") CPU的硬件運行效率
CPU的硬件運行效率
提到CPU性能,大部分同學(xué)想到的都是CPU利用率,這個指標(biāo)確實應(yīng)該首先被關(guān)注。但是除了利用率之外,還有很容易被人忽視的指標(biāo),就是指令的運行效率。如果運行效率不高,那CPU利用率再忙也都是瞎忙,產(chǎn)出并不高。
這就好比人,每天都是很忙,但其實每天的效率并不一樣。有的時候一天干了很多事情,但有的時候只是瞎忙了一天,回頭一看,啥也沒干!
一、CPU 硬件運行效率
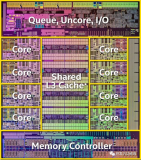
那啥是CPU的運行效率呢?介紹這個之前我們得先來簡單回顧下CPU的構(gòu)成和工作原理。CPU在生產(chǎn)過程結(jié)束后,在硬件上就被***刻成了各種各樣的模塊。
在上面的物理結(jié)構(gòu)圖中,可以看到每個物理核和L3 Cache的分布情況。另外就是在每個物理核中,還包括了更多組件。每個核都會集成自己獨占使用的寄存器和緩存,其中緩存包括L1 data、L1 code 和L2。
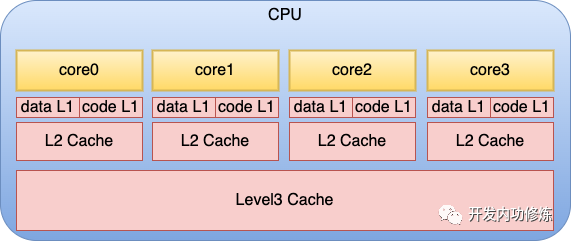
服務(wù)程序在運行的過程中,就是CPU核不斷地從存儲中獲取要執(zhí)行的指令,以及需要運算的數(shù)據(jù)。這里所謂的存儲包括寄存器、L1 data緩存、L1 code緩存、L2 緩存、L3緩存,以及內(nèi)存。 當(dāng)一個服務(wù)程序被啟動的時候,它會通過缺頁中斷的方式被加載到內(nèi)存中。當(dāng) CPU 運行服務(wù)時,它不斷從內(nèi)存讀取指令和數(shù)據(jù),進(jìn)行計算處理,然后將結(jié)果再寫回內(nèi)存。
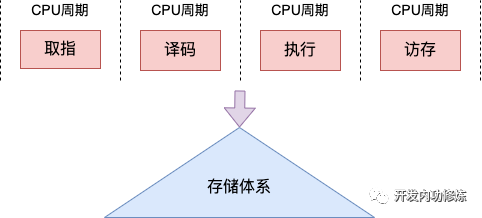
不同的 CPU 流水線不同。在經(jīng)典的 CPU 的流水線中,每個指令周期通常包括取指、譯碼、執(zhí)行和訪存幾個階段。
在取指階段,CPU 從內(nèi)存中取出指令,將其加載到指令寄存器中。
在譯碼階段,CPU 解碼指令,確定要執(zhí)行的操作類型,并將操作數(shù)加載到寄存器中。
在執(zhí)行階段,CPU 執(zhí)行指令,并將結(jié)果存儲在寄存器中。
在訪存階段,CPU 根據(jù)需要將數(shù)據(jù)從內(nèi)存寫入寄存器中,或?qū)⒓拇嫫髦械臄?shù)據(jù)寫回內(nèi)存。
但,內(nèi)存的訪問速度是非常慢的。CPU一個指令周期一般只是零點幾個納秒,但是對于內(nèi)存來說,即使是最快的順序 IO,那也得 10 納秒左右,如果碰上隨機IO,那就是 30-40 納秒左右的開銷。
