") 2023年使用樹(shù)莓派和替代品進(jìn)行深度學(xué)習(xí)
2023年使用樹(shù)莓派和替代品進(jìn)行深度學(xué)習(xí)
介紹
此頁(yè)面可幫助您在Raspberry Pi或Google Coral或Jetson Nano等替代品上構(gòu)建深度學(xué)習(xí)模式。有關(guān)深度學(xué)習(xí)及其限制的更多一般信息,請(qǐng)參閱深度學(xué)習(xí)。本頁(yè)更多地介紹一般原則,因此您可以很好地了解它的工作原理以及您的網(wǎng)絡(luò)可以在哪個(gè)板上運(yùn)行。有關(guān)軟件安裝的分步方法,請(qǐng)參見(jiàn) Raspberry Pi 4 和替代品的深度學(xué)習(xí)軟件。
一個(gè)廣泛使用的深度學(xué)習(xí)軟件包是TensorFlow。讓我們從名稱開(kāi)始。什么是tensor?
你可以有一個(gè)數(shù)字列表。這在數(shù)學(xué)中稱為向量。
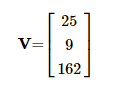
如果向此列表添加維度,則會(huì)得到一個(gè)矩陣。
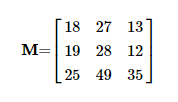
例如,通過(guò)這種方式,您可以顯示黑白圖像。每個(gè)值代表一個(gè)像素值。行數(shù)等于高度,列數(shù)與圖像的寬度匹配。如果你再次向矩陣添加一個(gè)額外的維度,你會(huì)得到一個(gè)tensor。

彼此重疊的 2D 矩陣堆棧。或者換句話說(shuō),一個(gè)矩陣,其中各個(gè)數(shù)字被一個(gè)向量所取代,一個(gè)數(shù)字列表。例如 RGB 圖片。每個(gè)單獨(dú)的像素(矩陣中的元素)由三個(gè)元素組成;一個(gè) R、G 和 B 分量。 這是tensor(n維數(shù)字?jǐn)?shù)組)的最簡(jiǎn)化定義。

TensorFlow和數(shù)學(xué)中的張量之間的定義存在細(xì)微差異。
在數(shù)學(xué)中,tensor不僅僅是矩陣中的數(shù)字集合。在這里,tensor必須遵守某些變換規(guī)則。這些規(guī)則與在不改變其結(jié)果的情況下改變tensor所在的坐標(biāo)系有關(guān)。大多數(shù)tensor都是 3D 的,并且具有與 Rubric 立方體相同數(shù)量的元素。每個(gè)單獨(dú)的立方體通過(guò)一組正交向量預(yù)測(cè)物理對(duì)象在應(yīng)力(tensor)下將如何變形。
如果觀察者在現(xiàn)實(shí)世界中占據(jù)另一個(gè)位置,物體本身的變形不會(huì)改變;顯然,它仍然是同一個(gè)對(duì)象。但是,給定此新位置,所有向量或公式都將更改。它們將以變形的結(jié)果保持不變的方式發(fā)生變化。可以把它想象成兩座塔頂之間的距離。無(wú)論你站在哪里,這都不會(huì)改變。然而,從你的位置到這些頂部繪制矢量會(huì)根據(jù)你的位置、你的原點(diǎn)而變化。
在tensor的上下文中,甚至還有第三個(gè)含義,即神經(jīng)tensor網(wǎng)絡(luò)。
這個(gè)特殊神經(jīng)網(wǎng)絡(luò)中的tensor在兩個(gè)實(shí)體之間建立了關(guān)系。狗有尾巴,狗是哺乳動(dòng)物,哺乳動(dòng)物需要氧氣等。
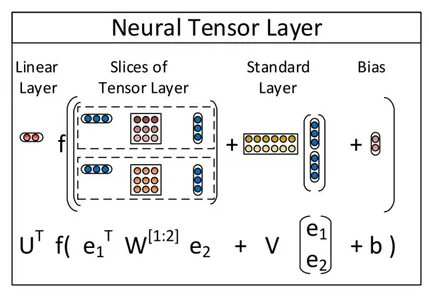
