 如何訓練自己的ChatGPT
如何訓練自己的ChatGPT
LLM 這兩周不斷帶給我們震撼與驚喜。GPT-4 的發布讓大家對 LLM 的想象空間進一步擴大,而這些想象在本周眼花繚亂的 LLM 應用發布中逐漸成為現實,下面分享一位朋友訓練ChatGPT的完整方案,供大家參考~
LLM 相關的開源社區這兩周涌現了很多優秀的工作,吸引了很多人的關注。其中,我比較關注的是 Stanford 基于 LLaMA 的 Alpaca 和隨后出現的 LoRA 版本 Alpaca-LoRA。原因很簡單,便宜 。
Alpaca 宣稱只需要 600$ 不到的成本(包括創建數據集),便可以讓 LLaMA 7B 達到近似 text-davinci-003 的效果。而 Alpaca-LoRA 則在此基礎上,讓我們能夠以一塊消費級顯卡,在幾小時內完成 7B 模型的 fine-turning。
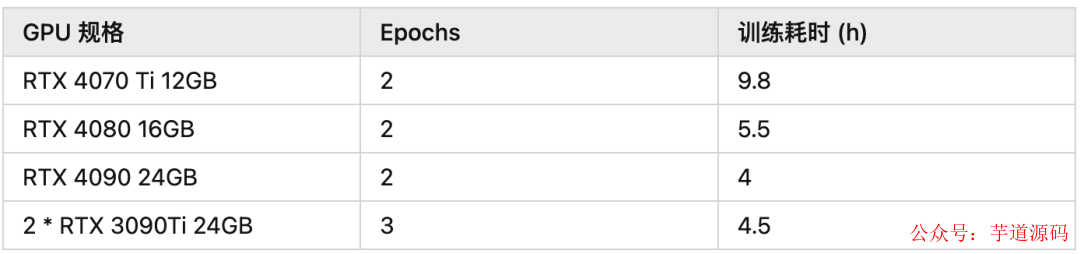
根據大家分享的信息,fine-tune 7B 模型僅需要 8-10 GB vram。因此我們很有可能可以在 Google Colab 上完成你所需要的 fine-tune!
那么,說干就干!
為什么要訓練自己的 ChatGPT ?
我想到了以下的方面:
- 對我個人而言,這非常非常 cooooool !
- 讓模型能夠講我熟悉的語言
- 讓模型替我寫注釋和測試代碼
- 讓模型學習產品文檔,幫我回答用戶提出的小白問題
- ...
計劃
那么,為了訓練自己的 Chat我們需要做那些事兒呢? 理論上需要如下步驟:
第一步:準備數據集
fine-tune 的目標通常有兩種:
- 像 Alpaca 一樣,收集 input/output 生成 prompt 用于訓練,讓模型完成特定任務
- 語言填充,收集文本用于訓練,讓模型補全 prompt。
以第一種目標為例,假設我們的目標是讓模型講中文,那么,我們可以通過其他 LLM (如 text-davinci-003)把一個現有數據集(如 Alpaca)翻譯為中文來做 fine-tune。實際上這個想法已經在開源社區已經有人實現了。
第二步:訓練并 apply LoRA