所以CPU為了加速運算,自建了臨時數(shù)據(jù)存儲倉庫。就是我們上面提到的各種緩存,包括每個核都有的寄存器、L1 data、L1 code 和L2緩存,也包括整個CPU共享的L3,還包括專門用于虛擬內(nèi)存到物理內(nèi)存地址轉(zhuǎn)換的TLB緩存。
拿最快的寄存器來說,耗時大約是零點幾納秒,和CPU就工作在一個節(jié)奏下了。再往下的L1大約延遲在 2 ns 左右,L2大約 4 ns 左右,依次上漲。
但速度比較慢的存儲也有個好處,離CPU核更遠(yuǎn),可以把容量做到更大。所以CPU訪問的存儲在邏輯上是一個金字塔的結(jié)構(gòu)。越靠近金字塔尖的存儲,其訪問速度越快,但容量比較小。越往下雖然速度略慢,但是存儲體積更大。
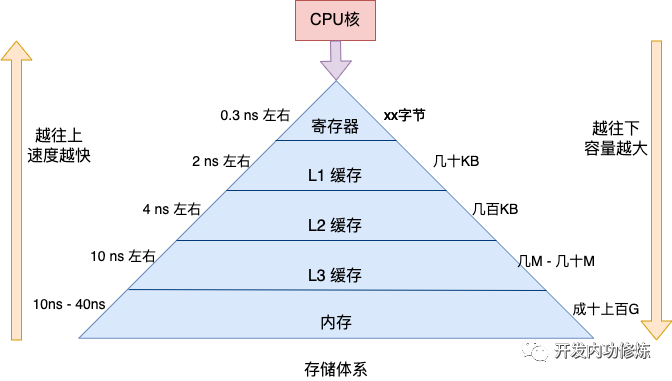
基本原理就介紹這么多。現(xiàn)在我們開始思考指令運行效率。根據(jù)上述金字塔圖我們可以很清楚地看到,如果服務(wù)程序運行時所需要的指令存儲都位于金字塔上方的話,那服務(wù)運行的效率就高。如果程序?qū)懙牟缓茫蛘邇?nèi)核頻繁地把進(jìn)程在不同的物理核之間遷移(不同核的L1和L2等緩存不是共享的),那上方的緩存就會命中率變低,更多的請求穿透到L3,甚至是更下方的內(nèi)存中訪問,程序的運行效率就會變差。
那如何衡量指令運行效率呢?指標(biāo)主要有以下兩類
第一類是CPI和IPC。
CPI全稱是cycle per instruction,指的是平均每條指令的時鐘周期個數(shù)。IPC的全稱是instruction per cycle,表示每時鐘周期運行多少個指令。這兩個指標(biāo)可以幫助我們分析我們的可執(zhí)行程序運行的快還是慢。由于這二位互為倒數(shù),所以實踐中只關(guān)注一個CPI就夠了。
CPI 指標(biāo)可以讓我們從整體上對程序的運行速度有一個把握。假如我們的程序運行緩存命中率高,大部分?jǐn)?shù)據(jù)都在緩存中能訪問到,那 CPI 就會比較的低。假如說我們的程序的局部性原理把握的不好,或者是說內(nèi)核的調(diào)度算法有問題,那很有可能執(zhí)行同樣的指令就需要更多的CPU周期,程序的性能也會表現(xiàn)的比較的差,CPI 指標(biāo)也會偏高。
第二類是緩存命中率。
緩存命中率指標(biāo)分析的是程序運行時讀取數(shù)據(jù)時有多少沒有被緩存兜住,而穿透訪問到內(nèi)存中了。穿透到內(nèi)存中訪問速度會慢很多。所以程序運行時的 Cachemiss 指標(biāo)就是越低越好了。
二、如何評估CPU硬件效率
上一小節(jié)我們說到CPU硬件工作效率的指標(biāo)主要有 CPI 和緩存命中率。那么我們該如何獲取這些指標(biāo)呢?
