") 模型在學(xué)習(xí)可轉(zhuǎn)移的語義分割表示方面的有效性
模型在學(xué)習(xí)可轉(zhuǎn)移的語義分割表示方面的有效性
目錄
前言
DPSS 方法概述
DeP 和 DDeP
基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu)
損失函數(shù)
diffusion 的擴(kuò)展
實(shí)驗(yàn)
總結(jié)
參考
前言
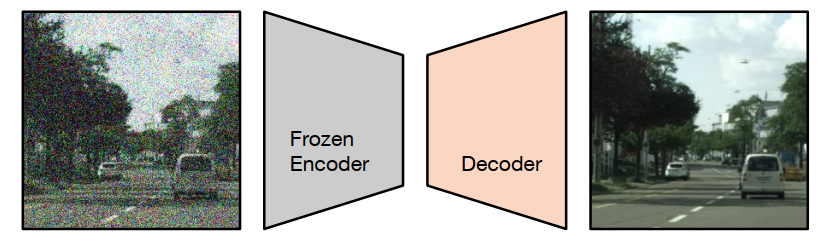
當(dāng)前語義分割任務(wù)存在一個特別常見的問題是收集 groundtruth 的成本和耗時很高,所以會使用預(yù)訓(xùn)練。例如監(jiān)督分類或自監(jiān)督特征提取,通常用于訓(xùn)練模型 backbone。基于該問題,這篇文章介紹的方法被叫做 decoder denoising pretraining (DDeP),如下圖所示。
 請?zhí)砑訄D片描述
請?zhí)砑訄D片描述
與標(biāo)準(zhǔn)的去噪自編碼器類似,網(wǎng)絡(luò)被訓(xùn)練用于對帶有噪聲的輸入圖像進(jìn)行去噪。然而,編碼器是使用監(jiān)督學(xué)習(xí)進(jìn)行預(yù)訓(xùn)練并凍結(jié)的,只有解碼器的參數(shù)使用去噪目標(biāo)進(jìn)行優(yōu)化。此外,當(dāng)給定一個帶有噪聲的輸入時,解碼器被訓(xùn)練用于預(yù)測噪聲,而不是直接預(yù)測干凈圖像,這也是比較常見的方式。
DPSS 方法概述
這次介紹的這篇文章叫做 Denoising Pretraining for Semantic Segmentation,為了方便,后文統(tǒng)一簡寫為 DPSS。DPSS 將基于 Transformer 的 U-Net 作為去噪自編碼器進(jìn)行預(yù)訓(xùn)練,然后在語義分割上使用少量標(biāo)記示例進(jìn)行微調(diào)。