最后兩個(gè)定義只是為了完整起見(jiàn)而給出的。許多人認(rèn)為TensorFlow與這些解釋之一有關(guān)。事實(shí)并非如此。
重量矩陣
TensorFlow和其他深度學(xué)習(xí)軟件最重要的構(gòu)建塊是n維數(shù)組。本節(jié)介紹這些數(shù)組的用法。每個(gè)深度學(xué)習(xí)應(yīng)用程序都由給定的神經(jīng)節(jié)點(diǎn)拓?fù)浣M成。每個(gè)神經(jīng)節(jié)點(diǎn)通常構(gòu)造如下。
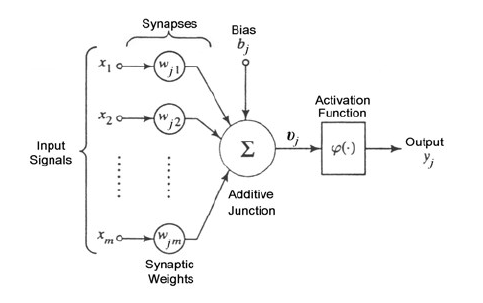
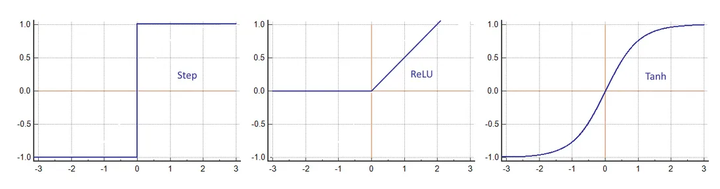
每個(gè)輸入乘以一個(gè)權(quán)重并相加。與偏差一起,結(jié)果進(jìn)入激活函數(shù)φ。這可以是簡(jiǎn)單的步進(jìn)運(yùn)算,也可以是更復(fù)雜的函數(shù),例如雙曲正切。
輸出是網(wǎng)絡(luò)中下一層的輸入。網(wǎng)絡(luò)可以由許多層組成,每層都有數(shù)千個(gè)單獨(dú)的神經(jīng)元。
如果您查看一個(gè)層,則相同的輸入數(shù)組可以應(yīng)用于不同的權(quán)重?cái)?shù)組。每個(gè)都有不同的結(jié)果,以便可以從單個(gè)輸入中提取各種特征。
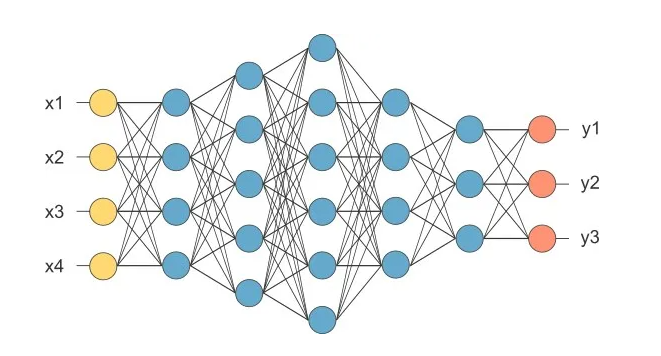
在上面的網(wǎng)絡(luò)中,四個(gè)輸入(黃色)都完全連接到第一層的四個(gè)神經(jīng)元(藍(lán)色)。它們連接到下一層的五個(gè)神經(jīng)元。跟隨另一個(gè)由六個(gè)神經(jīng)元組成的內(nèi)層。經(jīng)過(guò)連續(xù)兩層四層和三層后,達(dá)到具有三個(gè)通道的輸出(橙色)。
這樣的方案導(dǎo)致向量矩陣乘法。
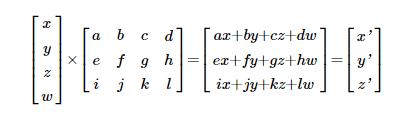
這里,四個(gè)值(x,y,z,w)的輸入層與權(quán)重矩陣相乘。x 輸入的權(quán)重 a,b,c,d,導(dǎo)致輸出端出現(xiàn) x'。y' 輸出的權(quán)重 e,f,g,h 等。還有其他方法可以描述這種乘法,例如,
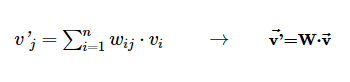
其中 v 是輸入向量 (x,y,z,w),v' 是輸出 (x',y',z')。 向量矩陣乘法是 TensorFlow 中執(zhí)行最多的操作之一,因此得名。
在將所有點(diǎn)放在一起之前,首先在 GPU 硬件中繞道而行。GPU 代表圖形處理單元,一種最初設(shè)計(jì)用于將 CPU 從沉悶的屏幕渲染任務(wù)中解放出來(lái)的設(shè)備。 多年來(lái),GPU變得更加強(qiáng)大。如今,它們擁有超過(guò)21億個(gè)晶體管,能夠執(zhí)行大規(guī)模的并行計(jì)算。 特別是在計(jì)算屏幕上每個(gè)像素的游戲中,需要這些計(jì)算能力。 移動(dòng)查看器的位置時(shí),例如,當(dāng)英雄開(kāi)始運(yùn)行時(shí),必須重新計(jì)算所有頂點(diǎn)。而這每秒25次以獲得平滑過(guò)渡。每個(gè)頂點(diǎn)都需要旋轉(zhuǎn)和平移。公式為:
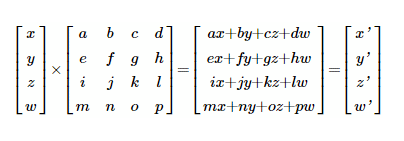
