 多語言AI的現狀
多語言AI的現狀
-01-
作者介紹
Sebastian Ruder是Google的研究科學家,致力于研究代表性不足的語言的自然語言處理(NLP)。在此之前,他是DeepMind的研究科學家。他在Insight Research Centre for Data Analytics完成了自然語言處理和深度學習博士學位。在學習期間,他曾與微軟,IBM的Extreme Blue,Google Summer of Code和SAP等公司合作。
-02-
譯者說
據統計,世界上有超過7000種不同的語言,每種語言都承載著不同的文化。但是在歷史的長河中,已經有很多語言已經消失或者瀕臨消失。笛卡爾曾經說過:“語言的分歧是人生最大的不幸之一”。長久以來,實現不同語言之間的互通,能夠在經濟活動、文化交流中消除語言造成的隔閡,是人類共同努力的方向。多語言的模型可以抵消現有的語言鴻溝,確保一些非主流語言的使用者不會落后。而當下的一些語言模型主要集中在英語和其他具有大量資源的語言上,對一些瀕危語言或者代表性較差的語言的研究十分不足。無論是當下最流行的語言模型比如ChatGPT(目前我們已知它支持至少95種語言),還是Meta-AI最新開發的多語言模型NLLB-200(目前種類最多的多語言翻譯模型,可以實現200+語言的互譯),都無法實現世界上所有語言的互通,就更不用提在低資源語言上進行其他研究了。因此,開發適用于更多語言的模型十分重要。
原文鏈接:https://www.ruder.io/state-of-multilingual-ai/
-03-
譯文大綱
多語言研究現狀
近期進展
挑戰與機遇
-04-
譯文
多語言研究現狀:全世界大約有7000種語言。大約400種語言的用戶超過100萬,大約200種語言的用戶超過10萬[1]。有研究人員[2]回顧了在ACL 2008上發表的論文,發現63%的論文都集中在英語上。對于最近的一項研究[3],同樣回顧了ACL 2021的論文,發現近70%的論文僅在英語上進行評估。10年過去了,以英語為主流的現象似乎沒有什么變化。 同樣的,使用這些低資源語言的研究人員在ML和NLP社區中的代表性同樣不足。例如,雖然我們可以觀察到隸屬于非洲大學的作者數量在頂級機器學習(ML)和NLP場所發表文章略有上升趨勢,但與每年來自其他地區的數千名作者在這些場所發表文章相比,這種增長相形見絀。
