 華為諾亞提出新型Prompting (PHP),GPT-4拿下最難數學推理數據集新SOTA
華為諾亞提出新型Prompting (PHP),GPT-4拿下最難數學推理數據集新SOTA
模擬人類推理過程,華為諾亞提出 Progressive-Hint Prompting (PHP) 引導大模型漸近正確答案。
近期,華為聯和港中文發表論文《Progressive-Hint Prompting Improves Reasoning in Large Language Models》,提出Progressive-Hint Prompting(PHP),用來模擬人類做題過程。在 PHP 框架下,Large Language Model (LLM) 能夠利用前幾次生成的推理答案作為之后推理的提示,逐步靠近最終的正確答案。要使用 PHP,只需要滿足兩個要求:
問題能夠和推理答案進行合并,形成新的問題;
模型可以處理這個新的問題,給出新的推理答案。
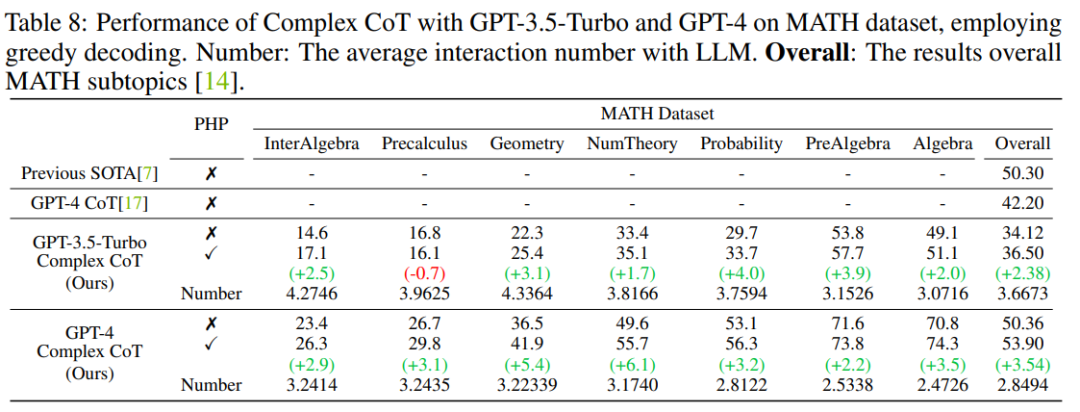
結果表明,GP-T-4+PHP 在多個數據集上取得了SOTA結果,包括 SVAMP (91.9%), AQuA (79.9%), GSM8K (95.5%) 以及 MATH (53.9%)。該方法大幅超過 GPT-4+CoT。比如,在現在最難的數學推理數據集 MATH 上,GPT-4+CoT 只有 42.5%,而 GPT-4+PHP 在 MATH 數據集的 Nember Theory (數論) 子集提升 6.1%, 將 MATH 整體提升到 53.9%,達到 SOTA。

論文鏈接:https://arxiv.org/abs/2304.09797
代碼鏈接:https://github.com/chuanyang-Zheng/Progressive-Hint
介紹
隨著 LLM 的發展,涌現了關于 prompting 的一些工作,其中有兩個主流方向:
一個以 Chain-Of-Thought( CoT,思維鏈) 為代表,通過清楚得寫下推理過程,激發模型的推理能力;
另一個以 Self-Consistency (SC) 為代表,通過采樣多個答案,然后進行投票得到最終答案。