在第一步準備的數據集上進行 fine-tune。
第三步:合并模型(可選)
合并 LoRA 與 base 可以加速推理,并幫助我們后續 Quantization 模型。
第四步:quantization(可選)
最后,Quantization 可以幫助我們加速模型推理,并減少推理所需內存。這方面也有開源的工具可以直接使用。
https://github.com/megvii-research/Sparsebit/blob/main/large_language_models/llama/quantization/README.md
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
實踐
柿子挑軟的捏,我們從簡單的目標開始:讓模型講中文。
為了達成這個目標,我使用的數據集是 Luotuo 作者翻譯的 Alpaca 數據集,訓練代碼主要來自 Alpaca-LoRA。
準備
由于我打算直接使用 Alpaca-LoRA 的代碼,我們先 clone Alpaca-LoRA:
gitclonegit@github.com:tloen/alpaca-lora.git
下載數據集:
wgethttps://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.json
創建虛擬環境并安裝依賴(需要根據不同環境的 cuda 版本調整):
condacreate-nalpacapython=3.9
condaactivatealpaca
cdalpaca-lora
pipinstall-rrequirements.txt
訓練
單卡選手很簡單,可以直接執行:
pythonfinetune.py
--base_model'decapoda-research/llama-7b-hf'
--data_path'/path/to/trans_chinese_alpaca_data.json'
--output_dir'./lora-alpaca-zh'
雙卡選手相對比較麻煩,需要執行:
WORLD_SIZE=2CUDA_VISIBLE_DEVICES=0,1torchrun
