") 如何利用LLM做一些多模態(tài)任務(wù)
如何利用LLM做一些多模態(tài)任務(wù)
大型語(yǔ)言模型LLM(Large Language Model)具有很強(qiáng)的通用知識(shí)理解以及較強(qiáng)的邏輯推理能力,但其只能處理文本數(shù)據(jù)。雖然已經(jīng)發(fā)布的GPT4具備圖片理解能力,但目前還未開(kāi)放多模態(tài)輸入接口并且不會(huì)透露任何模型上技術(shù)細(xì)節(jié)。因此,現(xiàn)階段,如何利用LLM做一些多模態(tài)任務(wù)還是有一定的研究?jī)r(jià)值的。
本文整理了近兩年來(lái)基于LLM做vision-lanuage任務(wù)的一些工作,并將其劃分為4個(gè)類別:
凍住LLM,訓(xùn)練視覺(jué)編碼器等額外結(jié)構(gòu)以適配LLM,例如mPLUG-Owl,LLaVA,Mini-GPT4,F(xiàn)rozen,BLIP2,F(xiàn)lamingo,PaLM-E[1]
將視覺(jué)轉(zhuǎn)化為文本,作為L(zhǎng)LM的輸入,例如PICA(2022),PromptCap(2022)[2],ScienceQA(2022)[3]
利用視覺(jué)模態(tài)影響LLM的解碼,例如ZeroCap[4],MAGIC
利用LLM作為理解中樞調(diào)用多模態(tài)模型,例如VisualChatGPT(2023), MM-REACT(2023)
接下來(lái)每個(gè)類別會(huì)挑選代表性的工作進(jìn)行簡(jiǎn)單介紹:
訓(xùn)練視覺(jué)編碼器等額外結(jié)構(gòu)以適配LLM
這部分工作是目前關(guān)注度最高的工作,因?yàn)樗哂袧摿?lái)以遠(yuǎn)低于多模態(tài)通用模型訓(xùn)練的代價(jià)將LLM拓展為多模態(tài)模型。
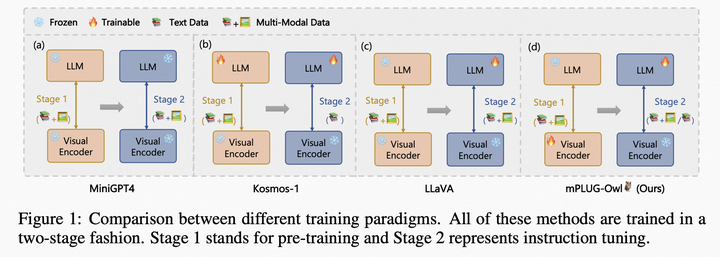
隨著GPT4的火熱,近期涌現(xiàn)了大量的工作,如LLaVA, Mini-GPT4和mPLUG-Owl。這三個(gè)工作的主要區(qū)別如下圖所示,總體而言,模型結(jié)構(gòu)和訓(xùn)練策略方面大同小異,主要體現(xiàn)在LLaVA和MiniGPT4都凍住基礎(chǔ)視覺(jué)編碼器,mPLUG-Owl將其放開(kāi),得到了更好的視覺(jué)文本跨模態(tài)理解效果;在實(shí)驗(yàn)方面mPLUG-Owl首次構(gòu)建并開(kāi)源視覺(jué)相關(guān)的指令理解測(cè)試集OwlEval,通過(guò)人工評(píng)測(cè)對(duì)比了已有的模型,包括BLIP2、LLaVA、MiniGPT4以及系統(tǒng)類工作MM-REACT。
