 海量視頻處理的應對和算法實踐
海量視頻處理的應對和算法實踐
隨著短視頻、直播、智慧城市、5G等的快速發展,視頻內容鋪天蓋地,五花八門,相應的處理需求也多種多樣。如何能高效地應對?需要在數據處理系統,底層計算能力,以及算法研究等多方面協同努力。LiveVideoStackCon 2022 北京站邀請到沐曦AI解決方案總監——虞新陽,為大家梳理視頻處理的需求及介紹沐曦應對視頻處理場景的GPU產品等。
大家好,我是虞新陽,早期主要從事GPU架構研發相關工作,包括視頻架構以及computer架構,曾在國際旗艦廠商主導設計硬件解碼器的架構設計和研發。對compute更上層的應用感興趣后加入互聯網公司,曾負責阿里巴巴智能家裝設計整體解決方案。2021年加入沐曦,一家提供GPU芯片及計算解決方案的算力公司,負責AI算法方向的解決方案。本次分享的主題是《海量視頻處理的應對和算法實踐》。

為什么要研究視頻的處理?
首先,人最基本的屬性包括視覺、聽覺、嗅覺、味覺、觸覺等,其中的視覺和聽覺是主要的信息接收和溝通管道。從人的基本屬性可以看出,音視頻永遠不會過時,不管是在當前飛速發展的現實社會還是在今后的元宇宙場景中。
其次,第三方數據對視頻的重要性也有總結。2021年,互聯網消耗的數據流量主要集中在視頻,占比大概是75%。一年后占比還在持續增加,由于短視頻、直播等各種更貼近人類視聽屬性的應用的爆發,客戶端的占比達到82%,移動端達到79%。可以想象,視頻內容的占比還會持續增加。
為什么我們要特別關注這個問題呢?因為計算需要感知上層應用,或者說一個應用只有充分利用了算力才能夠跑得快,而算力只有深刻分析理解應用,并不斷進行迭代優化,才能設計出更好的算力。兩方相互結合能更好地提升整體系統性能。

本次分享主要包括四部分:
1、視頻處理需求理解
2、系統解決方案
3、視頻處理算法實踐
4、后續工作
-01-
視頻處理需求理解

圖中數據來自Bitmovin2021年的視頻發展報告,它本身的調研數據來自于包括65個國家,大中小企業的工程、算法以及市場從業者等,覆蓋面非常廣。
挑戰方面,主要包括直播低延時、成本控制(最主要是帶寬流量)、各種設備可播放(筆記本、pad、手機)、精控分析、插廣告等。
趨勢方面,標黃部分特別重要:第一點,原來H.264是絕對的主流,但在2021年開始出現了首次下降(91%->83%),而專利費較高的H265提升卻較明顯(42%->49%),我理解是因為帶寬的成本太高,比起額外的專利費,大家更需要降低帶寬成本。第二點,無論是國外的亞馬遜、國內的阿里、騰訊等,它們的云服務都在持續發展,編碼采用云服務的比例持續提升。第三點是基于內容的編碼,也就是智能視頻編碼,比例提升到了35%。
其它期待AI賦能的場景包括ASR、視頻分析、打標簽、視頻質量的優化等。
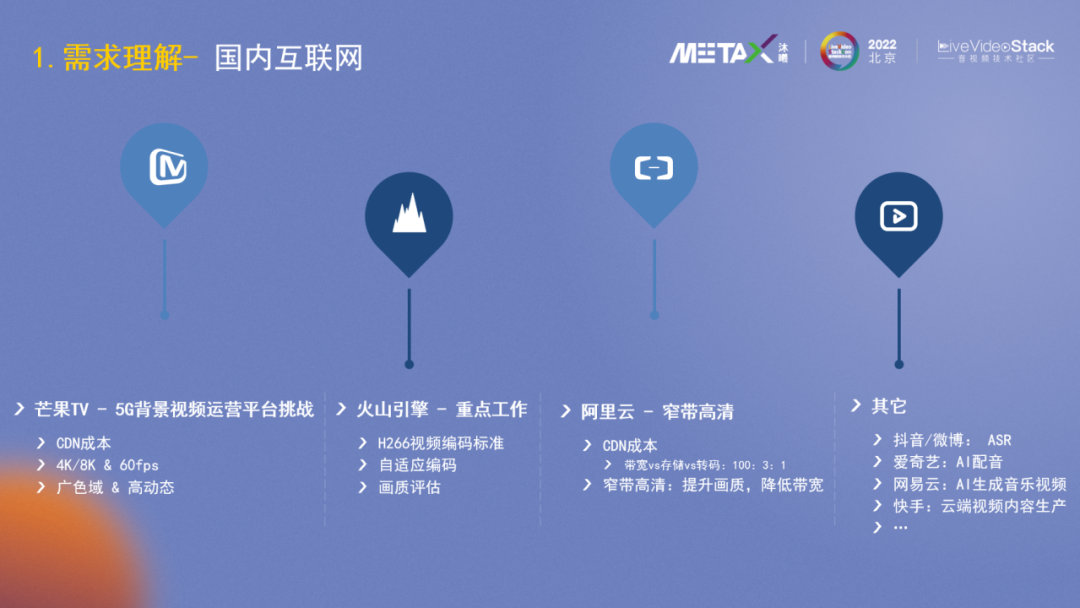
接下來也簡要介紹下國內互聯網的情況(來源于過往的公開分享):
芒果TV,既是視頻內容生產商,同時也是運營商,他們分享了5G背景下視頻運營平臺的挑戰,包括CDN成本,4K/8K&60fps的應對等。
火山引擎,他們重點投入了新一代的編碼器H266,并研發自適應編碼、畫質評價(感知短視頻質量并確定推薦權重)等。
阿里云有一個產品叫窄帶高清(降低帶寬提升畫質)。它具象地總結CDN成本占比,從他示例的視頻云廠商來說,帶寬:存儲:轉碼的成本占比是100:3:1,應該遠超出了很多人的感知。
抖音和微博在研發ASR技術來自動生成字幕,愛奇藝、網易云的工作重點是AI配音、AI生成音樂視頻等。

