") 從Elasticsearch到Apache Doris,10倍性價比的新一代日志存儲分析平臺
從Elasticsearch到Apache Doris,10倍性價比的新一代日志存儲分析平臺
本文導(dǎo)讀
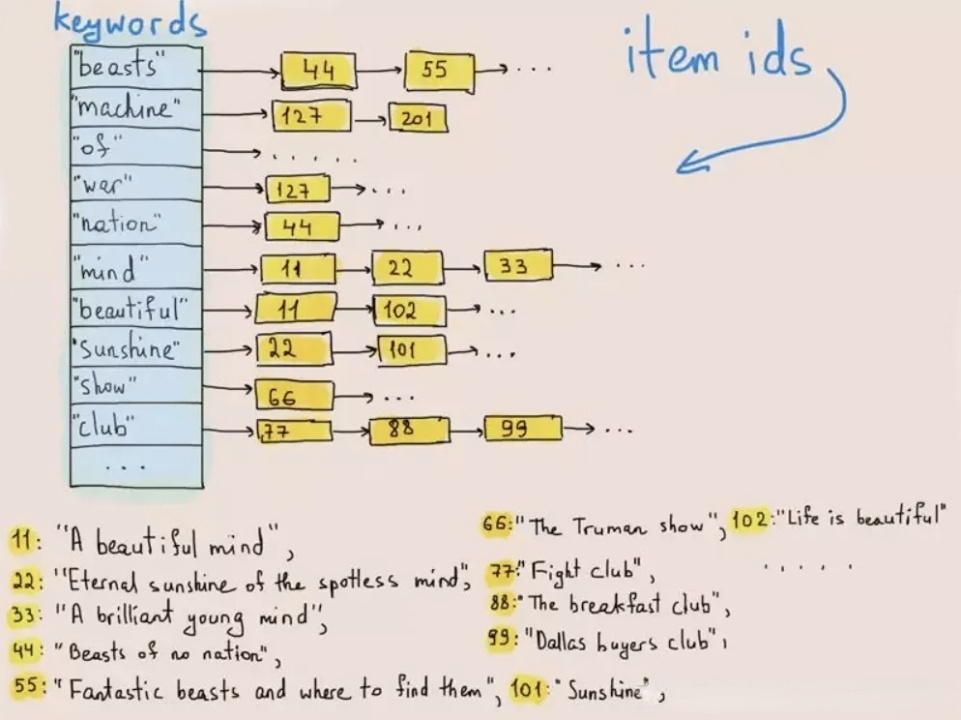
 ES 在日志場景的優(yōu)勢在于全文檢索能力,能快速從海量日志中檢索出匹配關(guān)鍵字的日志,其底層核心技術(shù)是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數(shù)據(jù)結(jié)構(gòu),最早應(yīng)用于信息檢索領(lǐng)域。如下圖所示,在數(shù)據(jù)寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構(gòu)建詞(Term) -> 行號列表(Posting List) 的映射關(guān)系,將映射關(guān)系按照詞進行排序存儲。當(dāng)需要查詢某個詞在哪些行出現(xiàn)的時候,先在 詞 -> 行號列表 的有序映射關(guān)系中查找詞對應(yīng)的行號列表,然后用行號列表中的行號去取出對應(yīng)行的內(nèi)容。這樣的查詢方式,可以避免遍歷對每一行數(shù)據(jù)進行掃描和匹配,只需要訪問包含查找詞的行,在海量數(shù)據(jù)下性能有數(shù)量級的提升。
ES 在日志場景的優(yōu)勢在于全文檢索能力,能快速從海量日志中檢索出匹配關(guān)鍵字的日志,其底層核心技術(shù)是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數(shù)據(jù)結(jié)構(gòu),最早應(yīng)用于信息檢索領(lǐng)域。如下圖所示,在數(shù)據(jù)寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構(gòu)建詞(Term) -> 行號列表(Posting List) 的映射關(guān)系,將映射關(guān)系按照詞進行排序存儲。當(dāng)需要查詢某個詞在哪些行出現(xiàn)的時候,先在 詞 -> 行號列表 的有序映射關(guān)系中查找詞對應(yīng)的行號列表,然后用行號列表中的行號去取出對應(yīng)行的內(nèi)容。這樣的查詢方式,可以避免遍歷對每一行數(shù)據(jù)進行掃描和匹配,只需要訪問包含查找詞的行,在海量數(shù)據(jù)下性能有數(shù)量級的提升。 業(yè)界各類系統(tǒng)為了支持全文檢索和任意列索引,往往有兩種實現(xiàn)方式:一是通過外接索引系統(tǒng)來實現(xiàn),原始數(shù)據(jù)存儲在原系統(tǒng)中、索引存儲在獨立的索引系統(tǒng)中,兩個系統(tǒng)通過數(shù)據(jù)的 ID 進行關(guān)聯(lián)。數(shù)據(jù)寫入時會同步寫入到原系統(tǒng)和索引系統(tǒng),索引系統(tǒng)構(gòu)建索引后不存儲完整數(shù)據(jù)只保留索引。查詢時先從索引系統(tǒng)查出滿足過濾條件的數(shù)據(jù) ID 集合,然后用 ID 集合去原系統(tǒng)查原始數(shù)據(jù)。這種架構(gòu)的優(yōu)勢是實現(xiàn)簡單,借力外部索引系統(tǒng),對原有系統(tǒng)改動小。但是問題也很明顯:
