") 使用Alpaca-Lora進(jìn)行參數(shù)高效模型微調(diào)
使用Alpaca-Lora進(jìn)行參數(shù)高效模型微調(diào)
之前嘗試了從0到1復(fù)現(xiàn)斯坦福羊駝(Stanford Alpaca 7B),Stanford Alpaca 是在 LLaMA 整個(gè)模型上微調(diào),即對(duì)預(yù)訓(xùn)練模型中的所有參數(shù)都進(jìn)行微調(diào)(full fine-tuning)。但該方法對(duì)于硬件成本要求仍然偏高且訓(xùn)練低效。
因此, Alpaca-Lora 則是利用 Lora 技術(shù),在凍結(jié)原模型 LLaMA 參數(shù)的情況下,通過(guò)往模型中加入額外的網(wǎng)絡(luò)層,并只訓(xùn)練這些新增的網(wǎng)絡(luò)層參數(shù)。由于這些新增參數(shù)數(shù)量較少,這樣不僅微調(diào)的成本顯著下降(使用一塊 RTX 4090 顯卡,只用 5 個(gè)小時(shí)就訓(xùn)練了一個(gè)與 Alpaca 水平相當(dāng)?shù)哪P停瑢⑦@類模型對(duì)算力的需求降到了消費(fèi)級(jí)),還能獲得和全模型微調(diào)(full fine-tuning)類似的效果。
LoRA 技術(shù)原理
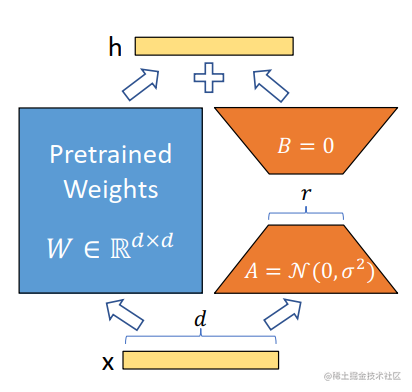 image.png
image.pngLoRA 的原理其實(shí)并不復(fù)雜,它的核心思想是在原始預(yù)訓(xùn)練語(yǔ)言模型旁邊增加一個(gè)旁路,做一個(gè)降維再升維的操作,來(lái)模擬所謂的 intrinsic rank(預(yù)訓(xùn)練模型在各類下游任務(wù)上泛化的過(guò)程其實(shí)就是在優(yōu)化各類任務(wù)的公共低維本征(low-dimensional intrinsic)子空間中非常少量的幾個(gè)自由參數(shù))。訓(xùn)練的時(shí)候固定預(yù)訓(xùn)練語(yǔ)言模型的參數(shù),只訓(xùn)練降維矩陣 A 與升維矩陣 B。而模型的輸入輸出維度不變,輸出時(shí)將 BA 與預(yù)訓(xùn)練語(yǔ)言模型的參數(shù)疊加。用隨機(jī)高斯分布初始化 A,用 0 矩陣初始化 B。這樣能保證訓(xùn)練開(kāi)始時(shí),新增的通路BA=0從,而對(duì)模型結(jié)果沒(méi)有影響。
在推理時(shí),將左右兩部分的結(jié)果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要將訓(xùn)練完成的矩陣乘積BA跟原本的權(quán)重矩陣W加到一起作為新權(quán)重參數(shù)替換原始預(yù)訓(xùn)練語(yǔ)言模型的W即可,不會(huì)增加額外的計(jì)算資源。
LoRA 的最大優(yōu)勢(shì)是速度更快,使用的內(nèi)存更少;因此,可以在消費(fèi)級(jí)硬件上運(yùn)行。
下面,我們來(lái)嘗試使用Alpaca-Lora進(jìn)行參數(shù)高效模型微調(diào)。
環(huán)境搭建
基礎(chǔ)環(huán)境配置如下:
- 操作系統(tǒng): CentOS 7
- CPUs: 單個(gè)節(jié)點(diǎn)具有 1TB 內(nèi)存的 Intel CPU,物理CPU個(gè)數(shù)為64,每顆CPU核數(shù)為16
- GPUs: 8 卡 A800 80GB GPUs
- Python: 3.10 (需要先升級(jí)OpenSSL到1.1.1t版本(點(diǎn)擊下載OpenSSL),然后再編譯安裝Python),點(diǎn)擊下載Python
- NVIDIA驅(qū)動(dòng)程序版本: 515.65.01,根據(jù)不同型號(hào)選擇不同的驅(qū)動(dòng)程序,點(diǎn)擊下載。
- CUDA工具包: 11.7,點(diǎn)擊下載
- NCCL: nccl_2.14.3-1+cuda11.7,點(diǎn)擊下載
- cuDNN: 8.8.1.3_cuda11,點(diǎn)擊下載
上面的NVIDIA驅(qū)動(dòng)、CUDA、Python等工具的安裝就不一一贅述了。
創(chuàng)建虛擬環(huán)境并激活虛擬環(huán)境alpara-lora-venv-py310-cu117:
cd /home/guodong.li/virtual-venv
virtualenv -p /usr/bin/python3.10 alpara-lora-venv-py310-cu117
source /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/bin/activate
離線安裝PyTorch,點(diǎn)擊下載對(duì)應(yīng)cuda版本的torch和torchvision即可。
pip install torch-1.13.1+cu117-cp310-cp310-linux_x86_64.whl
pip install pip install torchvision-0.14.1+cu117-cp310-cp310-linux_x86_64.whl