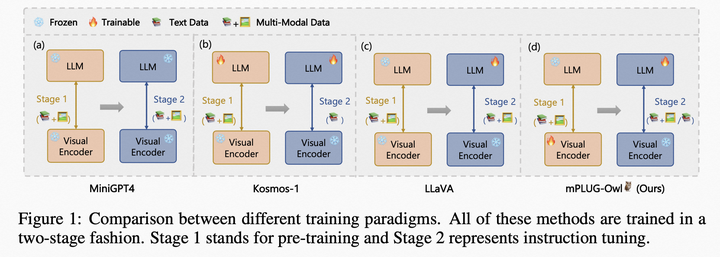 mPLUG-Owl vs MiniGPT4 vs LLaVA
mPLUG-Owl vs MiniGPT4 vs LLaVA
mPLUG-Owl
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
mPLUG-Owl是阿里巴巴達(dá)摩院mPLUG系列的最新工作,繼續(xù)延續(xù)mPLUG系列的模塊化訓(xùn)練思想,將LLM遷移為一個(gè)多模態(tài)大模型。此外,Owl第一次針對(duì)視覺(jué)相關(guān)的指令評(píng)測(cè)提出一個(gè)全面的測(cè)試集OwlEval,通過(guò)人工評(píng)測(cè)對(duì)比了已有工作,包括LLaVA和MIniGPT4。該評(píng)測(cè)集以及人工打分的結(jié)果都進(jìn)行了開(kāi)源,助力后續(xù)多模態(tài)開(kāi)放式回答的公平對(duì)比。
模型結(jié)構(gòu):采用CLIP ViT-L/14作為"視覺(jué)基礎(chǔ)模塊",采用LLaMA初始化的結(jié)構(gòu)作為文本解碼器,采用類似Flamingo的Perceiver Resampler結(jié)構(gòu)對(duì)視覺(jué)特征進(jìn)行重組(名為"視覺(jué)摘要模塊"),如圖。
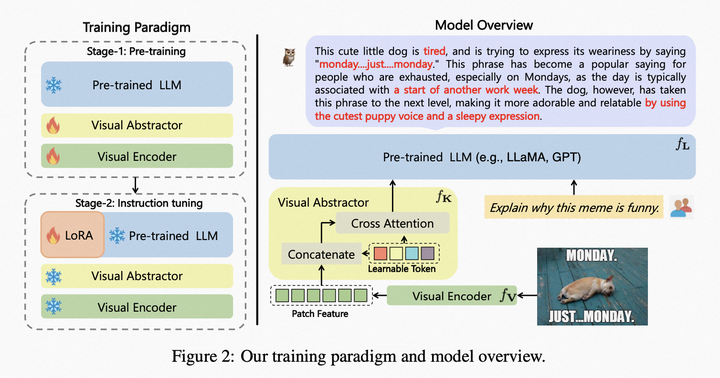 mPLUG-Owl模型結(jié)構(gòu)
mPLUG-Owl模型結(jié)構(gòu)
模型訓(xùn)練
第一階段: 主要目的也是先學(xué)習(xí)視覺(jué)和語(yǔ)言模態(tài)間的對(duì)齊。不同于前兩個(gè)工作,Owl提出凍住視覺(jué)基礎(chǔ)模塊會(huì)限制模型關(guān)聯(lián)視覺(jué)知識(shí)和文本知識(shí)的能力。因此Owl在第一階段只凍住LLM的參數(shù),采用LAION-400M,COYO-700M,CC以及MSCOCO訓(xùn)練視覺(jué)基礎(chǔ)模塊和視覺(jué)摘要模塊。
第二階段: 延續(xù)mPLUG和mPLUG-2中不同模態(tài)混合訓(xùn)練對(duì)彼此有收益的發(fā)現(xiàn),Owl在第二階段的指令微調(diào)訓(xùn)練中也同時(shí)采用了純文本的指令數(shù)據(jù)(102k from Alpaca+90k from Vicuna+50k from Baize)和多模態(tài)的指令數(shù)據(jù)(150k from LLaVA)。作者通過(guò)詳細(xì)的消融實(shí)驗(yàn)驗(yàn)證了引入純文本指令微調(diào)在指令理解等方面帶來(lái)的收益。第二階段中視覺(jué)基礎(chǔ)模塊、視覺(jué)摘要模塊和原始LLM的參數(shù)都被凍住,參考LoRA,只在LLM引入少量參數(shù)的adapter結(jié)構(gòu)用于指令微調(diào)。