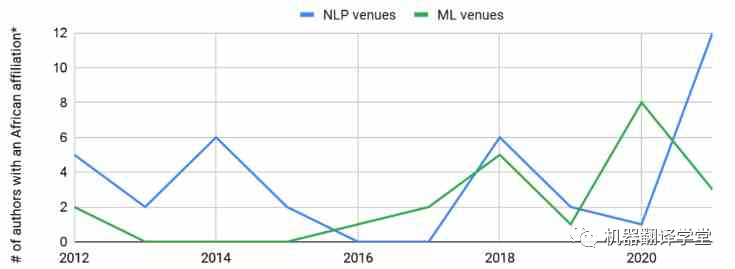
圖1. 非洲NLP研究人員在頂級ML和NLP會議中的代表。*:不考慮在國外工作的非洲作家。數據基于:Marek Rei的ml_nlp_paper_data。NLP會議:ACL,CL,COLING,CoNLL,EACL,EMNLP,NAACL,TACL;ML會議:AAAI,ICLR,ICML,NeurIPS。
許多 ML 領域中當前最先進的模型主要基于兩個要素:1) 大型的可擴展模型結構(通常基于 Transformer[4])和 2)遷移學習[5]。鑒于這些模型的一般性質,它們可以應用于各種類型的數據,包括圖像[6],視頻[7]和音頻[8]。最近NLP中一些成功的模型如BERT[9],RoBERTa[10],BART[11],T5[12]和DeBERTa[13],它們使用了多種掩碼語言建模(masked language modeling)方法的變體在數十億個token的文本上進行了訓練。在語音方面,wav2vec 2.0[14]也在大量未標記的語音上進行了預訓練。
多語言模型: 在當下的深度學習領域中,許多較為先進的模型都在數十億個token的文本上使用了多種掩碼語言建模(masked language modeling)進行預訓練。在NLP中,諸如mBERT,RemBERT[15],XLM-RoBERTa[16],mBART[17],mT5[18]和mDeBERTa[13]等模型,都使用了類似的方式進行訓練:在大約100種語言的預料上,隨機預測被mask的token。與單語模型相比,這些多語言模型需要更大的詞匯表來表示多種語言中的token。同時,也有一些研究致力于學習更魯棒的多語言表示,包括shared token[19],subword fertility[20]和詞嵌入對齊[21]等方法。在語音中,XSLR[22]和 UniSpeech[23]等模型分別針對 53 種和 60 種語言的大量未標記數據進行了預訓練。
多語言的詛咒: 為什么這些模型最多只能涵蓋 200種語言?其中一個原因是“多語言的詛咒”[16]。與許多其他任務的訓練過程相似,模型預訓練數據的語言越多,可用于學習每種語言表示的模型容量就越少。增加模型的大小在一定程度上可以改善這一點,使得模型能夠為每種語言提供更多容量[24]。