顯然,現存的兩種方法,沒有對問題進行任何的修改,相當于做了一遍題目之后就結束了,而沒有反過來帶著答案進行再次檢查。PHP 嘗試模擬更加類人推理過程:對上次的推理過程進行處理,然后合并到初始的問題當中,詢問 LLM 進行再次推理。當最近兩次推理答案一致時,得到的答案是準確的,將返回最終答案。具體的流程圖如下所示:

在第一次與 LLM 交互的時候,應當使用 Base Prompting (基礎提示), 其中的 prompt(提示)可以是 Standard prompt,CoT prompt 或者其改進版本。通過 Base Prompting,可以進行第一次交互,然后得到初步的答案。在隨后的交互中,應當使用 PHP,直至最新的兩個答案一致。
PHP prompt 基于 Base Prompt 進行修改。給定一個 Base Prompt,可以通過制定的 PHP prompt design principles 來得到對應的 PHP prompt。具體如下圖所示:

作者希望PHP prompt能夠讓大模型學習到兩種映射模式:
1)如果給的 Hint 是正確答案,那么返回的答案依然要是正確答案 (具體如上圖所示的「Hint is the correct answer」);
2)如果給的 Hint 是錯誤答案,那么 LLM 要通過推理,跳出錯誤答案的 Hint,返回正確答案(具體如上圖所示的「Hint is the incorrect answer」)。
按照這種 PHP prompt 的設計規則,給定任意現存的 Base Prompt,作者都可以設定出對應的 PHP Prompt。
實驗
作者使用七個數據集,包括 AddSub、MultiArith、SingleEQ、SVAMP、GSM8K、 AQuA 和 MATH。同時,作者一共使用了四個模型來驗證作者的想法,包括 text-davinci-002、text-davinci-003、GPT-3.5-Turbo 和 GPT-4。
主要結果
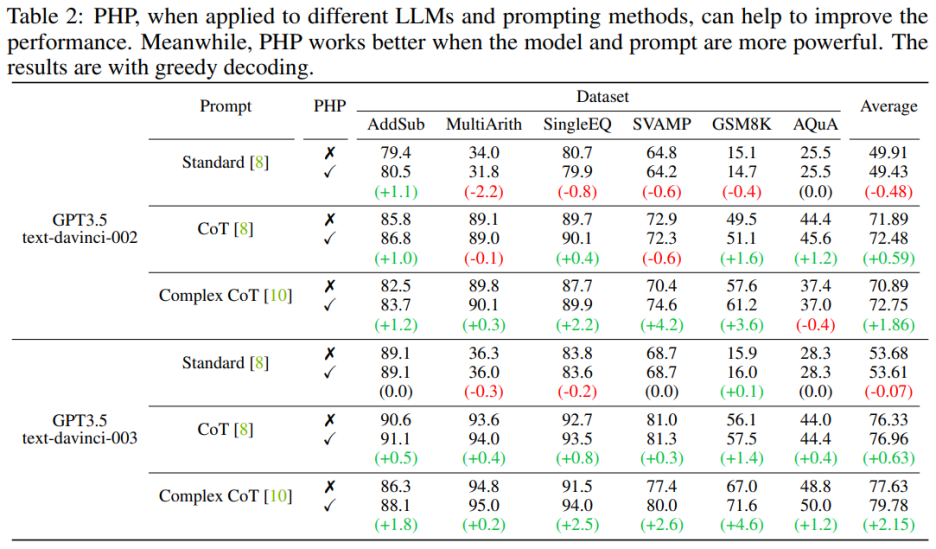
當語言模型更強大、提示更有效時,PHP 的效果更好。相比于 Standard Prompt 和 CoT Prompt,Complex CoT prompt 表現出了顯著的性能提升。分析還顯示,使用強化學習進行微調的 text-davinci-003 語言模型比使用監督指令微調的 text-davinci-002 模型表現更好,能夠提升文檔效果。text-davinci-003 的性能提高歸因于其增強的能力,使其更好地理解和應用給定的提示。同時,如果只是使用 Standard prompt,那么 PHP 所帶來的提升并不明顯。如果需要讓 PHP 起到效果,至少需要 CoT 來激發模型的推理能力。