2.1 使用 perf 工具
第一個辦法是采用 Linux 默認(rèn)自帶的 perf 工具。使用 perf list 可以查看當(dāng)前系統(tǒng)上支持的硬件事件指標(biāo)。
#perflisthwcache Listofpre-definedevents(tobeusedin-e): branch-instructionsORbranches[Hardwareevent] branch-misses[Hardwareevent] bus-cycles[Hardwareevent] cache-misses[Hardwareevent] cache-references[Hardwareevent] cpu-cyclesORcycles[Hardwareevent] instructions[Hardwareevent] ref-cycles[Hardwareevent] L1-dcache-load-misses[Hardwarecacheevent] L1-dcache-loads[Hardwarecacheevent] L1-dcache-stores[Hardwarecacheevent] L1-icache-load-misses[Hardwarecacheevent] branch-load-misses[Hardwarecacheevent] branch-loads[Hardwarecacheevent] dTLB-load-misses[Hardwarecacheevent] dTLB-loads[Hardwarecacheevent] dTLB-store-misses[Hardwarecacheevent] dTLB-stores[Hardwarecacheevent] iTLB-load-misses[Hardwarecacheevent] iTLB-loads[Hardwarecacheevent]
上述輸出中我們挑幾個重要的來解釋一下
cpu-cycles: 消耗的CPU周期
instructions: 執(zhí)行的指令計數(shù),結(jié)合cpu-cycles可以計算出CPI(每條指令需要消耗的平均周期數(shù))
L1-dcache-loads: 一級數(shù)據(jù)緩存讀取次數(shù)
L1-dcache-load-missed: 一級數(shù)據(jù)緩存讀取失敗次數(shù),結(jié)合L1-dcache-loads可以計算出L1級數(shù)據(jù)緩存命中率
dTLB-loads:dTLB緩存讀取次數(shù)
dTLB-load-misses:dTLB緩存讀取失敗次數(shù),結(jié)合dTLB-loads同樣可以算出緩存命中率
使用 perf stat 命令可以統(tǒng)計當(dāng)前系統(tǒng)或者指定進(jìn)程的上面這些指標(biāo)。直接使用 perf stat 可以統(tǒng)計到CPI。(如果要統(tǒng)計指定進(jìn)程的話只需要多個 -p 參數(shù),寫名 pid 就可以了)
#perfstatsleep5 Performancecounterstatsfor'sleep5': ...... 1,758,466cycles#2.575GHz 871,474instructions#0.50insnpercycle
從上述結(jié)果 instructions 后面的注釋可以看出,當(dāng)前系統(tǒng)的 IPC 指標(biāo)是 0.50,也就是說平均一個 CPU 周期可以執(zhí)行 0.5 個指令。前面我們說過 CPI 和 IPC 互為倒數(shù),所以 1/0.5 我們可以計算出 CPI 指標(biāo)為 2。也就是說平均一個指令需要消耗 2 個CPU周期。
我們再來看看 L1 和 dTLB 的緩存命中率情況,這次需要在 perf stat 后面跟上 -e 選項來指定要觀測的指標(biāo)了,因為這幾個指標(biāo)默認(rèn)都不輸出。
#perfstat-eL1-dcache-load-misses,L1-dcache-loads,dTLB-load-misses,dTLB-loadssleep5 Performancecounterstatsfor'sleep5': 22,578L1-dcache-load-misses#10.22%ofallL1-dcacheaccesses 220,911L1-dcache-loads 2,101dTLB-load-misses#0.95%ofalldTLBcacheaccesses 220,911dTLB-loads