預訓練數據的缺乏: 除了模型容量,多語言模型的另一個限制因素是數據。網絡上的數據偏向于西方國家使用的語言,對于那些低資源數據嚴重不足。這令人擔憂,因為之前有研究表明,預訓練數據量與某些任務的下游性能相關[25][26][27]。特別是,在預訓練期間從未見過的語言通常會導致模型在實際應用中性能不佳[28][29]。
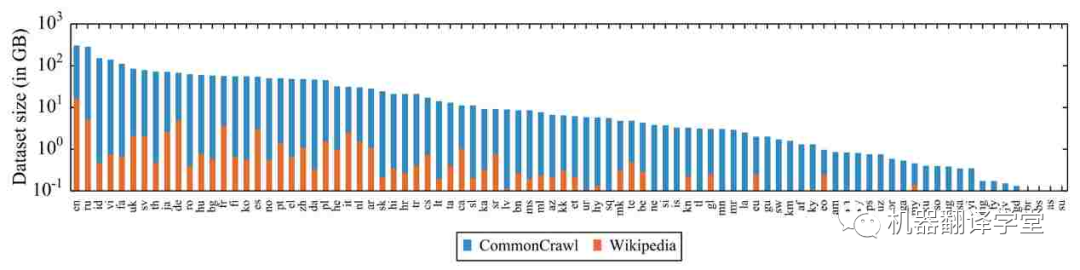
圖2. 維基百科和 CommonCrawl[16] 中統計的 88 種語言和其對應的數據量(對數尺度)。
現有多語言資源的質量問題 :即使對于數據豐富的語言,過去的工作也表明,一些常用的多語言資源存在嚴重的質量問題。例如WikiAnn[30](基于維基百科的弱監督多語言命名實體識別數據集)中的實體跨度有很多是錯誤的[31]。同樣,一些自動挖掘的資源和用于機器翻譯的自動對齊語料庫也是有問題的[32]。但是總的來說,在代表性不足的語言中,性能似乎主要受到數據數量而不是質量的限制[33]。
多語言評估 :我們可以在一些具有代表性的多語言評估指標(例如XTREME[25]和SuperGLUE[34])上查看最新模型的性能,從而更好地了解最新技術。該XTREME可以測試模型在9個任務和40種語言上的性能。從兩年半前的第一個多語言預訓練模型開始,多語言模型的性能穩步提高,并且正在慢慢接近基準測試上的人類水平。
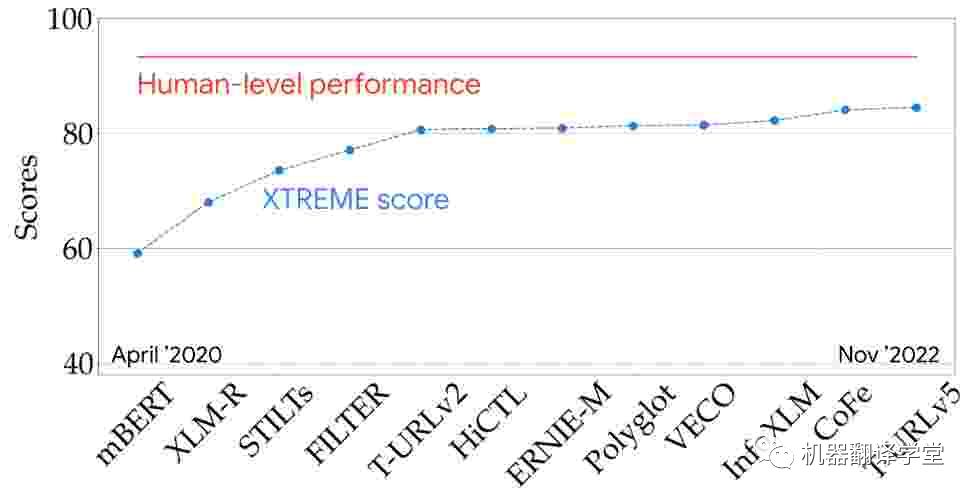
圖3. 模型在 XTREME 排行榜上的表現(9 個任務和 40 種語言)
多語言模型和以英語為中心的模型 :觀察最近 NLP 中的大型語言模型,我們根據預訓練中的非英語數據的比例繪制了如下圖片。基于這種特征,我們可以發現有兩個不同的研究流派:1)直接使用多種語言數據進行訓練的多語言模型和2)主要在英語數據上訓練的以英語為中心的模型。
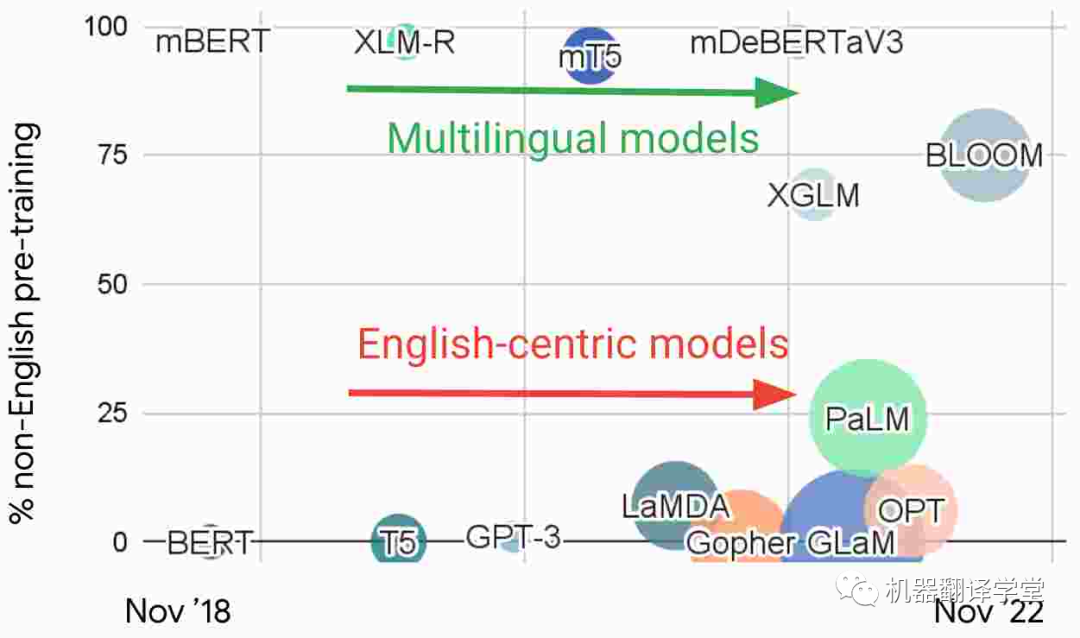
圖4. 近期一些大語言模型中預訓練數據中非英語數據的比例