業(yè)界各類系統(tǒng)為了支持全文檢索和任意列索引,往往有兩種實現(xiàn)方式:一是通過外接索引系統(tǒng)來實現(xiàn),原始數(shù)據(jù)存儲在原系統(tǒng)中、索引存儲在獨立的索引系統(tǒng)中,兩個系統(tǒng)通過數(shù)據(jù)的 ID 進行關(guān)聯(lián)。數(shù)據(jù)寫入時會同步寫入到原系統(tǒng)和索引系統(tǒng),索引系統(tǒng)構(gòu)建索引后不存儲完整數(shù)據(jù)只保留索引。查詢時先從索引系統(tǒng)查出滿足過濾條件的數(shù)據(jù) ID 集合,然后用 ID 集合去原系統(tǒng)查原始數(shù)據(jù)。這種架構(gòu)的優(yōu)勢是實現(xiàn)簡單,借力外部索引系統(tǒng),對原有系統(tǒng)改動小。但是問題也很明顯: 高性能是 Apache Doris 倒排索引設(shè)計和實現(xiàn)的首要出發(fā)點,我們通過公開的測試數(shù)據(jù)集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:
高性能是 Apache Doris 倒排索引設(shè)計和實現(xiàn)的首要出發(fā)點,我們通過公開的測試數(shù)據(jù)集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:
日志數(shù)據(jù)的處理與分析是最典型的大數(shù)據(jù)分析場景之一,過去業(yè)內(nèi)以 Elasticsearch 和 Grafana Loki 為代表的兩類架構(gòu)難以同時兼顧高吞吐實時寫入、低成本海量存儲、實時文本檢索的需求。Apache Doris 借鑒了信息檢索的核心技術(shù),在存儲引擎上實現(xiàn)了面向 AP 場景優(yōu)化的高性能倒排索引,對于字符串類型的全文檢索和普通數(shù)值、日期等類型的等值、范圍檢索具有更高效的支持,相較于 Elasticsearch 實現(xiàn)性價比 10 余倍的提升,以此為日志存儲與分析場景提供了更優(yōu)的選擇。

日志數(shù)據(jù)在企業(yè)大數(shù)據(jù)中非常普遍,其體量往往在企業(yè)大數(shù)據(jù)體系中占據(jù)非常高的比重,包括服務(wù)器、數(shù)據(jù)庫、網(wǎng)絡(luò)設(shè)備、IoT 物聯(lián)網(wǎng)設(shè)備產(chǎn)生的系統(tǒng)運維日志,與此同時還包含了用戶行為埋點等業(yè)務(wù)日志。
日志數(shù)據(jù)對于保障系統(tǒng)穩(wěn)定運行和業(yè)務(wù)發(fā)展至關(guān)重要:基于日志的監(jiān)控告警可以發(fā)現(xiàn)系統(tǒng)運行風(fēng)險,及時預(yù)警;在故障排查過程中,實時日志檢索能幫助工程師快速定位到問題,盡快恢復(fù)服務(wù);日志報表能通過長歷史統(tǒng)計發(fā)現(xiàn)潛在趨勢。而用戶埋點日志數(shù)據(jù)則是用戶行為分析以及智能推薦業(yè)務(wù)所依賴的決策基礎(chǔ),有助于用戶需求洞察與體驗優(yōu)化以及后續(xù)的業(yè)務(wù)流程改進。由于其在業(yè)務(wù)中能發(fā)揮的重要意義,因此構(gòu)建統(tǒng)一的日志分析平臺,提供對日志數(shù)據(jù)的存儲、高效檢索以及快速分析能力,成為企業(yè)挖掘日志數(shù)據(jù)價值的關(guān)鍵一環(huán)。而日志數(shù)據(jù)和應(yīng)用場景往往呈現(xiàn)如下的特點:- 數(shù)據(jù)增長快:每一次用戶操作、系統(tǒng)事件都會觸發(fā)新的日志產(chǎn)生,很多企業(yè)每天新增日志達到幾十甚至幾百億條,對日志平臺的寫入吞吐要求很高;
- 數(shù)據(jù)總量大:由于自身業(yè)務(wù)和監(jiān)管等需要,日志數(shù)據(jù)經(jīng)常要存儲較長的周期,因此累積的數(shù)據(jù)量經(jīng)常達到幾百 TB 甚至 PB 級,而較老的歷史數(shù)據(jù)訪問頻率又比較低,面臨沉重的存儲成本壓力;