最后來看看工業界的需求,主要包括智能安防、智慧交通、智能制造等。
國內的智能安防很發達,處理場景包括邊緣端、服務器端等,對采集的海量視頻的基本處理包括編解碼、結構化分析及比對等。
智能交通包括路邊停車識別、車路協同,以及汽車自動駕駛等,視頻解碼和結構化處理是這些功能最底層的要素。
智能制造主要是工業機器人,包括家電等的生產制造。最重要的場景是檢測分類,也有定位、測量等工作。
梳理后可以發現,大方向還是視頻編解碼+AI,雖然后處理略有不同,有的偏結構化存儲,有的偏檢索分析,有的偏定位控制等。
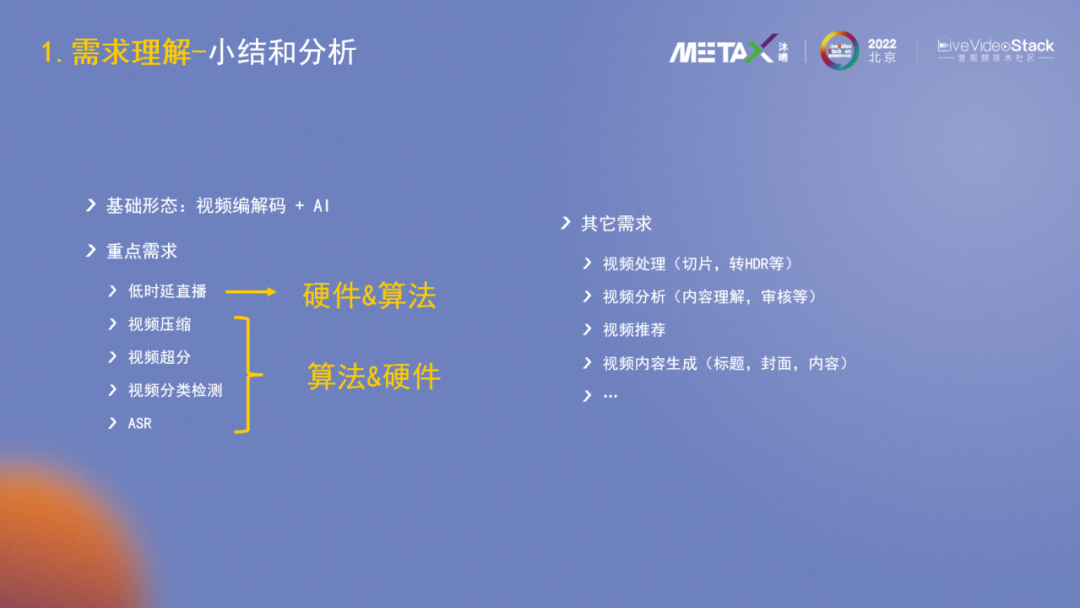
從前面的3個維度可以發現,海量音視頻處理的基本形態是視頻編解碼+AI,重點需求是低時延、視頻壓縮、視頻超分、視頻分類檢測及ASR,其他需求還包括視頻處理(切片、轉HDR等)、視頻分析、視頻推薦等。
重點需求中的低時延直播,主要在硬件層進行解決;而壓縮、超分等需求算法側可以發揮很大作用。
-02-
系統解決方案
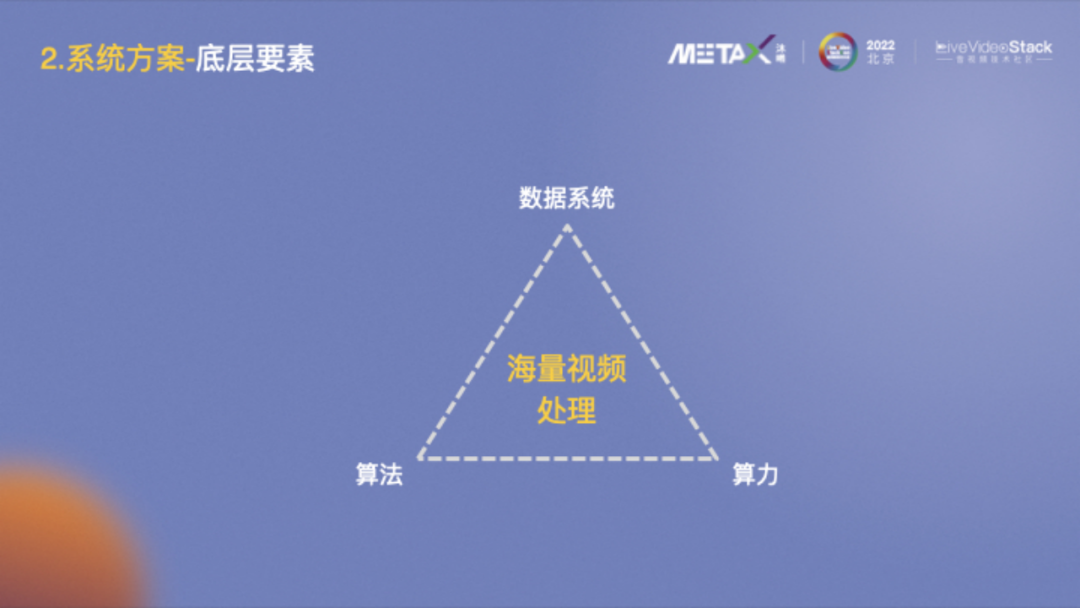
大家對這張圖應該不陌生,AI最基本的三要素包括算法、算力和數據。平移到海量視頻數據的處理,需要一個高效的數據系統做支撐,其中算力提供底層基礎能力,算法協助數據系統更加智能高效。接下來主要介紹下算力和算法方面。

