 ImageBind:跨模態之王,將6種模態全部綁定!
ImageBind:跨模態之王,將6種模態全部綁定!
Meta 新的開源模型 ImageBind 將多個數據流連接在一起,適用于文本、視頻和音頻等 6 種模態。
在人類的感官中,一張圖片可以將很多體驗融合到一起,比如一張海灘圖片可以讓我們想起海浪的聲音、沙子的質地、拂面而來的微風,甚至可以激發創作一首詩的靈感。圖像的這種「綁定」(binding)屬性通過與自身相關的任何感官體驗對齊,為學習視覺特征提供了大量監督來源。
理想情況下,對于單個聯合嵌入空間,視覺特征應該通過對齊所有感官來學習。然而這需要通過同一組圖像來獲取所有感官類型和組合的配對數據,顯然不可行。
最近,很多方法學習與文本、音頻等對齊的圖像特征。這些方法使用單對模態或者最多幾種視覺模態。最終嵌入僅限于用于訓練的模態對。因此,視頻 - 音頻嵌入無法直接用于圖像 - 文本任務,反之亦然。學習真正的聯合嵌入面臨的一個主要障礙是缺乏所有模態融合在一起的大量多模態數據。
今日,Meta AI 提出了 ImageBind,它通過利用多種類型的圖像配對數據來學習單個共享表示空間。該研究不需要所有模態相互同時出現的數據集,相反利用到了圖像的綁定屬性,只要將每個模態的嵌入與圖像嵌入對齊,就會實現所有模態的迅速對齊。Meta AI 還公布了相應代碼。