與隨機(jī)初始化的訓(xùn)練以及即使在標(biāo)記圖像數(shù)量較少時,對編碼器進(jìn)行監(jiān)督式 ImageNet-21K 預(yù)訓(xùn)練相比,去噪預(yù)訓(xùn)練(DeP)的效果更好。解碼器去噪預(yù)訓(xùn)練(DDeP)相對于主干網(wǎng)絡(luò)的監(jiān)督式預(yù)訓(xùn)練的一個關(guān)鍵優(yōu)勢是能夠預(yù)訓(xùn)練解碼器,否則解碼器將被隨機(jī)初始化。也就是說,DPSS 使用監(jiān)督學(xué)習(xí)初始化編碼器,并僅使用去噪目標(biāo)預(yù)訓(xùn)練解碼器。盡管方法簡單,但是 DDeP 在 label-efficient 的語義分割上取得了最先進(jìn)的結(jié)果。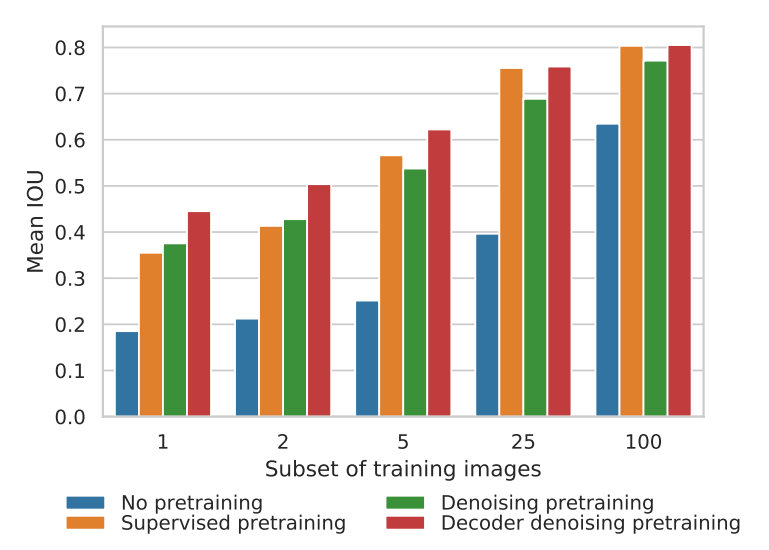
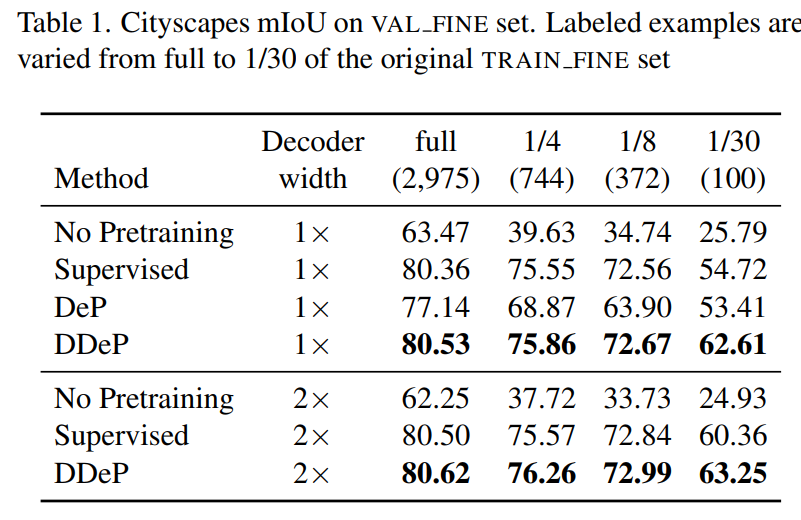
為了方便理解,上圖是以可用的標(biāo)記訓(xùn)練圖像比例為橫坐標(biāo)的 Cityscapes 驗(yàn)證集上的平均 IOU 結(jié)果。從左到右四個直方圖依次是不進(jìn)行預(yù)訓(xùn)練,使用 ImageNet-21K 預(yù)訓(xùn)練 backbone,使用 DeP 預(yù)訓(xùn)練編碼器和使用 DDeP 的方式。當(dāng)可用的標(biāo)記圖像比例小于5%時,去噪預(yù)訓(xùn)練效果顯著。當(dāng)可用標(biāo)記比例較大時,基于 ImageNet-21K 的監(jiān)督式預(yù)訓(xùn)練 backbone 網(wǎng)絡(luò)優(yōu)于去噪預(yù)訓(xùn)練。值得注意的是,DDeP 在各個標(biāo)記比例下都取得了最佳的結(jié)果。
DeP 和 DDeP
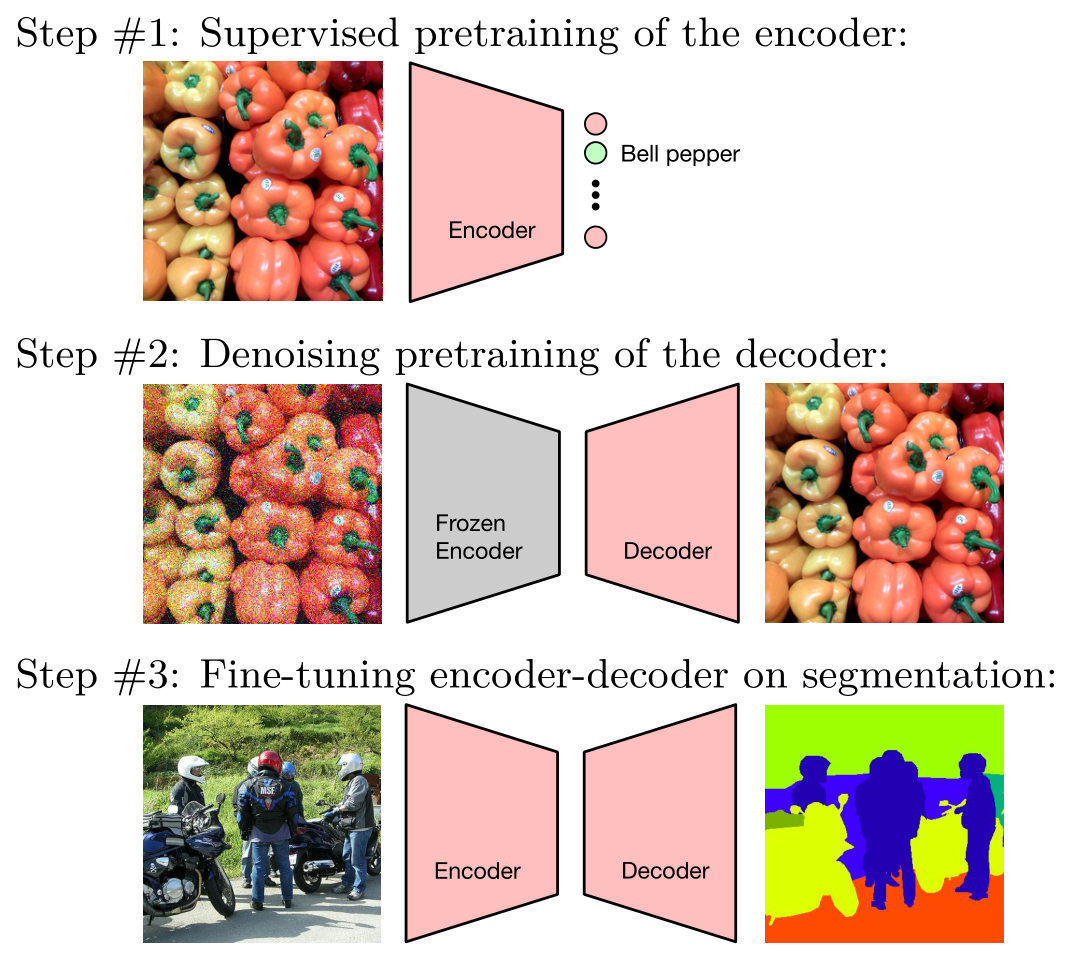
