 后ChatGPT時代NLP的下一個方向:增強式大規模語言模型
后ChatGPT時代NLP的下一個方向:增強式大規模語言模型
引言
目前,大規模語言模型(LLM)在自然語言處理領域表現出了驚人的性能,能夠完成前所未有的任務,為更多的人機交互形式打開了大門,ChatGPT是一個最好的例子。然而,LLM在大規模推廣中受到了一些限制,其中一些限制源于其單參數模型和有限的上下文(N個token)等基本缺陷。隨著硬件和軟件技術的不斷發展,LLM需要更長的上下文來展現其更強大的能力,但在實踐中,大多數LLM仍然只能使用較小的上下文尺寸。為了解決這些問題,出現了增強語言模型(ALM),它是一種利用外部信息來增強語言模型的方法。ALM包括推理、工具和行為三個方面,通過這些方面的增強,語言模型可以調用其他工具來解決更加復雜的任務,并對虛擬或真實世界產生影響并觀察結果。本文介紹2種最近出現的增強式語言模型去完成各種模態的交互式任務:1)VisualChatGPT;2)Toolformer。
文章概覽
文章概覽
Visual-ChatGPT

微軟最近的一個開源項目:Visual ChatGPT,讓用戶能夠用交互的形式與大規模語言模型完成圖片操作的任務。以此為 ChatGPT 提供了新的玩法。
論文:https://arxiv.org/abs/2303.04671
論文細節
介紹
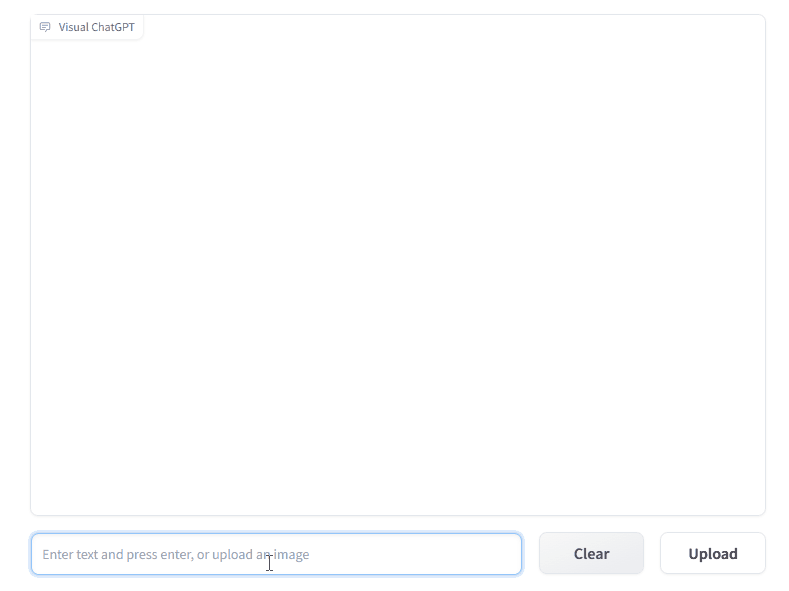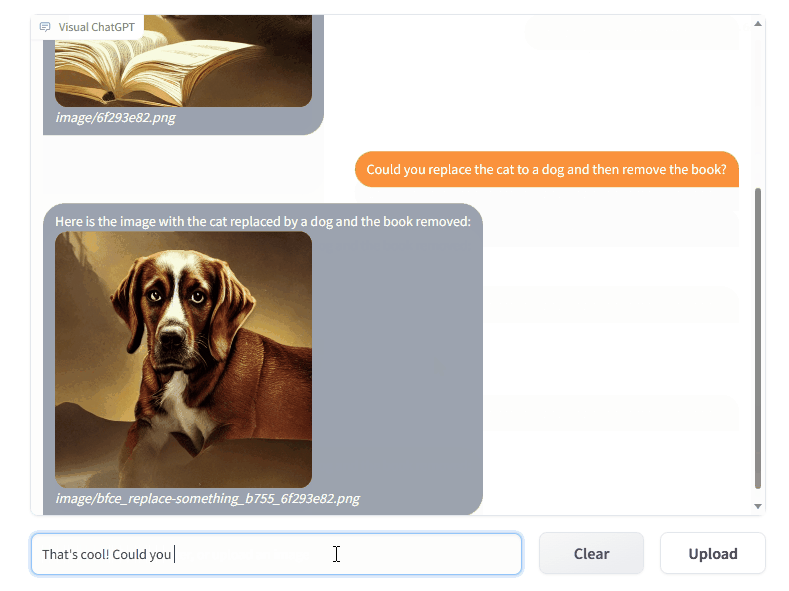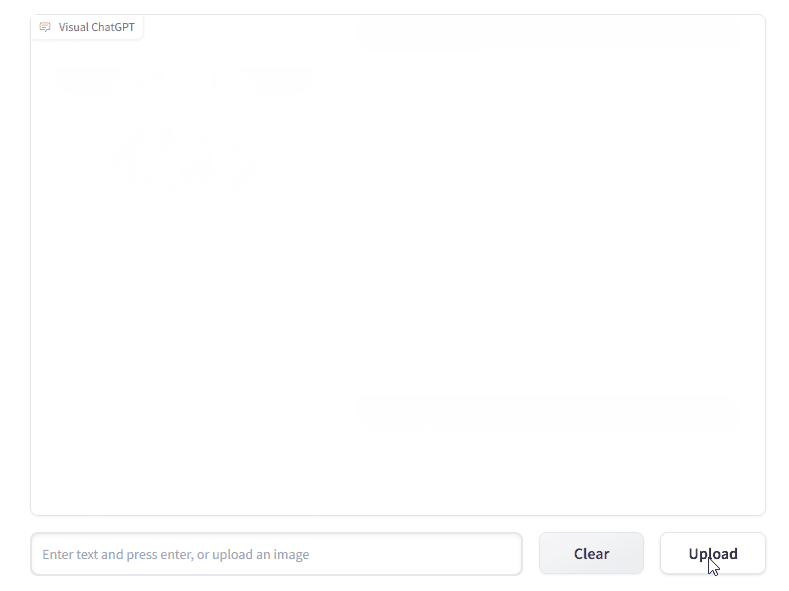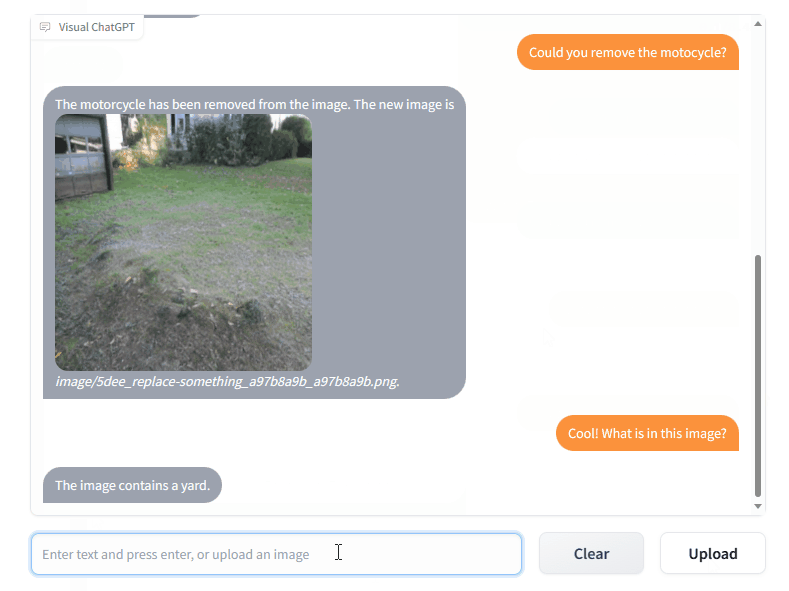
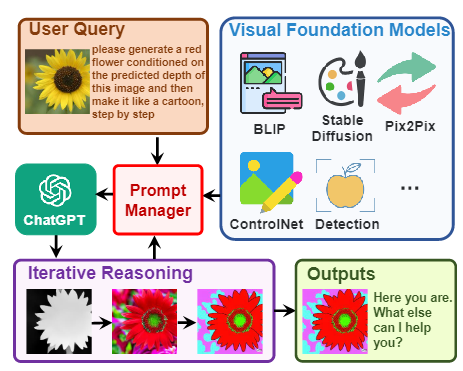
Visual ChatGPT 是一種智能交互系統,它將不同的視覺基礎模型與 ChatGPT 相結合,使得用戶可以通過發送語言和圖像與 AI 系統進行交互。與傳統的 ChatGPT 僅支持文字交互不同,Visual ChatGPT 可以支持文字+圖片的交互方式。除了可以進行簡單的對話外,Visual ChatGPT 還可以接收復雜的視覺問題或視覺編輯指令,并要求多個 AI 模型之間進行協作和多步驟操作。用戶還可以給出反饋,并要求修改結果,從而實現更加智能化、人性化的交互體驗。簡而言之,Visual ChatGPT 使用戶可以以一種更加豐富、直觀和自然的方式與 AI 系統進行交互。