海量視頻處理對算力側的需求包括強編解碼能力、強AI推理能力和高性價比。

這里介紹下沐曦的曦思N100產品。根據上述需求,我們針對性地設計了這款產品,它具備很強的編解碼能力,解碼支持96x1080p@30fps,標準包括H264/H265/AV1/AVS2,支持8K;編碼更強,能支持128x1080@30fps,標準包括H264/H265/AV1,支持8K。此外,它還具備很強的AI推理能力,上文提到很多場景同時需要編解碼能力和AI能力,它的AI算力達到160TOPS int8, 80TFLOPS FP16/BF16,此外它也有很好的帶寬能力,相關的軟件棧、開發工具、虛擬化等配套能力也很齊備。
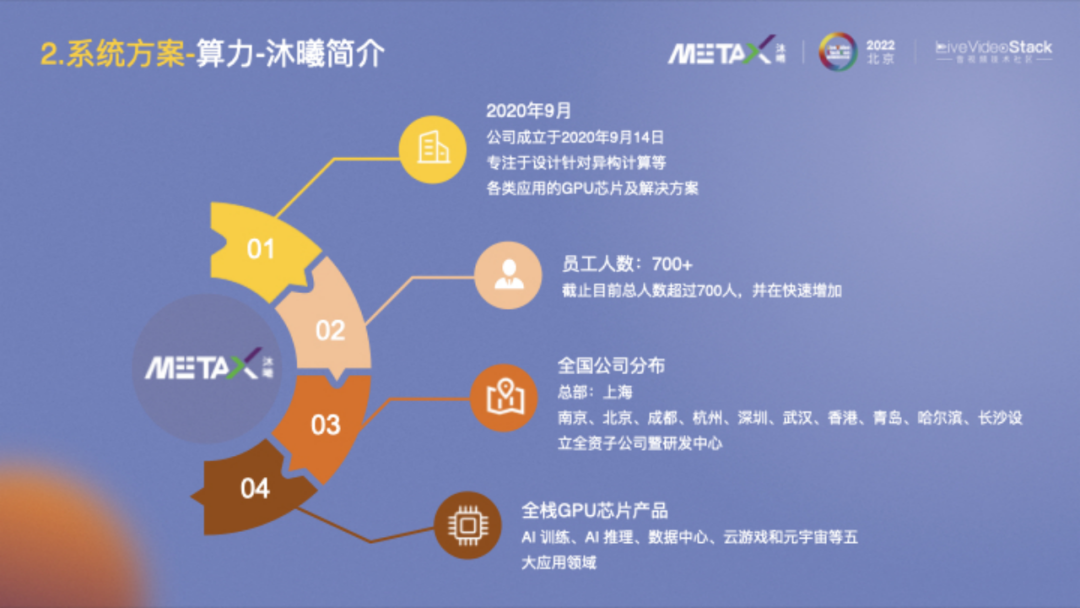
也簡要介紹一下沐曦,它成立于2020年9月,專注于設計針對異構計算等各類應用的GPU芯片及解決方案。公司發展速度很快,有80%以上的員工是碩士及以上學歷,70%以上的員工平均工齡超過10年。沐曦基本每年會推出一款產品進行持續迭代。
-03-
視頻處理算法實踐