下圖是 DPSS 的一個形象的圖示,其中第二步代表 DDeP。最后的 Fine-tuning 過程是微調(diào)整個網(wǎng)絡(luò),而不是只做 last layer。
 請?zhí)砑訄D片描述
請?zhí)砑訄D片描述
基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu)
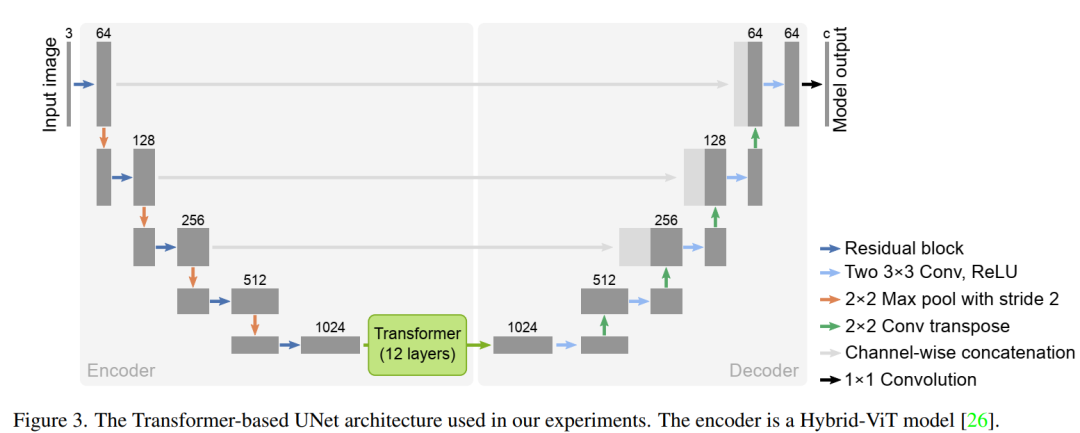
DPSS 使用了基于 Transfomer 的 U-Net 架構(gòu):TransUnet,如下圖所示。它將 12 層 Transfomer 與標(biāo)準(zhǔn)的 U-Net 模型相結(jié)合。這種架構(gòu)中的編碼器是一種混合模型,包括卷積層和自注意力層。也就是說,patch embeddings 是從 CNN 特征圖中提取的。這篇論文采用了和 Hybrid-vit 模型相同的編碼器,以利用在 imagenet-21k 數(shù)據(jù)集中預(yù)先訓(xùn)練的監(jiān)督模型 checkpoints。論文中強(qiáng)調(diào),去噪預(yù)訓(xùn)練方法并不特定模型架構(gòu)的選擇,只是結(jié)果都在 TransUNet 架構(gòu)上測試。
 請?zhí)砑訄D片描述
請?zhí)砑訄D片描述
損失函數(shù)
為了預(yù)訓(xùn)練 U-Net,設(shè)計(jì)了去噪目標(biāo)函數(shù)。該函數(shù)向未標(biāo)記的圖像添加高斯噪聲以創(chuàng)建噪點(diǎn)圖像。噪音水平由一個叫做 gamma 的標(biāo)量值控制:
然后,噪聲圖像被輸入到 U-Net,它試圖通過消除噪點(diǎn)來重建原始圖像。去噪目標(biāo)函數(shù)用如下公式表示,它涉及對噪聲水平和噪聲分布的期望值:
還將去噪目標(biāo)函數(shù)與另一種公式進(jìn)行了比較,該公式對圖像和噪聲進(jìn)行衰減以確保隨機(jī)變量的方差為 1。發(fā)現(xiàn)具有固定噪聲水平的更簡單的去噪目標(biāo)函數(shù)非常適合表示學(xué)習(xí):