這里 (x,y,z,w) 是 3D 中的初始像素位置,(x',y',z',w') 是矩陣運(yùn)算后的新位置。如您所見(jiàn),這種類型的算術(shù)與神經(jīng)網(wǎng)絡(luò)相同。還有另一個(gè)興趣點(diǎn)。當(dāng)你看x'時(shí),它是四個(gè)乘積(ax+by+cz+dw)的總和。另一方面,y' 也是一個(gè)求和 (ex+fy+gz+hw)。但是要計(jì)算y',不需要知道決定x'(a,b,c和d)的值。它們彼此無(wú)關(guān)。您可以同時(shí)計(jì)算 x'和 y'。還有 z' 和 w' 就此而言。理論上,與其他結(jié)果沒(méi)有關(guān)系的每個(gè)計(jì)算都可以同時(shí)執(zhí)行。因此,GPU 的非常并行的架構(gòu)。當(dāng)今(2023 年)最快的 GPU 每秒能夠達(dá)到驚人的 125 TFLOP。
這就是 GPU 加速背后的整個(gè)想法。將所有張量傳輸?shù)?GPU 內(nèi)存,并讓設(shè)備在花費(fèi) CPU 的一小部分時(shí)間內(nèi)執(zhí)行所有矢量矩陣計(jì)算。如果沒(méi)有令人印象深刻的GPU計(jì)算能力,深度學(xué)習(xí)幾乎是不可能的。
TPU
在深度學(xué)習(xí)的巨大市場(chǎng)潛力的推動(dòng)下,一些制造商將GPU替換為TPU,即Tensor處理單元。除了矢量矩陣乘法,GPU 還有其他任務(wù)要做,例如頂點(diǎn)插值和著色、H264 壓縮、驅(qū)動(dòng) HDMI 顯示器等。通過(guò)僅將所有晶體管用于Tensor點(diǎn)積,吞吐量增加,功耗降低。第一代僅適用于 8 位整數(shù),后者也適用于浮點(diǎn)數(shù)。下面嵌入式板上的 TPU 都是基于整數(shù)的,除了 Jetson Nano。在此處閱讀深入的文章。
GPU陷阱
關(guān)于 GPU 算術(shù),必須考慮幾點(diǎn)。
首先,堅(jiān)持矩陣。GPU 架構(gòu)專為這種操作而設(shè)計(jì)。編寫(xiě)一個(gè)廣泛的 if-else 結(jié)構(gòu)對(duì)于 GPU 和整體性能來(lái)說(shuō)是災(zāi)難性的。
另一點(diǎn)是內(nèi)存交換會(huì)消耗很多效率。越來(lái)越多的數(shù)據(jù)從CPU內(nèi)存(圖像通常所在的位置)和GPU內(nèi)存的數(shù)據(jù)傳輸正在成為一個(gè)嚴(yán)重的瓶頸。您在 NVIDIA 的每個(gè)文檔中一遍又一遍地閱讀相同的內(nèi)容;矢量矩陣點(diǎn)積越大,執(zhí)行速度越快。
在這方面,請(qǐng)記住,Raspberry 及其替代品通常有一個(gè)用于 CPU 和 GPU 的大 RAM。它們僅共享相同的 DDR4 芯片。您的神經(jīng)網(wǎng)絡(luò)不僅必須適合程序內(nèi)存,而且還必須在 RAM 中留出空間,以便 CPU 內(nèi)核可以運(yùn)行。這有時(shí)會(huì)對(duì)網(wǎng)絡(luò)或要識(shí)別的對(duì)象數(shù)量施加限制。在這種情況下,選擇另一塊具有更多 RAM 的電路板可能是唯一的解決方案。所有這些都與GPU具有內(nèi)存庫(kù)的PC中的圖形卡形成鮮明對(duì)比。
另一個(gè)區(qū)別是視頻卡上的 GPU 使用浮點(diǎn)或半浮點(diǎn),有時(shí)也稱為小浮點(diǎn)。樹(shù)莓上的嵌入式 GPU 或替代板上的 TPU 使用 8 位或 16 位整數(shù)。您的神經(jīng)網(wǎng)絡(luò)必須適應(yīng)這些格式。如果無(wú)法做到這一點(diǎn),請(qǐng)選擇另一個(gè)具有浮點(diǎn)運(yùn)算的板,例如 Jetson Nano。