實(shí)驗(yàn)分析
除了訓(xùn)練策略,mPLUG-Owl另一個(gè)重要的貢獻(xiàn)在于通過(guò)構(gòu)建OwlEval評(píng)測(cè)集,對(duì)比了目前將LLM用于多模態(tài)指令回答的SOTA模型的效果。和NLP領(lǐng)域一樣,在指令理解場(chǎng)景中,模型的回答由于開(kāi)放性很難進(jìn)行評(píng)估。
SOTA對(duì)比:本文初次嘗試構(gòu)建了一個(gè)基于50張圖片(21張來(lái)自MiniGPT-4, 13張來(lái)自MM-REACT, 9張來(lái)自BLIP-2, 3來(lái)自GPT-4以及4張自收集)的82個(gè)視覺(jué)相關(guān)的指令回答評(píng)測(cè)集OwlEval。由于目前并沒(méi)有合適的自動(dòng)化指標(biāo),本文參考Self-Intruct對(duì)模型的回復(fù)進(jìn)行人工評(píng)測(cè),打分規(guī)則為:A="正確且令人滿意";B="有一些不完美,但可以接受";C="理解了指令但是回復(fù)存在明顯錯(cuò)誤";D="完全不相關(guān)或不正確的回復(fù)"。實(shí)驗(yàn)證明Owl在視覺(jué)相關(guān)的指令回復(fù)任務(wù)上優(yōu)于已有的OpenFlamingo、BLIP2、LLaVA、MiniGPT4以及集成了Microsoft 多個(gè)API的MM-REACT。作者對(duì)這些人工評(píng)測(cè)的打分同樣進(jìn)行了開(kāi)源以方便其他研究人員檢驗(yàn)人工評(píng)測(cè)的客觀性。
多維度能力對(duì)比:多模態(tài)指令回復(fù)任務(wù)中牽扯到多種能力,例如指令理解、視覺(jué)理解、圖片上文字理解以及推理等。為了細(xì)粒度地探究模型在不同能力上的水平,本文進(jìn)一步定義了多模態(tài)場(chǎng)景中的6種主要的能力,并對(duì)OwlEval每個(gè)測(cè)試指令人工標(biāo)注了相關(guān)的能力要求以及模型的回復(fù)中體現(xiàn)了哪些能力。在該部分實(shí)驗(yàn),作者既進(jìn)行了Owl的消融實(shí)驗(yàn),驗(yàn)證了訓(xùn)練策略和多模態(tài)指令微調(diào)數(shù)據(jù)的有效性,也和上一個(gè)實(shí)驗(yàn)中表現(xiàn)最佳的baseline——MiniGPT4進(jìn)行了對(duì)比,結(jié)果顯示Owl在各個(gè)能力方面都優(yōu)于MiniGPT4。