DeP 經(jīng)過訓(xùn)練,可以從噪聲損壞的版本中重建圖像,并且可以使用未標(biāo)記的數(shù)據(jù)。降噪預(yù)訓(xùn)練目標(biāo)表示為 DDPM 擴(kuò)散過程的單次迭代。sigma 的選擇對表示學(xué)習(xí)質(zhì)量有很大影響,預(yù)訓(xùn)練后,最終的 projection layer 會被丟棄,然后再對語義分割任務(wù)進(jìn)行微調(diào)。此外,上面設(shè)計(jì) DDPM 的內(nèi)容,這里就不贅述了,在 GiantPandaCV 之前的語義分割和 diffusion 系列里可以找到。
diffusion 的擴(kuò)展
在最簡單的形式下,當(dāng)在上一節(jié)的最后一個方程中使用單個固定的 σ 值時,相當(dāng)于擴(kuò)散過程中的一步。DPSS 還研究了使該方法更接近于 DDPM 中使用的完整擴(kuò)散過程的方法,包括:
Variable noise schedule:在 DDPM 中,模擬從干凈圖像到純噪聲(以及其反向)的完整擴(kuò)散過程時,σ 被隨機(jī)均勻地從 [0, 1] 中抽樣,針對每個訓(xùn)練樣本。盡管發(fā)現(xiàn)固定的 σ 通常表現(xiàn)最佳,但 DPSS 也嘗試隨機(jī)采樣 σ。在這種情況下,將 σ 限制在接近 1 的范圍內(nèi)對于表示質(zhì)量是必要的。
Conditioning on noise level:在擴(kuò)散形式化方法中,模型表示從一個噪聲水平過渡到下一個的(反向)轉(zhuǎn)換函數(shù),因此受當(dāng)前噪聲水平的條件約束。在實(shí)踐中,這是通過將為每個訓(xùn)練樣本抽樣的 σ 作為額外的模型輸入(例如,用于標(biāo)準(zhǔn)化層)來實(shí)現(xiàn)的。由于我們通常使用固定的噪聲水平,對于 DPSS 來說,不需要進(jìn)行條件設(shè)置。