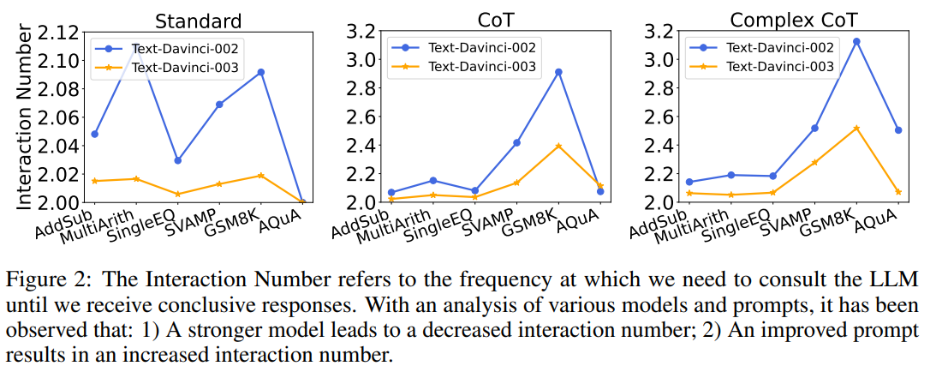
同時,作者也探究了交互次數與模型、prompt 之間的關系。當語言模型更強大,提示更弱時,交互次數會減少。交互次數指代智能體與 LLMs 互動的次數。當收到第一個答案時,交互次數為 1;收到第二個答案時,交互次數增加到 2。在圖 2 中,作者展示了各種模型和提示的交互次數。作者的研究結果表明:
1)在給定相同提示的情況下,text-davinci-003 的交互次數通常低于 text-davinci-002。這主要是由于 text-davinci-003 的準確性更高,導致基礎答案和后續答案的正確率更高,因此需要更少的交互才能得到最終的正確答案;
2)當使用相同的模型時,隨著提示變得更強大,交互次數通常會增加。這是因為當提示變得更有效時,LLMs 的推理能力會得到更好的發揮,從而使它們能夠利用提示跳出錯誤答案,最終導致需要更高的交互次數才能達到最終答案,這使得交互次數增加。
Hint 質量的影響
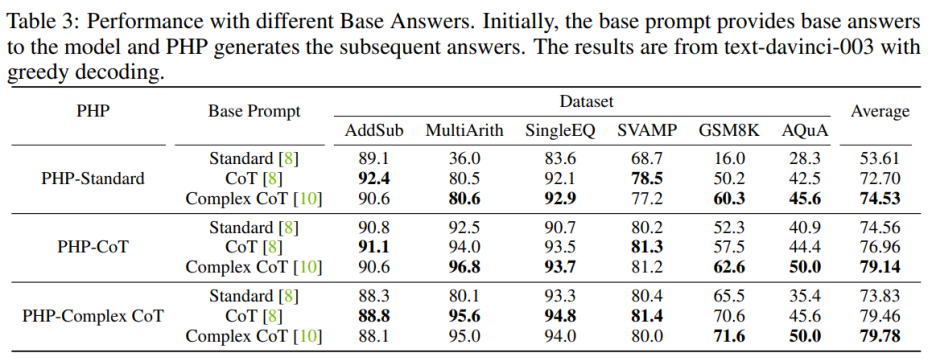
為了增強 PHP-Standard 的性能,將 Base Prompt Standard 替換為 Complex CoT 或 CoT 可以顯著提高最終性能。對 PHP-Standard 而言,作者觀察到在 Base Prompt Standard 下,GSM8K 的性能從 16.0% 提高到了在基礎提示 CoT 下的 50.2%,再提高到在基礎提示 Complex CoT 下的 60.3%。相反,如果將 Base Prompt Complex CoT 替換為 Standard,則最終性能會降低。例如,在將基礎提示 Complex CoT 替換為 Standard 后,PHP-Complex CoT 在 GSM8K 數據集上的性能從 71.6% 下降到了 65.5%。
