 LangChain:為你定制一個專屬的GPT
LangChain:為你定制一個專屬的GPT
導語:用戶可以利用LangChain的模塊來改善大語言模型的使用,通過輸入自己的知識庫來“定制化”自己的大語言模型。
LLM(大語言模型) 是一項變革性的技術,它將人類的各類知識和邏輯能力打包進入了一個體積龐大的模型當中。
但是通常來說,包括當前公認效果最好的LLM GPT-4都會有一個問題——事實問題錯誤,也常被稱之為幻覺。幻覺(Hallucination),或者說人工智能幻覺是人工智能的自信反應。
當模型輸出欺騙性數據的傾向時,其使用的的訓練數據并不能證明輸出的合理性。人工智能幻覺的危險之處之一是模型的輸出看起來是正確的,其實它本質上是錯誤的。
基于這種前提條件下,若是直接將LLM利用于生產環境中(例如客服答疑,新形式文檔等)時,那么事實幻覺就可能會造成極其嚴重的影響。
但是通過LangChain,我們可以通過將其它計算資源和自有的知識庫結合。依托于當前的各類產品,在整合了當前的語料資源庫后,各類LLM都會進入到一個新的實用化發展階段。
LangChain介紹
LangChain是一個用于開發基于語言模型的應用程序開發框架。總的來說,LangChain是一個鏈接面向用戶程序和LLM之間的一個中間層。
它在 2023 年 3 月獲得了 Benchmark Capital 的 1000 萬美元種子輪融資,在近期又拿到了紅杉2000-2500萬美金的融資,估值已經提升到了2億美金左右。
LangChain 可以輕松管理與語言模型的交互,將多個組件鏈接在一起,并集成額外的資源,例如 API 和數據庫。其組件包括了模型(各類LLM),提示模板(Prompts),索引,代理(Agent),記憶等等。
當前GitHub上的熱門項目Auto-GPT和Babyagi所使用的鏈式思考能力都是由LangChain啟發而來。
LangChain項目主頁圖
LangChain工作流程
本次重點介紹LangChain搭配自有的知識庫讓LLM發揮更大功能的流程。
在缺少了上下文的情況下,即使是目前公認最頂級的LLM GPT-4也無法回答部分需要特定領域的知識。
而要是想僅用自有知識庫來訓練出LLMs又是不可能的,這個時候最好的方法就是利用LangChain的模塊來改善LLM的使用,通過輸入自己的知識庫來“定制化”自己的LLM。
Question Answering over specific documents是一個寫在LangChain主頁的主推功能。翻譯過來就是 基于特定文檔的問答 。
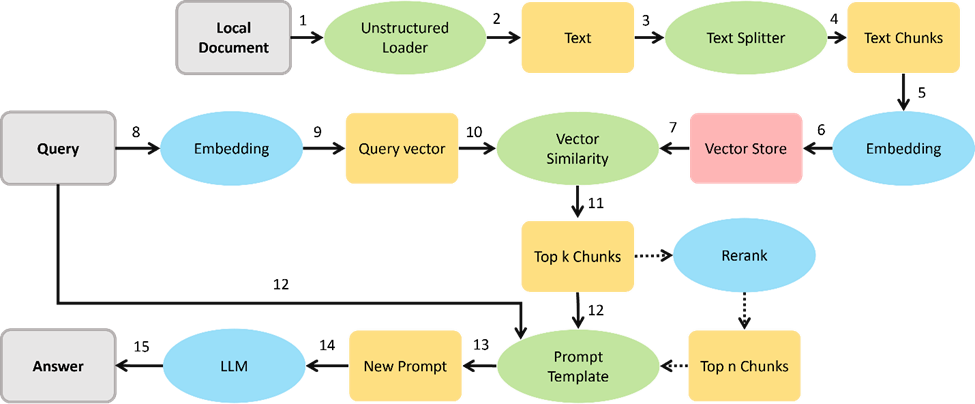
1.準備自定義數據
準備好需要LLM學習的內容,它可以是一個純文本文件或者其他類型的文本(不同類型的文本需要不同的文檔加載器)。
2.拆分文檔
一般來講,每個文檔都是由復雜長短句、多種語法結合寫作而成的。在進行輸入之前,就必須對這些文字進行解構處理。
對于英文LangChain一般會使用RecursiveCharacterTextSplitter處理。由于中文的復雜性,會使用到jieba等處理工具預處理中文語句。
3.文本嵌入(Embeddings)
處理完文本之后,就可以對文本進行嵌入(Embeddings)了。通過調用OpenAI的Embeddings API將文本向量化。在這步處理之后,文本就已經不再是文字,而是以向量化存儲的信息。
再使用一個開源的Embeddings數據庫ChromaDB保存Embeddings數據,就可以達到使用數據長期存儲和快速調用。
圖:將原文本嵌入
4.使用鏈(Chain)對矢量數據庫進行問答
在擁有了嵌入數據之后,我們就可以利用LangChain的強大鏈功能來執行我們的問答。這時就可以通過自然語言對于文檔內容進行提問了。
通過LangChain回答問題/完成任務
LangChain可能的應用場景
當前的AI熱潮吸引了很多人,而除了ChatGPT這類問答還有New Bing這種搜索服務外,并沒有什么可以將LLM商業化的案例。甚至可以說只有New Bing才是目前唯一一個成功的商業化案例。
LangChain為所有人提供了一個新的商業化方案。此前有將LLM導入客服軟件中應用的方案,但是由于LLM容易出現事實幻覺而無法實施。
