 LlamaIndex:面向QA系統的全新文檔摘要索引
LlamaIndex:面向QA系統的全新文檔摘要索引
在這篇博文中,我們介紹了一種全新的 LlamaIndex 數據結構:文檔摘要索引。我們描述了與傳統語義搜索相比,它如何幫助提供更好的檢索性能,并通過一個示例進行了介紹。
1背景
大型語言模型 (LLM) 的核心場景之一是對用戶自己的數據進行問答。為此,我們將 LLM 與“檢索”模型配對,該模型可以對知識語料庫執行信息檢索,并使用 LLM 對檢索到的文本執行響應合成。這個整體框架稱為檢索增強生成。
今天大多數構建 LLM 支持的 QA 系統的用戶傾向于執行以下某種形式的操作:
- 獲取源文檔,將每個文檔拆分為文本塊
- 將文本塊存儲在向量數據庫中
- 在查詢期間,通過嵌入相似性和/或關鍵字過濾器來檢索文本塊。
- 執行響應并匯總答案
由于各種原因,這種方法提供了有限的檢索性能。
2
現有方法的局限性
使用文本塊進行嵌入檢索有一些限制。
- 文本塊缺乏全局上下文。通常,問題需要的上下文超出了特定塊中索引的內容。
- 仔細調整 top-k / 相似度分數閾值。假設值太小,你會錯過上下文。假設值值太大,并且成本/延遲可能會隨著更多不相關的上下文而增加,噪音增加。
- 嵌入并不總是為問題選擇最相關的上下文。嵌入本質上是在文本和上下文之間分別確定的。
添加關鍵字過濾器是增強檢索結果的一種方法。但這也帶來了一系列挑戰。我們需要手動或通過 NLP 關鍵字提取/主題標記模型為每個文檔充分確定合適的關鍵字。此外,我們還需要從查詢中充分推斷出正確的關鍵字。
3
文檔摘要索引
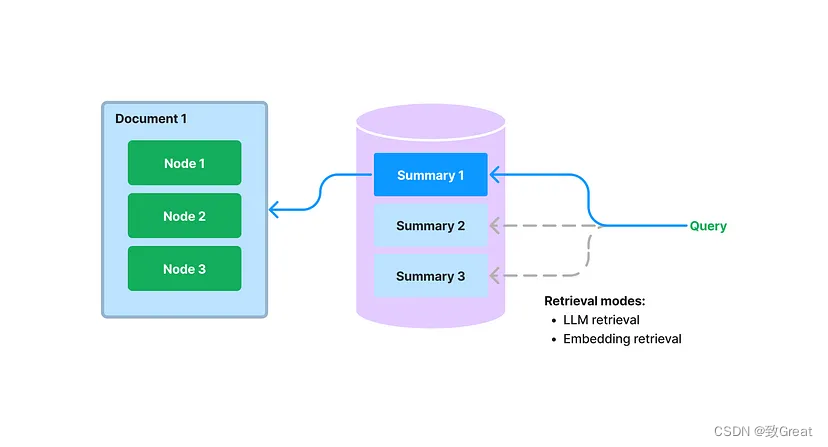
在LlamaIndex中提出了一個新索引,它將為每個文檔提取/索引非結構化文本摘要。該索引可以幫助提高檢索性能,超越現有的檢索方法。它有助于索引比單個文本塊更多的信息,并且比關鍵字標簽具有更多的語義。它還允許更靈活的檢索形式:我們可以同時進行 LLM 檢索和基于嵌入的檢索。
4
怎么運行的
在構建期間,我們提取每個文檔,并使用 LLM 從每個文檔中提取摘要。我們還將文檔拆分為文本塊(節點)。摘要和節點都存儲在我們的文檔存儲抽象中。我們維護從摘要到源文檔/節點的映射。
在查詢期間,我們使用以下方法根據摘要檢索相關文檔以進行查詢:
- 基于 LLM 的檢索:我們向 LLM 提供文檔摘要集,并要求 LLM 確定哪些文檔是相關的+它們的相關性分數。
- 基于嵌入的檢索:我們根據摘要嵌入相似性(使用 top-k 截止值)檢索相關文檔。
請注意,這種檢索文檔摘要的方法(即使使用基于嵌入的方法)不同于基于嵌入的文本塊檢索。文檔摘要索引的檢索類檢索任何選定文檔的所有節點,而不是返回節點級別的相關塊。
存儲文檔的摘要還可以實現基于 LLM 的檢索。我們可以先讓 LLM 檢查簡明的文檔摘要,看看它是否與查詢相關,而不是一開始就將整個文檔提供給 LLM。這利用了 LLM 的推理能力,它比基于嵌入的查找更先進,但避免了將整個文檔提供給 LLM 的成本/延遲
5
想法
帶有摘要的文檔檢索可以被認為是語義搜索和所有文檔的強力摘要之間的“中間地帶”。我們根據與給定查詢的摘要相關性查找文檔,然后返回與檢索到的文檔對應的所有節點。
我們為什么要這樣做?通過在文檔級別檢索上下文,這種檢索方法為用戶提供了比文本塊上的 top-k 更多的上下文。但是,它也是一種比主題建模更靈活/自動化的方法;不再擔心自己的文本是否有正確的關鍵字標簽!
6
例子
讓我們來看一個展示文檔摘要索引的示例,其中包含關于不同城市的維基百科文章。
本指南的其余部分展示了相關的代碼片段。您可以在此處找到完整的演練(這是筆記本鏈接)。
我們可以構建GPTDocumentSummaryIndex一組文檔,并傳入一個ResponseSynthesizer對象來合成文檔的摘要。
from llama_index import(
SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
ResponseSynthesizer
)
from llama_index.indices.document_summary import GPTDocumentSummaryIndex
from langchain.chat_models import ChatOpenAI
#load docs,define service context
...
#build the index
response_synthesizer=ResponseSynthesizer.from_args(response_mode="tree_summarize",use_async=True)
doc_summary_index=GPTDocumentSummaryIndex.from_documents(