Weighting of noise levels:在 DDPM 中,損失函數(shù)中不同噪聲水平的相對權(quán)重對樣本質(zhì)量有很大影響。論文中的實(shí)驗(yàn)表明,學(xué)習(xí)可轉(zhuǎn)移表示不需要使用多個噪聲水平。因此,DPSS 并未對不同噪聲水平的加權(quán)進(jìn)行實(shí)驗(yàn)。
實(shí)驗(yàn)
實(shí)驗(yàn)在 Cityscapes,Pascal Context 和 ADE20K 數(shù)據(jù)集上。下面兩個表是在 Cityscapes 的驗(yàn)證集上進(jìn)行測試,其中還測試了可用帶標(biāo)簽訓(xùn)練數(shù)據(jù)為原始訓(xùn)練數(shù)據(jù)量 1/30 的情況,表明即使有標(biāo)簽的樣本數(shù)量很少,DPSS 在 mIoU 上的表現(xiàn)也優(yōu)于以前的方法。
 請?zhí)砑訄D片描述
請?zhí)砑訄D片描述 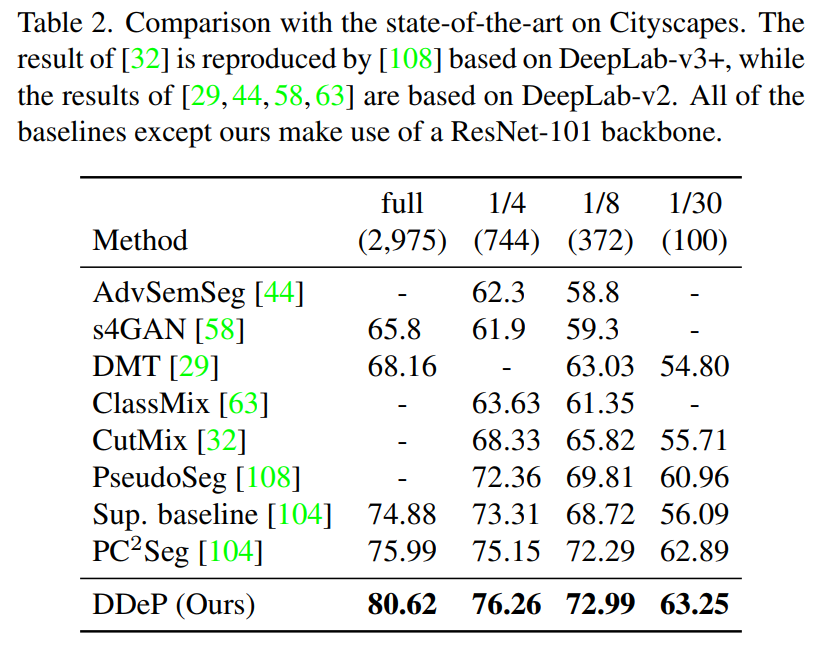 請?zhí)砑訄D片描述
請?zhí)砑訄D片描述
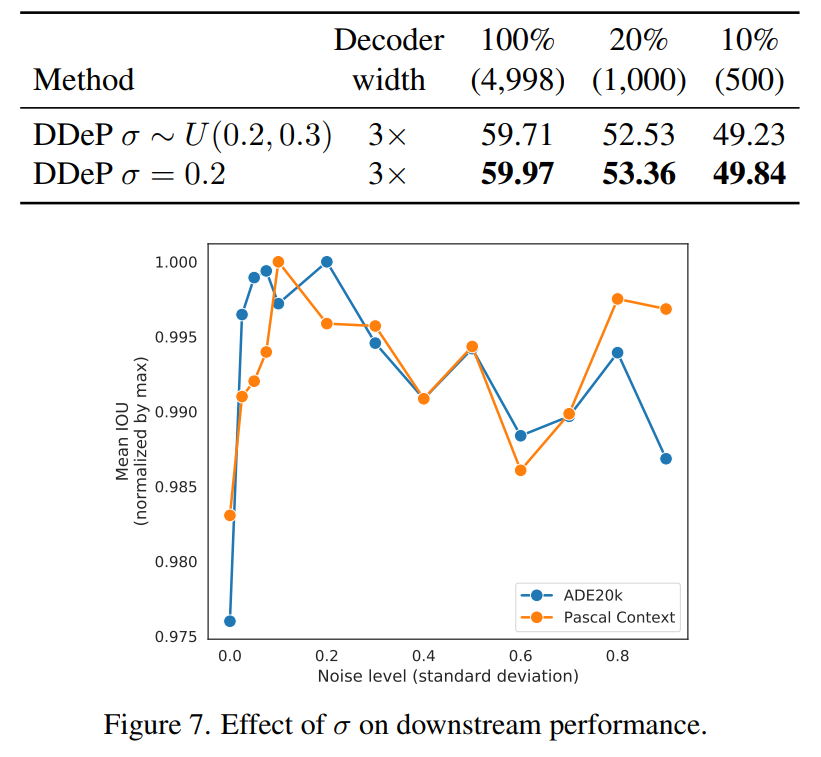
下面比較了在 DeP 模型中調(diào)整 sigma 參數(shù)的兩種不同方法的性能。第二種方法使用固定的 sigma 值,而第一種方法從間隔 [0.2,0.3] 對西格瑪進(jìn)行均勻采樣。此外,折線圖表示固定 sigma 在值為 0.2 左右的區(qū)間效果更好。這部分實(shí)驗(yàn)基于 Pascal Context 和 ADE20K 數(shù)據(jù)集。
 請?zhí)砑訄D片描述
請?zhí)砑訄D片描述
總結(jié)