針對算法實踐,接下來重點介紹下我們在視頻壓縮、視頻超分和ASR上的一些工作。
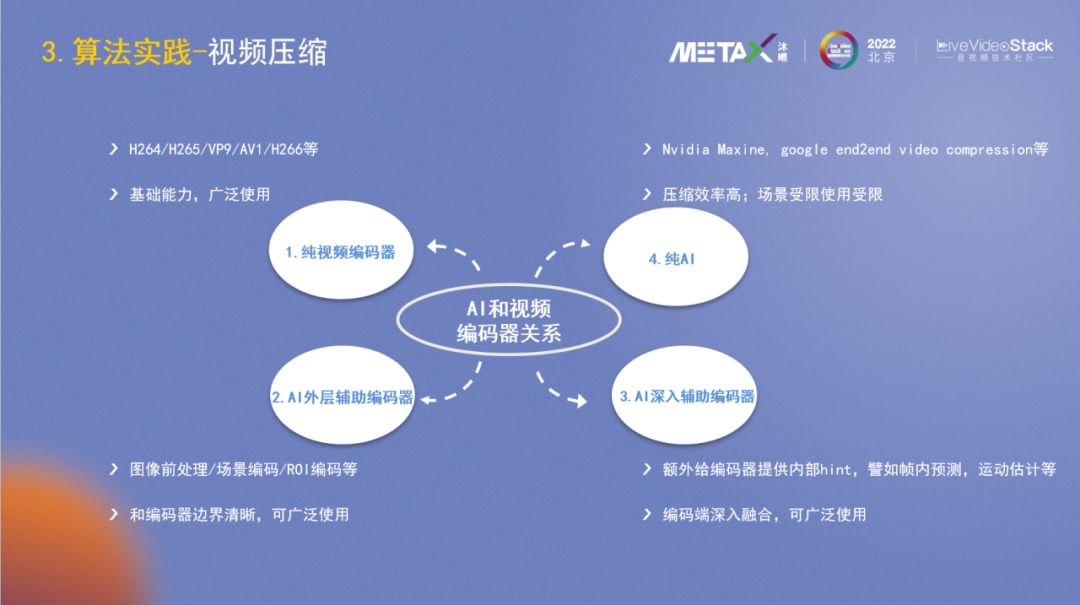
根據AI和編解碼的關系,視頻壓縮解決方案主要可分為四種:
1、純視頻編解碼:也是當前最普遍最基礎的形式,采用標準的視頻標準如H264等。
2、AI外層輔助編碼:AI和標準編碼器有清晰的邊界,依托FFmpeg框架等,主要在幀級別進行數據的交互控制,編出來的碼流符合標準。
3、AI深入輔助編碼:AI算法參與編碼的深層次控制,為編碼器提供各種hint,譬如幀內預測、運動估計等,需要在編碼器內部做相關的能力和接口實現。
4、純AI編碼:是未來的發展趨勢,拋棄了H.264/H.265等基于預測變換之類工具的編碼思路,而是用AI網絡進行編解碼,英偉達和Google等都有發布相關的工作。當前比較適用的場景是會議系統,無需重復傳輸背景,只需傳輸人臉關鍵點信息等即可較好恢復畫面,編解碼端也可控。新一代的編解碼標準(VCM, DCM)也有在往這個方向努力。
接下來分析下以上四種編碼方案的應用場景:純視頻編碼器,在任何場景都適用,無論是手機、電腦還是pad等等,因為編解碼器支持已官方內嵌在各種芯片和解決方案中。AI外層輔助編碼器,AI在外層輔助,和編解碼的邊界很清晰,編出的碼流符合規范,各種已有設備也都能播放。AI深入輔助編碼器,碼流符合標準,可以廣泛使用,但需要算法和編碼器底層深入協同,公司之間在這個層面合作的可能性較小,且不太適用于硬件編碼器方案。純AI,個人認為在10年之內不會廣泛使用,一方面因為算力和標準,它需要各種設備都具備不錯的AI算力,然后編解碼端需要有大家都認同的標準協議;另外一方面在標準統一后,大規模采用也需要好幾年的時間(參考H264/H265等的普及)。
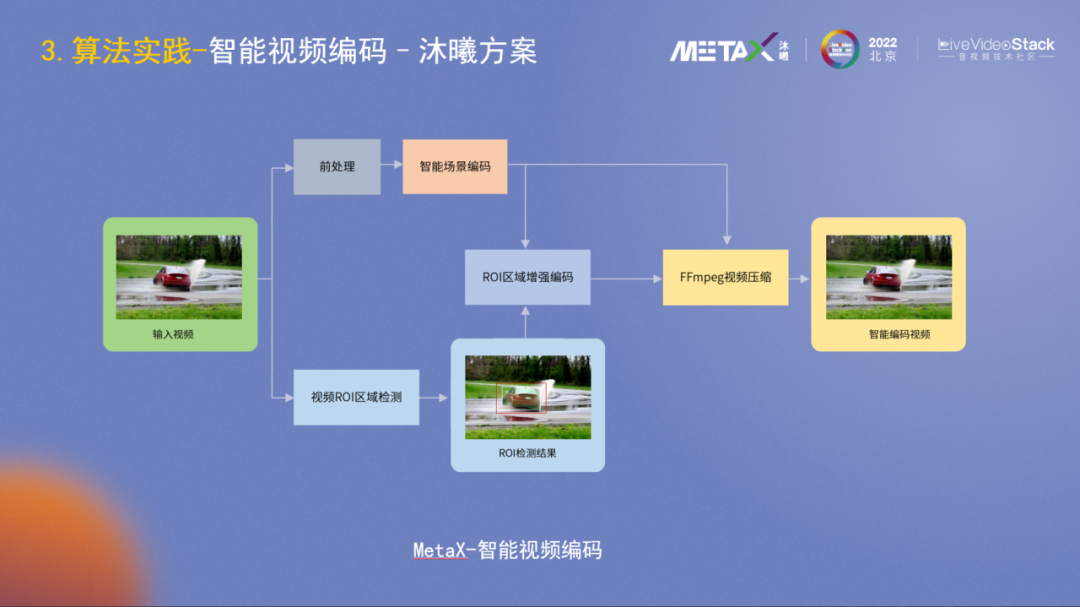
沐曦的智能視頻編碼方案是AI外層輔助編碼,整體框圖如圖所示。視頻輸入后分為兩路,先進行前處理、場景編碼和ROI區域檢測,然后再合并進行ROI區域增強編碼決策,最后用通用的接口調用FFmpeg框架進行視頻壓縮。
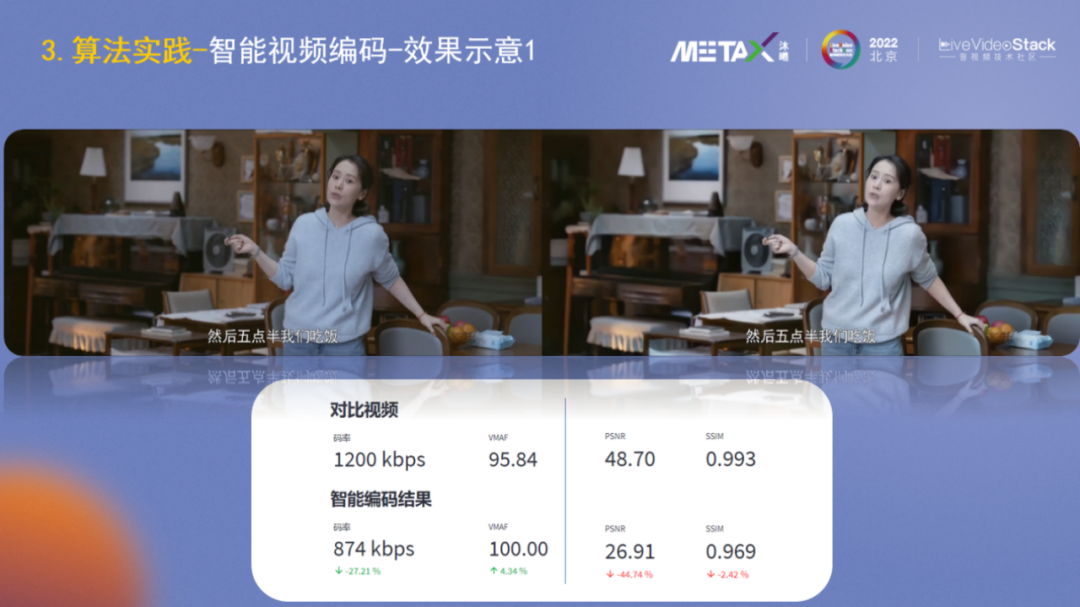
在具體介紹各模塊之前,大家先看下智能視頻編碼前后的效果對比。左側是H.264默認編碼,經過智能編碼后,碼率下降了27%,主觀質量VMAF還有所提高,但PSNR、SSIM有明顯下降。
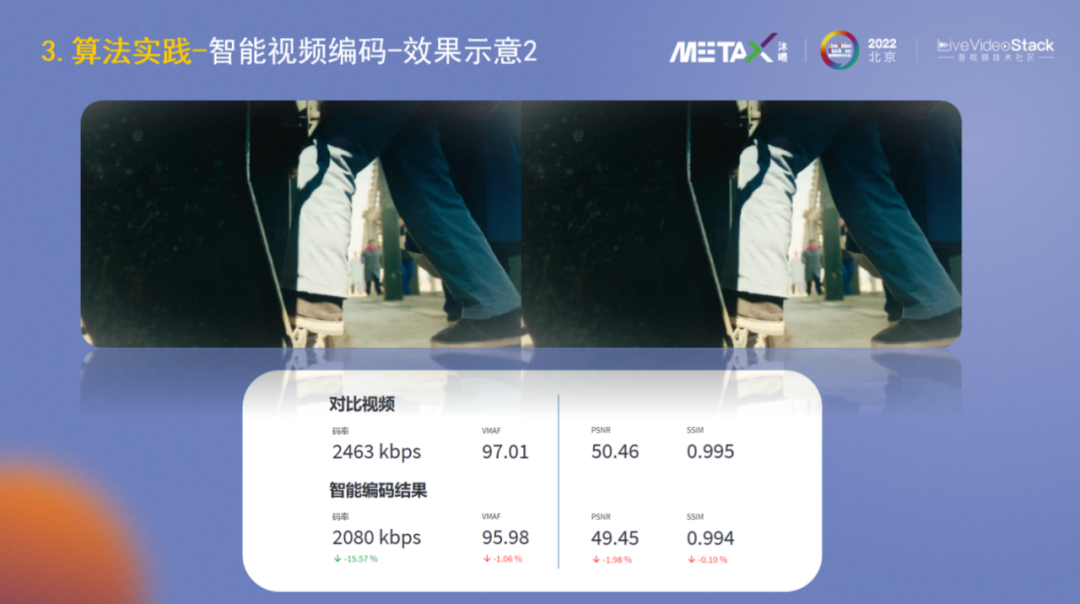
在效果示意2中,視頻碼率下降了15%,VMAF略有下降,PSNR和SSIM改變也很小,因為視頻沒有經過前處理。

