") 大數(shù)據(jù)的4個關(guān)鍵技術(shù)
大數(shù)據(jù)的4個關(guān)鍵技術(shù)
我們引用了大數(shù)據(jù)的4V特征
- Volume 大數(shù)據(jù)數(shù)據(jù)量大,數(shù)據(jù)量單位為T 或者P級
- Variety 數(shù)據(jù)類型多,大數(shù)據(jù)包含多種數(shù)據(jù)維度 比如 日志、視頻、圖片
- Value 價值密度低,商業(yè)價值高 比如監(jiān)控視頻,其中關(guān)鍵1-2秒可能具有極高的價值
- Velocity 要求處理速度塊
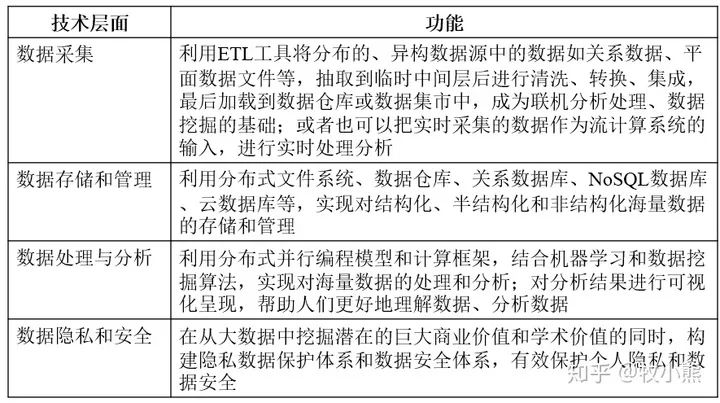
1.2 大數(shù)據(jù)的4個關(guān)鍵技術(shù)
1.3 ETL/ELT的區(qū)別
ETL 包含的過程是 Extract、Transform、Load的縮寫
包括了數(shù)據(jù)抽取 => 轉(zhuǎn)換 => 加載三個過程
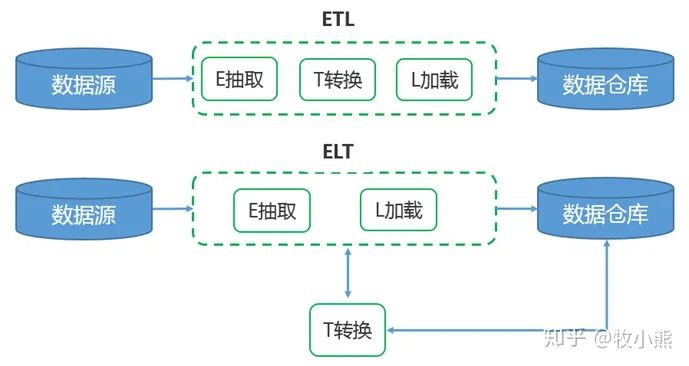
在數(shù)據(jù)源抽取后首先進行轉(zhuǎn)換,然后將轉(zhuǎn)換的結(jié)果寫入目的地
ETL 包含的過程是 Extract、Load、Transform的縮寫
ELT的過程是,在抽取后將結(jié)果先寫入目的地,然后利用數(shù)據(jù)庫的聚合分析能力或者外部計算框架,如Spark來完成轉(zhuǎn)換
目前數(shù)據(jù)主流框架是ETL,重抽取和加載,輕轉(zhuǎn)換,搭建的數(shù)據(jù)平臺屬于輕量級
ELT架構(gòu),在提取完成之后,數(shù)據(jù)加載會立即開始,更省時,數(shù)據(jù)變換這個過程根據(jù)后續(xù)使用需求在 SQL 中進行,而不是在加載階段
ELT框架的優(yōu)點就是保留了原始數(shù)據(jù),能夠?qū)⒃紨?shù)據(jù)展現(xiàn)給數(shù)據(jù)分析人員
ETL相關(guān)軟件:
- 商業(yè)軟件:Informatica PowerCenter、IBM InfoSphere DataStage、Oracle Data Integrator、Microsoft SQL Server Integration Services等
- 開源軟件:Kettle、DataX、Sqoop
1.4 大數(shù)據(jù)與數(shù)據(jù)庫管理系統(tǒng)
DataBase Management System,數(shù)據(jù)庫管理系統(tǒng),可以管理多個數(shù)據(jù)庫
目前關(guān)系型數(shù)據(jù)庫在DBMS中占據(jù)主流地位,常用的關(guān)系型數(shù)據(jù)庫有Oracle、MySQL和SQL Server
其中SQL就是關(guān)系型數(shù)據(jù)庫的查詢語言
SQL是與數(shù)據(jù)直接打交道的語言,是與前端、后端語言進行交互的“中臺”語言
SQL語言特點:
- 價值大,技術(shù)、產(chǎn)品、運營人員都要掌握SQL,使用無處不在
- 很少變化,SQL語言從誕生到現(xiàn)在,語法很少變化
- 入門并不難,很多人都會寫SQL語句,但是效率差別很大
除了關(guān)系型數(shù)據(jù)庫還有文檔型數(shù)據(jù)庫MongoDB、鍵值型數(shù)據(jù)庫Redis、列存儲數(shù)據(jù)庫Cassandra等