安裝transformers,目前,LLaMA相關(guān)的實(shí)現(xiàn)并沒(méi)有發(fā)布對(duì)應(yīng)的版本,但是已經(jīng)合并到主分支了,因此,我們需要切換到對(duì)應(yīng)的commit,從源代碼進(jìn)行相應(yīng)的安裝。
cd transformers
git checkout 0041be5
pip install .
在 Alpaca-LoRA 項(xiàng)目中,作者提到,為了廉價(jià)高效地進(jìn)行微調(diào),他們使用了 Hugging Face 的 PEFT。PEFT 是一個(gè)庫(kù)(LoRA 是其支持的技術(shù)之一,除此之外還有Prefix Tuning、P-Tuning、Prompt Tuning),可以讓你使用各種基于 Transformer 結(jié)構(gòu)的語(yǔ)言模型進(jìn)行高效微調(diào)。下面安裝PEFT。
git clone https://github.com/huggingface/peft.git
cd peft/
git checkout e536616
pip install .
安裝bitsandbytes。
git clone git@github.com:TimDettmers/bitsandbytes.git
cd bitsandbytes
CUDA_VERSION=117 make cuda11x
python setup.py install
安裝其他相關(guān)的庫(kù)。
cd alpaca-lora
pip install -r requirements.txt
requirements.txt文件具體的內(nèi)容如下:
accelerate
appdirs
loralib
black
black[jupyter]
datasets
fire
sentencepiece
gradio
模型格式轉(zhuǎn)換
將LLaMA原始權(quán)重文件轉(zhuǎn)換為Transformers庫(kù)對(duì)應(yīng)的模型文件格式。具體可參考之前的文章:從0到1復(fù)現(xiàn)斯坦福羊駝(Stanford Alpaca 7B) 。如果不想轉(zhuǎn)換LLaMA模型,也可以直接從Hugging Face下載轉(zhuǎn)換好的模型。
模型微調(diào)
訓(xùn)練的默認(rèn)值如下所示:
batch_size: 128
micro_batch_size: 4
num_epochs: 3
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
使用默認(rèn)參數(shù),單卡訓(xùn)練完成大約需要5個(gè)小時(shí),且對(duì)于GPU顯存的消耗確實(shí)很低。
1%|█▌ | 12/1170 [03:21<545, 16.83s/it]
本文為了加快訓(xùn)練速度,將batch_size和micro_batch_size調(diào)大并將num_epochs調(diào)小了。
python finetune.py
--base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b'
--data_path '/data/nfs/guodong.li/data/alpaca_data_cleaned.json'
--output_dir '/home/guodong.li/output/lora-alpaca'
--batch_size 256
--micro_batch_size 16
--num_epochs 2
當(dāng)然也可以根據(jù)需要微調(diào)超參數(shù),參考示例如下:
python finetune.py
--base_model 'decapoda-research/llama-7b-hf'
--data_path 'yahma/alpaca-cleaned'
--output_dir './lora-alpaca'
--batch_size 128
--micro_batch_size 4
--num_epochs 3
--learning_rate 1e-4
--cutoff_len 512
--val_set_size 2000
--lora_r 8
--lora_alpha 16
--lora_dropout 0.05
--lora_target_modules '[q_proj,v_proj]'
--train_on_inputs
--group_by_length
運(yùn)行過(guò)程:
python finetune.py
> --base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b'
> --data_path '/data/nfs/guodong.li/data/alpaca_data_cleaned.json'
> --output_dir '/home/guodong.li/output/lora-alpaca'
> --batch_size 256
> --micro_batch_size 16
> --num_epochs 2
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst')}
warn(msg)
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/libbitsandbytes_cuda117.so...
Training Alpaca-LoRA model with params:
base_model: /data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b
data_path: /data/nfs/guodong.li/data/alpaca_data_cleaned.json
output_dir: /home/guodong.li/output/lora-alpaca
batch_size: 256
micro_batch_size: 16
num_epochs: 2
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:10<00:00, 3.01it/s]
Found cached dataset json (/home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 228.95it/s]
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
Loading cached split indices for dataset at /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-d8c5d7ac95d53860.arrow and /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-4a34b0c9feb19e72.arrow
{'loss': 2.2501, 'learning_rate': 2.6999999999999996e-05, 'epoch': 0.05}
...
{'loss': 0.8998, 'learning_rate': 0.000267, 'epoch': 0.46}
{'loss': 0.8959, 'learning_rate': 0.00029699999999999996, 'epoch': 0.51}
28%|███████████████████████████████████████████▎ | 109/390 [32:48<114, 17.77s/it]
顯存占用:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.105.01 Driver Version: 515.105.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A800 80G... Off | 0000000000.0 Off | 0 |
| N/A 71C P0 299W / 300W | 57431MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
...
+-------------------------------+----------------------+----------------------+
| 7 NVIDIA A800 80G... Off | 0000000000.0 Off | 0 |
| N/A 33C P0 71W / 300W | 951MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 55017 C python 57429MiB |
...
| 7 N/A N/A 55017 C python 949MiB |
+-----------------------------------------------------------------------------+
發(fā)現(xiàn)GPU的使用率上去了,訓(xùn)練速度也提升了,但是沒(méi)有充分利用GPU資源,單卡訓(xùn)練(epoch:3)大概3小時(shí)即可完成。
因此,為了進(jìn)一步提升模型訓(xùn)練速度,下面嘗試使用數(shù)據(jù)并行,在多卡上面進(jìn)行訓(xùn)練。
torchrun --nproc_per_node=8 --master_port=29005 finetune.py
--base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b'
--data_path '/data/nfs/guodong.li/data/alpaca_data_cleaned.json'
--output_dir '/home/guodong.li/output/lora-alpaca'
--batch_size 256
--micro_batch_size 16
--num_epochs 2
運(yùn)行過(guò)程:
torchrun --nproc_per_node=8 --master_port=29005 finetune.py
> --base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b'
> --data_path '/data/nfs/guodong.li/data/alpaca_data_cleaned.json'
> --output_dir '/home/guodong.li/output/lora-alpaca'
> --batch_size 256
> --micro_batch_size 16
> --num_epochs 2
WARNING
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
...