用戶可以發送以下幾種指令進行交互:
發送和接收不僅是語言而且是圖像
提供復雜的視覺問題或視覺編輯指令,需要多個 AI 模型之間的協作和多步驟操作
提供反饋并要求修改結果,并且它能夠根據用戶反饋修改結果
方法
文中作者讓ChatGPT與其他視覺模型進行交互,下游模型稱作VFM, 是 Visual Foundation Model(視覺基礎模型)縮寫,其中Stable Diffusion、ControlNet、BLIP 等圖像處理類模型。作者還提出了提示管理器(Prompt Manger)作為 ChatGPT 和 VFM 之間的橋梁。提示管理器(Prompt Manger)明確告知 ChatGPT 每個 VFM 的功能并指定必要的輸入輸出格式; 它將各種類型的視覺信息(例如 png 圖像、深度圖像和遮罩矩陣)轉換為語言格式以幫助 ChatGPT 理解。同時管理不同 VFM 的歷史記錄、優先級和沖突; 通過使用提示管理器,ChatGPT 可以有效地利用 VFM 并以迭代的方式接收他們的反饋,直到滿足用戶的要求或達到結束條件。
詳細的整體結構如下:
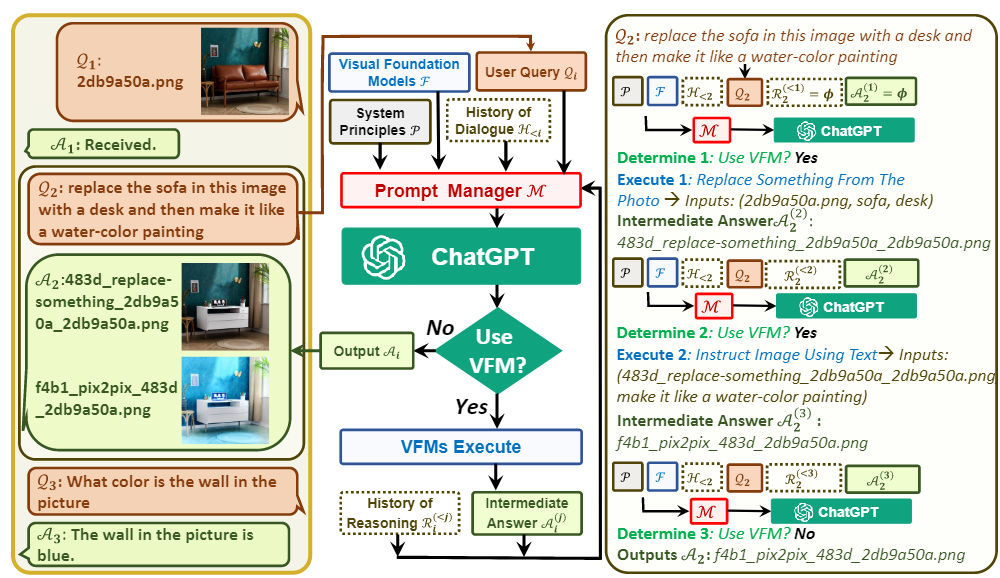
從左到右分為了三個部分,中間部分詳細展示了模型接收到提問(Query)后,會判斷是否需要使用 VFM 進行處理,如果需要則會調用下游的VFM相應的模型為這個指令進行回答。
Visual-ChatGPT特點
Visual ChatGPT 擴展了聊天機器人的輸入和輸出范圍,超越了傳統的基于文本的通信。它可以處理文本和圖像信息,并根據用戶需求生成各種格式的回復。
Visual ChatGPT 提高了聊天機器人的智能水平。傳統的聊天機器人只能在單一領域或任務上表現出智能行為,而 Visual ChatGPT 可以在多個領域或任務上表現出智能行為,并且可以根據上下文切換不同模式。
Visual ChatGPT 增加了聊天機器人的趣味性和互動性。與傳統的聊天機器人只能進行簡單而枯燥的對話不同,Visual ChatGPT 可以進行富有創意和想象力的對話,并且可以根據用戶喜好調整風格。
文章概覽
Toolformer