最后一個(gè)建議,不要過(guò)多地超頻 GPU。它們以低于 CPU 的頻率正常工作。ARM內(nèi)核中的一些Mali GPU運(yùn)行低至400 MHz。 超頻可以在冬季工作,但應(yīng)用程序可能會(huì)在仲夏動(dòng)搖。請(qǐng)記住,突然崩潰的是您在客戶端的視覺(jué)應(yīng)用程序,而不是您簡(jiǎn)單地重新啟動(dòng)游戲。
當(dāng)然,頁(yè)面上關(guān)于Raspberry上計(jì)算機(jī)視覺(jué)的評(píng)論也適用于這里。
Showstopper
您不能在 Raspberry Pi 或替代方案上訓(xùn)練深度學(xué)習(xí)模型。如果您沒(méi)有計(jì)劃環(huán)游世界,則不會(huì)。這些板缺乏計(jì)算機(jī)能力來(lái)執(zhí)行訓(xùn)練期間所需的大量浮點(diǎn)多加法。即使是Google Coral也無(wú)法訓(xùn)練網(wǎng)絡(luò),因?yàn)樵摪迳系腡PU僅適用于特殊的預(yù)編譯TensorFlow網(wǎng)絡(luò)。只有網(wǎng)絡(luò)中的最后一層可以稍作更改。盡管Jetson Nano具有浮點(diǎn)CUDA,但它仍然不能很好地在可接受的時(shí)間內(nèi)訓(xùn)練網(wǎng)絡(luò)。一夜之間完成是NVIDIA在這里的建議。因此,最后,您只能在這些板上導(dǎo)入并運(yùn)行已訓(xùn)練的模型。
云服務(wù)
如前所述,訓(xùn)練不是Raspberry Pi的選項(xiàng),也不是任何其他小型SBC的選擇。但是,有一條逃生路線。所有主要的科技公司都有云服務(wù)。其中許多還包括運(yùn)行配備 GPU 的 Linux 虛擬機(jī)的選項(xiàng)。現(xiàn)在,您擁有了觸手可及的 CUDA 加速的最先進(jìn)的 CPU。最好的免費(fèi)服務(wù)之一是谷歌,GDrive 上有 15 GB 的免費(fèi)空間,每天至少有 12 小時(shí)的免費(fèi)計(jì)算機(jī)時(shí)間。現(xiàn)在,只需一個(gè)簡(jiǎn)單的 Raspberry Pi 就可以在一定程度上訓(xùn)練您的深度學(xué)習(xí)模型。轉(zhuǎn)移訓(xùn)練(部分調(diào)整重量而不改變拓?fù)洌┦强尚械模驗(yàn)檫@是一項(xiàng)相對(duì)容易的任務(wù),您可以在幾個(gè)小時(shí)內(nèi)完成。另一方面,訓(xùn)練復(fù)雜的 GAN 需要更多的資源。它可能會(huì)迫使您購(gòu)買額外的電力。
實(shí)踐
第一步是安裝操作系統(tǒng),通常是Linux的衍生產(chǎn)品,如Ubuntu或Debian。這是容易的部分。
困難的部分是安裝深度學(xué)習(xí)模型。您必須弄清楚是否需要任何其他庫(kù)(OpenCV)或驅(qū)動(dòng)程序(GPU支持)。請(qǐng)注意,只有 Jetson Nano 支持 CUDA,這是 PC 上使用的大多數(shù)深度學(xué)習(xí)軟件包。如果您想加速神經(jīng)網(wǎng)絡(luò),所有其他板都需要不同的 GPU 支持。Raspberry Pi 或替代方案的 GPU 驅(qū)動(dòng)程序的開(kāi)發(fā)是一個(gè)持續(xù)的過(guò)程。查看網(wǎng)絡(luò)上的社區(qū)。