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst')}
warn(msg)
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/libbitsandbytes_cuda117.so...
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst')}
...
Training Alpaca-LoRA model with params:
base_model: /data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b
data_path: /data/nfs/guodong.li/data/alpaca_data_cleaned.json
output_dir: /home/guodong.li/output/lora-alpaca
batch_size: 256
micro_batch_size: 16
num_epochs: 2
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:14<00:00, 2.25it/s]
...
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:20<00:00, 1.64it/s]
Found cached dataset json (/home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 129.11it/s]
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
Loading cached split indices for dataset at /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-d8c5d7ac95d53860.arrow and /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-4a34b0c9feb19e72.arrow
Map: 4%|██████▎ | 2231/49942 [00:01<00:37, 1256.31 examples/s]Found cached dataset json (/home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 220.24it/s]
...
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
Loading cached split indices for dataset at /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-d8c5d7ac95d53860.arrow and /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-4a34b0c9feb19e72.arrow
Map: 2%|██▋ | 939/49942 [00:00<00:37, 1323.94 examples/s]Found cached dataset json (/home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 362.77it/s]
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
Loading cached split indices for dataset at /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-d8c5d7ac95d53860.arrow and /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-4a34b0c9feb19e72.arrow
{'loss': 2.2798, 'learning_rate': 1.7999999999999997e-05, 'epoch': 0.05}
...
{'loss': 0.853, 'learning_rate': 0.0002006896551724138, 'epoch': 1.02}
{'eval_loss': 0.8590874075889587, 'eval_runtime': 10.5401, 'eval_samples_per_second': 189.752, 'eval_steps_per_second': 3.036, 'epoch': 1.02}
{'loss': 0.8656, 'learning_rate': 0.0001903448275862069, 'epoch': 1.07}
...
{'loss': 0.8462, 'learning_rate': 6.620689655172413e-05, 'epoch': 1.69}
{'loss': 0.8585, 'learning_rate': 4.137931034482758e-06, 'epoch': 1.99}
{'loss': 0.8549, 'learning_rate': 0.00011814432989690721, 'epoch': 2.05}
{'eval_loss': 0.8465630412101746, 'eval_runtime': 10.5273, 'eval_samples_per_second': 189.983, 'eval_steps_per_second': 3.04, 'epoch': 2.05}
{'loss': 0.8492, 'learning_rate': 0.00011195876288659793, 'epoch': 2.1}
...
{'loss': 0.8398, 'learning_rate': 1.2989690721649484e-05, 'epoch': 2.92}
{'loss': 0.8473, 'learning_rate': 6.804123711340206e-06, 'epoch': 2.97}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 585/585 [23:46<00:00, 2.38s/it]