- 時效性要求高:在故障排查等場景需要能快速查詢到最新的日志,分鐘級的數(shù)據(jù)延遲往往無法滿足業(yè)務(wù)極高的時效性要求,因此需要實現(xiàn)日志數(shù)據(jù)的實時寫入與實時查詢。
- 高吞吐實時寫入:即需要保證日志流量的大規(guī)模寫入,又要支持低延遲可見;
- 低成本大規(guī)模存儲:系統(tǒng)自身可以存儲海量數(shù)據(jù),且通過數(shù)據(jù)壓縮、冷熱分離等多種機制降低存儲成本;
- 高性能交互式分析且支持文本檢索:日志檢索的隨機性很強、很難提前預(yù)測模式,因此要求支持靈活的文本檢索,通過實時交互式查詢滿足分析需求。

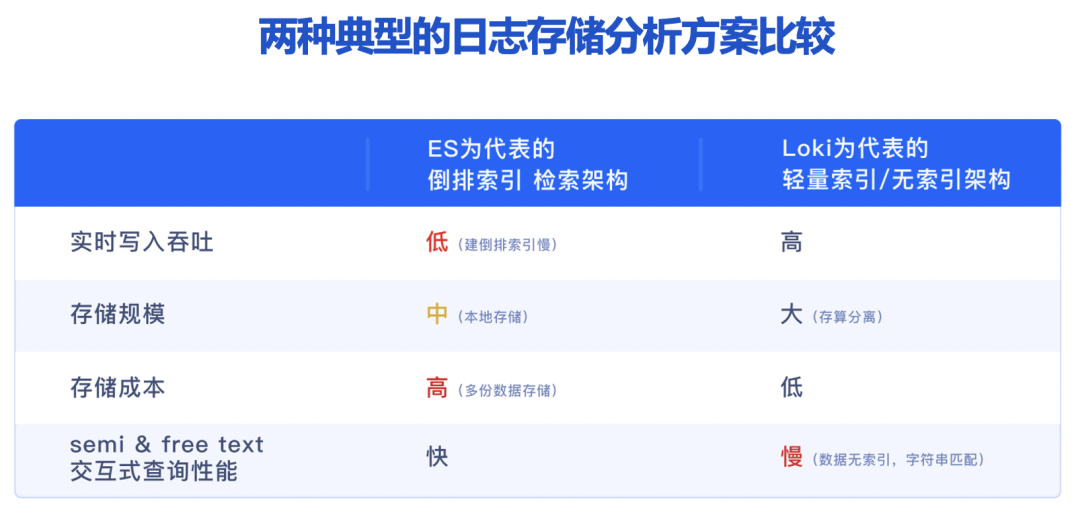
- 以 ES 為代表的倒排索引檢索架構(gòu),支持全文檢索、查詢性能好,因此在日志場景中被業(yè)內(nèi)大規(guī)模應(yīng)用,但其仍存在一些不足,包括實時寫入吞吐低、消耗大量資源構(gòu)建索引,且需要消耗巨大存儲成本;
- 以 Loki 為代表的輕量索引或無索引架構(gòu),實時寫入吞吐高、存儲成本較低,但是檢索性能慢、關(guān)鍵時候查詢響應(yīng)跟不上,性能成為制約業(yè)務(wù)分析的最大掣肘。
ES 在日志場景的優(yōu)勢在于全文檢索能力,能快速從海量日志中檢索出匹配關(guān)鍵字的日志,其底層核心技術(shù)是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數(shù)據(jù)結(jié)構(gòu),最早應(yīng)用于信息檢索領(lǐng)域。如下圖所示,在數(shù)據(jù)寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構(gòu)建詞(Term) -> 行號列表(Posting List) 的映射關(guān)系,將映射關(guān)系按照詞進行排序存儲。當(dāng)需要查詢某個詞在哪些行出現(xiàn)的時候,先在 詞 -> 行號列表 的有序映射關(guān)系中查找詞對應(yīng)的行號列表,然后用行號列表中的行號去取出對應(yīng)行的內(nèi)容。這樣的查詢方式,可以避免遍歷對每一行數(shù)據(jù)進行掃描和匹配,只需要訪問包含查找詞的行,在海量數(shù)據(jù)下性能有數(shù)量級的提升。

- ES 基于 Apache Lucene 構(gòu)建倒排索引,Apache Lucene 自 2000 年開源至今已有超過 20 年的歷史,設(shè)計之初主要面向信息檢索領(lǐng)域、功能豐富且復(fù)雜,而日志和大多數(shù) OLAP 場景只需要其核心功能,包括分詞、倒排表等,而相關(guān)度排序等并非強需求,因此存在進一步功能簡化和性能提升的空間;
- ES 和 Apache Lucene 均采用 Java 實現(xiàn),而 Apache Doris 存儲引擎和執(zhí)行引擎采用 C++ 開發(fā)并且實現(xiàn)了全面向量化,相對于 Java 實現(xiàn)具有更好的性能;
- 倒排索引并不能決定性能表現(xiàn)的全部,作為一個高性能、實時的 OLAP 數(shù)據(jù)庫,Apache Doris 的列式存儲引擎、MPP 分布式查詢框架、向量化執(zhí)行引擎以及智能 CBO 查詢優(yōu)化器,相較于 ES 更為高效。