LLaVA
Visual instruction tuning
自然語(yǔ)言處理領(lǐng)域的instruction tuning可以幫助LLM理解多樣化的指令并生成比較詳細(xì)的回答。LLaVA首次嘗試構(gòu)建圖文相關(guān)的instruction tuning數(shù)據(jù)集來(lái)將LLM拓展到多模態(tài)領(lǐng)域。具體來(lái)說(shuō),基于MSCOCO數(shù)據(jù)集,每張圖有5個(gè)較簡(jiǎn)短的ground truth描述和object bbox(包括類別和位置)序列,將這些作為text-only GPT4的輸入,通過(guò)prompt的形式讓GPT4生成3種類型的文本:1)關(guān)于圖像中對(duì)象的對(duì)話;2)針對(duì)圖片的詳細(xì)描述;3)和圖片相關(guān)的復(fù)雜的推理過(guò)程。注意,這三種類型都是GPT4在不看到圖片的情況下根據(jù)輸入的文本生成的,為了讓GPT4理解這些意圖,作者額外人工標(biāo)注了一些樣例用于in-context learning。
模型結(jié)構(gòu):采用CLIP的ViT-L/14作為視覺(jué)編碼器,采用LLaMA作為文本解碼器,通過(guò)一個(gè)簡(jiǎn)單的線性映射層將視覺(jué)編碼器的輸出映射到文本解碼器的詞嵌入空間,如圖。
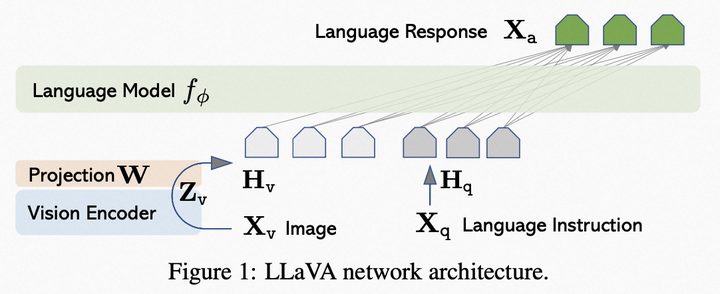 LLaVA模型結(jié)構(gòu)
LLaVA模型結(jié)構(gòu)
模型訓(xùn)練1/ 第一階段:跨模態(tài)對(duì)齊預(yù)訓(xùn)練,從CC3M中通過(guò)限制caption中名詞詞組的最小頻率過(guò)濾出595k圖文數(shù)據(jù),凍住視覺(jué)編碼器和文本解碼器,只訓(xùn)練線性映射層;2. 第二階段:指令微調(diào),一版針對(duì)多模態(tài)聊天機(jī)器人場(chǎng)景,采用自己構(gòu)建的158k多模態(tài)指令數(shù)據(jù)集進(jìn)行微調(diào);另一版針對(duì)Science QA數(shù)據(jù)集進(jìn)行微調(diào)。微調(diào)階段,線性層和文本解碼器(LLaMA)都會(huì)進(jìn)行優(yōu)化。
實(shí)驗(yàn)分析
消融實(shí)驗(yàn): 在30個(gè)MSCOCO val的圖片上,每張圖片設(shè)計(jì)3個(gè)問(wèn)題(對(duì)話、詳細(xì)描述、推理),參考 Vicuna[8],用GPT4對(duì)LLaVA和text-only GPT4的回復(fù)進(jìn)行對(duì)比打分,報(bào)告相對(duì)text-only GPT4的相對(duì)值。