最后一步是將神經(jīng)網(wǎng)絡(luò)降低到可接受的比例。著名的 AlexNet 每 幀具有原始的 2 .3億次浮點(diǎn)運(yùn)算。這永遠(yuǎn)不會(huì)在簡(jiǎn)單的單個(gè) ARM 計(jì)算機(jī)或移動(dòng)設(shè)備上快速運(yùn)行。大多數(shù)模型都有某種減少策略。YOLO有Tiny YOLO,Caffe有Caffe2,TensorFlow有TensorFlow Lite。它們都使用以下一種或多種技術(shù)。
減小輸入大小。較小的圖像在第一層上節(jié)省了大量計(jì)算。
減少要分類的對(duì)象數(shù)量;它修剪了許多內(nèi)層的大小。
盡可能將神經(jīng)網(wǎng)絡(luò)從浮點(diǎn)數(shù)移植到字節(jié)。這也大大降低了內(nèi)存負(fù)載。
另一種策略是將浮點(diǎn)數(shù)減少到單個(gè)比特,即XNOR網(wǎng)絡(luò)。 這里討論了這個(gè)迷人的想法。
樹(shù)莓派和替代品的比較。
Jetson Nano vs Google Coral vs Intel Neural stick,這里是比較。列表中的三個(gè)奇怪的是JeVois,Intel Neural Stick和Google Colar USB加速器。第一個(gè)有一個(gè)板載攝像頭,可以做很多事情,你可以在這里閱讀。
Intel Neural Stick和Google Colar 加速器是帶有特殊 TPU 芯片的 USB 加密狗,可執(zhí)行所有Tensor計(jì)算。Intel Neural Stick附帶一個(gè)工具集,用于將 TensorFlow、Caffe 或 MXNet 模型遷移到神經(jīng)棒的工作中間表示 (IR) 圖像中。
Google Coral與特殊的預(yù)編譯TensorFlow Lite網(wǎng)絡(luò)配合使用。如果神經(jīng)網(wǎng)絡(luò)的拓?fù)浼捌渌璧牟僮骺梢栽赥ensorFlow中描述,那么它可能在Google Coral上運(yùn)行良好。但是,由于其少量的 1 GB RAM,內(nèi)存短缺仍然是一個(gè)問(wèn)題。
Google USB加速器具有特殊的后端編譯器,可將TensorFlow Lite文件轉(zhuǎn)換為加密狗TPU的可執(zhí)行模型。
Jetson Nano是唯一具有浮點(diǎn)GPU加速功能的單板計(jì)算機(jī)。它支持大多數(shù)模型,因?yàn)樗锌蚣苋鏣ensorFlow,Caffe,PyTorch,YOLO,MXNet和其他在給定時(shí)間都使用的CUDA GPU支持庫(kù)。價(jià)格也非常有競(jìng)爭(zhēng)力。這與蓬勃發(fā)展的深度學(xué)習(xí)市場(chǎng)有關(guān),英偉達(dá)不想失去其突出地位。
并非所有型號(hào)都可以在每臺(tái)設(shè)備上運(yùn)行。大多數(shù)情況下是由于內(nèi)存不足或硬件和/或軟件不兼容。在這些情況下,可以使用多種解決方案。但是,它們的開(kāi)發(fā)將非常耗時(shí),并且結(jié)果通常會(huì)令人失望。
Benchmarks總是需要討論的。有些人可能會(huì)發(fā)現(xiàn)其他 FPS 使用相同的模型。這一切都與所使用的方法有關(guān)。我們使用Python,NVIDIA使用C++,谷歌使用他們的TensorFlow和TensorFlow Lite。Raspberry Pi 3 B+具有板載2.0 USB接口。兩種神經(jīng)棒都可以處理3.0,這意味著它們可以更快地執(zhí)行。另一方面,新的Raspberry Pi 4 B具有USB 3.0,與其前身相比,這將導(dǎo)致更高的FPS。