如果 PHP 不是基于相應的 Base Prompt 進行設計,那么效果可能進一步提高。使用 Base Prompt Complex CoT 的 PHP-CoT 在六個數據集中的四個數據集表現優于使用 CoT 的 PHP-CoT。同樣地,使用基礎提示 CoT 的 PHP-Complex CoT 在六個數據集中的四個數據集表現優于使用 Base Prompt Complex CoT 的 PHP-Complex CoT。作者推推測這是因為兩方面的原因:1)在所有六個數據集上,CoT 和 Complex CoT 的性能相似;2)由于 Base Answer 是由 CoT(或 Complex CoT)提供的,而后續答案是基于 PHP-Complex CoT(或 PHP-CoT),這就相當于有兩個人合作解決問題。因此,在這種情況下,系統的性能可能進一步提高。
消融實驗
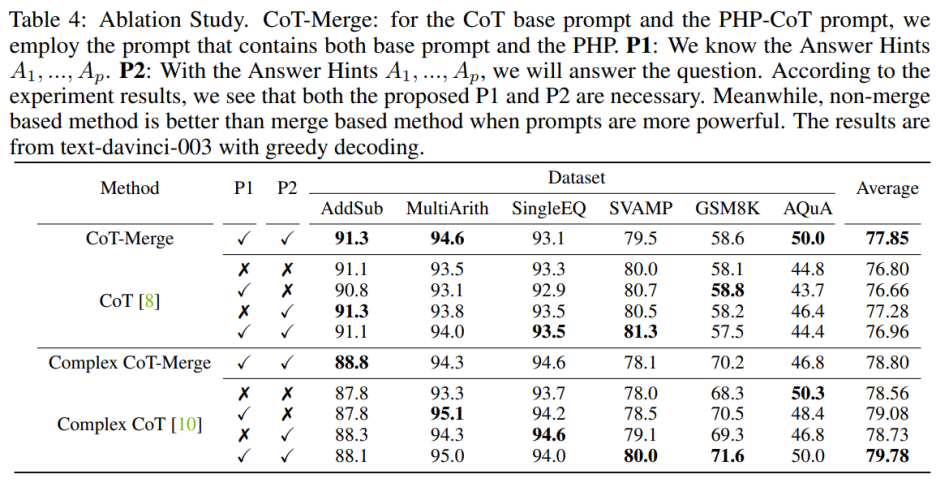
將句子 P1 和 P2 納入模型可以提高 CoT 在三個數據集上的表現,但當使用 Complex CoT 方法時,這兩個句子的重要性尤為明顯。在加入 P1 和 P2 后,該方法在六個數據集中有五個數據集的表現得到了提升。例如,在 SVAMP 數據集上,Complex CoT 的表現從 78.0% 提高到了 80.0%,在 GSM8K 數據集上從 68.3% 提高到了 71.6%。這表明,尤其是在模型的邏輯能力更強時,句子 P1 和 P2 的效果更為顯著。
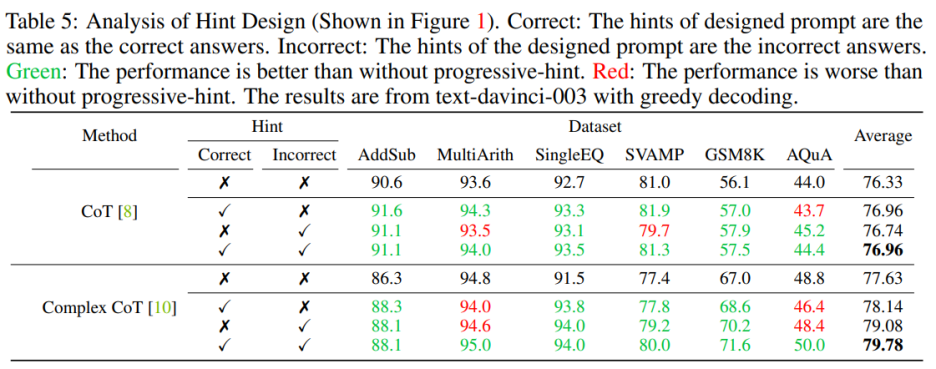
在設計提示時需要同時包含正確和錯誤的提示。當設計的提示同時包含正確和錯誤的提示時,使用 PHP 的效果優于不使用 PHP。具體來說,提示中提供正確的提示會促進生成與給定提示相符的答案。相反,提示中提供錯誤的提示則會通過給定的提示鼓勵生成其他答案
PHP+Self-Consistency
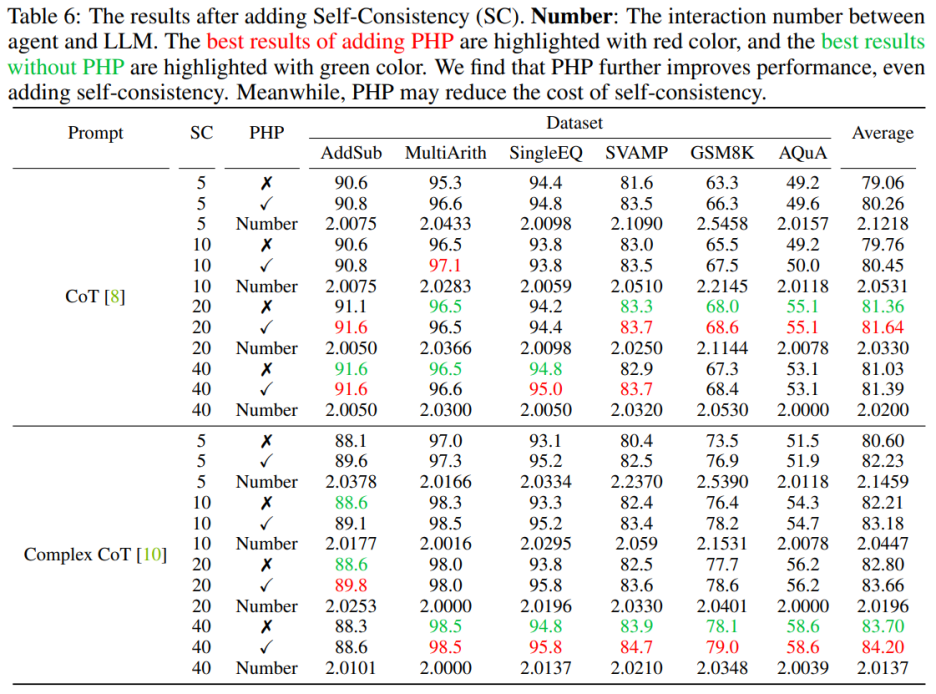
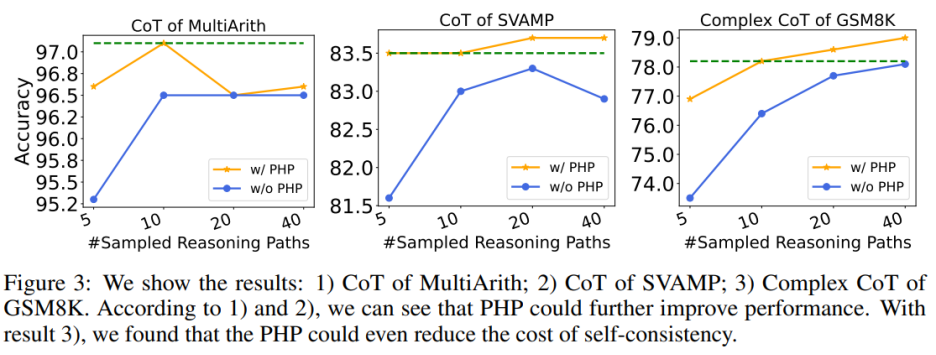
使用 PHP 可以進一步提高性能。通過使用類似的提示和樣本路徑數量,作者發現在表 6 和圖 3 中,作者提出的 PHP-CoT 和 PHP-Complex CoT 總是比 CoT 和 Complex CoT 表現更好。例如,CoT+SC 的樣本路徑為 10、20 和 40 時,能夠在 MultiArith 數據集上達到 96.5% 的準確率。因此,可以得出結論,CoT+SC 的最佳性能為 96.5%,使用 text-davinci-003。然而,在實施 PHP 之后,性能升至 97.1%。同樣,作者還觀察到在 SVAMP 數據集上,CoT+SC 的最佳準確率為 83.3%,在實施 PHP 后進一步提高到 83.7%。這表明,PHP 可以打破性能瓶頸并進一步提高性能。