上述結(jié)果中 L1-dcache-load-misses 次數(shù)為22,578,總的 L1-dcache-loads 為 220,911。可以算出 L1-dcache 的緩存訪問失敗率大約是 10.22%。同理我們可以算出 dTLB cache 的訪問失敗率是 0.95。這兩個指標(biāo)雖然已經(jīng)不高了,但是實踐中仍然是越低越好。
2.2 直接使用內(nèi)核提供的系統(tǒng)調(diào)用
雖然 perf 給我們提供了非常方便的用法。但是在某些業(yè)務(wù)場景中,你可能仍然需要自己編程實現(xiàn)數(shù)據(jù)的獲取。這時候就只能繞開 perf 直接使用內(nèi)核提供的系統(tǒng)調(diào)用來獲取這些硬件指標(biāo)了。
開發(fā)步驟大概包含這么兩個步驟
第一步:調(diào)用 perf_event_open 創(chuàng)建 perf 文件描述符
第二步:定時 read 讀取 perf 文件描述符獲取數(shù)據(jù)
其核心代碼大概如下。為了避免干擾,我只保留了主干。完整的源碼我放到咱們開發(fā)內(nèi)功修改的 Github 上了。
Github地址:https://github.com/yanfeizhang/coder-kung-fu/blob/main/tests/cpu/test08/main.c
intmain()
{
//第一步:創(chuàng)建perf文件描述符
structperf_event_attrattr;
attr.type=PERF_TYPE_HARDWARE;//表示監(jiān)測硬件
attr.config=PERF_COUNT_HW_INSTRUCTIONS;//標(biāo)志監(jiān)測指令數(shù)
//第一個參數(shù)pid=0表示只檢測當(dāng)前進(jìn)程
//第二個參數(shù)cpu=-1表示檢測所有cpu核
intfd=perf_event_open(&attr,0,-1,-1,0);
//第二步:定時獲取指標(biāo)計數(shù)
while(1)
{
read(fd,&instructions,sizeof(instructions));
...
}
}
在源碼中首先聲明了一個創(chuàng)建 perf 文件所需要的 perf_event_attr 參數(shù)對象。這個對象中 type 設(shè)置為 PERF_TYPE_HARDWARE 表示監(jiān)測硬件事件。config 設(shè)置為 PERF_COUNT_HW_INSTRUCTIONS 表示要監(jiān)測指令數(shù)。
然后調(diào)用 perf_event_open系統(tǒng)調(diào)用。在該系統(tǒng)調(diào)用中,除了 perf_event_attr 對象外,pid 和 cpu 這兩個參數(shù)也是非常的關(guān)鍵。其中 pid 為 -1 表示要監(jiān)測所有進(jìn)程,為 0 表示監(jiān)測當(dāng)前進(jìn)程,> 0 表示要監(jiān)測指定 pid 的進(jìn)程。對于 cpu 來說。-1 表示要監(jiān)測所有的核,其它值表示只監(jiān)測指定的核。
內(nèi)核在分配到 perf_event 以后,會返回一個文件句柄fd。后面這個perf_event結(jié)構(gòu)可以通過read/write/ioctl/mmap通用文件接口來操作。
perf_event 編程有兩種使用方法,分別是計數(shù)和采樣。本文中的例子是最簡單的技術(shù)。對于采樣場景,支持的功能更豐富,可以獲取調(diào)用棧,進(jìn)而渲染出火焰圖等更高級的功能。這種情況下就不能使用簡單的 read ,需要給 perf_event 分配 ringbuffer 空間,然后通過mmap系統(tǒng)調(diào)用來讀取了。在 perf 中對應(yīng)的功能是 perf record/report 功能。
將完整的源碼編譯運行后。
#gccmain.c-omain #./main instructions=1799 instructions=112654 instructions=123078 instructions=133505 ...