SOTA對(duì)比: 在Science QA上微調(diào)的版本實(shí)現(xiàn)了該評(píng)測(cè)集上的SOTA效果。
Mini-GPT4
Minigpt-4: Enhancing vision-language under- standing with advanced large language models
Mini-GPT4和LLaVA類似,也發(fā)現(xiàn)了多模態(tài)指令數(shù)據(jù)對(duì)于模型在多模態(tài)開(kāi)放式場(chǎng)景中表現(xiàn)的重要性。
模型結(jié)構(gòu):采用BLIP2的ViT和Q-Former作為視覺(jué)編碼器,采用LLaMA經(jīng)過(guò)自然語(yǔ)言指令微調(diào)后的版本Vicuna作為文本解碼器,也通過(guò)一個(gè)線性映射層將視覺(jué)特征映射到文本表示空間,如圖:
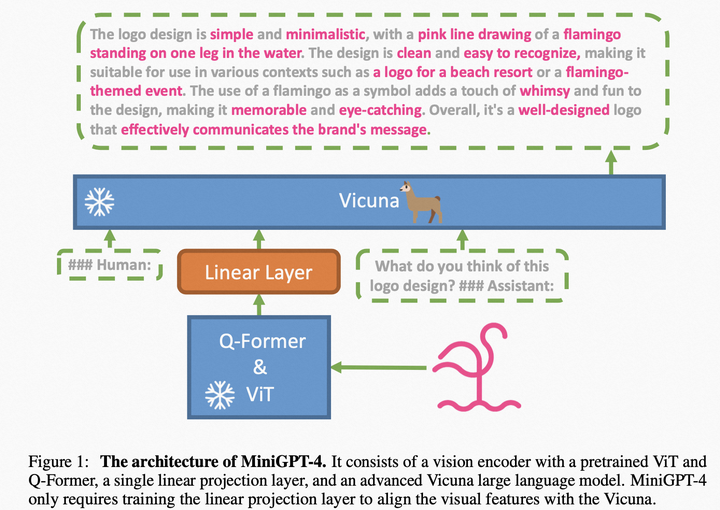 MiniGPT4模型結(jié)構(gòu)
MiniGPT4模型結(jié)構(gòu)
模型訓(xùn)練
第一階段:目標(biāo)通過(guò)大量圖文對(duì)數(shù)據(jù)學(xué)習(xí)視覺(jué)和語(yǔ)言的關(guān)系以及知識(shí),采用CC+SBU+LAION數(shù)據(jù)集,凍住視覺(jué)編碼器和文本解碼器,只訓(xùn)練線性映射層;
第二階段:作者發(fā)現(xiàn)只有第一階段的預(yù)訓(xùn)練并不能讓模型生成流暢且豐富的符合用戶需求的文本,為了緩解這個(gè)問(wèn)題,本文也額外利用ChatGPT構(gòu)建一個(gè)多模態(tài)微調(diào)數(shù)據(jù)集。具體來(lái)說(shuō),1)其首先用階段1的模型對(duì)5k個(gè)CC的圖片進(jìn)行描述,如果長(zhǎng)度小于80,通過(guò)prompt讓模型繼續(xù)描述,將多步生成的結(jié)果合并為一個(gè)描述;2)通過(guò)ChatGPT對(duì)于構(gòu)建的長(zhǎng)描述進(jìn)行改寫(xiě),移除重復(fù)等問(wèn)題;3)人工驗(yàn)證以及優(yōu)化描述質(zhì)量。最后得到3.5k圖文對(duì),用于第二階段的微調(diào)。第二階段同樣只訓(xùn)練線性映射層。
DeepMind于2021年發(fā)表的Frozen,2022年的Flamingo以及Saleforce 2023年的BLIP2也都是這條路線,如圖所示。
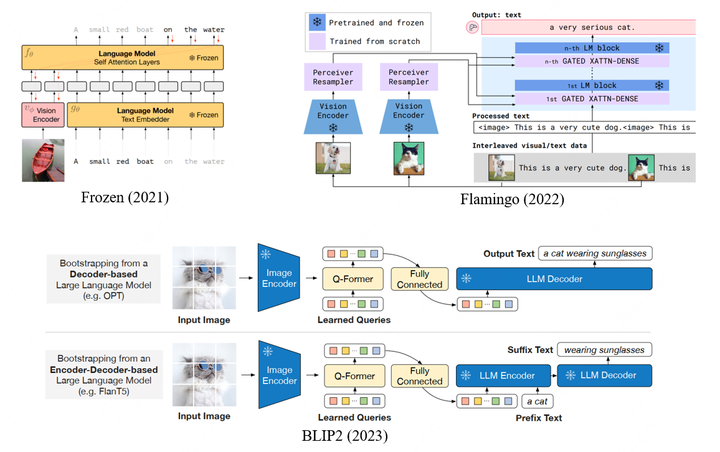
Frozen
Multimodal Few-Shot Learning with Frozen Language Models.