以英語為中心的模型構成了NLP研究主流的基礎,雖然這些模型越來越大,但它們并沒有變得更加多語言。例如,GPT-3[35]和 PaLM[36]可以在具有大量數據的語言之間翻譯文本。雖然它們已被證明能夠執行多語言的few-shot學習[37][38][39],但當prompt或輸入數據被翻譯成英語時,模型表現最佳。在非英語語言對之間翻譯或翻譯成低資源的語言時,它們的表現也很差。雖然 PaLM 能夠將非英語文本匯總為英語,但在生成其他語言的文本時卻很困難。
近期進展
原博客對于多語言領域的研究團體,領域會議等進行了介紹,由于篇幅原因,我們先略過這部分,只介紹在數據集和模型方面的進展,感興趣的同學可以去原博客學習。
數據集 :在研究方面,在一些代表性比較低的語言上,出現了一系列新的數據集,它們包含了許多任務,包括文本分類[40],情感分析[41],ASR,命名實體識別[42],問答[43]和摘要[44]等等。

圖5. MasakhaNER中非洲語言的命名實體注釋。PER、LOC 和 DATE 實體分別為紫色、橙色和綠色(Adelani 等人,2021 年)[42]
模型 :在多語言領域開發的新模型特別關注代表性不足的語言。有專注于非洲語言的基于文本(text-based)的語言模型,如AfriBERTa[45],AfroXLM-R[46]和KinyaBERT[47],以及印度尼西亞語言的模型,如IndoBERT[48][49]和IndoGPT[50]。對于印度語言,有IndicBERT[51]和MuRIL[52],以及語音模型,如CLSRIL[53]和IndicWav2Vec[54]。其中許多模型是先在幾種相關語言上進行訓練,因此能夠利用遷移學習,并且比較大的多語言模型更有效。論文[55]和[56]中論述了最近NLP和語音中的多語言模型的進展。
-03-
挑戰與機遇
挑戰1:有限的數據
可以說,多語言研究面臨的最大挑戰是世界上大多數語言可用的數據量有限。Joshi等人[57]根據其中可用的標記和未標記數據量將世界語言分為六個不同的類別。如下圖所示,世界上 88% 的語言屬于資源組 0,幾乎沒有可用的文本數據,而 5% 的語言屬于資源組 1,可用的文本數據非常有限。
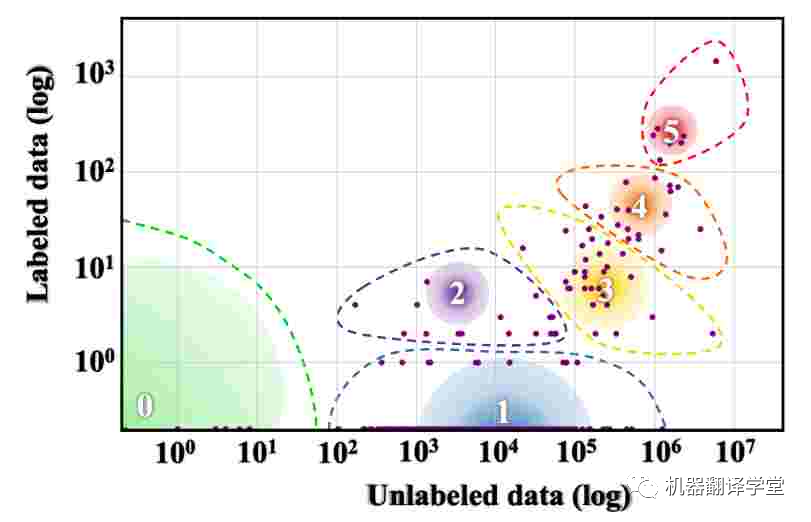
圖6. 世界語言的資源分布。漸變圓圈的大小表示該類中的語言數。(Joshi 等人,2020 年)[57]。
機遇1:真實世界的數據