使用 PHP 可以降低 SC 的成本,眾所周知,SC 涉及更多的推理路徑,導致成本更高。表 6 說明,PHP 可以是降低成本的有效方法,同時仍保持性能增益。如圖 3 所示,使用 SC+Complex CoT,可以使用 40 個樣本路徑達到 78.1% 的準確率,而加入 PHP 將所需平均推理路徑降低到 10×2.1531=21.531 條路徑,并且結果更好,準確率達到了 78.2%。
GPT-3.5-Turbo 和 GPT-4
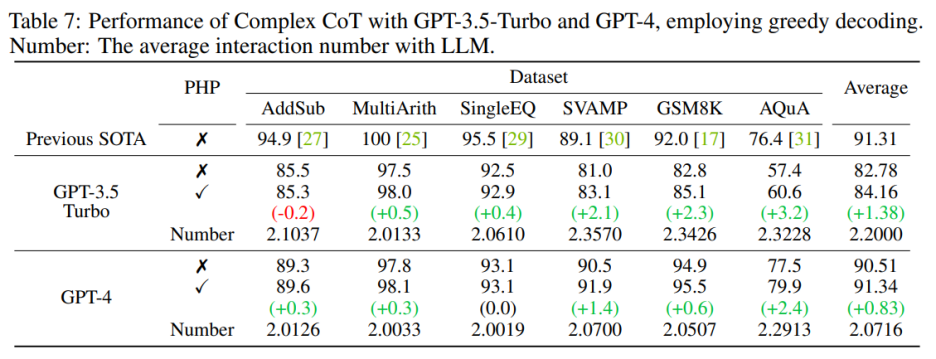
作者按照以前的工作設置,使用文本生成模型進行實驗。隨著 GPT-3.5-Turbo 和 GPT-4 的 API 發布,作者在相同的六個數據集上驗證了具有 PHP 的 Complex CoT 的性能。作者對這兩個模型都使用貪心解碼(即溫度 = 0)和 Complex CoT 作為提示。
如表 7 所示,提出的 PHP 增強了性能,在 GSM8K 上提高了 2.3%,在 AQuA 上提高了 3.2%。然而,與 text-davinci-003 相比,GPT-3.5-Turbo 表現出對提示的依附能力降低。作者提供了兩個例子來說明這一點:
a)在提示缺失的情況下,GPT-3.5-Turbo 無法回答問題,并回復類似于 “由于答案提示缺失,我無法回答此問題。請提供答案提示以繼續” 的聲明。相比之下,text-davinci-003 在回答問題之前會自主生成并填充缺失的答案提示;
b)當提供超過十個提示時,GPT-3.5-Turbo 可能會回復 “由于給出了多個答案提示,我無法確定正確的答案。請為問題提供一個答案提示。”
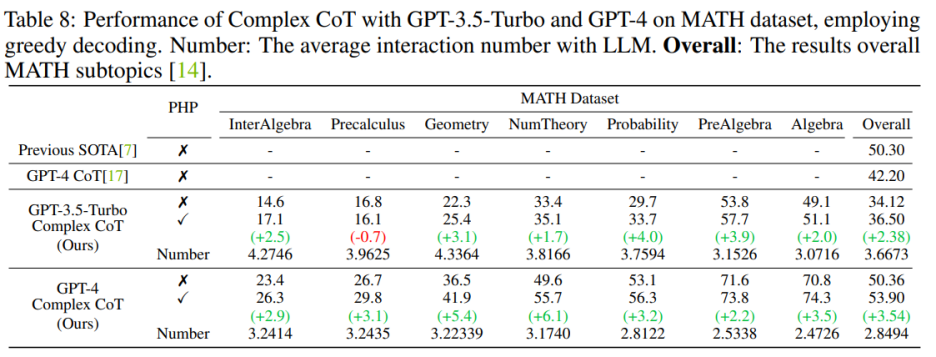
在部署 GPT-4 模型后,作者能夠在 SVAMP、GSM8K、AQuA 和 MATH 基準測試上實現新的 SOTA 性能。作者提出的 PHP 方法不斷改善了 GPT-4 的性能。此外,與 GPT-3.5-Turbo 模型相比,作者觀察到 GPT-4 所需的交互次數減少了,這與 “當模型更加強大時,交互次數會減少” 的發現相一致。
