 LLM性能的主要因素
LLM性能的主要因素
現在是2023年5月,截止目前,網絡上已經開源了眾多的LLM,如何用較低的成本,判斷LLM的基礎性能,選到適合自己任務的LLM,成為一個關鍵。
本文會涉及以下幾個問題:
影響LLM性能的主要因素
目前主要的模型的參數
LLaMA系列是否需要擴中文詞表
不同任務的模型選擇
影響LLM性能的主要因素
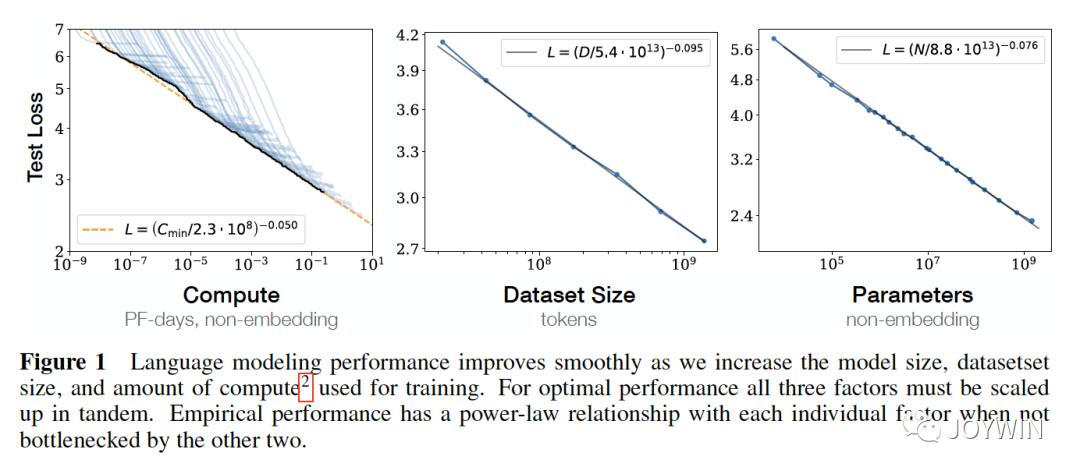
Scaling Laws for Neural Language Models
OpenAI的論文Scaling Laws中列舉了影響模型性能最大的三個因素:計算量、數據集大小、模型參數量。也就是說,當其他因素不成為瓶頸時,計算量、數據集大小、模型參數量這3個因素中的單個因素指數增加時,loss會線性的下降。同時,DeepMind的研究也得出來和OpenAI類似的結論。那么我們可以基本確定,如果一個模型在這3個方面,均做的不錯,那么將會是一個很好的備選。
模型參數量是我們最容易注意到的,一般而言,LLM也只在訓練數據上訓練1個epoch(如果還有算力,其實可以擴更多的新數據),那么,數據集的大小就是很關鍵的參數。訓練OPT-175B的Susan Zhang在Stanford分享的時候,也提到了,如果能夠重新再來一次,她會選擇much much more data。可見數據量的重要性。
了解到Scaling Laws之后,為了降低模型的推理成本,可以在模型參數量降低的同時,增加訓練的數據量,這樣可以保證模型的效果。Chinchilla和LLaMA就是這樣的思路。