city_docs,
service_context=service_context,
response_synthesizer=response_synthesizer
)
建立索引后,我們可以獲得任何給定文檔的摘要:
summary=doc_summary_index.get_document_summary("Boston")
接下來,我們來看一個基于 LLM 的索引檢索示例。
from llama_index.indices.document_summary import DocumentSummaryIndexRetriever
retriever=DocumentSummaryIndexRetriever(
doc_summary_index,
#choice_select_prompt=choice_select_prompt,
#choice_batch_size=choice_batch_size,
#format_node_batch_fn=format_node_batch_fn,
#parse_choice_select_answer_fn=parse_choice_select_answer_fn,
#service_context=service_context
)
retrieved_nodes=retriever.retrieve("What are the sports teams in Toronto?")
print(retrieved_nodes[0].score)
print(retrieved_nodes[0].node.get_text())The retriever will retrieve asetof relevant nodesfora given index.`
請注意,除了文檔文本之外,LLM 還返回相關性分數:
8.0
Toronto((listen)t?-RON-toh;locally[t???????]or[?t?????])is the capital city of the Canadian province of Ontario.With a recorded population of 2,794,356in2021,it is the most populous cityinCanada...
高級api
query_engine=doc_summary_index.as_query_engine(
response_mode="tree_summarize",use_async=True
)
response=query_engine.query("What are the sports teams in Toronto?")
print(response)
底層api
#use retriever as part of a query engine
from llama_index.query_engine import RetrieverQueryEngine
#configure response synthesizer
response_synthesizer=ResponseSynthesizer.from_args()
#assemble query engine
query_engine=RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
#query
response=query_engine.query("What are the sports teams in Toronto?")
print(response)
審核編輯 :李倩
-
代碼
+關注
關注
30文章
4753瀏覽量
68368 -
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
nlp
+關注
關注
1文章
487瀏覽量
22015
原文標題:LlamaIndex :面向QA 系統的全新文檔摘要索引
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
最新文檔控件軟件!
請問能提供下K210 datasheet與standloneSDK最新文檔嗎?
基于詞頻統計的多文檔自動摘要生成方案
電位器整定的定時器專用電路QA640896/QA640892
基于知識圖譜的QA系統研究

基于HBase行鍵面向海量交通數據的HBase時空索引

基于網頁排名算法面向論文索引排名的啟發式方法
基于布谷鳥搜索算法與多目標函數的多文檔摘要方法

VectorCAST/QA如何在LiteOS-A內核上實現系統白盒測試
面向關系數據庫的智能索引調優方法

摘要模型理解或捕獲輸入文本的要點
什么是LlamaIndex?LlamaIndex數據框架的特點和功能





 工商網監
工商網監
評論