業(yè)界各類系統(tǒng)為了支持全文檢索和任意列索引,往往有兩種實現(xiàn)方式:一是通過外接索引系統(tǒng)來實現(xiàn),原始數(shù)據(jù)存儲在原系統(tǒng)中、索引存儲在獨立的索引系統(tǒng)中,兩個系統(tǒng)通過數(shù)據(jù)的 ID 進行關(guān)聯(lián)。數(shù)據(jù)寫入時會同步寫入到原系統(tǒng)和索引系統(tǒng),索引系統(tǒng)構(gòu)建索引后不存儲完整數(shù)據(jù)只保留索引。查詢時先從索引系統(tǒng)查出滿足過濾條件的數(shù)據(jù) ID 集合,然后用 ID 集合去原系統(tǒng)查原始數(shù)據(jù)。這種架構(gòu)的優(yōu)勢是實現(xiàn)簡單,借力外部索引系統(tǒng),對原有系統(tǒng)改動小。但是問題也很明顯:- 數(shù)據(jù)寫入兩個系統(tǒng),異常有數(shù)據(jù)不一致的問題,也存在一定冗余存儲;
- 查詢需在兩個系統(tǒng)進行網(wǎng)絡(luò)交互有額外開銷,數(shù)據(jù)量大時用 ID 集合去原系統(tǒng)查性能比較低;
- 維護兩套系統(tǒng)的復(fù)雜度高,將系統(tǒng)的復(fù)雜性從開發(fā)測轉(zhuǎn)移到運維測;
數(shù)據(jù)庫內(nèi)置倒排索引
在選擇了在數(shù)據(jù)庫內(nèi)核中內(nèi)置倒排索引后,我們需要進一步對 Apache Doris 索引結(jié)構(gòu)進行分析,判斷能否通過在已有索引基礎(chǔ)上進行拓展來實現(xiàn)。Apache Doris 現(xiàn)有的索引存儲在 Segment 文件的 Index Region 中,按照適用場景可以分為跳數(shù)索引和點查索引兩類:1. 跳數(shù)索引:包括 ZoneMap 索引和 Bloom Filter 索引。
- ZoneMap 索引對每一個數(shù)據(jù)塊和文件保存 Min/Max/isnull 等匯總信息,可以用于等值、范圍查詢的粗粒度過濾,只能排除不滿足查詢條件的數(shù)據(jù)塊和文件,不能定位到行,也不支持文本分詞。
- BloomFilter 索引也是數(shù)據(jù)塊和文件級別的索引,通過 Bloom Filter 判斷某個值是否在數(shù)據(jù)塊和文件中,同樣不能定位到行、不支持文本分詞;
- ShortKey 在排序的基礎(chǔ)上,根據(jù)給定的前綴列實現(xiàn)快速查詢數(shù)據(jù)的索引方式,能夠?qū)η熬Y索引的列進行等值、范圍查詢,但不支持文本分詞,另外由于數(shù)據(jù)要按前綴索引排序、因此一個表只允許一組前綴索引。
- Bitmap 索引記錄數(shù)據(jù)值 -> 行號 Bitmap 的有序映射,是一種很基礎(chǔ)的倒排索引,但是索引結(jié)構(gòu)比較簡單、查詢效率不高、不支持文本分詞。
- 數(shù)據(jù)寫入和 Compaction 階段:在寫 Segment 文件的同時,同步寫入一個 Inverted Index 文件,文件路徑由 Segment ID + Index ID 決定。寫入 Segment 的 Row 和 Index 中的 Doc 一一對應(yīng),由于同步順序?qū)懭耄琒egment 中的 Rowid 和 Index 中的 Docid 完全對應(yīng)。
- 查詢階段:如果查詢 Where 條件中有建了倒排索引的列,會自動去 Index 文件中查詢,返回滿足條件的 Docid List,將 Docid List 一一對應(yīng)的轉(zhuǎn)成 Rowid Bitmap,然后走 Doris 通用的 Rowid 過濾機制只讀取滿足條件的行,達到查詢加速的效果。
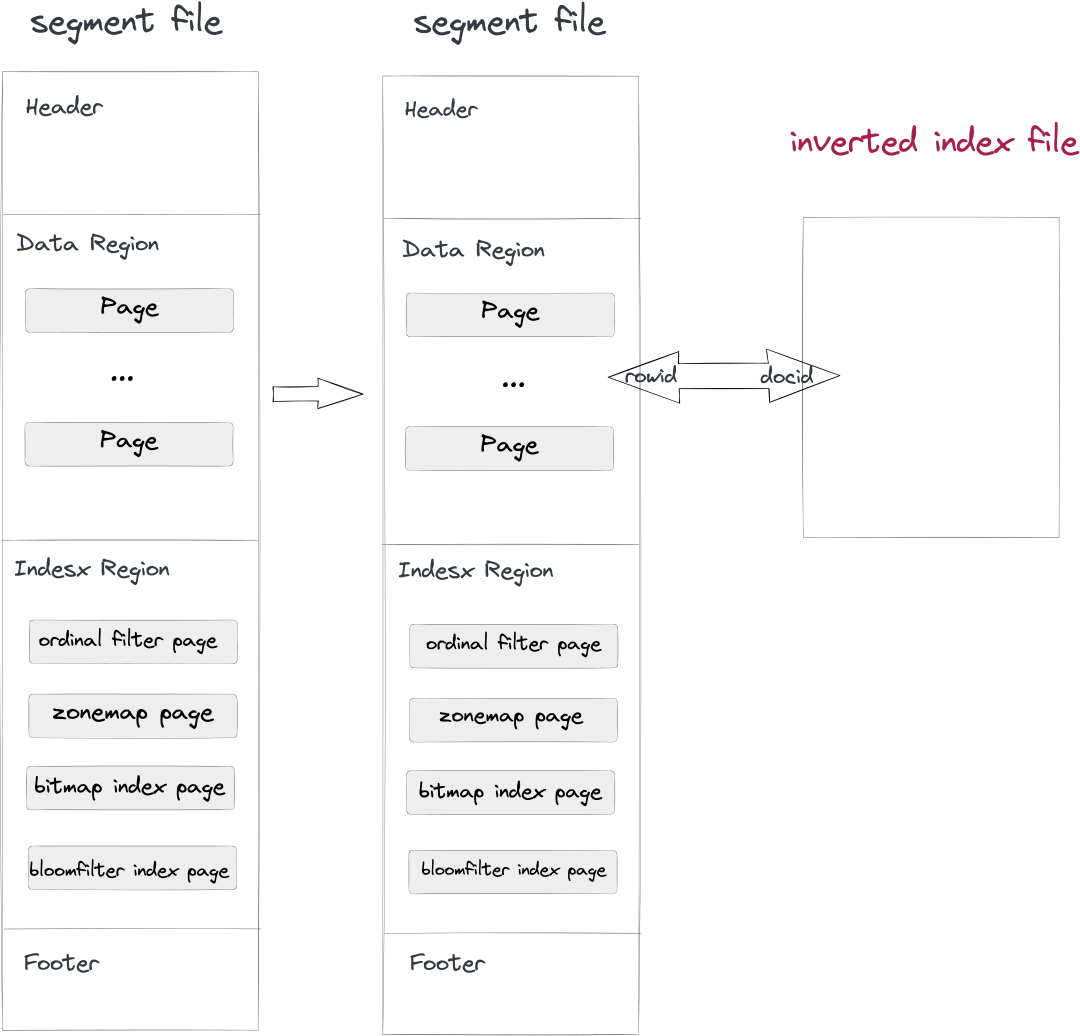
Doris倒排索引架構(gòu)圖
這個設(shè)計的好處是已有的數(shù)據(jù)文件無需修改,可以做到兼容升級,而且增減索引不影響數(shù)據(jù)文件和其他索引,用戶增建索引沒有負(fù)擔(dān)。
通用倒排索引優(yōu)化