除了以上的因素之外,還有一個比較大的影響因素就是數據質量。
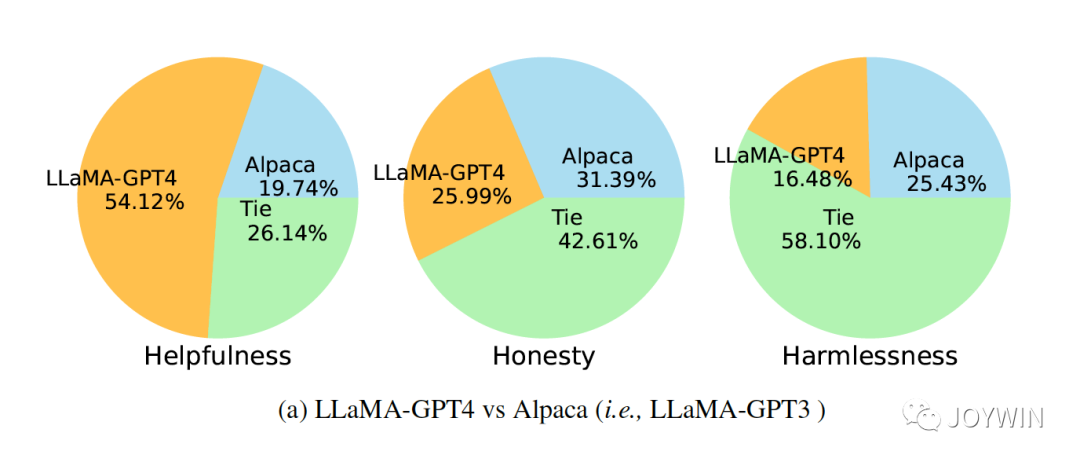
Instruction Tuning with GPT-4
在微軟的論文中指出,同樣基于LLaMA模型,使用GPT3和GPT4產生的數據,對模型進行Instruction Turing,可以看到GPT4的數據微調過的模型效果遠遠好于GPT3數據微調的模型,可見數據質量帶來的影響。同樣的,Vicuna的Instruction Turing中,也對shareGPT的數據做了很細致的清洗工作。
所以,如果沒有數量級的差異,在Instruction Turing的時候,可以盡可能拋棄質量差的數據,保留高質量的數據。
目前主要的模型的參數
| 訓練數據量 | 參數 | |
|---|---|---|
| LLaMA | 1T~1.4T tokens | 7B~65B |
| chatGLM-6B | 1T tokens | 6B |
根據我們上面的推理,訓練數據量是對模型影響最關鍵的因素。LLaMA和chatGLM-6B是目前效果相對比較好的LLM,他們的訓練數據都達到了至少1T tokens。那么如果一個LLM的訓練數據量,少于1T tokens數的話,這個模型可以不用考慮了。
而LLaMA的參數量可以有7B、13B、33B、65B可以選擇,那么在參數量上和可選擇性上,比chatGLM要更優秀。那么,基于這些考慮,LLaMA系列及其變種,是當前更好的選擇。而且,經過Instruction Turing之后,Vicuna已經表現出了非常好的性能,根據微軟的論文(不是伯克利自己的論文),Vicuna已經達到90%的GPT4的效果。這一點和伯克利自己的結論也吻合。
