 垂直大模型競爭,能突破數據“卡點”嗎?
垂直大模型競爭,能突破數據“卡點”嗎?
AI大模型火遍全球,中國產業也激發了對人工智能應用的新熱情。
隨著各大廠商參與競逐,市場正在分化為通用與垂直兩大路徑,兩者在參數級別、應用場景、商業模式等方面差異已逐步顯現。
企業涌入垂直大模型賽道
通用AI大模型像ChatGPT,能夠處理各種領域和場景的自然語言,但由于需要巨大的計算資源和數據量,已經成為國內外大廠的重點項目。
這類企業往往有著強大的技術團隊和資金支持,且有著自己的場景和流量優勢。比如百度、阿里、騰訊、字節、華為等,在搜索、社交、電商、辦公等領域都有著自己的通用AI大模型。
相較之下,創業公司、細分領域企業很難在這樣的競爭中獲得先發優勢或者差異化優勢。
而垂直AI大模型只關注某個特定的領域或者場景,它能夠利用行業的數據和知識,提供更精準和高效的解決方案,更好地滿足用戶在某個領域或者場景下的需求和期待,如:醫療、金融、教育等。
同時,它可以利用一些開源或者閉源的通用AI大模型作為基礎,然后在其上進行指令微調(instruction tuning),來適應自己的目標領域或者場景。
因此,它的參數規模比通用大模型低一個量級,如果讓數據飛輪和模型訓練能夠很好結合,在某些特定領域甚至比通用大模型的效果更好、成本更低。
在這樣的背景下,越來越多的企業加入了垂直大模型的賽道。
5月18日,深信服發布國內首個自研安全大模型,成為安全領域GPT技術應用首秀;
5月5日,學而思宣布正在進行自研數學大模型的研發,命名為MathGPT,面向全球數學愛好者和科研機構;
3月,達觀數據公布正在開發曹植系統,專注于金融、政務、制造等垂直領域的大語言模型。
明確的商業化落地場景和更低的算力成本,為各類企業打開了進軍垂直大模型的大門。
垂直大模型的考驗
垂直大模型的優勢在于不夠大:算力不夠大、算法難度低,但并不代表垂直大模型誰都能做。
眾所周知,AI大模型三要素:算力、算法、數據,都是喂養AI的“飼料”。
先說算力。
大模型之所以“大”,就是因為參數眾多和數據量龐大。AI大模型所需要的計算量,大致上相當于參數量與數據量的乘積。
過去5年,AI大模型的參數量幾乎每年提升一個數量級,例如GPT-4參數量是GPT-3的16倍,達到1.6萬億個。
隨著圖像、音視頻等多模態數據的引入,大模型的數據量也在飛速膨脹。這意味著想要玩轉大模型,必須擁有大算力。
而一套垂直大模型的訓練和推理成本,做個參考,在數字人垂類技術場景中,可以做到比Open AI同參數規模的模型低一個量級,像啟元世界的戰略總監王思捷就曾提到:先構建更小的垂類模型(比如百億參數、十億參數),讓數據飛輪和模型訓練能夠很好結合,垂類模型在某些領域可能比Open AI的效果更好成本更低。
即便垂直大模型在算力要求上已遠遠低于通用大模型,但對算力基礎設施的投入依然會阻擋部分小公司的入局。
再說算法。
在三要素中,算法的研發難度相對較低,每家公司都有自己實現大模型的路徑算法,且有眾多開源項目可作為參考,中國公司最容易縮短甚至抹平差距。
最后說數據。
高質量的數據是助力AI訓練與調優的關鍵,足夠多、足夠豐富的數據,是AI大模型的根基。
OpenAI此前披露,為了AI像人類那樣流暢交談,研發人員給GPT-3.5提供多達45TB的文本語料,相當于472萬套中國“四大名著”。這些語料的來源包括維基百科、網絡文章、書籍期刊等,甚至還將代碼開源平臺Github納入其中。
但是聚焦到細分行業,數據的獲取就沒那么容易了。
興業證券公開表示,要訓練專業的行業大模型,優質的行業數據、公共數據至關重要。
就國內數據市場而言,據發改委官方批露,我國政府數據資源占全國數據資源的比重超過3/4,但開放規模不足美國的10%,個人和企業可以利用的規模更是不及美國的7%。
而行業數據更是非常核心的私域數據,私域數據量越大,質量越高,就越有價值。