前處理的底層原理,是人眼視覺系統有一些基礎屬性,主要包括:對邊緣輪廓信息敏感,對運動敏感,對對比度敏感,對高頻信息(白噪聲、小雪花)不敏感,亮度感受強于色度等。
對原始圖片做了修改后差距會變得更大?實際上,壓縮總體上是降低質量、模糊圖片的過程,前處理階段會把重要信息先提升起來,再通過H.264/H.265壓縮時又降低下去,加減相抵。總體過程使得處理前后的VMAF差距不大,但PSNR降低會較明顯。

針對前處理,我們主要做了以下兩方面的工作:退化質量修復和主觀質量增強。
退化質量修復:視頻內容的編碼效果不理想,很多時候是輸入時的質量就不高,普遍存在的一個質量問題是重復壓縮。比如上傳一張圖片到微信,默認它會進行二次壓縮,如果再經過其它應用或手機可能又會壓縮一遍,整體畫質就會逐步下降。其次是噪聲,大部分噪點是拍攝采集端數字化時引入的,另外在傳輸保存過程中也可能會引入噪聲。噪聲對編碼器很不友好,因為沒有規律會引起預測后的編碼殘差較大,浪費挺多的碼流。
主觀質量增強:人是視覺動物,導演拍攝時會進行場景布置,補光及后期制作,各種設備包括手機等持續優化甚至美化圖片,都是為了讓拍出來的東西讓人感受更好,所以從某種角度看來,并不是要一模一樣的真實才有意義。對主觀質量的增強,我們主要處理了邊緣增強和SDR2SDR+。
下圖示例了去失真修復,細節增強以及SDR2SDR+等的效果,對比左側的原始圖片可以看出是明顯會更清晰明亮些的。
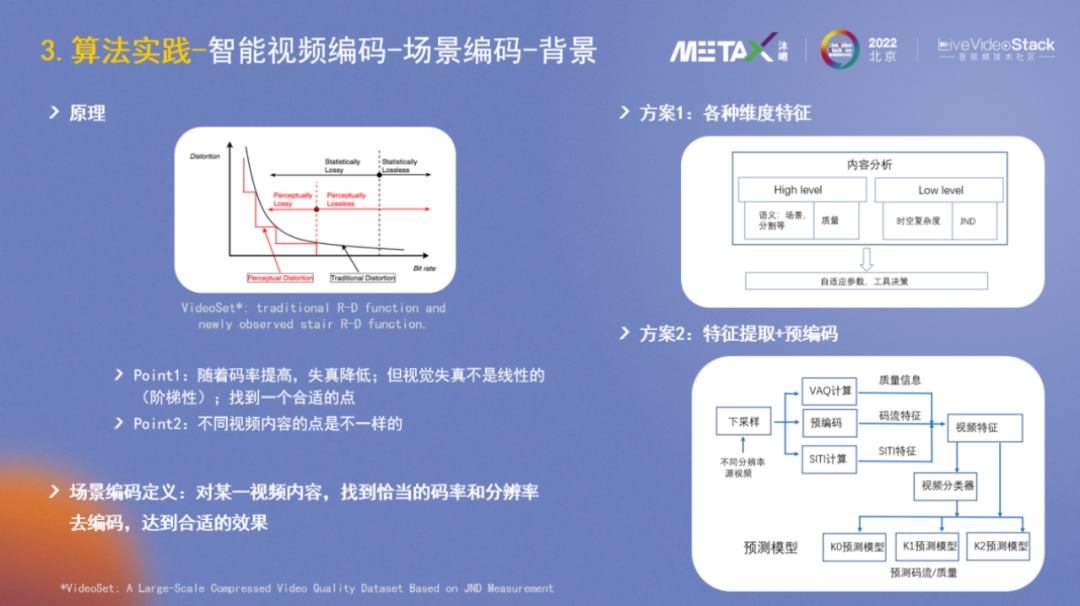
場景編碼的原理相信大家并不陌生,視頻編碼領域的R-D曲線描述了一個基本原理:碼率越低,失真越大。論文VideoSet進行了進一步的研究,發覺人的視覺感受并不是光滑的R-D曲線,而是階梯狀的,類似于我們學英語時并不是循序漸進的,而是平穩一段時間然后會突然提升。在AI算法訓練側也有類似現象,Loss很多時候也是一段一段震蕩下降的。所以在對一個視頻進行壓縮時,需要找到一個合適的點,使得Distortion差不多的情況下,Bitrate盡量小。另外,不同視頻內容,比如游戲變化較劇烈,動畫變化較少,合適的點是不一樣的。
綜上,可以對場景編碼做一個定義:對某一視頻內容,找到恰當的碼率和分辨率去編碼,達到合適的效果。
在過往的音視頻大會上,各大廠商也分享了不少的方案,譬如方案1,它會提取各種維度特征如High-level(場景、質量)、Low-level(時空復雜度、JND),然后得到自適應參數進行決策。方案2側重于特征提取+預編碼,即通過下采樣、預編碼、VAQ計算后得到一些特征,然后再預測碼率和編碼質量。
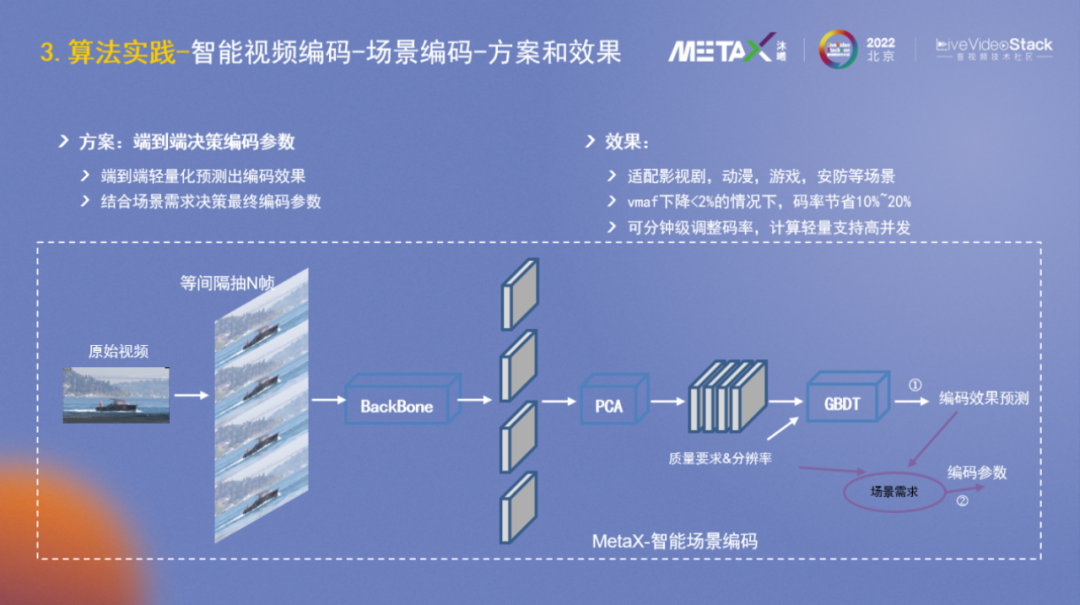
在以上方案的基礎上,進一步思考,是否可以直接端到端而非分階段分類別地提取特征呢?
通過探索嘗試,我們設計研發了圖中的算法模型和策略,它能夠端到端輕量化地預測出編碼效果,然后結合場景需求決策出最終的編碼參數。模型已經適配影視劇、動漫、游戲、安防等場景。在VMAF下降<2%的情況下,碼率節省10%~20%;并且可以分鐘級調整碼率;計算輕量支持高并發譬如32路。

