二分圖為例(將 G 分為不相交的 , 兩部分),若只考慮局部信息,那么分離出一個點顯然是一個 min-cut,因此圖劃分的結果便是類似 或 這樣離群點,而從全局來看,實際想分成的組卻是左右兩大部分。
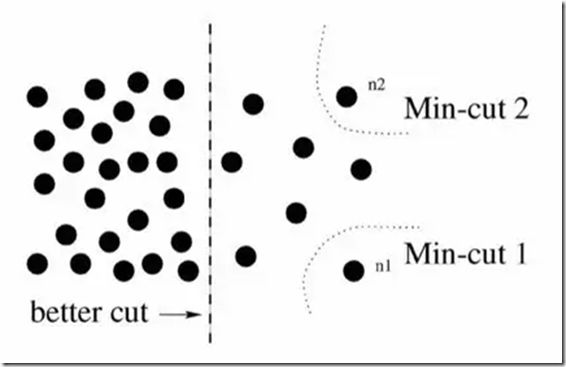
針對這一情形,N-cut 則提出了一種考慮全局信息的方法來進行圖劃分(Graph partitioning),即,將兩個分割部分 A,B , 與全圖節點的連接權重(assoc(A,V) 和 assoc(B,V))考慮進去:
如此一來,在離群點劃分中,中的某一項會接近 1,而這樣的圖劃分顯然不能使得是一個較小的值,故達到考慮全局信息而摒棄劃分離群點的目的。這樣的操作類似于機器學習中特征的規范化(Normalization)操作,故稱為Normalized cut。N-cut不僅可以處理二類語義分割,而且將二分圖擴展為 K 路( -way)圖劃分即可完成多語義的圖像語義分割,如下圖例。

2.1.2 Grab cut
Grab cut 是微軟劍橋研究院于 2004 年提出的著名交互式圖像語義分割方法。與 N-cut 一樣,grab cut 同樣也是基于圖劃分,不過 grab cut 是其改進版本,可以看作迭代式的語義分割算法。Grab cut 利用了圖像中的紋理(顏色)信息和邊界(反差)信息,只要少量的用戶交互操作即可得到比較好的前后背景分割結果。
在 Grab cut 中,RGB 圖像的前景和背景分別用一個高斯混合模型(Gaussian mixture model, GMM)來建模。兩個 GMM 分別用以刻畫某像素屬于前景或背景的概率,每個 GMM 高斯部件(Gaussian component)個數一般設為 。接下來,利用吉布斯能量方程(Gibbs energy function)對整張圖像進行全局刻畫,而后迭代求取使得能量方程達到最優值的參數作為兩個 GMM 的最優參數。GMM 確定后,某像素屬于前景或背景的概率就隨之確定下來。
在與用戶交互的過程中,Grab cut 提供兩種交互方式:一種以包圍框(Bounding box)為輔助信息;另一種以涂寫的線條(Scribbled line)作為輔助信息。以下圖為例,用戶在開始時提供一個包圍框,grab cut 默認的認為框中像素中包含主要物體/前景,此后經過迭代圖劃分求解,即可返回扣出的前景結果,可以發現即使是對于背景稍微復雜一些的圖像,grab cut 仍有不俗表現。