提到大數(shù)據(jù)就不得不說Hive
Hive是基于Hadoop的一個數(shù)據(jù)倉庫工具,用來進行數(shù)據(jù)提取、轉(zhuǎn)化、加載,這是一種可以存儲、查詢和分析存儲在Hadoop中的大規(guī)模數(shù)據(jù)的機制。
Hive與關(guān)聯(lián)型數(shù)據(jù)庫RDBMS相比
不足:
- 不能像 RDBMS 一般實時響應,Hive 查詢延時大
- 不能像 RDBMS 做事務(wù)型查詢,Hive 沒有事務(wù)機制
- 不能像 RDBMS 做行級別的變更操作(包括插入、更新、刪除)
優(yōu)點:
- Hive 沒有定長的 varchar 這種類型,字符串都是 string
- Hive 是讀時模式,保存表數(shù)據(jù)時不會對數(shù)據(jù)進行校驗,而在讀數(shù)據(jù)時將校驗不符合格式的數(shù)據(jù)設(shè)置為NULL
1.5 OLTP/OLAP
在數(shù)據(jù)倉庫架構(gòu)中有非常相關(guān)的2個概念,一個是OLTP,一個是OLAP
- OLTP( On-Line Transaction Processing )
聯(lián)機事務(wù)處理,主要是對數(shù)據(jù)的增刪改
記錄業(yè)務(wù)發(fā)生,比如購買行為,發(fā)生后,要記錄是誰在什么時候做了什么事,數(shù)據(jù)會以增刪改的方式在數(shù)據(jù)庫中進行數(shù)據(jù)的更新處理操作
實時性高、穩(wěn)定性強,ATM,ERP,CRM,OA等都屬于OLTP
- OLAP( On-Line Analytical Processing )
聯(lián)機分析處理,主要是對數(shù)據(jù)的分析查詢
當數(shù)據(jù)積累到一定的程度,需要做總結(jié)分析,BI報表=> OLAP
OLTP產(chǎn)生的數(shù)據(jù)通常在不同的業(yè)務(wù)系統(tǒng)中
OLAP需要將不同的數(shù)據(jù)源 => 數(shù)據(jù)集成 => 數(shù)據(jù)清洗 => 數(shù)據(jù)倉庫,然后由數(shù)據(jù)倉庫統(tǒng)一提供OLAP分析
2.大數(shù)據(jù)計算
2.1 大數(shù)據(jù)計算模式
| 大數(shù)據(jù)計算模式 | 解決問題 | 代表產(chǎn)品 |
|---|---|---|
| 批處理計算 | 針對大規(guī)模數(shù)據(jù)的批量處理 | MapReduce、Spark等 |
| 流計算 | 針對流數(shù)據(jù)的實時計算 | Storm、S4、Flume、Streams、Puma、DStream、Super Mario、銀河流數(shù)據(jù)處理平臺 |
| 圖計算 | 針對大規(guī)模圖結(jié)構(gòu)數(shù)據(jù)的處理 | Pregel、GraphX、Giraph、PowerGraph、Hama、GoldenOrb等 |
| 查詢分析計算 | 大規(guī)模數(shù)據(jù)的存儲管理和查詢分析 | Dremel、Hive、Cassandra、Impala等 |
2.2 Lambda大數(shù)據(jù)框架
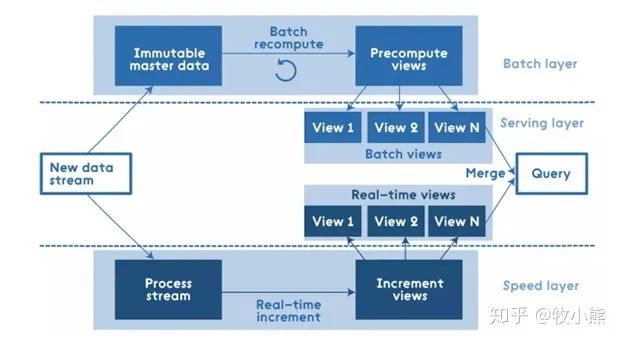
Lambda架構(gòu):
Batch Layer(批處理層),對離線的歷史數(shù)據(jù)進行預計算,能讓下游進行快速查詢。因為基于完整的數(shù)據(jù)集,準確性能得到保證。可以用Hadoop、Spark 和 Flink 等計算框架