ROI檢測的發展歷程大致是中心區域ROI—人臉ROI—字幕ROI—主觀感興趣區域ROI。主觀感興趣區域ROI的難度較大,且因人而異。思考實踐后,我們定義重要的前景就是感興趣區域,然后前景分割技術目前也是比較成熟了。
一個特殊的場景是游戲,如王者榮耀、絕地求生等與當前前景分割的公開數據集領域差異很大,因此在開源預訓練模型上的效果很差。此外不同游戲場景的差異也很大,數據標注繁瑣且泛化能力差。我們的研發目標是帶普遍意義的基礎解決方案,是否存在一種避免數據標注然后泛化性高的算法能力,能夠自動在各種游戲場景分割檢測重要目標,譬如英雄?
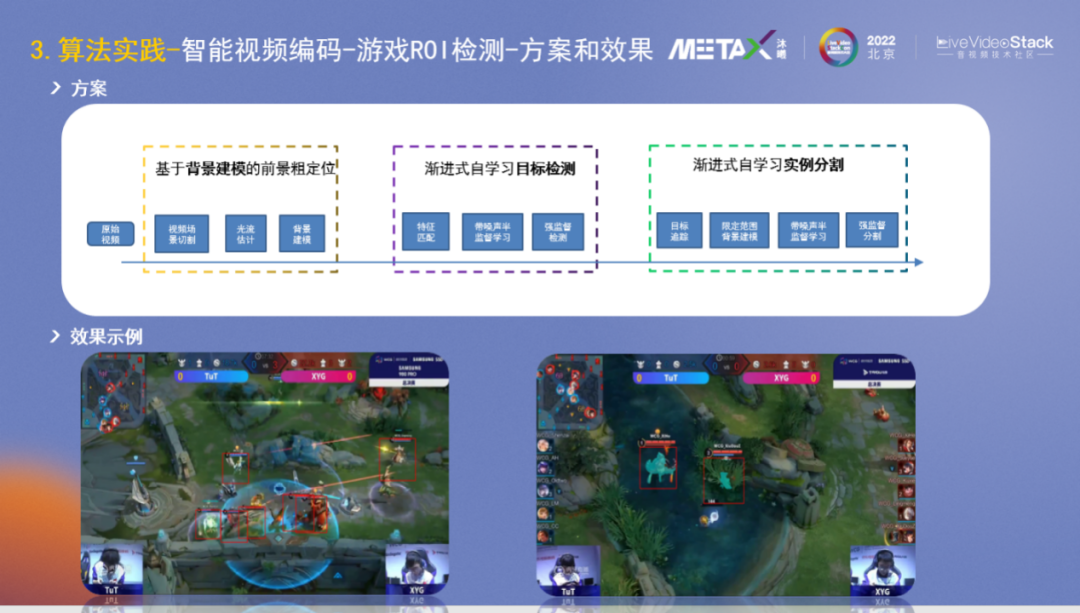
我們的檢測分割方案大體可以分為三個研發階段:
1、基于背景建模的前景粗定位:基于人眼對運動物體的敏感,先對視頻進行場景分割,然后在做光流估計,再結合背景建模算法,可以較粗糙的檢測出來英雄。
2、漸進式自學習目標檢測:再結合特征匹配和帶噪聲的半監督學習,可以訓練出一個模型較細致地框出英雄。
3、漸進式自學習實例分割:在前兩個階段的基礎上繼續努力,進行目標追蹤,限定范圍內的背景建模等,可以很好地進行實例分割。
下方是效果示例,這些游戲視頻并沒有標注任何訓練圖片,是通過純算法學習出來的。

