 什么是無聲語音接口?
什么是無聲語音接口?
可穿戴設備依賴于具有標準物理能力的人機界面,如語音、觸摸或運動。雖然這種形式的機器交互適用于大多數消費者,但殘疾人可能很難或無法操作標準的可穿戴設備。為了使更多人能夠使用可穿戴設備,研究人員正在研究新的人機界面。
最近,康奈爾大學的一個團隊發表了一篇論文,描述了一副為不能發聲的用戶配備了無聲語音接口(SSI)的智能眼鏡。本文將討論無聲語音接口和來自康奈爾大學的可穿戴原型。
什么是無聲語音接口?
無聲語音接口(Silent speech interface,簡稱SSI)允許人們無需發聲就能與機器互動。雖然AI助手(如蘋果的Siri)等技術是通過聲音交流工作的,但SSI通過與語音相關的動作來完成交流。
SSI技術通過嘴巴和舌頭的運動而不是聲音來識別語音。為了做到這一點,SSI依賴于各種不同的傳感器,包括放置在嘴巴附近的振動傳感器,用于檢測人們嘴巴的振動,以及跟蹤和分類與語音相關運動的攝像頭。在許多情況下,這些信息會被機器學習算法處理,該算法會解釋嘴巴的動作,并將其翻譯成文字。
雖然大多數人可能找不到SSI的用途,但這項技術對于因疾病或受傷而失聲的人來說是必不可少的,可以讓他們更容易地交流。例如,患有聲帶損傷或影響語言的神經系統疾病的患者可以從SSI中獲益良多。
康奈爾大學開發無攝像頭SSI眼鏡
最近,康奈爾大學的研究人員在SSI技術方面取得了重大進展,發明了基于SSI的智能眼鏡。
該系統被稱為EchoSpeech,是一種新穎的、侵入性最小的SSI技術,它使用低功率有源聲學傳感來捕捉由無聲語音引起的細微皮膚變形,并將這些信息轉換為可操作的數據。這款智能眼鏡的原型建立在康奈爾大學之前對一種類似的聲學傳感可穿戴設備(“EarIO”)的研究基礎上,EarIO可以從耳朵內追蹤面部運動。
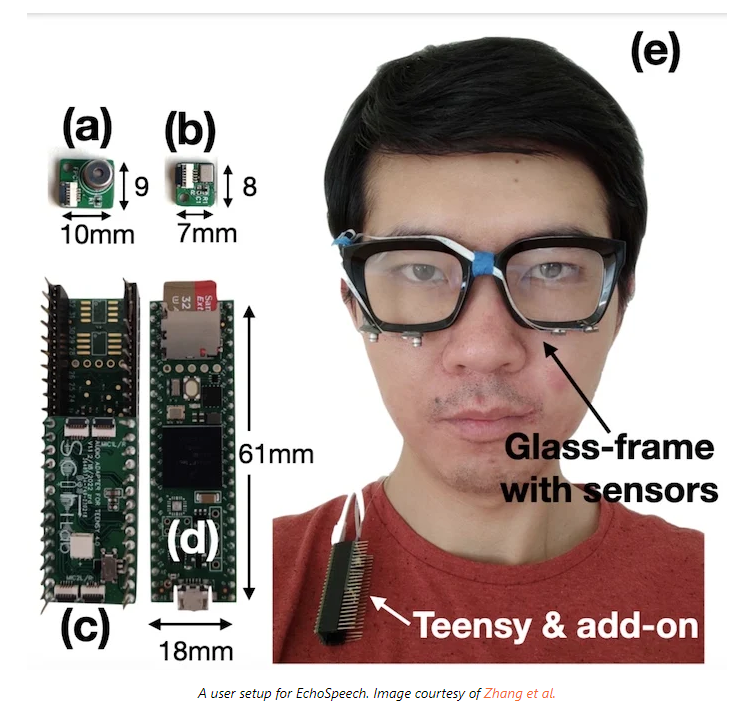
該系統依靠安裝在眼鏡框架上的一系列揚聲器和麥克風向皮膚發射聽不見的聲波。發出的聲波產生沿多條路徑傳播的回聲,并被系統解釋推斷為佩戴者的無聲語音。EchoSpeech完全可以在標準的智能手機上運行,只需要1到6分鐘的訓練數據,并以73.3 mW的低功耗實時運行。該團隊的深度學習算法可以實時分析回聲,準確率約為95%。
該系統通過12名用戶研究進行了評估,成功展示了識別31個獨立命令和三到六位連接數字的能力,單詞錯誤率(WER)分別為4.5%(標準3.5%)和6.1%(標準4.2%)。此外,在行走和噪聲注入等場景中測試了系統的魯棒性。
更私密、低功耗、易使用
大多數SSI技術使用面部攝像頭,從用戶和與其交流的人那里收集數據。除了造成隱私問題外,可穿戴攝像頭還會收集高帶寬視頻數據。
由于EchoSpeech不需要可穿戴攝像機,設備只捕捉音頻數據,這比圖像或視頻數據需要的帶寬要少得多,并且可以通過藍牙實時發送到手機。隱私信息永遠不會脫離用戶的控制,因為數據是在智能手機上本地處理的(不用在云中處理)。研究人員表示,純音頻傳感器的電池效率也更高:音頻傳感器可以工作10個小時,而攝像頭只能工作30分鐘。
康奈爾大學的研究小組表示,他們發現EchoSpeech在很多應用中都有應用價值,從默念密碼來解鎖智能手機,到跳過播放列表中的歌曲。該設備還可以與智能手機配對,在說話不方便的地方與他人交談,比如嘈雜的餐廳或安靜的圖書館。研究人員表示,該界面與手寫筆和CAD等設計軟件兼容,從而消除了對鼠標和鍵盤的需求。
審核編輯:劉清
-
人機界面
+關注
關注
5文章
524瀏覽量
44103 -
SSI
+關注
關注
0文章
38瀏覽量
19212 -
可穿戴設備
+關注
關注
55文章
3807瀏覽量
166852
原文標題:什么?無聲語音接口?
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
omap4460開發板錄音后播放無聲音是怎么回事?
TLV320AIC33更換后數字mic無聲音是怎么回事?
功放SR5200中置音箱無聲音是什么原因?怎么解決?
TMS320C6000 MCBSP轉語音帶音頻處理器(VBAP)接口

tas5711 EVM配置以后無聲音輸出是怎么回事?
TAS2552+AM4379為什么無聲音輸出?
TLV320AIC23B-Q1無聲音輸出的原因?
LM4916規格書中的BTL方案接后無聲音輸出,是什么問題呢?
LM4991 WSON封裝手工搭建的電路,通電后揚聲器無聲音,為什么?
谷歌AI新突破:為無聲視頻智能配音
MCU配對簡化了語音控制接口設計
微軟發布視頻編輯新功能:自動消除無聲片段
未來之聲 | 人形機器人說話篇:無聲!






 工商網監
工商網監
評論