C++和向量化實現(xiàn)Apache Doris 使用 CLucene(https://clucene.sourceforge.net/) 作為底層的倒排索引庫,CLucene 是一個用 C++ 實現(xiàn)的高性能、穩(wěn)定的 Lucene 倒排索引庫,它的功能比較完整,支持分詞和自定義分詞算法,支持全文檢索查詢和等值、范圍查詢。Apache Doris 的存儲模塊和 CLucene 都用 C++ 實現(xiàn),避免了Java Lucene 的 JVM GC 等開銷,同樣的計算 C++ 實現(xiàn)相對于 Java 性能優(yōu)勢明顯,而且更利于做向量化加速。Doris 倒排索引進行了向量化優(yōu)化,包括分詞、倒排表構(gòu)建、查詢等,性能得到進一步提升。整體來看 Doris 的倒排索引寫入速度可以超過單核 20MB/s,而 ES 的單核寫入速度不到 5MB/s,有 4 倍的性能優(yōu)勢。列式存儲和壓縮Lucene 本身是文檔存儲模型,主數(shù)據(jù)采用行存,而 Doris 中不同列的倒排索引是相互獨立的,因此倒排索引文件也采用列式存儲,有利于向量化構(gòu)建索引和提高壓縮率。采用壓縮比高且速度快的 ZSTD,通常可以達到 5 ~10倍的壓縮比,與常用的GZIP壓縮相比有50%以上的空間節(jié)省且速度更快。BKD 索引與數(shù)值、日期類型列優(yōu)化針對數(shù)值、日期類型的列,我們還實現(xiàn)了 BKD 索引,可以對范圍查詢提高性能,存儲空間也相對于轉(zhuǎn)成定長字符串更加高效,具有以下主要特性和優(yōu)勢:- 高效范圍查詢:BKD 索引采用多維數(shù)據(jù)結(jié)構(gòu),為范圍查詢帶來高效率。它能迅速定位數(shù)值或日期類型列中所需的數(shù)據(jù)范圍,降低查詢時間復(fù)雜度。
- 存儲空間優(yōu)化:與其他索引方法相比,BKD 索引在存儲空間使用上更高效。通過聚合并壓縮相鄰數(shù)據(jù)塊,減少索引所需存儲空間,降低存儲成本。
- 多維數(shù)據(jù)支持:BKD 索引具備良好擴展性,支持多維數(shù)據(jù)類型,如地理坐標(biāo)(GEO point)和范圍(Range),使其在處理復(fù)雜數(shù)據(jù)類型時具有高適應(yīng)性。
- 優(yōu)化低基數(shù)場景:針對數(shù)值分布集中、單個數(shù)值倒排列表較多的低基數(shù)場景,我們調(diào)整了針對性的壓縮算法,降低大量倒排表解壓縮和反序列化所帶來的CPU性能消耗。
- 預(yù)查詢技術(shù):針對查詢結(jié)果命中數(shù)較高的場景,我們采用預(yù)查詢技術(shù)進行命中數(shù)預(yù)估。若命中數(shù)顯著超過閾值,可跳過索引查詢,直接利用Doris在大數(shù)據(jù)量查詢下的技術(shù)優(yōu)勢進行數(shù)據(jù)過濾。
面向 OLAP 的倒排索引優(yōu)化
日志存儲和分析場景對檢索的需求很簡單,不需要特別復(fù)雜的功能(比如相關(guān)性排序),更需要降低存儲成本和快速按照條件查出數(shù)據(jù)。因此,在面對海量數(shù)據(jù)的寫入和查詢時,Apache Doris 還針對 OLAP 數(shù)據(jù)庫的特點優(yōu)化了倒排索引的結(jié)構(gòu),使其更加簡潔高效。例如:- 在寫入流程保證不會多個線程寫入一個索引,從而避免寫入時多線程鎖競爭的開銷;
- 在存儲結(jié)構(gòu)上去掉了不必要的正排、norm 等文件,減少寫入 IO 開銷和存儲空間占用;
- 查詢過程中簡化相關(guān)性打分和排序邏輯,降低不必要的開銷,提升查詢性能。
- 指定分區(qū)構(gòu)建倒排索引,比如新增一個索引的時候指定最近7天的日志構(gòu)建索引,歷史數(shù)據(jù)不建索引