在Vicuna的作者的博客中,作者也提到了vicuna-13B會比vicuna-7B效果好很多。筆者自己微調過這兩個模型,13B確實會比7B的準確率高出5-10%。
同時,int8量化的Vicuna-13B在推理時,只需要20GB的顯存,可以放進很多消費級的顯卡中。
這么看起來,Vicuna-13B確實是一個很強的baseline,目前看到的開源LLM,只有WizardVicunaLM 的效果更優于Vicuna-13B。如果你沒有很多時間調研,那么vicuna-13B會是一個不錯的備選。
LLaMA系列是否需要擴中文詞表
關于LLaMA的一個爭論就是,LLaMA的base model是在以英語為主要語言的拉丁語系上進行訓練的,中文效果會不會比較差?還有就是,LLaMA詞表中的中文token比較少,需不需要擴詞表?
針對問題一,微軟的論文中已經驗證了,經過Instruction Turing的Vicuna-13B已經有非常好的中文能力。
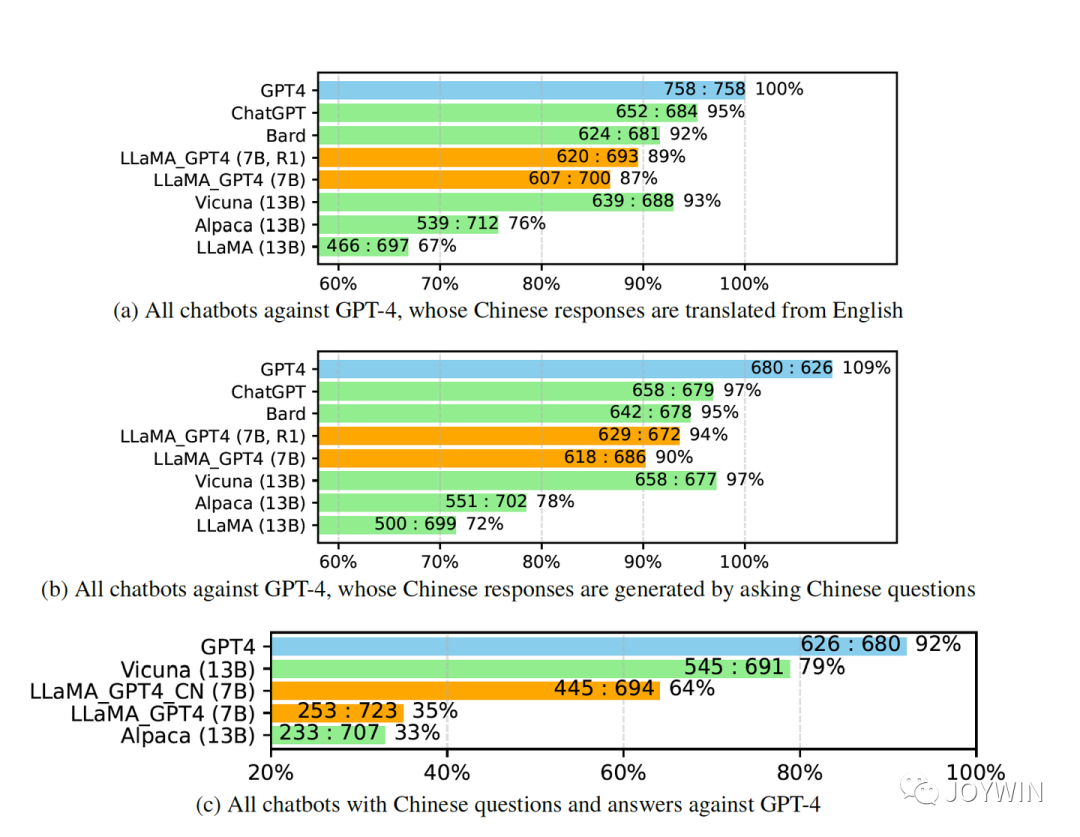
Instruction Tuning with GPT-4
那為什么沒有在很多中文語料上訓練過的LLaMA,能有這么好的中文能力呢?首先,在GPT4的技術報告中提到,即使在數據量很少的語言上,GPT4也有非常好的性能。
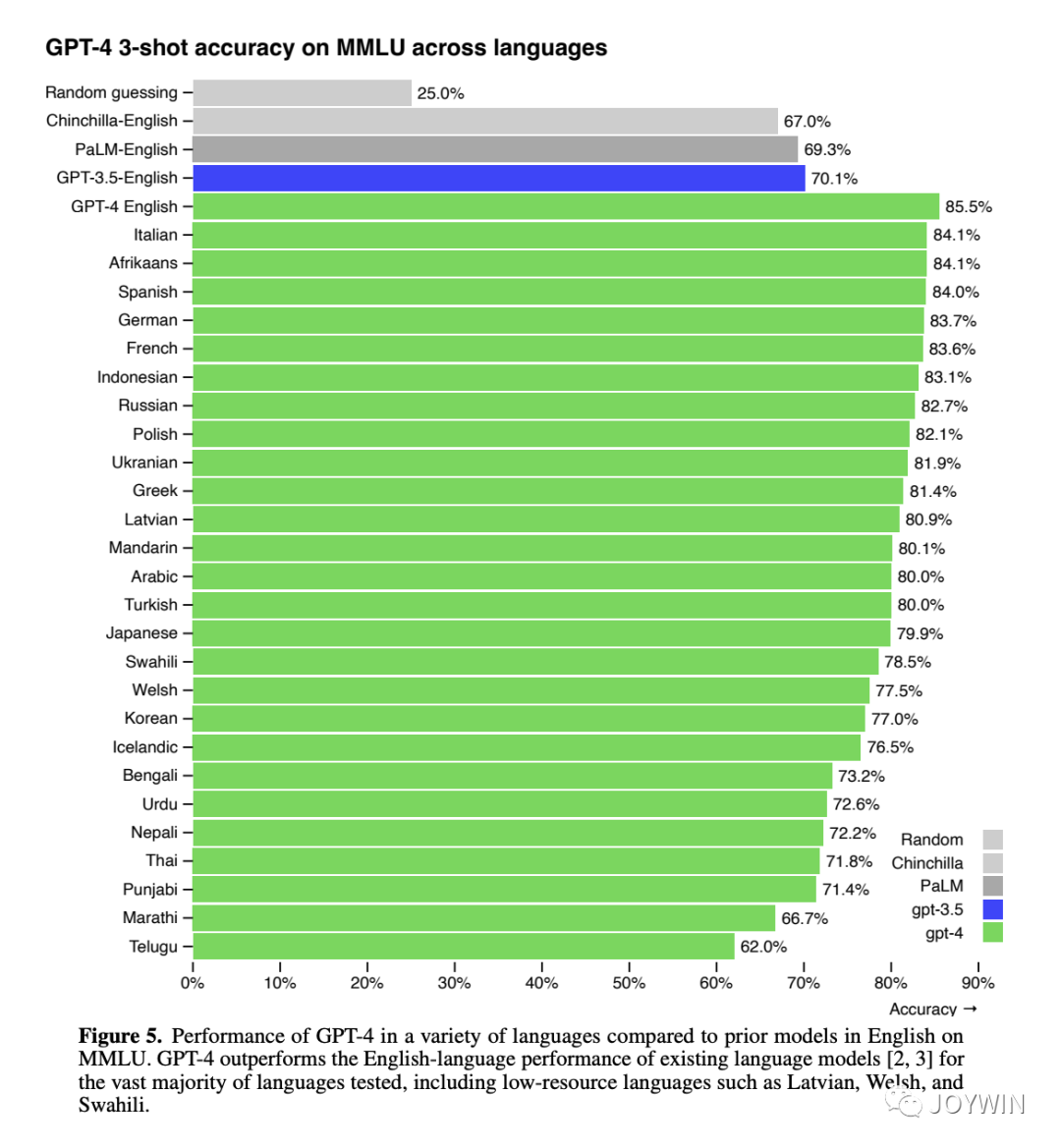