不過,在處理下圖時,grab cut 的分割效果則不能令人滿意。此時,需要額外人為的提供更強的輔助信息:用紅色線條/點標明背景區域,同時用白色線條標明前景區域。在此基礎上,再次運行 grab cut 算法求取最優解即可得到較為滿意的語義分割結果。Grab cut 雖效果優良,但缺點也非常明顯,一是僅能處理二類語義分割問題,二是需要人為干預而不能做到完全自動化。
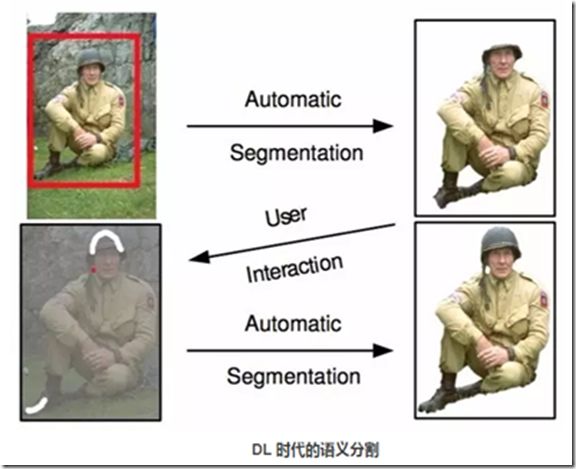
其實大家不難看出,前 DL 時代的語義分割工作多是根據圖像像素自身的低階視覺信息(Low-level visual cues)來進行圖像分割。由于這樣的方法沒有算法訓練階段,因此往往計算復雜度不高,但是在較困難的分割任務上(如果不提供人為的輔助信息),其分割效果并不能令人滿意。
2.2 DL 時代的語義分割
前 DL 時代的語義分割工作多是根據圖像像素自身的低階視覺信息(Low-level visual cues)來進行圖像分割。由于這樣的方法沒有算法訓練階段,因此往往計算復雜度不高,但是在較困難的分割任務上(如果不提供人為的輔助信息),其分割效果并不能令人滿意。
在計算機視覺步入深度學習時代之后,語義分割同樣也進入了全新的發展階段,以全卷積神經網絡(Fully convolutional networks,FCN)為代表的一系列基于卷積神經網絡「訓練」的語義分割方法相繼提出,屢屢刷新圖像語義分割精度。下面就介紹三種在 DL時代語義分割領域的代表性做法。
2.2.1全卷積神經網絡[3]
全卷積神經網絡 FCN 可以說是深度學習在圖像語義分割任務上的開創性工作,出自 UC Berkeley 的 Trevor Darrell 組,發表于計算機視覺領域頂級會議 CVPR 2015,并榮獲best paper honorable mention。
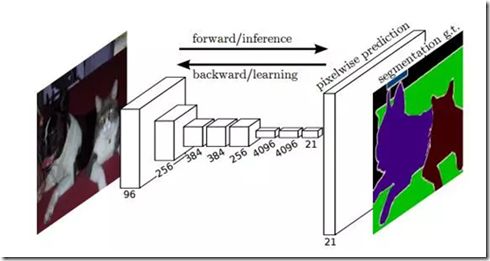
FCN 的思想很直觀,即直接進行像素級別端到端(end-to-end)的語義分割,它可以基于主流的深度卷積神經網絡模型(CNN)來實現。正所謂‘全卷積神經網絡‘,在FCN中,傳統的全連接層 fc6 和 fc7 均是由卷積層實現,而最后的 fc8 層則被替代為一個 21 通道(channel)的 1x1 卷積層,作為網絡的最終輸出。之所以有 21 個通道是因為 PASCAL VOC 的數據中包含 21 個類別(20個object類別和一個「background」類別)。下圖為 FCN 的網絡結構,若原圖為 H×W×3,在經過若干堆疊的卷積和池化層操作后可以得到原圖對應的響應張量(Activation tensor)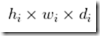 ?,其中,
?,其中,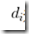 為 i 第 層的通道數。可以發現,由于池化層的下采樣作用,使得響應張量的長和寬遠小于原圖的長和寬,這便給像素級別的直接訓練帶來問題。
為 i 第 層的通道數。可以發現,由于池化層的下采樣作用,使得響應張量的長和寬遠小于原圖的長和寬,這便給像素級別的直接訓練帶來問題。
為了解決下采樣帶來的問題,FCN 利用雙線性插值將響應張亮的長寬上采樣到原圖大小,另外為了更好的預測圖像中的細節部分,FCN 還將網絡中淺層的響應也考慮進來。具體來說,就是將 Pool4 和 Pool3 的響應也拿來,分別作為模型 FCN-16s 和 FCN-8s 的輸出,與原來 FCN-32s 的輸出結合在一起做最終的語義分割預測(如下圖所示)。
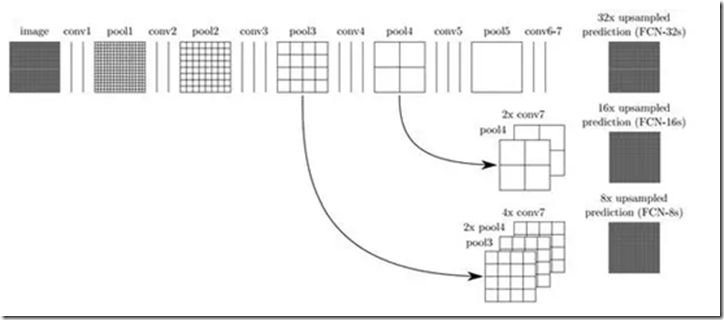
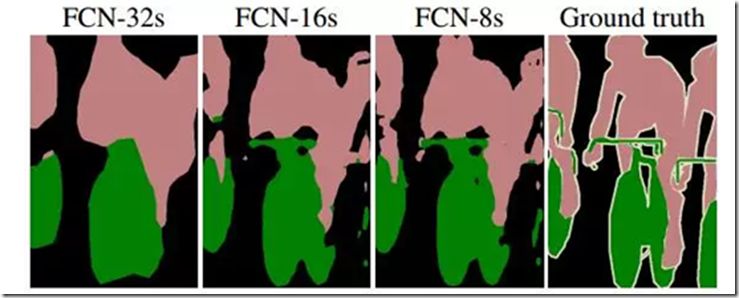
下圖是不同層作為輸出的語義分割結果,可以明顯看出,由于池化層的下采樣倍數的不同導致不同的語義分割精細程度。如 FCN-32s,由于是 FCN 的最后一層卷積和池化的輸出,該模型的下采樣倍數最高,其對應的語義分割結果最為粗略;而 FCN-8s 則因下采樣倍數較小可以取得較為精細的分割結果。
2.2.2 Dilated Convolutions [4]
FCN 的一個不足之處在于,由于池化層的存在,響應張量的大小(長和寬)越來越小,但是FCN的設計初衷則需要和輸入大小一致的輸出,因此 FCN 做了上采樣。但是上采樣并不能將丟失的信息全部無損地找回來。
對此,dilated convolution 是一種很好的解決方案——既然池化的下采樣操作會帶來信息損失,那么就把池化層去掉。但是池化層去掉隨之帶來的是網絡各層的感受野(Receptive field)變小,這樣會降低整個模型的預測精度。Dilated convolution 的主要貢獻就是,如何在去掉池化下采樣操作的同時,而不降低網絡的感受野。
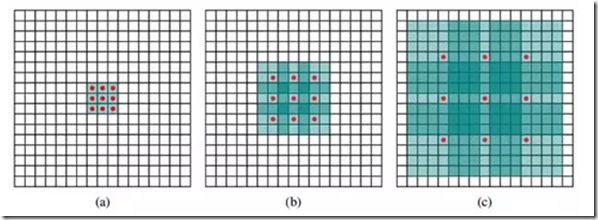
以 3×3 的卷積核為例,傳統卷積核在做卷積操作時,是將卷積核與輸入張量中「連續」的 3×3 的 patch 逐點相乘再求和(如下圖a,紅色圓點為卷積核對應的輸入「像素」,綠色為其在原輸入中的感知野)。而 dilated convolution 中的卷積核則是將輸入張量的 3×3 patch 隔一定的像素進行卷積運算。如下圖 b 所示,在去掉一層池化層后,需要在去掉的池化層后將傳統卷積層換做一個「dilation=2」的 dilated convolution 層,此時卷積核將輸入張量每隔一個「像素」的位置作為輸入 patch 進行卷積計算,可以發現這時對應到原輸入的感知野已經擴大(dilate)為 ;同理,如果再去掉一個池化層,就要將其之后的卷積層換成「dilation=4」的 dilated convolution 層,如圖 c 所示。這樣一來,即使去掉池化層也能保證網絡的感受野,從而確保圖像語義分割的精度。
從下面的幾個圖像語義分割效果圖可以看出,在使用了 dilated convolution 這一技術后可以大幅提高語義類別的辨識度以及分割細節的精細度。