Speed Layer(加速處理層),處理實時的增量數(shù)據(jù),加速層的數(shù)據(jù)不如批處理層完整和準確,但重點在于低延遲。可以用 Spark streaming、Storm 和 Flink 等計框架算
Serving Layer(合并層),將歷史數(shù)據(jù)計算與實時數(shù)據(jù)計算合并,輸出到數(shù)據(jù)庫,供下游分析
2.3 大數(shù)據(jù)典型技術(shù)
- Hadoop
一個文件系統(tǒng),外加一個離線處理框架MapReduce,由于提供的上層api不太友好,加上MapReduce 處理框架比較慢,基本上都用作文件系統(tǒng)
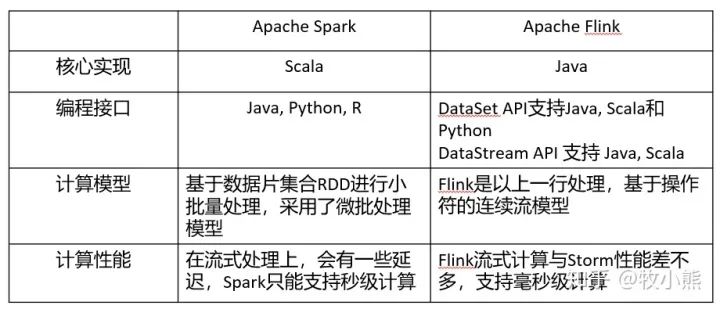
- Spark
本身是一個執(zhí)行引擎,不保存數(shù)據(jù),所以需要外部的文件系統(tǒng)(通常會基于hadoop)提出了內(nèi)存計算的概念,即盡可能把數(shù)據(jù)放到內(nèi)存中,還提供了良好的上層使用接口,包括spl語句(spark sql)處理數(shù)據(jù)十分方便。相比 Hadoop MapReduce 獲得了百倍的性能提升,基本上用它來做離線數(shù)據(jù)處理
- Flink
分布式實時計算框架,具有超高的性能,支持Flink流式計算與Storm性能差不多,支持毫秒級計算
Spark 和 Flink的區(qū)別
3.大數(shù)據(jù)實踐
本文主要講解了大數(shù)據(jù)的概念和基礎(chǔ)知識,幫助讀者對大數(shù)據(jù)有一個基本了解。如果對實踐有學習需要(可以留言),我再花時間整理大數(shù)據(jù)的實踐講解:Pyspark進行Titanic乘客生存預測。使用pyspark進行初步的大數(shù)據(jù)操作,數(shù)據(jù)選取Kaggle泰坦尼克號項目的數(shù)據(jù),通過Spark讀取數(shù)據(jù),并利用Spark中的ML工具對數(shù)據(jù)進行構(gòu)建模型。
-
SQL
+關(guān)注
關(guān)注
1文章
759瀏覽量
44069 -
volume
+關(guān)注
關(guān)注
0文章
5瀏覽量
7835 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8863瀏覽量
137292
發(fā)布評論請先 登錄
相關(guān)推薦
一文匯總大數(shù)據(jù)四大方面十五大關(guān)鍵技術(shù)
工業(yè)4.O的關(guān)鍵技術(shù)
智能穿戴產(chǎn)業(yè)的五大關(guān)鍵技術(shù)
無人駕駛汽車的關(guān)鍵技術(shù)是什么?
POE的關(guān)鍵技術(shù)有哪些?
明白VPP關(guān)鍵技術(shù)有哪些
視覺導航關(guān)鍵技術(shù)及應用
大數(shù)據(jù)時代,這十五大關(guān)鍵技術(shù)你竟不知道?
貴州省大數(shù)據(jù)領(lǐng)域技術(shù)榜單“大數(shù)據(jù)安全與隱私保護關(guān)鍵技術(shù)”項目啟動
水文大數(shù)據(jù)標準化方法和水文大數(shù)據(jù)共享平臺關(guān)鍵技術(shù)的設(shè)計和資料概述





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論