--nproc_per_node=2
--master_port=1234
finetune.py
--base_model'decapoda-research/llama-7b-hf'
--data_path'/path/to/trans_chinese_alpaca_data.json'
--output_dir'./lora-alpaca-zh'
在我的環境下(2 * RTX 3090 Ti 24GB),需要額外配置 micro_batch_size 避免 OOM。
--micro_batch_size2
--num_epochs2
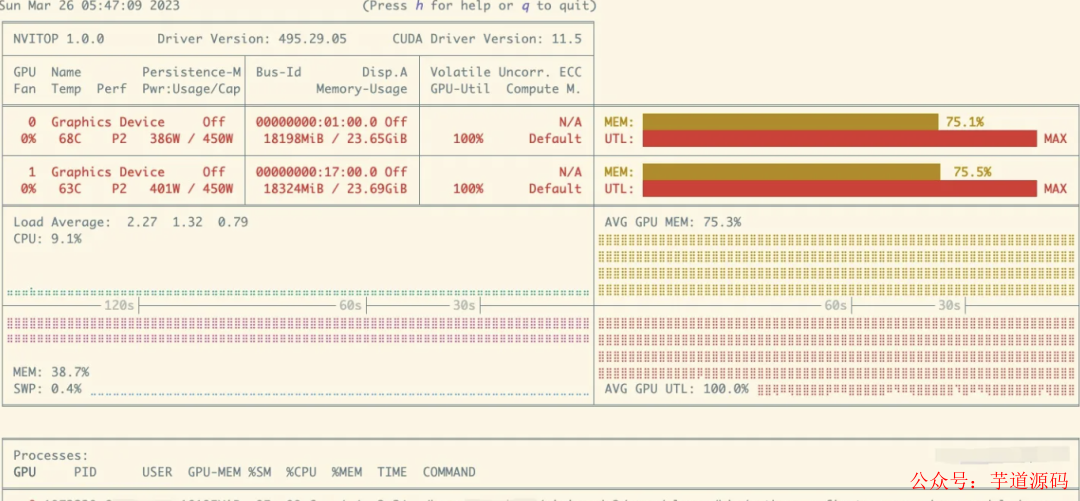
訓練的過程比較穩定,我在訓練過程中一直在用 nvitop 查看顯存和顯卡的用量:
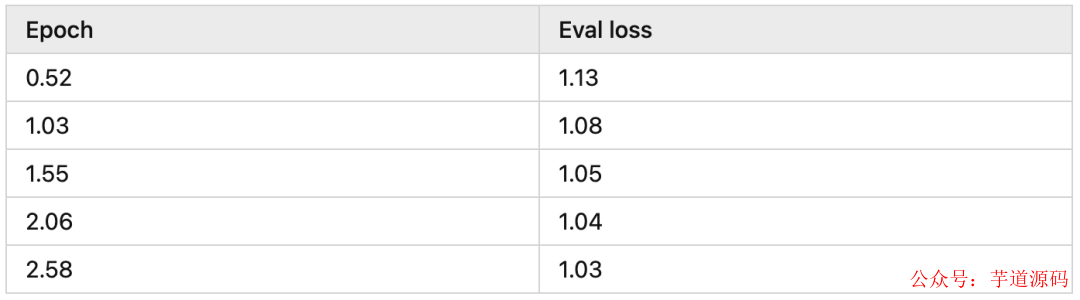
下面是我訓練時模型收斂的情況,可以看到差不多 2 epochs 模型就收斂的差不多了:
推理
單卡選手可以直接執行:
pythongenerate.py--base_model"decapoda-research/llama-7b-hf"
--lora_weights'./lora-alpaca-zh'
--load_8bit
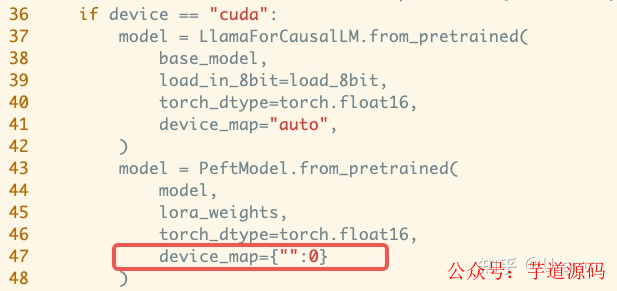
雙卡選手還是會麻煩點,由于現在還不支持雙卡推理,我手動修改了 generate.py,添加了第 47 行:
而后,執行上面的命令即可。
如果你的推理運行在服務器上,想要通過其他終端訪問,可以給 launch 方法添加參數:
server_name="0.0.0.0"
此時打開瀏覽器,享受你的工作成果吧 :D
加速推理
Alpaca-LoRA 提供了一些腳本,如 export_hf_checkpoint.py 來合并模型。合并后的模型可以通過 llamap.cpp 等項目達到更好的推理性能。
測試
最后,讓我們對比下原生 Alpaca 與自己 fine-tune 的 Alpaca,看看 fine-tune 到底有沒有讓模型學會講中文吧!