2.2.3 以條件隨機場為代表的后處理操作[5]
當下許多以深度學習為框架的圖像語義分割工作都是用了條件隨機場(Conditional random field,CRF)作為最后的后處理操作來對語義預測結果進行優化。
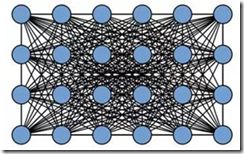
一般來講,CRF 將圖像中每個像素點所屬的類別都看作一個變量 ,然后考慮任意兩個變量之間的關系,建立一個完全圖(如下圖所示)。
,然后考慮任意兩個變量之間的關系,建立一個完全圖(如下圖所示)。
在全鏈接的 CRF 模型中,對應的能量函數為:
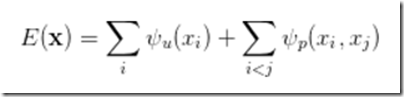
其中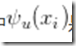 是一元項,表示Xi像素對應的語義類別, 其類別可以由 FCN 或者其他語義分割模型的預測結果得到;而第二項為二元項,二元項可將像素之間的語義聯系/關系考慮進去。例如,「天空」和「鳥」這樣的像素在物理空間是相鄰的概率,應該要比「天空」和「魚」這樣像素的相鄰概率大。最后通過對 CRF 能量函數的優化求解,得到對 FCN 的圖像語義預測結果進行優化,得到最終的語義分割結果。值得一提的是,已經有工作[5]將原本與深度模型訓練割裂開的 CRF 過程嵌入到神經網絡內部,即,將 FCN+CRF 的過程整合到一個端到端的系統中,這樣做的好處是 CRF 最后預測結果的能量函數可以直接用來指導 FCN 模型參數的訓練,而取得更好的圖像語義分割結果。
是一元項,表示Xi像素對應的語義類別, 其類別可以由 FCN 或者其他語義分割模型的預測結果得到;而第二項為二元項,二元項可將像素之間的語義聯系/關系考慮進去。例如,「天空」和「鳥」這樣的像素在物理空間是相鄰的概率,應該要比「天空」和「魚」這樣像素的相鄰概率大。最后通過對 CRF 能量函數的優化求解,得到對 FCN 的圖像語義預測結果進行優化,得到最終的語義分割結果。值得一提的是,已經有工作[5]將原本與深度模型訓練割裂開的 CRF 過程嵌入到神經網絡內部,即,將 FCN+CRF 的過程整合到一個端到端的系統中,這樣做的好處是 CRF 最后預測結果的能量函數可以直接用來指導 FCN 模型參數的訓練,而取得更好的圖像語義分割結果。