三、perf內(nèi)部工作原理
你以為看到這里本文就結(jié)束了?大錯特錯!只講用法不講原理從來不是咱們開發(fā)內(nèi)功修煉公眾號的風(fēng)格。
所以介紹完如何獲取硬件指標(biāo)后,咱們接下來也會展開聊聊上層的軟件是如何和CPU硬件協(xié)同來獲取到底層的指令數(shù)、緩存命中率等指標(biāo)的。展開聊聊底層原理。
CPU的硬件開發(fā)者們也想到了軟件同學(xué)們會有統(tǒng)計觀察硬件指標(biāo)的需求。所以在硬件設(shè)計的時候,加了一類專用的寄存器,專門用于系統(tǒng)性能監(jiān)視。關(guān)于這部分的描述參見Intel官方手冊的第18節(jié)。這個手冊你在網(wǎng)上可以搜到,我也會把它丟到我的讀者群里,還沒進(jìn)群的同學(xué)加我微信 zhangyanfei748527。
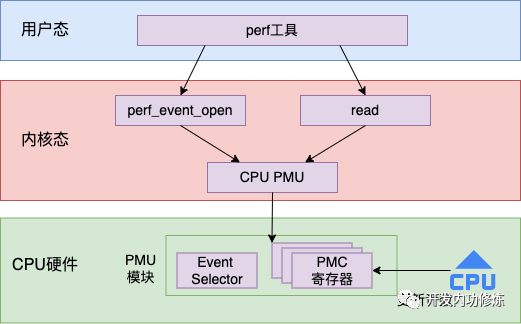
這類寄存器的名字叫硬件性能計數(shù)器(PMC: Performance Monitoring Counter)。每個PMC寄存器都包含一個計數(shù)器和一個事件選擇器,計數(shù)器用于存儲事件發(fā)生的次數(shù),事件選擇器用于確定所要計數(shù)的事件類型。例如,可以使用PMC寄存器來統(tǒng)計 L1 緩存命中率或指令執(zhí)行周期數(shù)等。當(dāng)CPU執(zhí)行到 PMC 寄存器所指定的事件時,硬件會自動對計數(shù)器加1,而不會對程序的正常執(zhí)行造成任何干擾。
有了底層的支持,上層的 Linux 內(nèi)核就可以通過讀取這些 PMC 寄存器的值來獲取想要觀察的指標(biāo)了。整體的工作流程圖如下
接下來我們再從源碼的視角展開看一下這個過程。
3.1 CPU PMU 的初始化
Linux 的 PMU (Performance Monitoring Unit)子系統(tǒng)是一種用于監(jiān)視和分析系統(tǒng)性能的機制。它將每一種要觀察的指標(biāo)都定義為了一個 PMU,通過 perf_pmu_register 函數(shù)來注冊到系統(tǒng)中。
其中對于 CPU 來說,定義了一個針對 x86 架構(gòu) CPU 的 PMU,并在開機啟動的時候就會注冊到系統(tǒng)中。
//file:arch/x86/events/core.c
staticstructpmupmu={
.pmu_enable=x86_pmu_enable,
.read=x86_pmu_read,
...
}
staticint__initinit_hw_perf_events(void)
{
...
err=perf_pmu_register(&pmu,"cpu",PERF_TYPE_RAW);
}
3.2 perf_event_open 系統(tǒng)調(diào)用
在前面的實例代碼中,我們看到是通過 perf_event_open 系統(tǒng)調(diào)用來創(chuàng)建了一個 perf 文件。我們來看下這個創(chuàng)建過程都做了啥?
//file:kernel/events/core.c
SYSCALL_DEFINE5(perf_event_open,
structperf_event_attr__user*,attr_uptr,
pid_t,pid,int,cpu,int,group_fd,unsignedlong,flags)
{
...
//1.為調(diào)用者申請新文件句柄
event_fd=get_unused_fd_flags(f_flags);
...