這篇文章受到 diffusion 的啟發(fā),探索了這些模型在學(xué)習(xí)可轉(zhuǎn)移的語義分割表示方面的有效性。發(fā)現(xiàn)將語義分割模型預(yù)訓(xùn)練為去噪自編碼器可以顯著提高語義分割性能,尤其是在帶標(biāo)記樣本數(shù)量有限的情況下。基于這一發(fā)現(xiàn),提出了一個兩階段的預(yù)訓(xùn)練方法,其中包括監(jiān)督預(yù)訓(xùn)練的編碼器和去噪預(yù)訓(xùn)練的解碼器的組合。在不同大小的數(shù)據(jù)集上都表現(xiàn)出了性能提升,是一種很實(shí)用的預(yù)訓(xùn)練方法。
-
解碼器
+關(guān)注
關(guān)注
9文章
1131瀏覽量
40676 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4306瀏覽量
62430 -
模型
+關(guān)注
關(guān)注
1文章
3172瀏覽量
48714
原文標(biāo)題:用于語義分割的解碼器 diffusion 預(yù)訓(xùn)練方法
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
特征選擇在減少預(yù)測推理時間方面的有效性展示
高斯混合模型對乳腺癌診斷的有效性初探
基于網(wǎng)絡(luò)本體語言O(shè)WL表示模型語義的相似性計(jì)算方法
利用深度學(xué)習(xí)模型實(shí)現(xiàn)監(jiān)督式語義分割
分析總結(jié)基于深度神經(jīng)網(wǎng)絡(luò)的圖像語義分割方法

基于語義耦合相關(guān)的判別式跨模態(tài)哈希特征表示學(xué)習(xí)算法

基于深度神經(jīng)網(wǎng)絡(luò)的圖像語義分割方法

基于SEGNET模型的圖像語義分割方法
語義分割模型 SegNeXt方法概述
普通視覺Transformer(ViT)用于語義分割的能力
圖像語義分割的概念與原理以及常用的方法
深度學(xué)習(xí)圖像語義分割指標(biāo)介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論