同時,將所需內容通過Prompt導入LLM的想法也由于LLM的對話(Context)輸入限制而不可能實施。LangChain則通過將數據向量化避免了使用輸入限制,從而將所需內容導入LLM進行問答。
當下的人工成本逐漸提升,例如淘寶客服等人工密集型產業的成本逐步提升。當前的智能問答距離可用仍有較遠的距離。
通過已經預訓練好的LLM是一個快速降本增效的方案。基于每個產品的數據,可以將數據引入LLM中,讓LLM接替客服工作,準確、快速的回答客戶的定制化問題,同時語氣貼合自然口吻,避免了情緒化工作。
基于文檔的工作還可以在各類公司培訓和智能化文檔方面提供作用。很多產品文檔隨著時間的積累變得越來越復雜,多層跳轉也會讓人學習起來效率低下且不適。
此時基于LangChain就可以將文檔重新梳理,輸出為大綱類,在使用的時候可以隨時通過問答的形式將內容輸出。類似于新員工培訓和產品說明書等等場景都可以有所應用。這就極大的拓寬了文字類LLM的使用場景。
基于LangChain的問答
除了直接與人交互的方面外,還可以導入特定領域的知識庫,實時更新LLM的內容,讓LLM的知識時刻處于最新的狀態。依賴于此,LangChain除了可以完成自然語言文檔搜索外,還可以基于及時的資源進行快速開發。
導入資源后LangChain開發出的網頁
當前LangChain的局限性
目前,由于整個AI生態還處于一種快速發展期,各類工具和平臺還沒有完全成熟,因此LangChain的各類鏈和模塊的定制性和功能都還不夠強大。對于有高性能場景需求和定制化任務的可能需要自己重新修改。
事實合法性也是未來需要解決的一個痛點。LLM的各類越獄層出不窮。雖然在引入了嵌入之后LLM只會對文檔內容進行問答,但是仍然需要有一套額外的監督系統防止出現任何非法的回答。
同時當前LangChain還有使用難度較高等問題。目前的各類AI工具都面臨著普通用戶無法輕松駕馭等等的問題,而LangChain的問題更盛。
普通產品或者開發者的上手學習成本較高,使用起來難度很大。這一切都需要社區和商業資本的共同投入才有可能解決。
結語
LangChain是當前眾多的AGI實驗性工具的基石項目。基于鏈(Chain)的LLM調用思維勢必會貫穿未來LLM的發展生態。
提前關注AI發展動向,關注LangChain的開發進度,會對未來的AI應用落地有極大的幫助。
審核編輯 :李倩
-
AI
+關注
關注
87文章
30172瀏覽量
268433 -
數據庫
+關注
關注
7文章
3766瀏覽量
64277 -
GPT
+關注
關注
0文章
351瀏覽量
15315
原文標題:LangChain:為你定制一個專屬的GPT
文章出處:【微信號:alpworks,微信公眾號:阿爾法工場研究院】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LangChain框架關鍵組件的使用方法
OpenAI解鎖GPT-4o定制功能,助力企業精準優化AI應用
OpenAI api key獲取并可調用GPT-4.0、GPT-4o、GPT-4omini
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜

如何為MOTIX TLE9879X MCU配置500KHz的GPT中斷?
寶塔面板Docker一鍵安裝:部署GPTAcademic,開發私有GPT學術優化工具
OpenAI CEO: GPT-4o and GPT-5引領未來12個月編程領域,GPT-5更具潛力
【Longan Pi 3H 開發板試用連載體驗】給ChatGPT裝上眼睛,并且還可以語音對話:8,GPT接入,功能整合完成項目
使用TC21x的GPT實現1m計時器執行定時任務,怎么配置GTM和GPT?
探索LangChain:構建專屬LLM應用的基石
虹科分享 | 用Redis為LangChain定制AI代理——OpenGPTs
用Redis為LangChain定制AI代理——OpenGPTs

LangChain 0.1版本正式發布
工程師說 | 使用Chat-GPT為RL78 MCU(Arduino)編寫AI代碼






 工商網監
工商網監
評論