我們如何克服世界語言資源分布的巨大差異?創建新數據的成本很高,尤其是在標注很少的語言中。出于這個原因,許多現有的多語言數據集,如XNLI[58],XQuAD[59]和XCOPA[60]都是基于已創建的英語數據集的翻譯。然而,這種基于翻譯的數據是有問題的。一種語言的翻譯文本可以被認為是該語言的一種“方言”,稱為“translationese”,它不同于這種語言本身[61]。因此基于翻譯的測試集可能會高估在類似數據上訓練的模型的性能,而這些模型在真實場景中的表現可能不盡人意[62]。
西方概念的過度學習 :除了這些問題之外,翻譯現有數據集會繼承原始數據的偏差。特別是,翻譯數據不同于不同語言用戶自然創建的數據。由于現有的數據集大多是由西方國家的工作者或研究人員創建的,因此它們主要反映了以西方為中心的概念。例如,ImageNet[63]是ML中最具影響力的數據集之一,它基于英語WordNet。因此,它包含了一些過于針對英語、但是不存在于其他文化中的概念[64]。
實用數據 :因此,根據實際使用情況提供的信息來創建數據集是十分重要的。一方面,數據應反映講該語言的人的背景比如文化背景、語言使用背景。一方面,它還減少了研究和實際場景之間的分布偏移,并使在學術數據集、或者在金融、法律等專業領域上開發的模型性能更好。
多模態數據 :世界上許多語言更常用而不是書面語言。我們可以通過關注來自多模態數據源(如無線電廣播和在線視頻)的信息以及組合來自多種模態的信息來克服對文本數據的依賴(和缺乏)。最近的語音和文本模型[65][66]在語音任務(如ASR,語音翻譯和文本到語音)上有了很大的進步。但是它們在純文本任務上的表現還是很差[67]。利用多模態數據以及研究不同語言的語言特征及其在文本和語音中的相互作用有很大的潛力[68]。
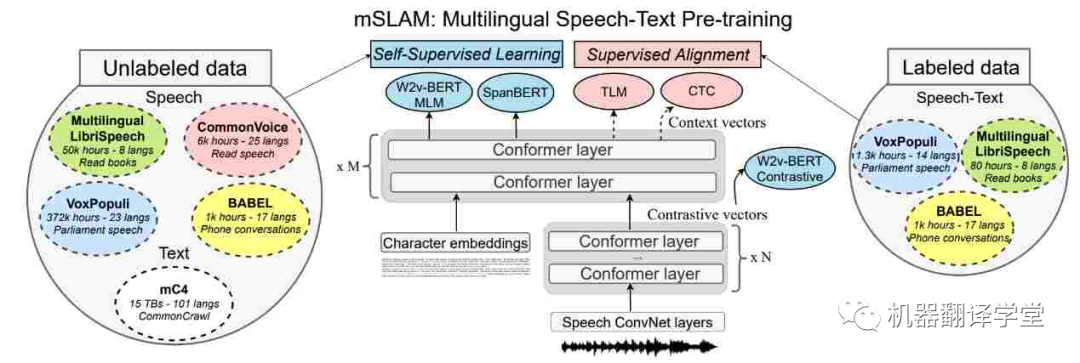
圖7. mSLAM 中的多語言語音文本預訓練模型,在未標記和標記的文本和語音數據集上聯合預訓練模型(Bapna 等人,2022 年)[67]。
最后,在為一些代表性不足的語言收集數據和開發模型時,人工智能面臨的挑戰包括數據管理、安全、隱私等等。為了應對這些挑戰,需要回答以下問題:如何保證數據和技術的適當使用和所有權[69]?是否有適當的方法來檢測和過濾有偏差的數據,并檢測模型中的偏差?在數據收集和使用過程中如何保護隱私?如何使數據和技術開發參與[70]?