Frozen訓(xùn)練時(shí)將圖片編碼成2個(gè)vision token,作為L(zhǎng)LM的前綴,目標(biāo)為生成后續(xù)文本,采用Conceptual Caption作為訓(xùn)練語(yǔ)料。Frozen通過(guò)few-shot learning/in-context learning做下游VQA以及image classification的效果還沒(méi)有很強(qiáng),但是已經(jīng)能觀察到一些多模態(tài)in-context learning的能力。
Flamingo
Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo為了解決視覺(jué)feature map大小可能不一致(尤其對(duì)于多幀的視頻)的問(wèn)題,用Perceiver Resampler (類似DETR的解碼器)生成固定長(zhǎng)度的特征序列(64個(gè)token),并且在LLM的每一層之前額外增加了一層對(duì)視覺(jué)特征進(jìn)行注意力計(jì)算的cross-attention layer,以實(shí)現(xiàn)更強(qiáng)的視覺(jué)相關(guān)性生成。Flamingo的訓(xùn)練參數(shù)遠(yuǎn)高于Frozen,因此采用了大量的數(shù)據(jù):1)MultiModal MassiveWeb(M3W) dataset:從43million的網(wǎng)頁(yè)上收集的圖文混合數(shù)據(jù),轉(zhuǎn)化為圖文交叉排列的序列(根據(jù)網(wǎng)頁(yè)上圖片相對(duì)位置,決定在轉(zhuǎn)化為序列后,token 在文本token系列中的位置);2)ALIGN (alt-text & image Pairs): 1.8 million圖文對(duì);3)LTIP (LongText & Image Pairs):312 million圖文對(duì);4)VTP (Video & Text Pairs) :27 million視頻文本對(duì)(平均一個(gè)視頻22s,幀采樣率為1FPS)。類似LLM,F(xiàn)lamingo的訓(xùn)練目標(biāo)也為文本生成,但其對(duì)于不同的數(shù)據(jù)集賦予不同的權(quán)重,上面四部分權(quán)重分別為1.0、0.2、0.2、0.03,可見(jiàn)圖文交叉排列的M3W數(shù)據(jù)集的訓(xùn)練重要性是最高的,作者也強(qiáng)調(diào)這類數(shù)據(jù)是具備多模態(tài)in-context learning能力的重要因素。Flamingo在多個(gè)任務(wù)上實(shí)現(xiàn)了很不錯(cuò)的zero-shot以及few-shot的表現(xiàn)。
BLIP2
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BLIP2采用了類似于Flamingo的視覺(jué)編碼結(jié)構(gòu),但是采用了更復(fù)雜的訓(xùn)練策略。其包含兩階段訓(xùn)練,第一階段主要想讓視覺(jué)編碼器學(xué)會(huì)提取最關(guān)鍵的視覺(jué)信息,訓(xùn)練任務(wù)包括image-Text Contrastive Learning, Image-grounded Text Generation以及Image-Text Matching;第二階段則主要是將視覺(jué)編碼結(jié)構(gòu)的輸出適配LLM,訓(xùn)練任務(wù)也是language modeling。BLIP2的訓(xùn)練數(shù)據(jù)包括MSCOCO,Visual Genome,CC15M,SBU,115M來(lái)自于LAION400M的圖片以及BLIP在web images上生成的描述。