LLM表現出了驚人的跨語言能力。我猜其中一個比較重要的原始是采用了byte-level BPE算法構建詞表。這種BBPE算法,將很多字符都拆分到byte級別。比如,雖然詞表中沒有對應的中文字符,但是可以通過組合byte,構建出來原始的中文字符。這部分可以參考文章Dylan:[分析] 淺談ChatGPT的Tokenizer。因此,經過超大規模的語料訓練之后,LLM可以跨不同的語言,表現出很好的性能。
采用BBPE的好處是可以跨語言共用詞表,顯著壓縮詞表的大小。而壞處就是,對于類似中文這樣的語言,一段文字的序列長度會顯著增長。因此,很多人會想到擴中文詞表。但考慮到擴詞表,相當于從頭初始化開始訓練這些參數。因此,參考第一節的結論,如果想達到比較好的性能,需要比較大的算力和數據量。如果沒有很多數據和算力,就不太建議這么搞。
根據開源項目Chinese-LLaMA-Alpaca公布的數據,他們在使用120G的中文語料后(下圖中的Alpaca-Plus-7B和Alpaca-Plus-13B),效果才有不錯的提升,而在使用20G語料時(下圖中的Alpaca-13B),效果還相對比較差。作為對比,原始的LLaMA使用的數據量大概是4T左右(此處是存儲空間,不是token數)。
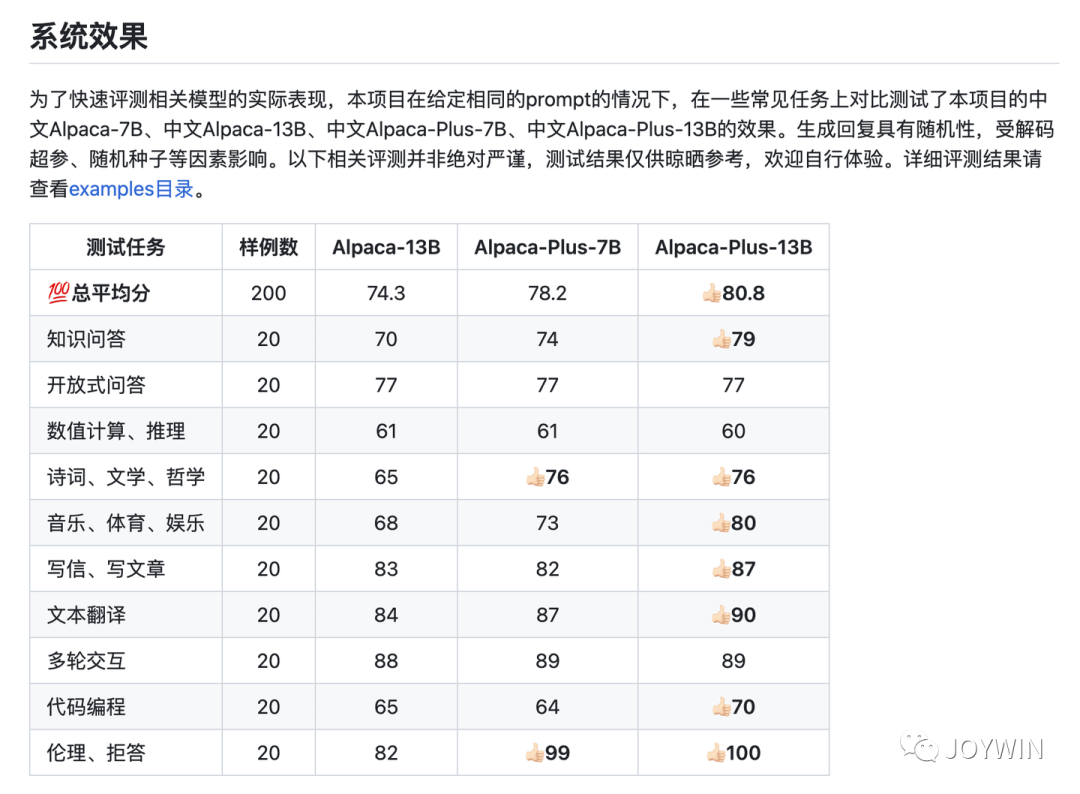
Chinese-LLaMA-Alpaca
因此,雖然擴詞表看起來很誘人,但是實際操作起來,還是很有難度的,不過如果你有很多數據和算力,這個當我沒說(不是)。
不同任務的模型選擇