//2.根據(jù)用戶參數(shù)attr,定位pmu對象,通過pmu初始化event
event=perf_event_alloc(&attr,cpu,task,group_leader,NULL,
NULL,NULL,cgroup_fd);
pmu=event->pmu;
//3.創(chuàng)建perf_event_contextctx對象,ctx保存了事件上下文的各種信息
ctx=find_get_context(pmu,task,event);
//4.創(chuàng)建一個文件,指定perf類型文件的操作函數(shù)為perf_fops
event_file=anon_inode_getfile("[perf_event]",&perf_fops,event,
f_flags);
//5.把event安裝到ctx中
perf_install_in_context(ctx,event,event->cpu);
fd_install(event_fd,event_file);
returnevent_fd;
}
上面的代碼是 perf_event_open 的核心源碼。其中最關(guān)鍵的是 perf_event_alloc 的調(diào)用。在這個函數(shù)中,根據(jù)用戶傳入的 attr 來查找 pmu 對象。回憶本文的實例代碼,我們指定的是要監(jiān)測CPU硬件中的指令數(shù)。
structperf_event_attrattr; attr.type=PERF_TYPE_HARDWARE;//表示監(jiān)測硬件 attr.config=PERF_COUNT_HW_INSTRUCTIONS;//標(biāo)志監(jiān)測指令數(shù)
所以這里就會定位到我們3.1節(jié)提到的 CPU PMU 對象,并用這個 pmu 初始化 新event。接著再調(diào)用 anon_inode_getfile 創(chuàng)建一個真正的文件對象,并指定該文件的操作方法是 perf_fops。perf_fops 定義的操作函數(shù)如下:
//file:kernel/events/core.c staticconststructfile_operationsperf_fops={ ... .read=perf_read, .unlocked_ioctl=perf_ioctl, .mmap=perf_mmap, };
在創(chuàng)建完 perf 內(nèi)核對象后。還會觸發(fā)在perf_pmu_enable,經(jīng)過一系列的調(diào)用,最終會指定要監(jiān)測的寄存器。
perf_pmu_enable ->pmu_enable ->x86_pmu_enable ->x86_assign_hw_event
//file:arch/x86/events/core.c
staticinlinevoidx86_assign_hw_event(structperf_event*event,
structcpu_hw_events*cpuc,inti)
{
structhw_perf_event*hwc=&event->hw;
...
if(hwc->idx==INTEL_PMC_IDX_FIXED_BTS){
hwc->config_base=0;
hwc->event_base=0;
}elseif(hwc->idx>=INTEL_PMC_IDX_FIXED){
hwc->config_base=MSR_ARCH_PERFMON_FIXED_CTR_CTRL;
hwc->event_base=MSR_ARCH_PERFMON_FIXED_CTR0+(hwc->idx-INTEL_PMC_IDX_FIXED);
hwc->event_base_rdpmc=(hwc->idx-INTEL_PMC_IDX_FIXED)|1<<30;
????}?else?{
????????hwc->config_base=x86_pmu_config_addr(hwc->idx);
hwc->event_base=x86_pmu_event_addr(hwc->idx);
hwc->event_base_rdpmc=x86_pmu_rdpmc_index(hwc->idx);
}
}
3.3 read 讀取計數(shù)
在實例代碼的第二步中,就是定時調(diào)用 read 系統(tǒng)調(diào)用來讀取指標(biāo)計數(shù)。在 3.2 節(jié)中我們看到了新創(chuàng)建出來的 perf 文件對象在內(nèi)核中的操作方法是 perf_read。
//file:kernel/events/core.c
staticconststructfile_operationsperf_fops={
...
.read=perf_read,
.unlocked_ioctl=perf_ioctl,
.mmap=perf_mmap,
};
perf_read 函數(shù)實際上支持可以同時讀取多個指標(biāo)出來。但為了描述起來簡單,我只描述其讀取一個指標(biāo)時的工作流程。其調(diào)用鏈如下:
perf_read __perf_read perf_read_one __perf_event_read_value perf_event_read __perf_event_read_cpu perf_event_count
其中在 perf_event_read 中是要讀取硬件寄存器中的值。
staticintperf_event_read(structperf_event*event,boolgroup)
{
enumperf_event_statestate=READ_ONCE(event->state);
intevent_cpu,ret=0;
...
again:
//如果event正在運行嘗試更新最新的數(shù)據(jù)
if(state==PERF_EVENT_STATE_ACTIVE){
...
data=(structperf_read_data){
.event=event,
.group=group,
.ret=0,
};
(void)smp_call_function_single(event_cpu,__perf_event_read,&data,1);
preempt_enable();
ret=data.ret;
}elseif(state==PERF_EVENT_STATE_INACTIVE){
...