- 指定分區(qū)刪除倒排索引,比如刪除超過1個月的日志的索引,釋放訪問頻度低的索引存儲空間
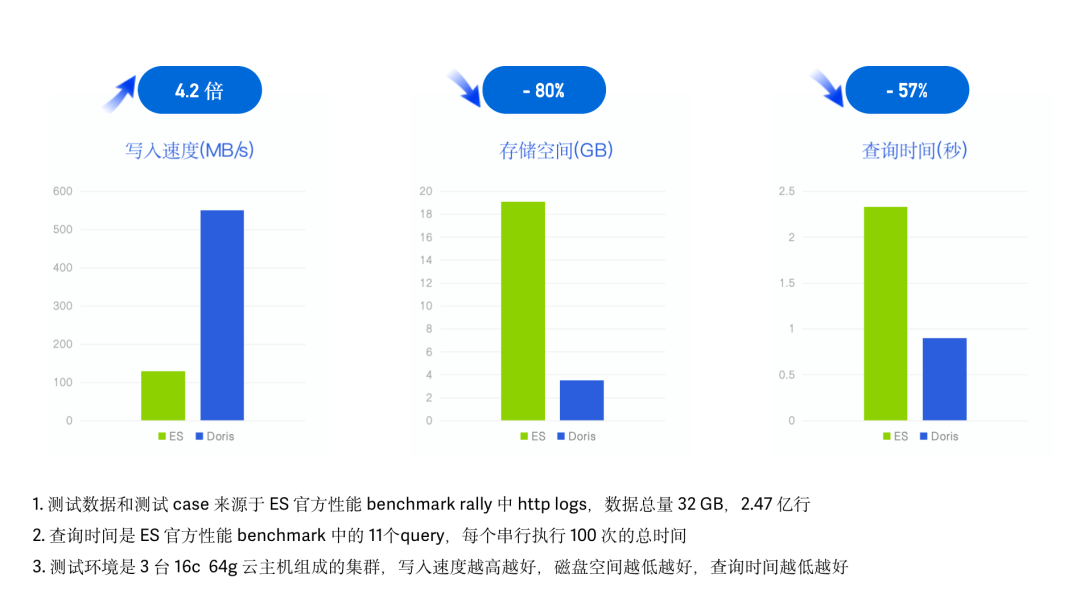
高性能是 Apache Doris 倒排索引設(shè)計和實現(xiàn)的首要出發(fā)點,我們通過公開的測試數(shù)據(jù)集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:vs Elasticsearch
我們采用了 ES 官方的性能測試 Benchmark esrally 并使用其中的 HTTP Logs 日志,在同樣的硬件資源、數(shù)據(jù)、測試Case 以及測試工具下,記錄并對比各自的數(shù)據(jù)寫入時間、吞吐以及查詢延遲。- 測試數(shù)據(jù):esrally HTTP Logs track 中自帶測試數(shù)據(jù)集,1998 年 World Cup HTTP Server Logs,未壓縮前 32G、共 2.47 億行、單行平均長度 134 字節(jié);
- 測試查詢:esrally HTTP Logs 測試關(guān)鍵詞檢索、范圍查詢、聚合、排序等 11 個 Query,所有查詢跑 100 次串行執(zhí)行;
- 測試環(huán)境:3 臺 16C 64G 云主機組成的集群。
vs Clickhouse
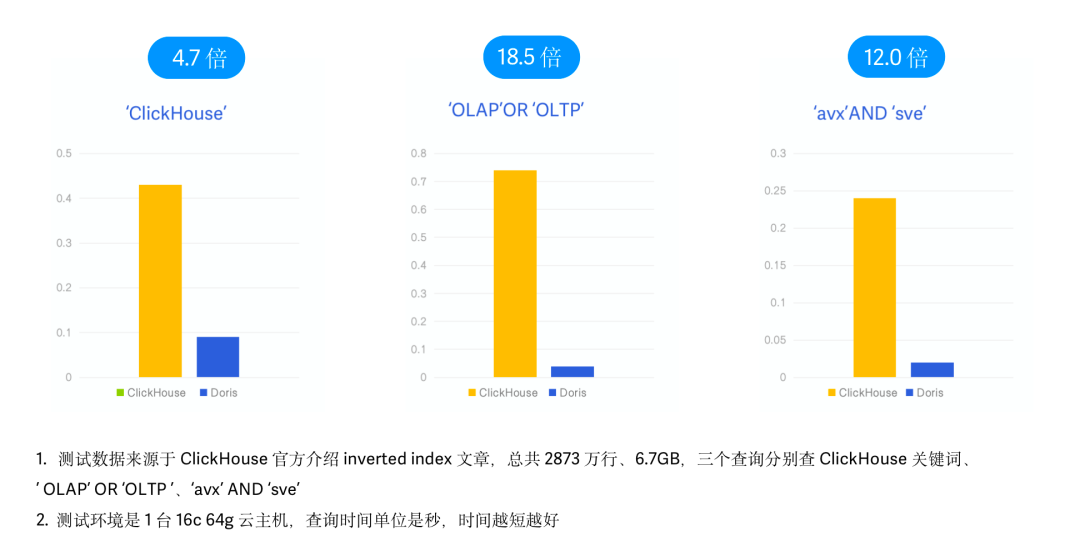
Clickhouse 近期的 v23.1 版本也引入了類似 Feature,將倒排索引作為實驗性功能發(fā)布,因此我們同樣進行了跟 Clickhouse 倒排索引的性能對比。在本次測試中,我們采用了 Clickhouse 官方 Inverted Index 介紹博客中使用的 Hacker News 樣例數(shù)據(jù)以及查詢 SQL ,同樣保持相同的物理資源、數(shù)據(jù)、測試 Case 以及測試工具。(參考文章:https://clickhouse.com/blog/clickhouse-search-with-inverted-indices)- 測試數(shù)據(jù):Hacker News 2873 萬條數(shù)據(jù),6.7G,Parquet 格式;
- 測試查詢:3 個查詢,分別查詢 'clickhouse'、'olap' OR 'oltp'、'avx' AND 'sve' 等關(guān)鍵字出現(xiàn)的次數(shù);
- 測試機器:1 臺 16C 64G 云主機

-
INDEX idx_comment (`comment`)指定對 comment 列建一個名為idx_comment的索引 -
USING INVERTED指定索引類型為倒排索引 -
PROPERTIES("parser" = "english")指定分詞類型為英文分詞
CREATETABLEhackernews_1m ( `id`BIGINT, `deleted`TINYINT, `type`String, `author`String, `timestamp`DateTimeV2, `comment`String, `dead`TINYINT, `parent`BIGINT, `poll`BIGINT, `children`Array<BIGINT>, `url`String, `score`INT, `title`String, `parts`Array<INT>, `descendants`INT, INDEXidx_comment(`comment`)USINGINVERTEDPROPERTIES("parser"="english")COMMENT'invertedindexforcomment' ) DUPLICATEKEY(`id`) DISTRIBUTEDBYHASH(`id`)BUCKETS10 PROPERTIES("replication_num"="1");注:對于已經(jīng)存在的表,也可以通過ADD INDEX idx_comment ON hackernews_1m(`comment`) USING INVERTED PROPERTIES("parser" = "english")來增加索引。