{'train_runtime': 1426.9255, 'train_samples_per_second': 104.999, 'train_steps_per_second': 0.41, 'train_loss': 0.9613736364576552, 'epoch': 2.99}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 585/585 [23:46<00:00, 2.44s/it]
模型文件:
> tree /home/guodong.li/output/lora-alpaca
/home/guodong.li/output/lora-alpaca
├── adapter_config.json
├── adapter_model.bin
└── checkpoint-200
├── optimizer.pt
├── pytorch_model.bin
├── rng_state_0.pth
├── rng_state_1.pth
├── rng_state_2.pth
├── rng_state_3.pth
├── rng_state_4.pth
├── rng_state_5.pth
├── rng_state_6.pth
├── rng_state_7.pth
├── scaler.pt
├── scheduler.pt
├── trainer_state.json
└── training_args.bin
1 directory, 16 files
我們可以看到,在數(shù)據(jù)并行的情況下,如果epoch=3(本文epoch=2),訓(xùn)練僅需要20分鐘左右即可完成。目前,tloen/Alpaca-LoRA-7b提供的最新“官方”的Alpaca-LoRA adapter于 3 月 26 日使用以下超參數(shù)進(jìn)行訓(xùn)練。
- Epochs: 10 (load from best epoch)
- Batch size: 128
- Cutoff length: 512
- Learning rate: 3e-4
- Lorar: 16
- Lora target modules: q_proj, k_proj, v_proj, o_proj
具體命令如下:
python finetune.py
--base_model='decapoda-research/llama-7b-hf'
--num_epochs=10
--cutoff_len=512
--group_by_length
--output_dir='./lora-alpaca'
--lora_target_modules='[q_proj,k_proj,v_proj,o_proj]'
--lora_r=16
--micro_batch_size=8
模型推理
運(yùn)行命令如下:
python generate.py
--load_8bit
--base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b'
--lora_weights '/home/guodong.li/output/lora-alpaca'
運(yùn)行這個(gè)腳本會(huì)啟動(dòng)一個(gè)gradio服務(wù),你可以通過(guò)瀏覽器在網(wǎng)頁(yè)上進(jìn)行測(cè)試。
運(yùn)行過(guò)程如下所示:
python generate.py
> --load_8bit
> --base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b'
> --lora_weights '/home/guodong.li/output/lora-alpaca'
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst')}
warn(msg)
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/libbitsandbytes_cuda117.so...
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:12<00:00, 2.68it/s]
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/gradio/inputs.py UserWarning: Usage of gradio.inputs is deprecated, and will not be supported in the future, please import your component from gradio.components
warnings.warn(
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/gradio/deprecation.py UserWarning: `optional` parameter is deprecated, and it has no effect
warnings.warn(value)
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/gradio/deprecation.py UserWarning: `numeric` parameter is deprecated, and it has no effect
warnings.warn(value)
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
顯存占用:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.105.01 Driver Version: 515.105.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A800 80G... Off | 0000000000.0 Off | 0 |
| N/A 50C P0 81W / 300W | 8877MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 7837 C python 8875MiB |