比如,一個醫療公司擁有大量醫療數據、病例數據,那么它就能開發出醫療垂直大模型類的產品。同理,建筑行業的項目數據、金融行業的用戶畫像數據、海運行業的船位數據等,都是賦能垂直大模型的關鍵。
但是這些私域數據都攥在企業自己手中,而且為了數據安全和合規,絕大部分機構是要本地化部署才會嘗試大模型訓練,很難想象企業會把自己的核心數據拿給別人去訓練。
此外,如何合理地給數據打上分級標簽、做好標注也非常重要。數據分級分類能夠幫助產品提效,而高精度的標注數據能夠進一步提升大模型的專業表現。
但現階段垂直行業想要獲取高精度標注數據的成本較高,而在公開數據庫中,行業專業數據也較少,因此對垂直大模型的建構提出了很高的要求。
總體而言,想要做好垂直大模型,數據的重要性,遠超過算力和算法。
數據,已成為企業突破垂直大模型的“卡點”。
手握行業數據領先一步
垂類大模型講求應用與場景先行的邏輯,而在國內更是強調產業側的價值。
一方面,在當前中國的智能化浪潮下,產業側數字化革新本就有廣闊的市場需求;另一方面,在toB生態下,基于垂直應用的實踐也有利于形成數據飛輪與場景飛輪。
而這一切的前提,是推出垂類大模型的公司在該行業已建立技術壁壘與護城河,即“人無我有”的競爭優勢。
如此看來,在垂直行業深耕多年的企業或將有更大的贏面。
這類企業在數據層面、大模型以及知識圖譜方面都有較為深厚的積累,對于大模型的優化更具優勢。同時,它們對于to B客戶需求和落地場景有很深的理解,能夠更好地保證垂直大模型產品的可信和可靠,滿足企業級對于安全可控合規的需求。
目前,已有一些垂類大模型在金融、教育、醫藥、營銷等場景中得到試煉。
例如,彭博社利用自身豐富的金融數據源,基于開源的GPT-3框架再訓練,開發出了金融專屬大模型BloombergGPT;
網易有道則面向教育場景,推出自研的類ChatGPT模型“子曰”;
在ChatGPT發布后僅幾周,谷歌公布了一個專門用于回答醫療保健相關問題的大型醫用語言模型Med-PaLM......
相信隨著越來越多企業入局,垂直大模型在各個行業和細分領域中將大量涌現。而那些能將一個垂直領域做專、做透,用高質量的數據持續優化模型,跑通商業閉環,構建起產業生態的企業,最終將把價值鏈做到足夠長。
【關于科技云報道】
專注于原創的企業級內容行家——科技云報道。成立于2015年,是前沿企業級IT領域Top10媒體。獲工信部權威認可,可信云、全球云計算大會官方指定傳播媒體之一。深入原創報道云計算、大數據、人工智能、區塊鏈等領域。
-
數據
+關注
關注
8文章
6909瀏覽量
88849 -
AI
+關注
關注
87文章
30239瀏覽量
268479 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507 -
大模型
+關注
關注
2文章
2339瀏覽量
2500
發布評論請先 登錄
相關推薦
中國電信人工智能研究院完成首個全國產化萬卡萬參大模型訓練
萬卡集群解決大模型訓算力需求,建設面臨哪些挑戰

【大規模語言模型:從理論到實踐】- 每日進步一點點
澳鵬入選億歐大模型基礎層圖譜,以優質數據賦能AGI智能涌現

NAND Flash(貼片式TF卡)存儲新突破,基礎示例
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
泰來三維|三維掃描點云數據怎么處理如何建模
安筱鵬:AI大模型重構產業競爭力的五種模式

名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
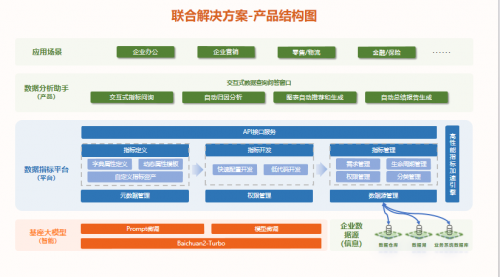
數勢聯動百川,發布首批大模型聯合解決方案,推動中國大模型價值落地
如何基于深度學習模型訓練實現工件切割點位置預測






 工商網監
工商網監
評論