總結
本文介紹了 PHP 與 LLMs 交互的新方法,具有多個優點:
1)PHP 在數學推理任務上實現了顯著的性能提升,在多個推理基準測試上領先于最先進的結果;
2)使用更強大的模型和提示,PHP 可以更好地使 LLMs 受益;
3)PHP 可以與 CoT 和 SC 輕松結合,進一步提高性能。
為了更好地增強 PHP 方法,未來的研究可以集中在改進問題階段的手工提示和答案部分的提示句子的設計上。此外,除了將答案當作 hint,還可以確定和提取有助于 LLMs 重新考慮問題的新 hint。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3174瀏覽量
48720 -
PHP
+關注
關注
0文章
452瀏覽量
26650 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:華為諾亞提出新型Prompting (PHP),GPT-4拿下最難數學推理數據集新SOTA
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Llama 3 與 GPT-4 比較
科大訊飛發布訊飛星火4.0 Turbo:七大能力超GPT-4 Turbo
OpenAI推出新模型CriticGPT,用GPT-4自我糾錯
OpenAI API Key獲取:開發人員申請GPT-4 API Key教程
開發者如何調用OpenAI的GPT-4o API以及價格詳情指南
GPT-4人工智能模型預測公司未來盈利勝過人類分析師
OpenAI全新GPT-4o能力炸場!速度快/成本低,能讀懂人類情緒
阿里云發布通義千問2.5大模型,多項能力超越GPT-4
微軟Copilot全面更新為OpenAI的GPT-4 Turbo模型
新火種AI|秒殺GPT-4,狙殺GPT-5,橫空出世的Claude 3振奮人心!

全球最強大模型易主,GPT-4被超越
ChatGPT plus有什么功能?OpenAI 發布 GPT-4 Turbo 目前我們所知道的功能

AI觀察 | 今年最火的GPT-4,正在締造科幻版妙手仁心!


OpenAI發布的GPT-4 Turbo版本ChatGPT plus有什么功能?





 工商網監
工商網監
評論