上文還提到,LLaMA系列的一大優勢是,有很多不同大小的模型,從7B-65B。上面我們主要討論了13B的模型,還有33B和65B的模型沒有討論。那什么場景下,13B的模型也不夠,需要更大的模型呢?
答案就是,只要你的算力可以支持,就建議上更大的模型。
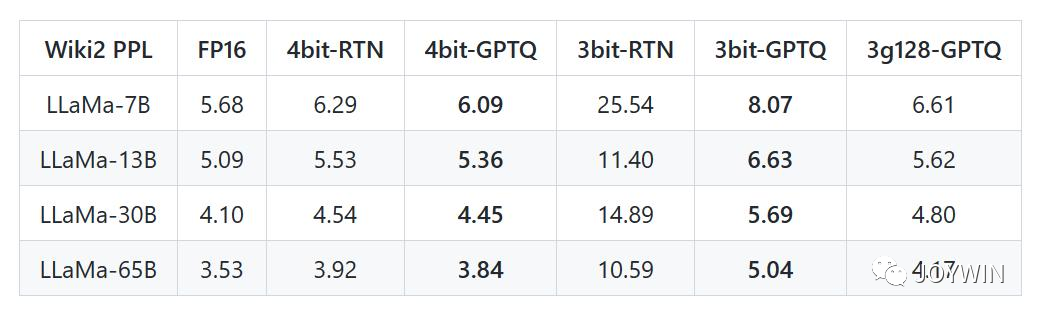
GPTQ-for-LLaMa
根據GPTQ-for-LLaMa 的數據,可以看到隨著模型的增大,模型在wiki2數據上的困惑度一直在下降。更重要的是,LLaMA-33B經過int4量化之后,PPL低于LLaMA-13B!LLaMA-65B經過int4量化之后,PPL低于LLaMA-33B!并且,LLaMA-33B經過int4量化之后,推理只需要20GB的顯存!!!
看到這個數據,我著實有點小激動。然后立馬開始著手微調33B的模型!!!
當然,從推理成本的角度來看,模型參數量越小,成本越低。那什么情況下可以用小模型呢?回答是,需要根據任務的難易程度選擇模型大小,如果任務很簡單,其實小模型就OK。比如處理一些比較簡單的中文任務,chatGLM-6B將會更合適。中文詞表,再加上推理更好的優化,可以極大降低推理成本。
但如果任務很難,對于語義的理解程度很高,那么肯定是模型越大效果越好。有什么任務是比較難的任務呢?我們來看看什么任務讓GPT4的覺得比較困難。
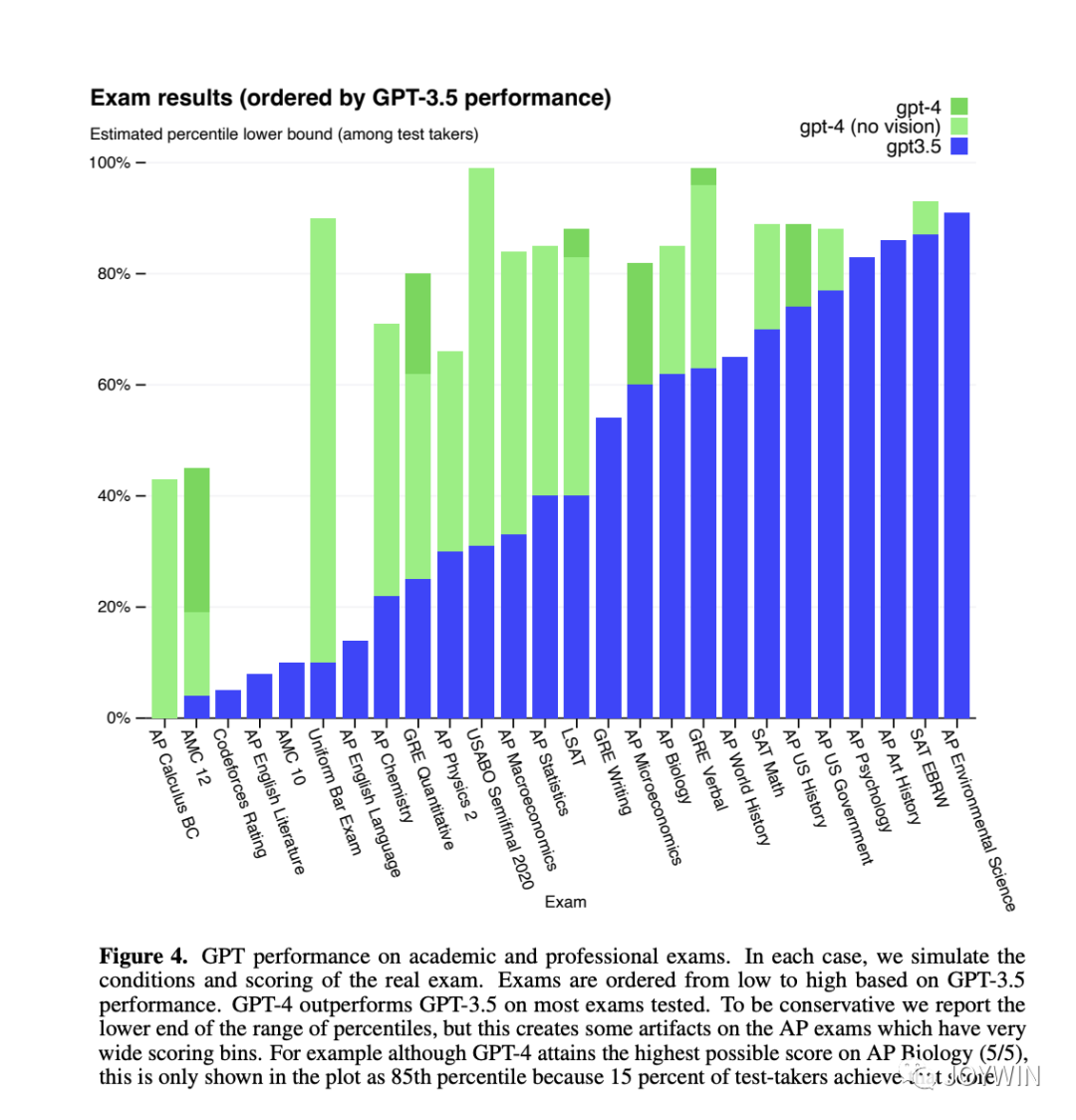
GPT-4 Technical Report