主頁:https://imagebind.metademolab.com/
論文地址:https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
GitHub 地址:https://github.com/facebookresearch/ImageBind
具體而言,ImageBind 利用網絡規模(圖像、文本)匹配數據,并將其與自然存在的配對數據(視頻、音頻、圖像、深度)相結合,以學習單個聯合嵌入空間。這樣做使得 ImageBind 隱式地將文本嵌入與其他模態(如音頻、深度等)對齊,從而在沒有顯式語義或文本配對的情況下,能在這些模態上實現零樣本識別功能。
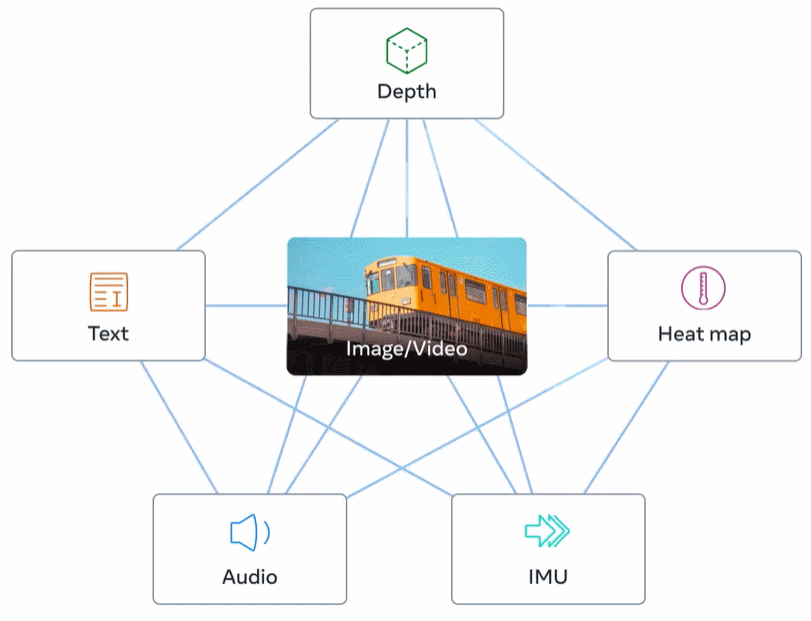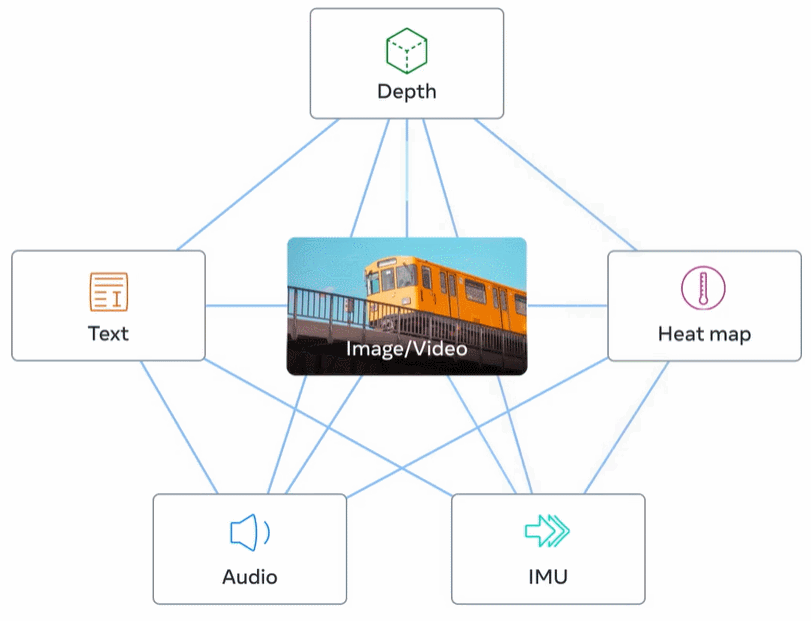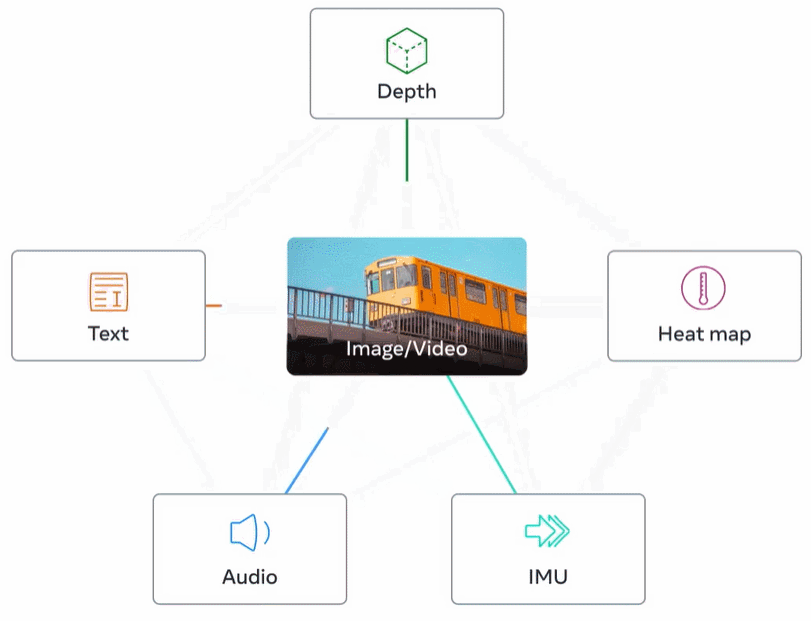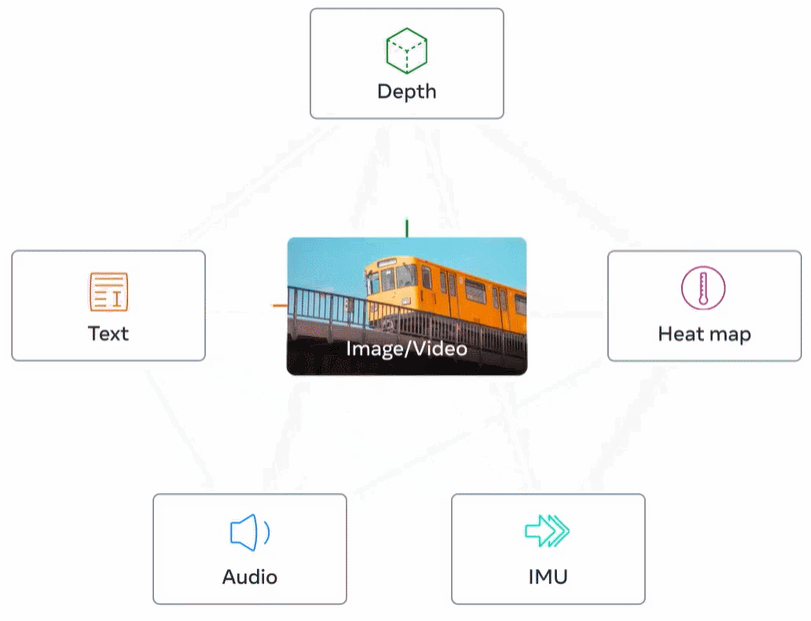
下圖 2 為 ImageBind 的整體概覽。