+-----------------------------------------------------------------------------+
打開(kāi)瀏覽器輸入IP+端口進(jìn)行測(cè)試。
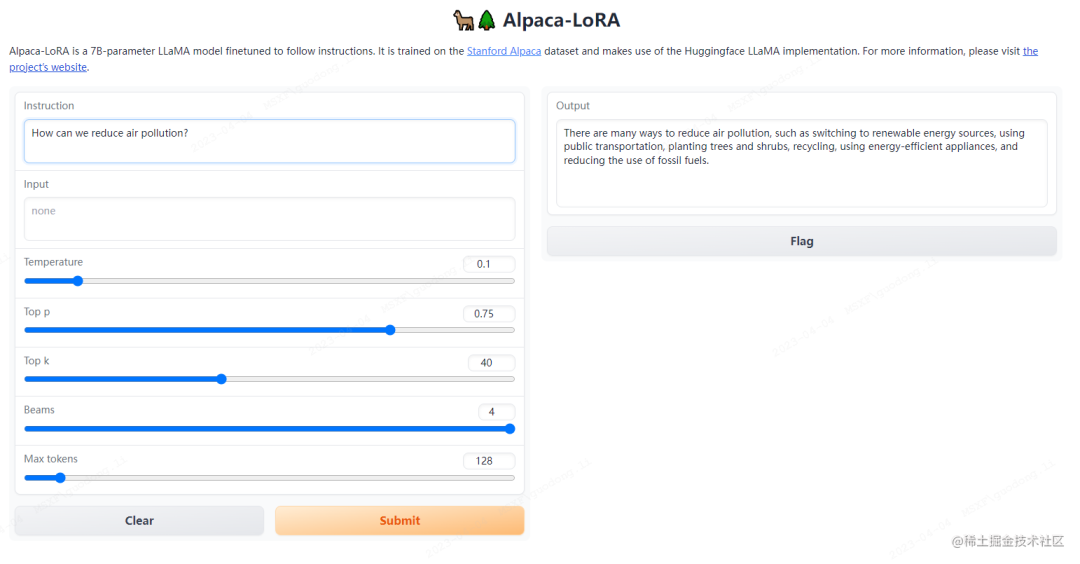 image.png
image.png將 LoRA 權(quán)重合并回基礎(chǔ)模型
下面將 LoRA 權(quán)重合并回基礎(chǔ)模型以導(dǎo)出為 HuggingFace 格式和 PyTorch state_dicts。以幫助想要在 llama.cpp 或 alpaca.cpp 等項(xiàng)目中運(yùn)行推理的用戶。
導(dǎo)出為 HuggingFace 格式:
修改export_hf_checkpoint.py文件:
import os
import torch
import transformers
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: F402
BASE_MODEL = os.environ.get("BASE_MODEL", None)
# TODO
LORA_MODEL = os.environ.get("LORA_MODEL", "tloen/alpaca-lora-7b")
HF_CHECKPOINT = os.environ.get("HF_CHECKPOINT", "./hf_ckpt")
assert (
BASE_MODEL
), "Please specify a value for BASE_MODEL environment variable, e.g. `export BASE_MODEL=decapoda-research/llama-7b-hf`" # noqa: E501
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()
lora_model = PeftModel.from_pretrained(
base_model,
# TODO
# "tloen/alpaca-lora-7b",
LORA_MODEL,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
...
# TODO
LlamaForCausalLM.save_pretrained(
base_model, HF_CHECKPOINT , state_dict=deloreanized_sd, max_shard_size="400MB"
)
運(yùn)行命令:
BASE_MODEL=/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b
LORA_MODEL=/home/guodong.li/output/lora-alpaca
HF_CHECKPOINT=/home/guodong.li/output/hf_ckpt
python export_hf_checkpoint.py
運(yùn)行過(guò)程:
BASE_MODEL=/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b
> LORA_MODEL=/home/guodong.li/output/lora-alpaca
> HF_CHECKPOINT=/home/guodong.li/output/hf_ckpt
> python export_hf_checkpoint.py
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst')}
warn(msg)
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/libbitsandbytes_cuda117.so...
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:05<00:00, 5.99it/s]
查看模型輸出文件:
> tree /home/guodong.li/output/hf_ckpt
/home/guodong.li/output/hf_ckpt
├── config.json
├── generation_config.json
├── pytorch_model-00001-of-00039.bin
├── pytorch_model-00002-of-00039.bin
...
├── pytorch_model-00038-of-00039.bin
├── pytorch_model-00039-of-00039.bin
└── pytorch_model.bin.index.json
0 directories, 42 files
導(dǎo)出為PyTorch state_dicts:
修改export_state_dict_checkpoint.py文件:
import json
import os
import torch
import transformers
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: E402
BASE_MODEL = os.environ.get("BASE_MODEL", None)
LORA_MODEL = os.environ.get("LORA_MODEL", "tloen/alpaca-lora-7b")
PTH_CHECKPOINT_PREFIX = os.environ.get("PTH_CHECKPOINT_PREFIX", "./ckpt")
assert (
BASE_MODEL
), "Please specify a value for BASE_MODEL environment variable, e.g. `export BASE_MODEL=decapoda-research/llama-7b-hf`" # noqa: E501
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
lora_model = PeftModel.from_pretrained(
base_model,
# todo
#"tloen/alpaca-lora-7b",
LORA_MODEL,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
...