值得一提的是,和 Doris 原先存儲在 Segment 數(shù)據(jù)文件中的智能索引和二級索引相比,增加倒排索引的過程只會讀 comment 列構(gòu)建新的倒排索引文件,不會讀寫原有的其他數(shù)據(jù),效率有明顯提升。2. 導(dǎo)入數(shù)據(jù)后查詢,使用
MATCH_ALL在comment這一列上匹配 OLAP 和 OLTP 兩個詞,和LIKE掃描硬匹配相比,查詢性能有十余倍的提升。(這僅是 100 萬條數(shù)據(jù)下的測試效果,而隨著數(shù)據(jù)量增大、性能提升越明顯)mysql>SELECTcount()FROMhackernews_1mWHEREcommentLIKE'%OLAP%'ANDcommentLIKE'%OLTP%'; +---------+ |count()| +---------+ |15| +---------+ 1rowinset(0.13sec) mysql>SELECTcount()FROMhackernews_1mWHEREcommentMATCH_ALL'OLAPOLTP'; +---------+ |count()| +---------+ |15| +---------+ 1rowinset(0.01sec)更多詳細(xì)功能介紹和測試步驟可以參考Apache Doris 倒排索引官方文檔:https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-index/

審核編輯 :李倩
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
日志
+關(guān)注
關(guān)注
0文章
138瀏覽量
10632 -
數(shù)據(jù)類型
+關(guān)注
關(guān)注
0文章
236瀏覽量
13609 -
數(shù)組
+關(guān)注
關(guān)注
1文章
416瀏覽量
25910
原文標(biāo)題:從 Elasticsearch 到 Apache Doris,10 倍性價比的新一代日志存儲分析平臺|新版本揭秘
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
存儲芯片大反彈,三星一季度利潤暴漲近10倍
了過去的頹勢,結(jié)束了從2022年第三季度以來開始的下滑趨勢。 ? 另一方面,受益于智能手機及人工智能的發(fā)展,導(dǎo)致數(shù)據(jù)中心服務(wù)器需求大增,包括商用存儲的緊缺,都讓三星業(yè)績得以大幅增長。 ? ? 三星Q1 利潤暴增近
日志篇:模組日志總體介紹
?今天我們學(xué)習(xí)合宙模組日志總體介紹,以下進入正文。 一、本文討論的邊界 本文是對合宙 4G 模組, 以及 4G+GNSS 模組的日志功能的總體介紹。通過日志,可以對研發(fā)過程中,以及模組

啟明信息完成國產(chǎn)化Doris數(shù)據(jù)庫升級替代任務(wù)
近日,隨著集團公司監(jiān)控平臺(Elasticsearch集群)的下線,標(biāo)志著啟明信息正式完成國產(chǎn)化Doris數(shù)據(jù)庫升級替代任務(wù)。該項目既標(biāo)志著啟明信息信創(chuàng)升級替代邁入新臺階,同時也標(biāo)志著在Dor
用OPA695做了10倍放大,從1Mhz到100Mhz放大倍數(shù)一直在縮小,還失真,為什么?