與此同時,研究者表示 ImageBind 可以使用大規模視覺語言模型(如 CLIP)進行初始化,從而利用這些模型的豐富圖像和文本表示。因此,ImageBind 只需要很少的訓練就可以應用于各種不同的模態和任務。
ImageBind 是 Meta 致力于創建多模態 AI 系統的一部分,從而實現從所有相關類型數據中學習。隨著模態數量的增加,ImageBind 為研究人員打開了嘗試開發全新整體性系統的閘門,例如結合 3D 和 IMU 傳感器來設計或體驗身臨其境的虛擬世界。此外它還可以提供一種探索記憶的豐富方式,即組合使用文本、視頻和圖像來搜索圖像、視頻、音頻文件或文本信息。
綁定內容和圖像,學習單個嵌入空間
人類有能力通過很少的樣本學習新概念,比如如閱讀對動物的描述之后,就可以在實際生活中認出它們;通過一張不熟悉的汽車模型照片,就可以預測其引擎可能發出的聲音。這在一定程度上是因為單張圖像可以將整體感官體驗「捆綁」在一起。然而在人工智能領域,雖然模態數量一直在增加,但多感官數據的缺乏會限制標準的需要配對數據的多模態學習。
理想情況下,一個有著不同種類數據的聯合嵌入空間能讓模型在學習視覺特征的同時學習其他的模態。此前,往往需要收集所有可能的配對數據組合,才能讓所有模態學習聯合嵌入空間。
ImageBind 規避了這個難題,它利用最近的大型視覺語言模型它將最近的大規模視覺語言模型的零樣本能力擴展到新的模態,它們與圖像的自然配對,如視頻 - 音頻和圖像 - 深度數據,來學習一個聯合嵌入空間。針對其他四種模式(音頻、深度、熱成像和 IMU 讀數),研究者使用自然配對的自監督數據。
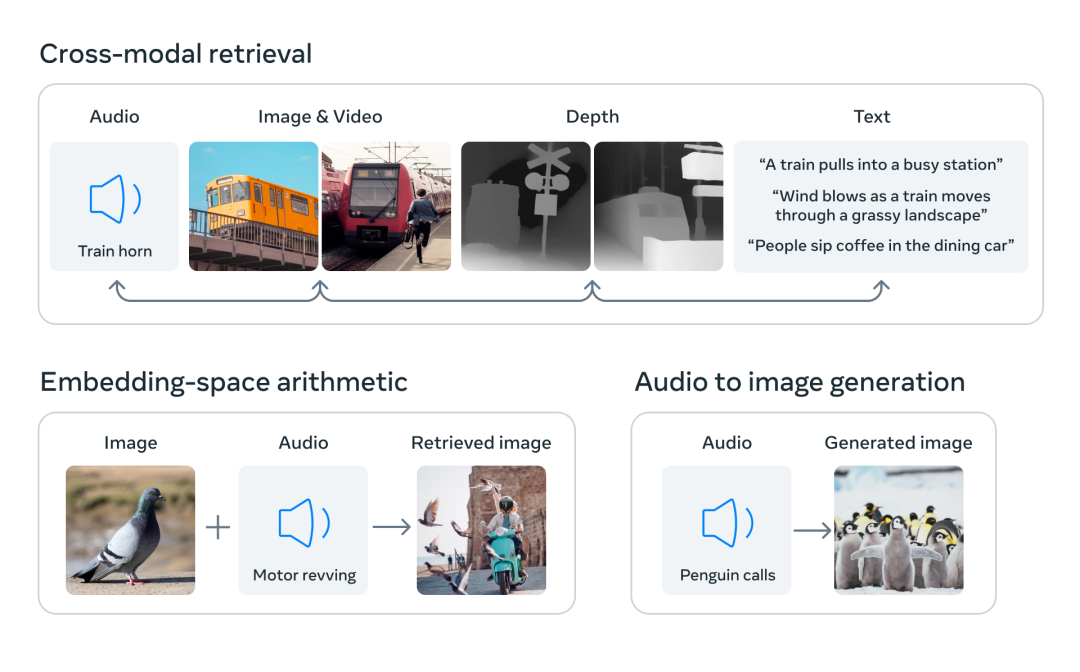
通過將六種模態的嵌入對齊到一個公共空間,ImageBind 可以跨模態檢索未同時觀察到的不同類型的內容,添加不同模態的嵌入以自然地對它們的語義進行組合,以及結合使用 Meta AI 的音頻嵌入與預訓練 DALLE-2 解碼器(設計用于與 CLIP 文本嵌入)來實現音頻到圖像生成。
互聯網上存在大量連同文本一起出現的圖像,因此訓練圖像 - 文本模型已經得到了廣泛的研究。ImageBind 利用了圖像能與各種模態相連接的綁定屬性,比如利用網絡數據將文本與圖像連接起來,或者利用在有 IMU 傳感器的可穿戴相機中捕捉到的視頻數據將運動與視頻連接起來。
從大規模網絡數據中學習到的視覺表征可以用作學習不同模態特征的目標。這使得 ImageBind 將圖像與同時出現的任何模態對齊,自然地使這些模態彼此對齊。熱圖和深度圖等與圖像具有強相關性的模態更容易對齊。音頻和 IMU(慣性測量單元)等非視覺的模態則具有較弱的相關性,比如嬰兒哭聲等特定聲音可以搭配各種視覺背景。