挑戰2:有限的計算
代表性不足的語言的應用面臨的限制不僅僅是數據的缺乏,還有計算資源的匱乏。例如,GPU服務器即使在許多國家的頂尖大學中也很稀缺[4],而在使用代表性不足的語言的國家,計算的成本更高[71]。
機遇2:高效性
為了更好地利用有限的計算,我們必須開發更有效的方法。有關高效Transformer架構和高效NLP方法的綜述,請參閱[72]和[73]。由于預訓練模型廣泛可用,一個有前景的方向是通過參數高效方法優化這些模型,這已被證明比in-context learning更有效[74]。
一種常見的方法是是使用adapter[75][76],這是插入預訓練模型權重之間的小模塊。這些參數高效的方法可以通過分配額外模型容量給特定的語言來提升多語言的能力。它們還能夠讓多語言預訓練模型在預訓練期間沒見過的語言上有更好的表現[77][78]。
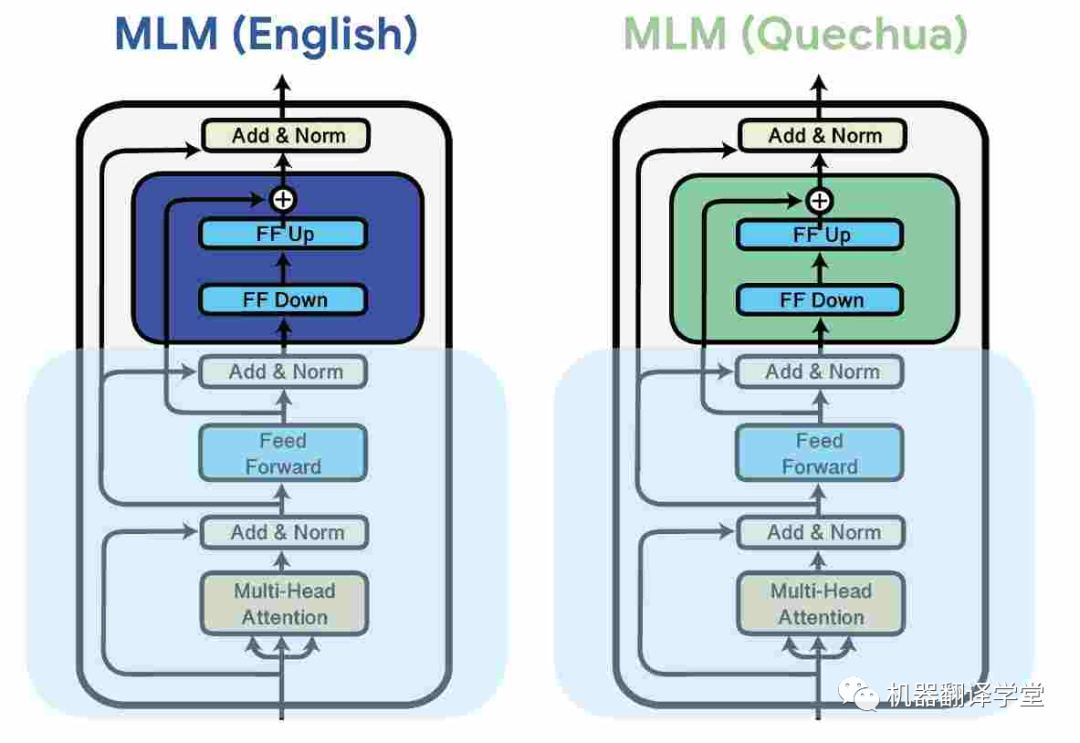
圖8.通過對每種語言的數據進行掩碼語言建模 (MLM) 學習針對特定于語言的adapter,同時凍結模型的其余參數(Pfeiffer 等人,2020 年)。[79]
與對模型進行微調[80]相比,adapter已被證明可以提高模型的魯棒性[81][82],從而提高學習效率,并且優于其他參數高效方法[83][84]。
跨語言參數高效遷移學習不只有adapter,還可以采用其他形式[85],例如稀疏子網[86]。這些方法已被應用于各種領域,比如機器翻譯[87][88]、ASR [89]和語音翻譯[90]。
挑戰3 語言類型特征
與現實世界的語言分布相比,現有數據集中的語言分布嚴重偏斜,并且具有可用數據的語言不能代表世界上大多數語言。代表性不足的語言具有許多西方語言中不存在的語言特征比如聲調,它存在于大約80%的非洲語言中。在Yorùbá中,詞匯音調區分了含義,例如,在以下單詞中:igbá(“葫蘆”,“籃子”),igba(“200”),ìgbà(“時間”),ìgbá(“花園雞蛋”)和igbà(“繩子”)。在阿坎語氣中,語法語氣區分習慣動詞和狀態動詞,例如Ama dá ha(“Ama睡在這里”)和Ama dàha(“Ama睡在這里”)。現有的NLP模型對于語言的音調研究還較少。
機遇3 特殊化處理
對于大多數代表性不足的語言,計算和數據是有限的。因此,將一定數量的先驗知識納入我們的語言模型以使它們對這些語言更有用是合理的。
