 深度學習基礎知識(4)
深度學習基礎知識(4)
神經網絡的學習:從訓練數據中自動獲取最優權重的過程,是使損失函數的值最小的權重參數。
機器學習做手寫數據識別:從圖像中提取特征量,再用機器學習技術學習這些特征量的模式。 圖像的特征量通常表示為向量的形式,機器視覺領域常用的特征量包括SIFT、SURF和HOG等。 對轉換后的向量使用機器學習中的SVM、KNN等分類器進行學習。
深度學習直接學習圖像本身,特征量也是由機器來學習的。 它的優點是對所有問題都可以用同樣的流程來解決。
1、訓練數據和測試數據
機器學習中,一般將數據分為訓練數據和測試數據。 首先使用訓練數據進行學習,尋找最優的參數,然后使用測試數據評價模型。 為了正確評價模型的泛化能力,必須劃分訓練數據和測試數據。 泛化能力是指處理未被觀察過的數據的能力。 獲得泛化能力是機器學習的最終目標。 僅僅使用一個數據集去學習和評價參數,是無法正確評價的。 可能順利處理某個數據集,但無法處理其他數據集的情況。 只對某個數據集過度擬合的狀態稱為過擬合,避免過擬合也是機器學習的一個重要課題。
2、損失函數
神經網絡通過損失函數尋找最優權重參數。 損失函數是表示神經網絡性能的惡劣程度的指標。
1)均方誤差
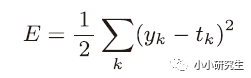
表示輸出與訓練數據的不匹配程度,希望得到最小的均方誤差。
2)交叉熵誤差

實際上只計算對應正確解標簽的輸出的自然對數。 交叉熵誤差的值是由正確解標簽所對應的輸出結果決定的。 根據自然對數的圖像,正確解標簽對應的輸出越大,交叉熵誤差越接近0,當輸出為1時,交叉熵誤差為0。 使用代碼實現時為了避免負無窮大需要添加一個微小值。
以上都是針對單個數據的損失函數,如果要求所有訓練數據的損失函數的總和,需要寫成下式

MNIST數據集的訓練數據有60000個,如果求全部數據的損失函數和不太現實。 因此,需要從全部數據中選出一部分,神經網絡的學習也是從訓練數據中選出一部分(mini-batch)然后對每批數據進行學習。
從訓練數據中隨機抽取10筆數據的代碼:
train_size=x_train.shape[0]
batch_size=10
batch_mask=np.random.choice(train_size,batch_size)
x_batch=x_train[batch_mask]
t_batch=t_train[batch_mask]
x_train形狀為60000*784,所以train_size=60000。 使用np.random.choice()可以從指定的數字中隨機選擇想要的數字,在60000個數據中隨機取10個數字。 后續只需要使用這個mini_batch計算損失函數。
3、mini_batch交叉熵誤差的實現
def cross_entropy_error(y,t):
if y.dim==1:
t=t.reshape(1,t.size)
y=y.reshape(1,y.size)
batch_size=y.shape[0]
return -np.sum(t*np.log(y+1e-7))/batch_size
當y的維度為1,即求單個數據的交叉熵誤差時,需要改變數據的形狀變為1*60000,當輸入為mini-batch時,需要用batch的個數進行歸一化,計算單個數據的平均交叉熵誤差。
return -np.sum(np.log(y[np.arange(batch_size),t]+1e-7))/batch_size
如果訓練數據是標簽形式,改為上述代碼。 np.arange(batch_size)會生成一個0到batch_size-1的數組,因為t中的標簽是以0-9數字的方式進行存儲的,所以y[np.arange(batch_size),t]生成了一個二維數組。
4、為什么要設定損失函數
在神經網絡的學習中,尋找最優權重和偏置時,要尋找使損失函數的值盡可能小的參數,需要計算梯度并更新參數。 如果用識別精度作為指標,絕大多數地方的導數都會變為0導致參數無法更新。 因為識別精度的概念是在訓練數據中正確識別的數量,稍微改變權重的值識別精度可能無法變化,即使變化也是離散的值。 階躍函數不能作為激活函數的原因也是這樣,對微小變化不敏感,且變化是不連續的。
-
神經網絡
+關注
關注
42文章
4717瀏覽量
99983 -
函數
+關注
關注
3文章
4234瀏覽量
61961 -
SVM
+關注
關注
0文章
154瀏覽量
32337 -
機器學習
+關注
關注
66文章
8306瀏覽量
131834 -
深度學習
+關注
關注
73文章
5422瀏覽量
120583
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論