}
returnret;
}
smp_call_function_single 這個函數(shù)是要在指定的 CPU 上運行某個函數(shù)。因為寄存器都是 CPU 專屬的,所以讀取寄存器應(yīng)該要指定 CPU 核。要運行的函數(shù)就是其參數(shù)中指定的 __perf_event_read。在這個函數(shù)中,真正讀取了 x86 CPU 硬件寄存器。
__perf_event_read ->x86_pmu_read ->intel_pmu_read_event ->x86_perf_event_update
其中 __perf_event_read 調(diào)用到 x86 架構(gòu)這塊是通過函數(shù)指針指過來的。
//file:kernel/events/core.c
staticvoid__perf_event_read(void*info)
{
...
pmu->read(event);
}
在3.1中我們介紹過CPU 的這個pmu,它的read函數(shù)指針是指向 x86_pmu_read的。
//file:arch/x86/events/core.c
staticstructpmupmu={
...
.read=x86_pmu_read,
}
這樣就會執(zhí)行到 x86_pmu_read,最后就會調(diào)用到 x86_perf_event_update。在 x86_perf_event_update 中調(diào)用 rdpmcl 匯編指令來獲取寄存器中的值。
//file:arch/x86/events/core.c
u64x86_perf_event_update(structperf_event*event)
{
...
rdpmcl(hwc->event_base_rdpmc,new_raw_count);
returnnew_raw_count
}
最后返回到 perf_read_one 中會調(diào)用 copy_to_user 將值真正拷貝到用戶空間中,這樣我們的進(jìn)程就讀取到了寄存器中的硬件執(zhí)行計數(shù)了。
//file:kernel/events/core.c
staticintperf_read_one(structperf_event*event,
u64read_format,char__user*buf)
{
values[n++]=__perf_event_read_value(event,&enabled,&running);
...
copy_to_user(buf,values,n*sizeof(u64))
returnn*sizeof(u64);
}
總結(jié)
雖然內(nèi)存很快,但它的速度在 CPU 面前也只是個弟弟。所以 CPU 并不直接從內(nèi)存中獲取要運行的指令和數(shù)據(jù),而是優(yōu)先使用自己的緩存。只有緩存不命中的時候才會請求內(nèi)存,性能也會變低。
那觀察 CPU 使用緩存效率高不高的指標(biāo)主要有 CPI 和緩存命中率幾個指標(biāo)。CPU 硬件在實現(xiàn)上,定義了專門 PMU 模塊,其中包含專門用戶計數(shù)的寄存器。當(dāng)CPU執(zhí)行到 PMC 寄存器所指定的事件時,硬件會自動對計數(shù)器加1,而不會對程序的正常執(zhí)行造成任何干擾。有了底層的支持,上層的 Linux 內(nèi)核就可以通過讀取這些 PMC 寄存器的值來獲取想要觀察的指標(biāo)了。
我們可以使用 perf 來觀察,也可以直接使用內(nèi)核提供的 perf_event_open 系統(tǒng)調(diào)用獲取 perf 文件對象,然后自己來讀取。
-
cpu
+關(guān)注
關(guān)注
68文章
10824瀏覽量
211137 -
硬件
+關(guān)注
關(guān)注
11文章
3252瀏覽量
66112 -
光刻機
+關(guān)注
關(guān)注
31文章
1147瀏覽量
47249
原文標(biāo)題:人人都應(yīng)該知道的CPU緩存運行效率
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
DSP程序運行效率
CPU主頻降到極低到1Hz,系統(tǒng)還能運行嗎
使用智能外設(shè)提高CPU效率

配電網(wǎng)運行效率評價
Intel Graphics上提高CPU效率的DX12
CPU的概念是什么
cpu的程序是如何運行起來的
CPU運行模式S7-CPU工作的原理
CPU工作過程——MCU

程序是如何在 CPU 中運行的(二)
信創(chuàng)基礎(chǔ)硬件:CPU、GPU、存儲和整機
如何評估CPU硬件效率?CPU硬件運行效率介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論