論文地址:https://arxiv.org/pdf/2302.04761v1.pdf
論文細節
介紹
大型語言模型存在一些局限性,例如無法獲取最新信息、可能會產生“信息幻覺”、難以理解低資源語言以及缺乏進行精確計算的數學技能等。為了解決這些問題,一種簡單的方法是為模型提供外部工具,例如搜索引擎、計算器或日歷。然而,現有方法通常需要大量的人工注釋或將工具的使用限制在特定任務設置下,這使得語言模型與外部工具的結合使用難以推廣。為了克服這種瓶頸,Meta AI 最近提出了一種名為 Toolformer 的新方法,該方法使得語言模型能夠學會“使用”各種外部工具。
Toolformer滿足了以下實際需求:
大型語言模型應該在自監督的方式下學習工具的使用,而不需要大量的人工注釋。人工注釋的成本很高,而且人類認為有用的東西可能與模型認為有用的東西不同。
語言模型需要更全面地使用不受特定任務約束的工具。Toolformer打破了大語言模型的瓶頸。接下來我們將詳細介紹Toolformer的方法
方法
Toolformer基于帶有in-context learning(ICL)的大型語言模型從頭開始生成數據集。這種方法只需要提供少量人類使用API的樣本,就可以讓語言模型用潛在的API調用標注一個巨大的語言建模數據集。然后,使用自監督損失函數來確定哪些API調用實際上有助于模型預測未來的token,并根據對LM本身有用的API調用進行微調。由于Toolformer與所使用的數據集無關,因此可以將其用于與模型預訓練完全相同的數據集,這確保了模型不會失去任何通用性和語言建模能力。具體來說,該研究旨在讓語言模型具備一種能力——通過API調用使用各種工具。為了實現這個目標,每個API的輸入和輸出都可以表征為文本序列。這允許將API調用無縫插入到任何給定文本中,并使用特殊的token來標記每個此類調用的開始和結束。
該工作把每個API調用建模為一個元祖,如下所示:
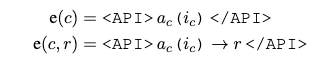
其中 是 API 的名稱, 是相應的輸入。給定一個API調用c和一個對應的結果r,上面的式子表示不帶有結果的API調用,下面的式子表示帶有API調用的結果的線性化序列。其中


給定一個只含有普通文本的數據集
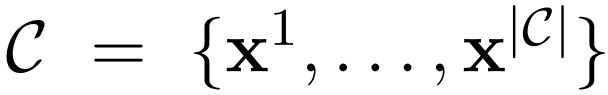