可以看到,GPT4表現最差的幾個項目分別是Codeforces Rating、AP English Literature、AMC 10和AP English Language(AP是Advanced Placement,美國大學先修課程)。其中有兩個分別是代碼測試和數學測試,語言模型(LM)表現比較差符合預期。但是作為地表最強語言模型,在English Literature和English Language的考試中,這樣的表現,是讓人有點意外的。不過,話說回來,OpenAI對于GPT4的定位,還是一個工具型助手,而不是一個寫文學性文字的模型。RLHF的作用,也是讓模型,盡可能符合人對它的instruction。
因此,如果你的任務是,讓LLM去寫偏文學性的文章,應該要注意兩個方面:1、任務本身有難度,盡可能上能力范圍內的參數量更大的模型;2、數據層面,不要使用Instruction Turing的數據 ,而需要自己去找合適的高質量數據集。
-
模型
+關注
關注
1文章
3178瀏覽量
48729 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
GPT
+關注
關注
0文章
352瀏覽量
15315 -
LLM
+關注
關注
0文章
276瀏覽量
306
原文標題:大模型選型的一點思考
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
決定仿真精度的主要因素
影響步進電機性能的主要因素有哪些?
影響電機結構的主要因素有哪些
影響光纖跳線管理的4種主要因素





 工商網監
工商網監
評論