檢測出感興趣區域后,接下來的問題是來應該分配多少碼流對它進行編碼。
方案1的實現是第三種視頻壓縮方案,它和編碼器深入融合,通過分析統計所有宏塊的QP,然后根據目標,譬如30%碼流分給20%ROI區域,修正得到各QP值并進行配置。
基于AI外層輔助編碼,我們避免在幀內進行數據交互,而是考慮直接在幀級別控制。
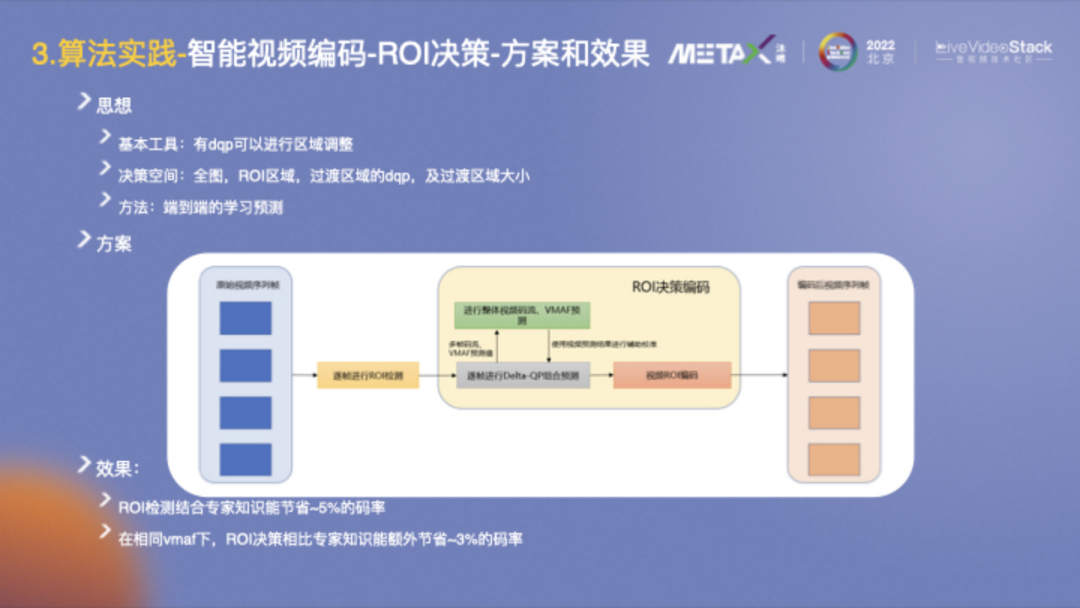
FFmpeg開放了dqp(delta-QP)進行區域調整,整個問題可以抽象為決策問題:設置全圖、ROI區域、過渡區域的dqp值以及設置過渡區域的大小。具體方案充分利用了AI的能力,端到端的直接學習預測,可以較好地解決這一問題。
從效果上看,ROI檢測結合專家知識能節省~5%的碼率;然后在相同VMAF下,ROI決策相比專家知識能額外節省~3%的碼率。
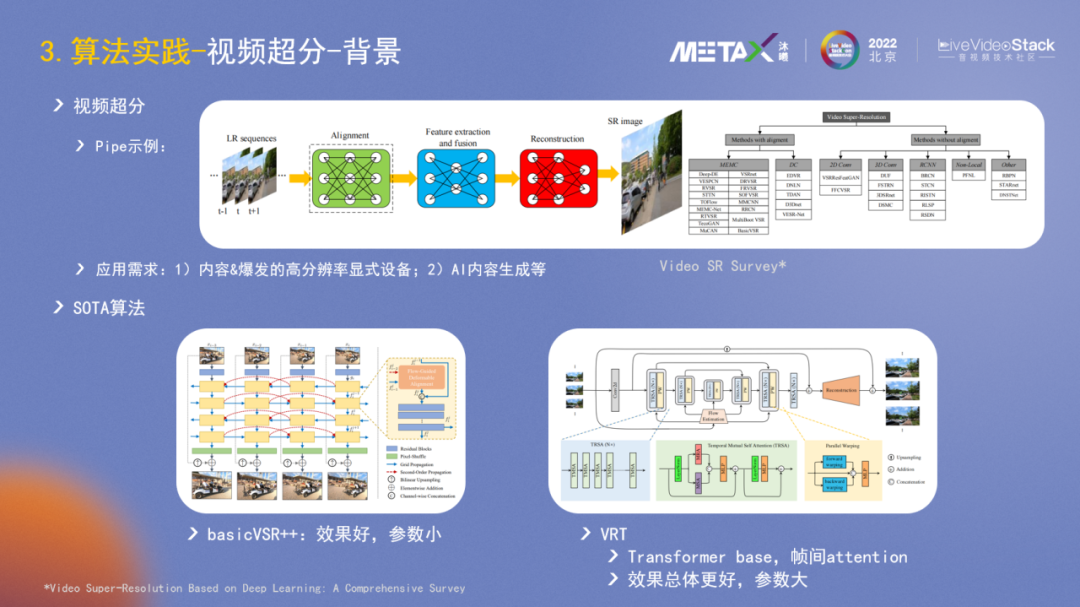
視頻超分方面,隨著顯示設備如電視機等越來越大,一個重要需求是在影視劇等視頻內容上,可以是視頻內容的源側做超分提升內容質量;也可以是在終端側做超分提升顯示效果。另一個可見的大需求是AIGC,超分模塊會和diffusion模塊協同生成video。
Video SR Survey這篇文章較好地總結了超分pipeline和主流的方法。整個過程可描述為輸入低分辨率視頻序列,進行圖像數據的對齊,然后做特征提取和融合,最后進行重建。右側歸納總結了一些主流的算法模型,包括運動估計、光流、2D/3D卷積等。
2022年有兩個SOTA算法,一個是basicVSR++,基于LSTM做特征的雙向傳播,需要的幀不多,對齊技術用光流;另一個是VRT,使用Transformer結構,用QKV而非傳統光流做特征的匹配融合,總體效果更好,但參數量也更大。
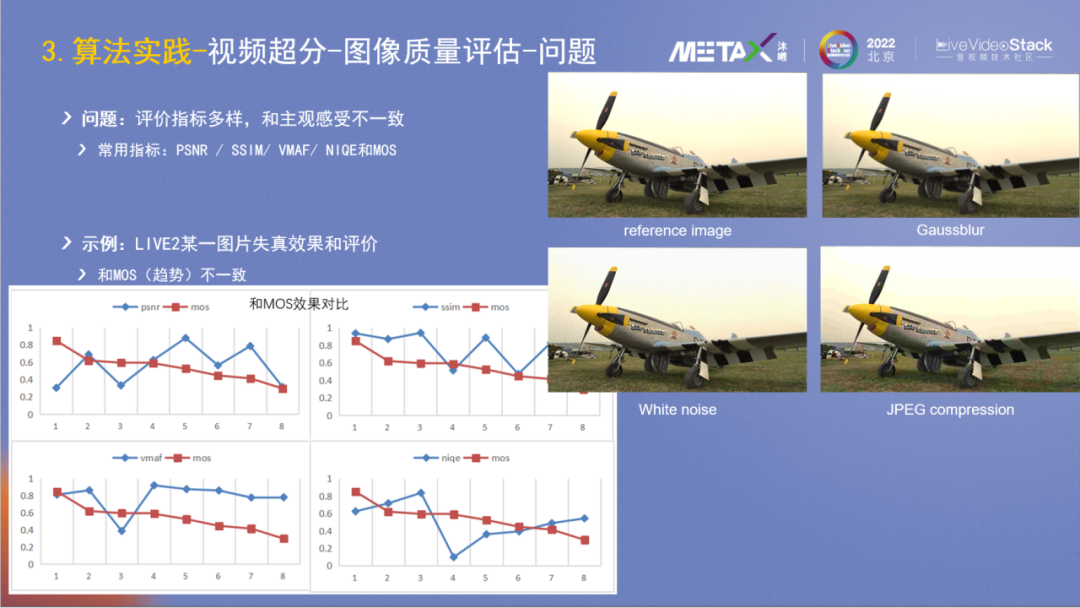
算法研發特別重要的是評價,在超分所屬的圖像質量評價領域,已有PSNR/SSIM/VMAF/NIQE等四個自動化的客觀指標;也有MOS的主觀評價,代表了人的主觀感受,但它是人工的所以獲取成本較高。在超分算法等研發過程中,時常會出現多個客觀指標評價不一致的情況,那如何判斷迭代中的算法效果是否正向呢?
右側是LIVE2的圖片示例,圖1是reference image,圖2做了Gaussblur,圖3加了白噪聲,圖4加了JPEG壓縮。主觀看來圖3和圖1比較好,圖2和圖4看起來較差。
左下角是不同指標的對比結果,它包含了八種不同的失真方式,包括JPEG compression、JPEG-2000 compression、Gaussian blur、White noise、Bit error等。紅色曲線是MOS的結果,可以看出其它4個客觀指標與MOS的表征都不一樣,或者說它們都不能很好地反應圖片主觀質量。