我用OPA695做了10倍放大 但是從1Mhz到100Mhz放大倍數(shù)一直在縮小,而且還失真,OPA694壓擺率4500應(yīng)該不會失真啊!PC
發(fā)表于 08-27 06:31
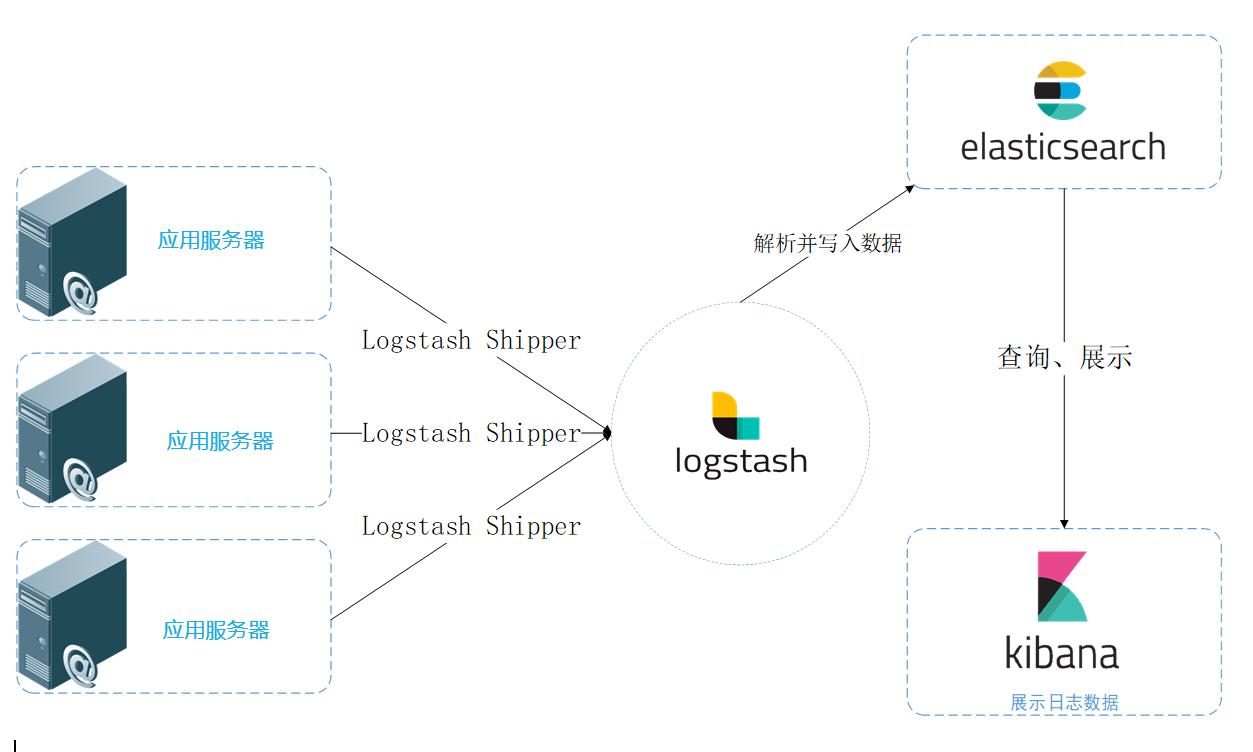
統(tǒng)一日志數(shù)據(jù)流圖
統(tǒng)一日志數(shù)據(jù)流圖 日志系統(tǒng)數(shù)據(jù)流圖 系統(tǒng)進行日志收集的過程可以分為三個環(huán)節(jié): (1)日志收集和導(dǎo)入ElasticSearch (2)
th4521在0輸入時,251倍放大倍數(shù),25℃到130℃時輸出從10mv到0.35v是什么原因引起的?
th4521在0輸入時,251倍放大倍數(shù),25℃到130℃時輸出從10mv到0.35v,是什么原因引起的,怎么解決?
發(fā)表于 08-14 06:49
鐵威馬教程 如何收集NAS的日志
一:使用Putty等工具登錄NAS命令行終端。 步驟二:修改日志存儲的位置 2.1.執(zhí)行以下命令: ? 代碼:

浪潮信息推出基于新一代分布式存儲平臺AS13000G7的AIGC存儲解決方案
6月28日,浪潮信息“元腦中國行”全國巡展杭州站順利舉行。會上,浪潮信息重磅推出基于新一代分布式存儲平臺AS13000G7的AIGC存儲解決方案。通過加持EPAI/AIStation的

ABB推出新一代機器人控制平臺OmniCore
ABB近日發(fā)布了其新一代機器人控制平臺——OmniCore,標(biāo)志著機器人技術(shù)的一大飛躍。這款全新的控制平臺相較于ABB之前的IRC5控制器,實現(xiàn)了顯著的性能提升。

Rokid正式發(fā)布新一代AR Lite空間計算套裝
Rokid正式發(fā)布新一代AR Lite空間計算套裝,包括Rokid Max2眼鏡和搭載驍龍平臺的Rokid Station2主機。
銀河麒麟與英特爾攜手引領(lǐng)新一代私有云平臺
近日,銀河麒麟云底座操作系統(tǒng)V10與第五代英特爾?至強?可擴展處理器達成強大的技術(shù)融合。這一合作不僅為數(shù)據(jù)中心用戶提供了構(gòu)建新一代私有云平臺
單片機斷電記憶日志 多串口助手波形圖像彩色日志 Stm32嵌入式FLASH保存日志管理工具
特點如下:
使用空格分隔各個日志元素,不能調(diào)換元素的順序。
最少包含日志等級(LL)和文字信息(LT)。
日志緩沖(LB)表示為LL+LT4+文字,其中LT4表示4位數(shù)值從000
發(fā)表于 01-19 11:28
Apache Doris聚合函數(shù)源碼解析
筆者最近由于工作需要開始調(diào)研 Apache Doris,通過閱讀聚合函數(shù)代碼切入 Apache Doris 內(nèi)核,同時也秉承著開源的精神,開發(fā)了 array_agg 函數(shù)并貢獻給社區(qū)。
什么是Apache日志?Apache日志分析工具介紹
Apache Web 服務(wù)器在企業(yè)中廣泛用于托管其網(wǎng)站和 Web 應(yīng)用程序,Apache 服務(wù)器生成的原始日志提供有關(guān) Apache 服務(wù)器托管的網(wǎng)站如何處理用戶請求以及訪問您的網(wǎng)站時





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論