BLIP2實(shí)現(xiàn)了很強(qiáng)的zero-shot capitoning以及VQA的能力,但是作者提到未觀察到其in-context learning的能力,即輸入樣例并不能提升它的性能。作者分析是因?yàn)橛?xùn)練數(shù)據(jù)里不存在Flamingo使用的圖文交錯(cuò)排布的數(shù)據(jù)。不過(guò)Frozen也是沒(méi)有用這類數(shù)據(jù),但是也觀察到了一定的in-context learning能力。因此多模態(tài)的in-context learning能力可能和訓(xùn)練數(shù)據(jù)、訓(xùn)練任務(wù)以及位置編碼方法等都存在相關(guān)性。
將視覺(jué)轉(zhuǎn)化為文本,作為L(zhǎng)LM的輸入
PICA
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
以PICA為例,它的目標(biāo)是充分利用LLM中的海量知識(shí)來(lái)做Knowledge-based QA。給定一張圖和問(wèn)題,以往的工作主要從外部來(lái)源,例如維基百科等來(lái)檢索出相關(guān)的背景知識(shí)以輔助答案的生成。但PICA嘗試將圖片用文本的形式描述出來(lái)后,直接和問(wèn)題拼在一起作為L(zhǎng)LM的輸入,讓LLM通過(guò)in-context learning的方式直接生成回答,如圖所示。
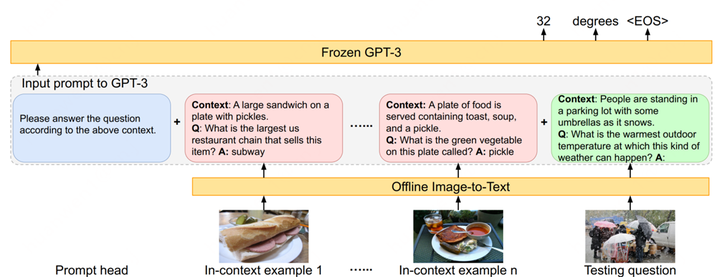 PICA
PICA
In-context learning的效果比較依賴example/demonstration的質(zhì)量,為此PICA的作者利用CLIP挑選了和當(dāng)前測(cè)試樣例在問(wèn)題和圖片上最接近的16個(gè)訓(xùn)練樣例作為examples。
利用視覺(jué)模態(tài)影響LLM的解碼
MAGIC
Language Models Can See: Plugging Visual Controls in Text Generation
以MAGIC為例,它的目標(biāo)是讓LLM做image captioning的任務(wù),它的核心思路是生成每一個(gè)詞時(shí),提高視覺(jué)相關(guān)的詞的生成概率,公式如圖所示。
 MAGIC解碼公式
MAGIC解碼公式
該公式主要由三部分組成:
LLM預(yù)測(cè)詞的概率
退化懲罰(橙色)
視覺(jué)相關(guān)性(紅色)
退化懲罰主要是希望生成的詞能帶來(lái)新的信息量。視覺(jué)相關(guān)性部分為基于CLIP計(jì)算了所有候選詞和圖片的相關(guān)性,取softmax之后的概率作為預(yù)測(cè)概率。
利用LLM作為理解中樞調(diào)用多模態(tài)模型
Visual ChatGPT
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
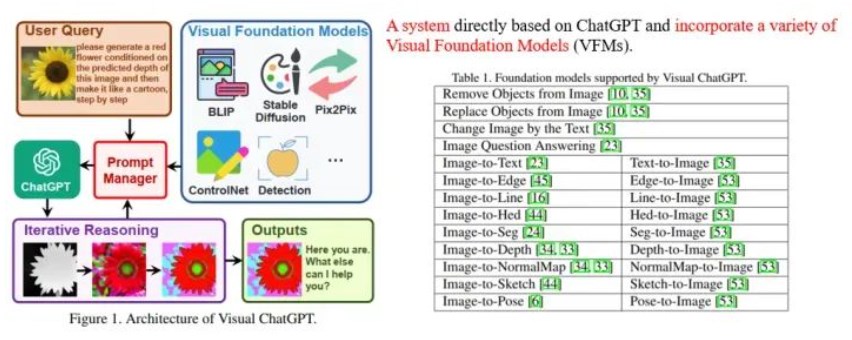
以微軟Visual ChatGPT為例,它的目標(biāo)是使得一個(gè)系統(tǒng)既能和人進(jìn)行視覺(jué)內(nèi)容相關(guān)的對(duì)話,又能進(jìn)行畫(huà)圖以及圖片修改的工作。為此,Visual ChatGPT采用ChatGPT作為和用戶交流的理解中樞,整合了多個(gè)視覺(jué)基礎(chǔ)模型(Visual Foundation Models),通過(guò)prompt engineering (即Prompt Manager)告訴ChatGPT各個(gè)基礎(chǔ)模型的用法以及輸入輸出格式,讓ChatGPT決定為了滿足用戶的需求,應(yīng)該如何調(diào)用這些模型,如圖所示。