表中顯示的數(shù)字純粹是從輸入到輸出執(zhí)行所需的時(shí)間。不考慮其他過(guò)程,例如捕獲和縮放圖像。順便說(shuō)一下,不使用超頻。
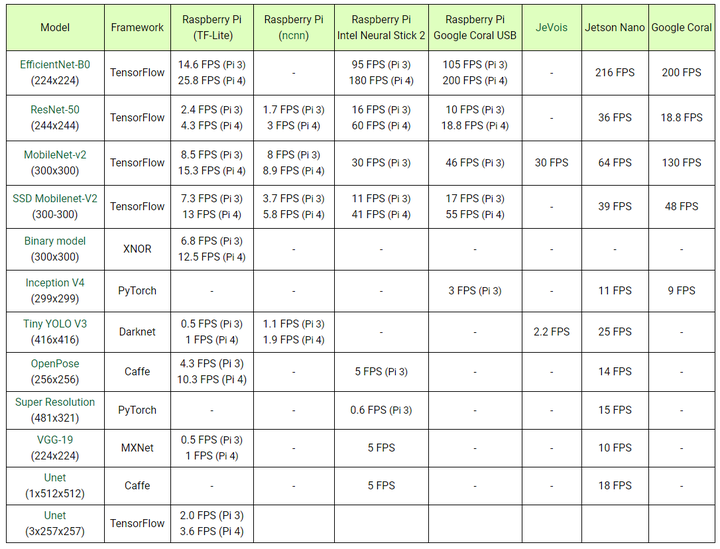
樹(shù)莓派和深度學(xué)習(xí)
我們?cè)?GitHub 上放置了一個(gè)深度學(xué)習(xí)庫(kù)和幾個(gè)深度學(xué)習(xí)網(wǎng)絡(luò)。結(jié)合簡(jiǎn)單的C++示例代碼,您可以在裸露的樹(shù)莓派上構(gòu)建深度學(xué)習(xí)應(yīng)用程序。它非常用戶友好。此頁(yè)面上的更多信息。

上面是在裸樹(shù)莓派上運(yùn)行的 TensorFlow Lite 模型(帶有 COCO 訓(xùn)練集MobileNetV1_SSD 300x300)的印象。
使用像 Ubuntu 這樣的 64 位操作系統(tǒng),如果您超頻到 24 FPS,您將獲得 1925MHz 。
使用像Raspbian這樣的常規(guī)32位系統(tǒng),一旦超頻到17FPS,您將獲得2000MHz 。
樹(shù)莓派和最近的替代品
下面在Raspberry Pi和適合實(shí)現(xiàn)深度學(xué)習(xí)模型的最新替代方案之間進(jìn)行選擇。 大多數(shù)芯片上都有廣泛的GPU或TPU硬件。請(qǐng)注意,報(bào)價(jià)是從 2023 年 1 月開(kāi)始的,即全球芯片嚴(yán)重短缺之前的價(jià)格。GPU 速度以 TOPS 表示,代表 Tera Operations P er Second。當(dāng)然,最高分將是當(dāng)您使用 8 位整數(shù)時(shí)。大多數(shù)供應(yīng)商給出這個(gè) 8 位分?jǐn)?shù)。如果你想在TFLOPS(Tera Floating Operations Per S econd)中有一個(gè)印象,請(qǐng)將數(shù)字除以四。雖然有些GPU不能處理單個(gè)8位,比如Jetson Nano,但分?jǐn)?shù)仍然在TOPS,只是出于比較的原因。
















單個(gè)微型 (40x48 mm) 可插拔模塊,具有完整的 I/O 和Edge TPU加速器。
審核編輯黃宇
-
樹(shù)莓派
+關(guān)注
關(guān)注
116文章
1699瀏覽量
105537 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120998 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60500
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
尋找松下TX2-12V的替代品
尋求Ubuntu13系統(tǒng)下軟件替代品……
MMBFJ176替代品??
請(qǐng)問(wèn)儀表放大器AD624有沒(méi)有便宜的完全兼容的替代品?
是否有TDA2003的替代品
如何使用ISP1763作為替代品?
Commodore 6540 ROM的替代品
MC908JL3ECDWE的替代品是什么?
鈷鎳錳(三元)正極材料---鈷酸鋰的理想替代品
樹(shù)莓派的學(xué)習(xí)設(shè)計(jì)方案合集

御芯微榮獲2023國(guó)產(chǎn)化替代品大賽先鋒獎(jiǎng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論