Good Examples
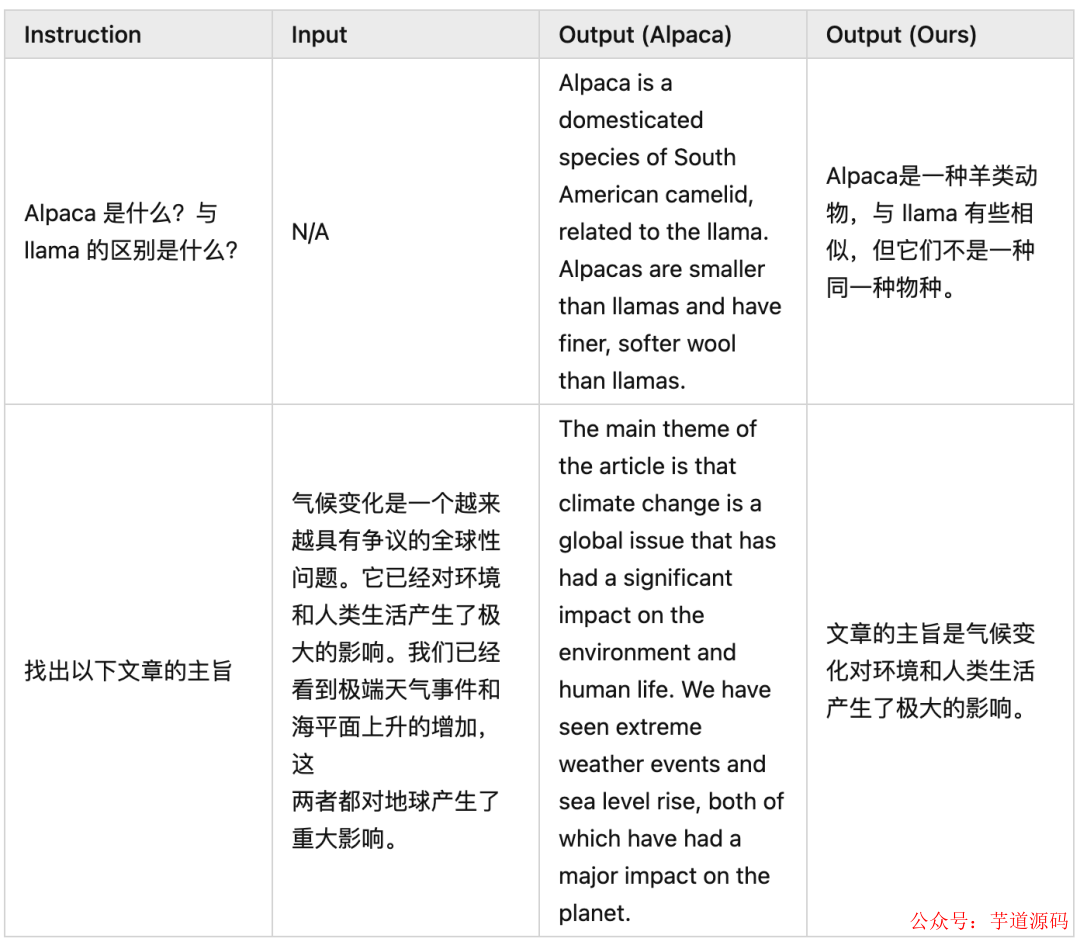
Bad Examples
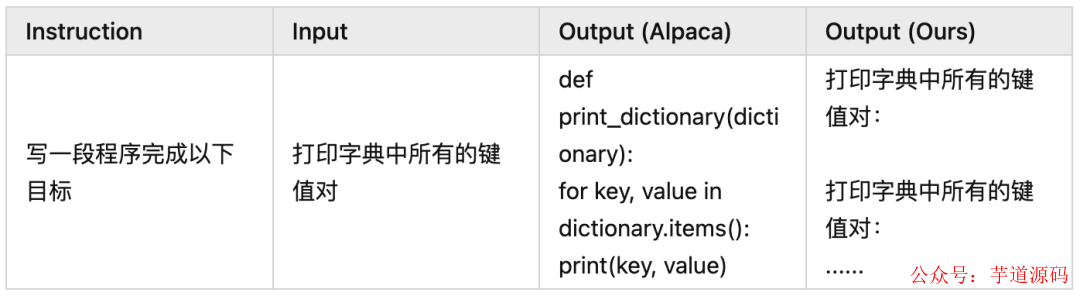
可以看出模型確實在講中文,也能依據中文的指令和輸入完成一些工作。但是由于 LLaMA 本身訓練數據大部分為英文以及 Alpaca 數據集翻譯后的質量不足,我們的模型有些時候效果不如原生 Alpaca。此時不得不感嘆高質量數據對 LLM 的重要性 。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
總結
作為一個分布式系統方向的工程師,fine-tune 一個 LLM 的過程遇到了不少問題,也有很多樂趣。雖然 LLaMA 7B 展現出的能力還比較有限,我還是很期待后面開源社區進一步的工作。
后續我也打算嘗試 fine-tune 特定目的的 LLM,比如讓 LLM 教我做飯,感興趣的朋友可以保持關注!
審核編輯 :李倩
-
模型
+關注
關注
1文章
3176瀏覽量
48721 -
數據集
+關注
關注
4文章
1205瀏覽量
24648 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7504
原文標題:如何訓練自己的ChatGPT
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
類ChatGPT訓練需高性能芯片大規模并聯,高速接口IP迎紅利時代
科技大廠競逐AIGC,中國的ChatGPT在哪?
ChatGPT系統開發AI人功智能方案
chatgpt怎么用
ChatGPT使用初探

如何訓練ChatGPT?中國版ChatGPT下月面世
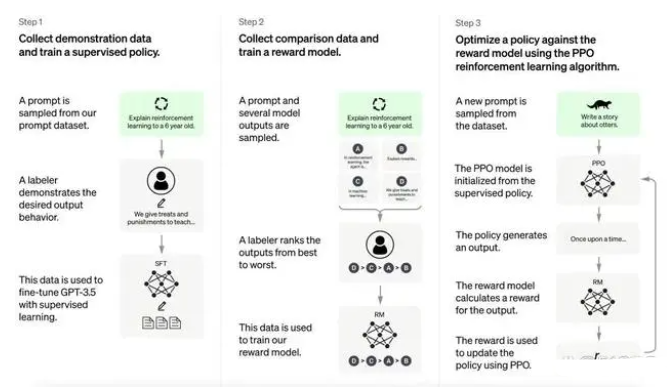
ChatGPT介紹和代碼智能
如何打造我們自己的ChatGPT
ChatGPT是什么?ChatGPT寫代碼的原理你知道嗎
chatgpt是什么原理
ChatGPT原理 ChatGPT模型訓練 chatgpt注冊流程相關簡介





 工商網監
工商網監
評論