比如說在tokenize的過程中,因為面對具有豐富的詞匯形態或者有數據有限的語言,不夠好的tokenize方法會導致分詞結果較差。我們可以修改算法以首選多種語言共享的token[91],保留token的形態結構[92],或者使tokenize的算法面對錯誤的分割時更魯棒[93]。
除此之外,許多代表性不足的語言屬于類似語言的群體,即某一個語系。因此,專注于這些語系的模型可以更容易地共享跨語言的信息。模型可以從相關語言的遷移學習中得到有用的知識。
過去的基于掩碼的一些算法對于多語言的學習有一定的效果,比如whole word masking[94]和PMI-masking[95],但考慮到語言的一些特征(如豐富的詞形結構或語氣),融入這些特征的預訓練目標可能會使得模型能夠更高效地學習。比如在基尼亞盧旺達語的KinyaBERT模型[47]中,它調整了模型的結構以融合有關語言形態的信息,使得模型在低資源但是詞形豐富的吉尼亞盧旺達語上有了更優秀的翻譯結果。
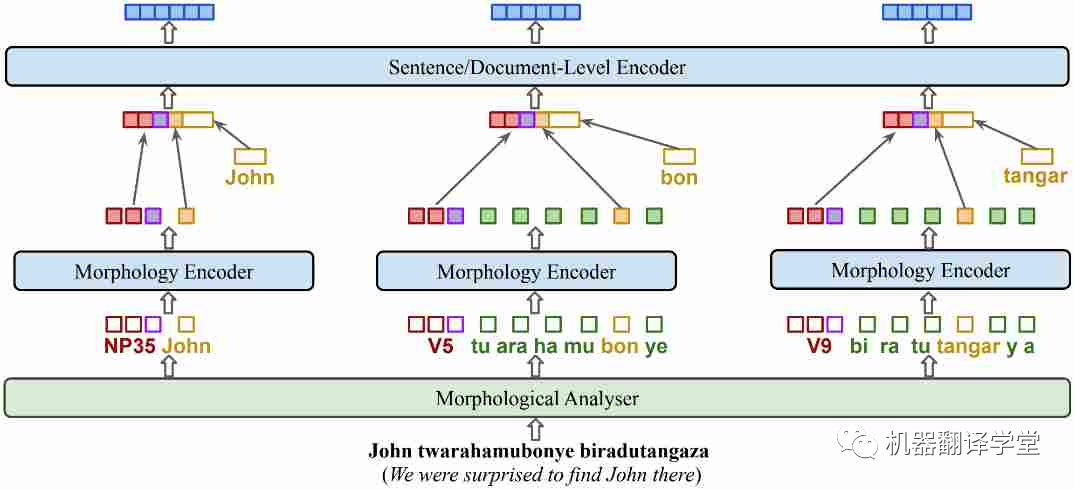
圖9.KinyaBERT模型。添加了針對不同詞形、單詞內部結構的encoder,對 POS 標簽、詞干和詞綴使用不同的嵌入
-05-
總結
雖然最近的多語言人工智能取得了巨大的進展,但仍有很多任務作要做。最重要的是,我們應該專注于創建反映語言用戶真實世界情況的數據,并開發滿足全球語言用戶需求的語言技術。雖然人們越來越意識到這項工作很重要,但需要一個團體來為世界語言開發公平的語言技術。Masakhane(祖魯語中的“讓我們一起建設”)!
審核編輯 :李倩
-
AI
+關注
關注
87文章
30113瀏覽量
268402 -
語言模型
+關注
關注
0文章
504瀏覽量
10245 -
自然語言處理
+關注
關注
1文章
612瀏覽量
13504
原文標題:多語言AI的現狀
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
多語言開發的流程詳解
HarmonyOS低代碼開發-多語言支持及屏幕適配
多語言綜合信息服務系統研究與設計
SoC多語言協同驗證平臺技術研究
基于Toradex多語言image的編譯與MUI切換演示
Multilingual多語言預訓練語言模型的套路
螞蟻集團開源高性能多語言序列化框架Fury解讀

基于LLaMA的多語言數學推理大模型
如何在TSMaster面板和工具箱中實現多語言切換

大語言模型(LLMs)如何處理多語言輸入問題






 工商網監
工商網監
評論