3、展望
基于深度學習的圖像語義分割技術雖然可以取得相比傳統方法突飛猛進的分割效果,但是其對數據標注的要求過高:不僅需要海量圖像數據,同時這些圖像還需提供精確到像素級別的標記信息(Semantic labels)。因此,越來越多的研究者開始將注意力轉移到弱監督(Weakly-supervised)條件下的圖像語義分割問題上。在這類問題中,圖像僅需提供圖像級別標注(如,有「人」,有「車」,無「電視」)而不需要昂貴的像素級別信息即可取得與現有方法可比的語義分割精度。
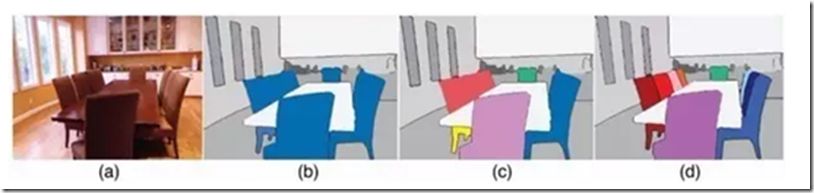
另外,示例級別(Instance level)的圖像語義分割問題也同樣熱門。該類問題不僅需要對不同語義物體進行圖像分割,同時還要求對同一語義的不同個體進行分割(例如需要對圖中出現的九把椅子的像素用不同顏色分別標示出來)
審核編輯 :李倩
-
算法
+關注
關注
23文章
4601瀏覽量
92673 -
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
自動駕駛
+關注
關注
783文章
13694瀏覽量
166166
原文標題:圖像語義分割的概念與原理以及常用的方法
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

聚焦語義分割任務,如何用卷積神經網絡處理語義圖像分割?


基于SEGNET模型的圖像語義分割方法
跨圖像關系型KD方法語義分割任務-CIRKD
PyTorch教程-14.9. 語義分割和數據集








 工商網監
工商網監
評論