作者首先將這個數據集轉換成一個增加了 API 調用表示的數據集 C*。這個操作分為三步如下圖所示
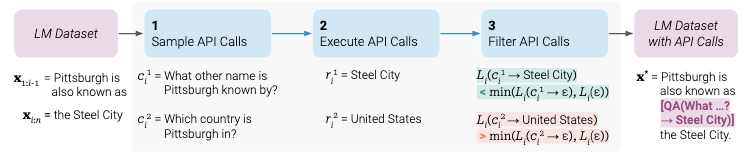
1)首先,該研究利用 LM 的 in-context learning 能力對大量潛在的 API 調用進行采樣
2)然后執行這些 API 調用
3)再檢查獲得的響應是否有助于預測未來的 token,以用作篩選標準。
4) 篩選之后,該研究合并對不同工具的 API 調用,最終生成數據集 C*,并在此數據集上微調 LM 本身。
Toolformer結合了一系列的工具,包括一個計算器、一個Q/A系統、兩個不同的搜索引擎、一個翻譯系統和一個日歷。Toolformer在各種下游任務中實現了大幅提高的零樣本性能,通常與更大的模型競爭,而不犧牲其核心語言建模能力。
總結
本文介紹了兩種增強式大語言模型(Visual-ChatGPT,Toolformer),使得大語言模型能夠通過調用其他基礎視覺模型,來通過交互讓用戶能夠與大規模語言模型進行多模態任務的溝通;并且,通過構建API數據集的方式微調,讓大規模語言模型學會利用調用API來執行各種任務。在當今火爆的大語言模型的浪潮下,增強式語言模型的范式為我們前往通用人工智能提供了有力的支持。
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
506瀏覽量
10245 -
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7495
原文標題:后ChatGPT時代NLP的下一個方向:增強式大規模語言模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT爆火背后,NLP呈爆發式增長!
【大規模語言模型:從理論到實踐】- 每日進步一點點
名單公布!【書籍評測活動NO.34】大語言模型應用指南:以ChatGPT為起點,從入門到精通的AI實踐教程
科技大廠競逐AIGC,中國的ChatGPT在哪?
人類科技的下一個時代將是VR/AR的時代

NVIDIA NeMo最新語言模型服務幫助開發者定制大規模語言模型
檢索增強的語言模型方法的詳細剖析
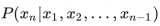






 工商網監
工商網監
評論