ImageBind 表明,圖像配對數據足以將這六種模態綁定在一起。該模型可以更全面地解釋內容,使不同的模態可以相互「對話」,并在沒有同時觀察它們的情況下找到它們之間的聯系。例如,ImageBind 可以在沒有一起觀察音頻和文本的情況下將二者聯系起來。這使得其他模型能夠「理解」新的模態,而不需要任何資源密集型的訓練。
ImageBind 強大的 scaling 表現使該模型能夠替代或增強許多人工智能模型,使它們能夠使用其他模態。例如雖然 Make-A-Scene 可以通過使用文本 prompt 生成圖像,但 ImageBind 可以將其升級為使用音頻生成圖像,如笑聲或雨聲。
ImageBind 的卓越性能
Meta 的分析表明,ImageBind 的 scaling 行為隨著圖像編碼器的強度而提高。換句話說,ImageBind 對齊模態的能力隨著視覺模型的能力和大小而提升。這表明,更大的視覺模型對非視覺任務有利,如音頻分類,而且訓練這種模型的好處超出了計算機視覺任務的范疇。
在實驗中,Meta 使用了 ImageBind 的音頻和深度編碼器,并將其與之前在 zero-shot 檢索以及音頻和深度分類任務中的工作進行了比較。
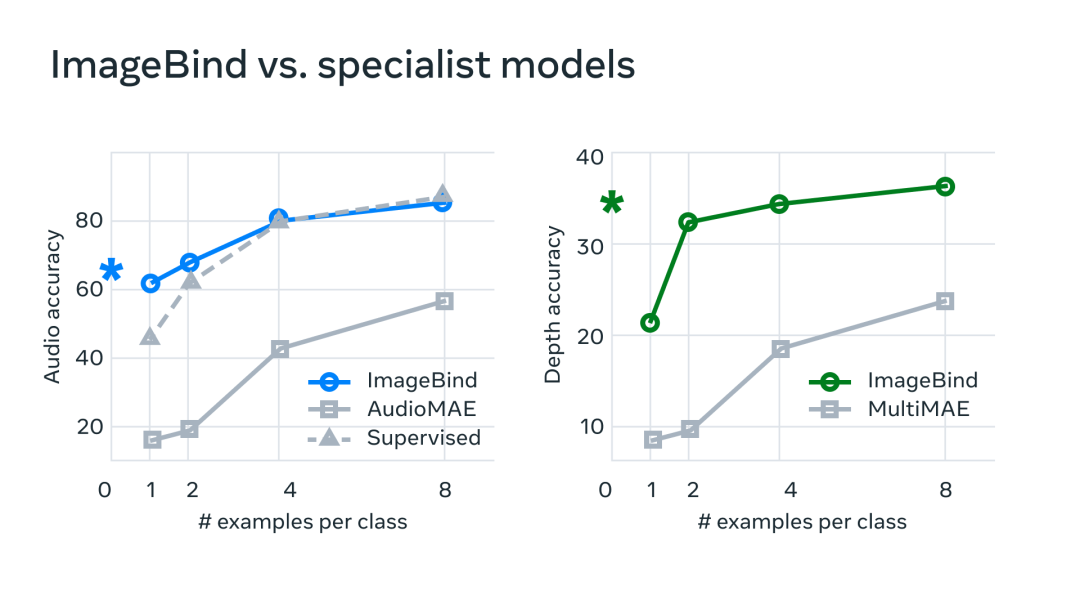
在基準測試上,mageBind 在音頻和深度方面優于專家模型。
Meta 發現 ImageBind 可以用于少樣本音頻和深度分類任務,并且優于之前定制的方法。例如,ImageBind 明顯優于 Meta 在 Audioset 上訓練的自監督 AudioMAE 模型,以及在音頻分類上微調的監督 AudioMAE 模型。
此外,ImageBind 還在跨模態的零樣本識別任務上取得了新的 SOTA 性能,甚至優于經過訓練以識別該模態概念的最新模型。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3596瀏覽量
134162 -
語言模型
+關注
關注
0文章
507瀏覽量
10245 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:爆火!ImageBind:跨模態之王,將6種模態全部綁定!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenHarmony實戰開發-如何實現模態轉場
模態窗口的設置問題
labview 模態分析
LMS Virtual Lab 流固模態分析
百度研制知識增強的跨模態深度問答技術等在內的的應用系統

基于語義耦合相關的判別式跨模態哈希特征表示學習算法

可提高跨模態行人重識別算法精度的特征學習框架
模態分析定義以及模態假設理論
大模型+多模態的3種實現方法

鴻蒙ArkTS聲明式開發:跨平臺支持列表【全屏模態轉場】模態轉場設置

鴻蒙ArkTS聲明式開發:跨平臺支持列表【半模態轉場】模態轉場設置






 工商網監
工商網監
評論