os.makedirs(PTH_CHECKPOINT_PREFIX, exist_ok=True)
torch.save(new_state_dict, PTH_CHECKPOINT_PREFIX+"/consolidated.00.pth")
with open(PTH_CHECKPOINT_PREFIX+"/params.json", "w") as f:
json.dump(params, f)
運(yùn)行命令:
BASE_MODEL=/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b
LORA_MODEL=/home/guodong.li/output/lora-alpaca
PTH_CHECKPOINT_PREFIX=/home/guodong.li/output/ckpt
python export_state_dict_checkpoint.py
查看模型輸出文件:
tree /home/guodong.li/output/ckpt
/home/guodong.li/output/ckpt
├── consolidated.00.pth
└── params.json
當(dāng)然,你還可以封裝為Docker鏡像來(lái)對(duì)訓(xùn)練和推理環(huán)境進(jìn)行隔離。
封裝為Docker鏡像并進(jìn)行推理
- 構(gòu)建Docker鏡像:
docker build -t alpaca-lora .
-
運(yùn)行Docker容器進(jìn)行推理 (您還可以使用
finetune.py及其上面提供的所有超參數(shù)進(jìn)行訓(xùn)練):
docker run --gpus=all --shm-size 64g -p 7860:7860 -v ${HOME}/.cache:/root/.cache --rm alpaca-lora generate.py
--load_8bit
--base_model 'decapoda-research/llama-7b-hf'
--lora_weights 'tloen/alpaca-lora-7b'
-
打開(kāi)瀏覽器,輸入U(xiǎn)RL:
https://localhost:7860進(jìn)行測(cè)試。
結(jié)語(yǔ)
從上面可以看到,在一臺(tái)8卡的A800服務(wù)器上面,基于Alpaca-Lora針對(duì)alpaca_data_cleaned.json指令數(shù)據(jù)大概20分鐘左右即可完成參數(shù)高效微調(diào),相對(duì)于斯坦福羊駝?dòng)?xùn)練速度顯著提升。
參考文檔:
- LLaMA
- Stanford Alpaca:斯坦福-羊駝
- Alpaca-LoRA
審核編輯 :李倩
-
服務(wù)器
+關(guān)注
關(guān)注
12文章
9024瀏覽量
85187 -
模型
+關(guān)注
關(guān)注
1文章
3174瀏覽量
48720 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
508瀏覽量
10245
原文標(biāo)題:足夠驚艷,使用Alpaca-Lora基于LLaMA(7B)二十分鐘完成微調(diào),效果比肩斯坦福羊駝
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
有哪些省內(nèi)存的大語(yǔ)言模型訓(xùn)練/微調(diào)/推理方法?
使用LoRA和Hugging Face高效訓(xùn)練大語(yǔ)言模型
如何訓(xùn)練自己的ChatGPT
關(guān)于LLM+LoRa微調(diào)加速技術(shù)原理
調(diào)教LLaMA類模型沒(méi)那么難,LoRA將模型微調(diào)縮減到幾小時(shí)

iPhone都能微調(diào)大模型了嘛
GLoRA—高效微調(diào)模型參數(shù)
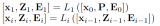
GLoRA:一種廣義參數(shù)高效的微調(diào)方法
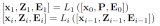
怎樣使用QLoRA對(duì)Llama 2進(jìn)行微調(diào)呢?
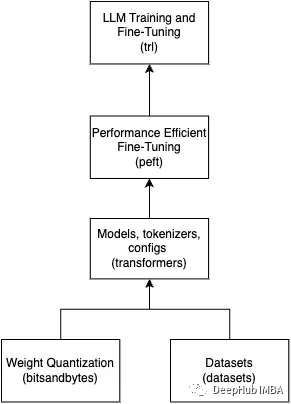
四種微調(diào)大模型的方法介紹
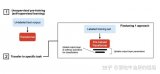
大模型微調(diào)開(kāi)源項(xiàng)目全流程
基于雙級(jí)優(yōu)化(BLO)的消除過(guò)擬合的微調(diào)方法

大模型為什么要微調(diào)?大模型微調(diào)的原理
chatglm2-6b在P40上做LORA微調(diào)
一種信息引導(dǎo)的量化后LLM微調(diào)新算法IR-QLoRA






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論