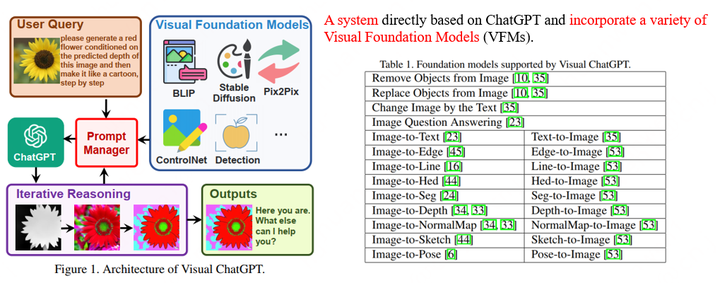
微軟另一個(gè)小組稍晚一段時(shí)間提出的MM-REACT[5]也是同樣的思路,區(qū)別主要在于prompt engineering的設(shè)計(jì)以及MM-REACT更側(cè)重于視覺(jué)的通用理解和解釋,包含了很多Microsoft Azure API,例如名人識(shí)別、票據(jù)識(shí)別以及Bing搜索等。
總結(jié)
對(duì)比幾種融入方式:
“訓(xùn)練視覺(jué)編碼器等額外結(jié)構(gòu)以適配LLM”具有更高的研究?jī)r(jià)值,因?yàn)槠渚邆鋵⑷我饽B(tài)融入LLM,實(shí)現(xiàn)真正意義多模態(tài)模型的潛力,其難點(diǎn)在于如何實(shí)現(xiàn)較強(qiáng)的in-context learning的能力。
“將視覺(jué)轉(zhuǎn)化為文本,作為L(zhǎng)LM的輸入”和“利用視覺(jué)模態(tài)影響LLM的解碼”可以直接利用LLM做一些多模態(tài)任務(wù),但是可能上限較低,其表現(xiàn)依賴于外部多模態(tài)模型的能力。
“利用LLM作為理解中樞調(diào)用多模態(tài)模型”可以方便快捷地基于LLM部署一個(gè)多模態(tài)理解和生成系統(tǒng),難點(diǎn)主要在于prompt engineering的設(shè)計(jì)來(lái)調(diào)度不同的多模態(tài)模型。
-
編碼器
+關(guān)注
關(guān)注
45文章
3597瀏覽量
134170 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
6898瀏覽量
88833 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
508瀏覽量
10245 -
LLM
+關(guān)注
關(guān)注
0文章
274瀏覽量
306
原文標(biāo)題:總結(jié)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
實(shí)時(shí)多任務(wù)系統(tǒng)中的一些基本概念
一種無(wú)監(jiān)督下利用多模態(tài)文檔結(jié)構(gòu)信息幫助圖片-句子匹配的采樣方法
多模態(tài)中NLP與CV融合的方式有哪些?
如何使用多模態(tài)信息做prompt
基于圖文多模態(tài)領(lǐng)域典型任務(wù)
一個(gè)真實(shí)閑聊多模態(tài)數(shù)據(jù)集TikTalk
利用大語(yǔ)言模型做多模態(tài)任務(wù)
如何利用LLM做多模態(tài)任務(wù)?
邱錫鵬團(tuán)隊(duì)提出具有內(nèi)生跨模態(tài)能力的SpeechGPT,為多模態(tài)LLM指明方向

Macaw-LLM:具有圖像、音頻、視頻和文本集成的多模態(tài)語(yǔ)言建模
更強(qiáng)更通用:智源「悟道3.0」Emu多模態(tài)大模型開(kāi)源,在多模態(tài)序列中「補(bǔ)全一切」

基于視覺(jué)的多模態(tài)觸覺(jué)感知系統(tǒng)
如何利用OpenVINO加速LangChain中LLM任務(wù)
大模型+多模態(tài)的3種實(shí)現(xiàn)方法

自動(dòng)駕駛和多模態(tài)大語(yǔ)言模型的發(fā)展歷程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論