再來看一個具體案例,它們是使用了SwinIR-GAN和BasicVSR++的圖片效果。右圖的PSNR指標較好,但人的主觀感受應該是左圖較好。

針對指標不一致的問題,能否有更強表征能力的指標?我們設計了一個基于集成學習的更有MOS表征能力的指標stackMosScore。在數據集側搭建了包含主觀評價的數據集和其它影視劇的數據,然后使用當前的4個客觀指標作為基礎做集成學習,目標是擬合MOS。
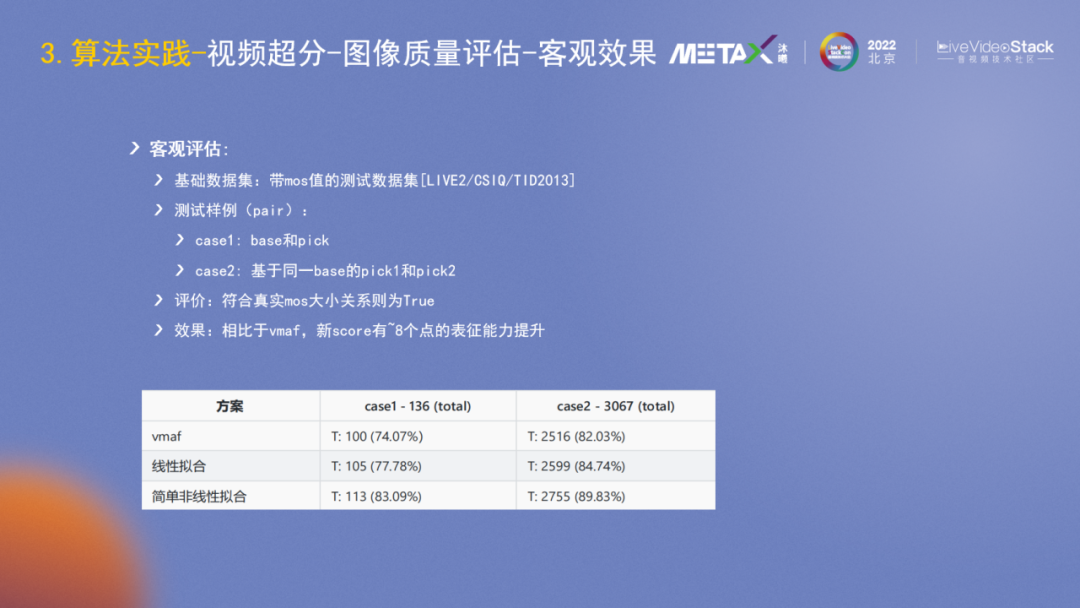
從評價數據集上看,它比原來最好的VMAF高出7個點,更好地表征了人的主觀感受。

這里是一個圖片示例,stackMosScore較好地表征了3張圖片的質量好壞關系。
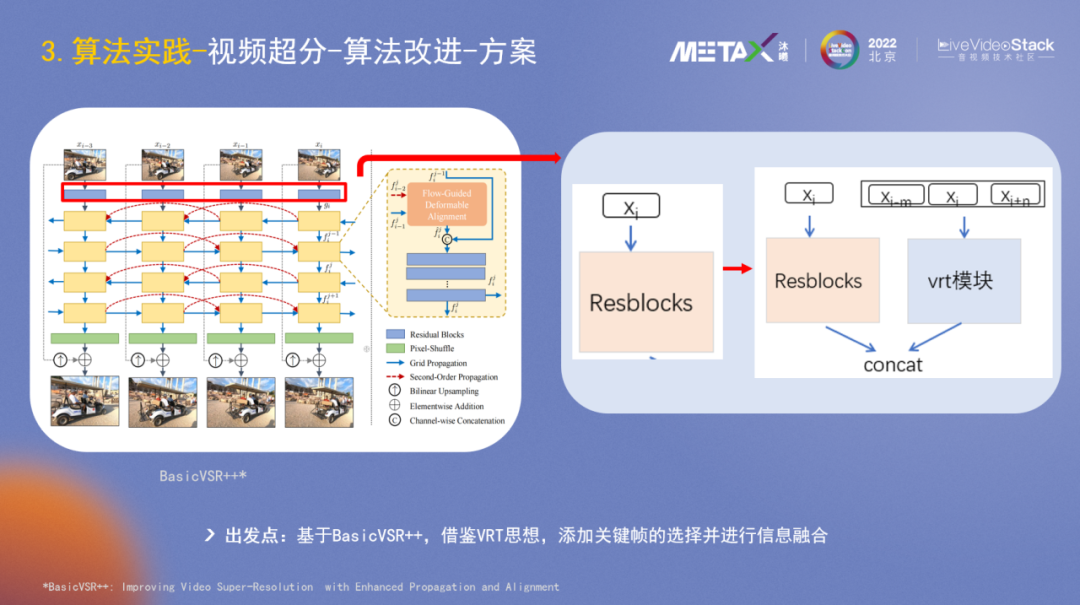
在算法模型層面我們也做了一些探索嘗試,采用BasicVSR++的主體結構,借鑒VRT思想,添加了關鍵幀的選擇并進行信息融合。

實際場景一般是兩倍超分,在影視劇數據集的評測上,PSNR提升0.18db。
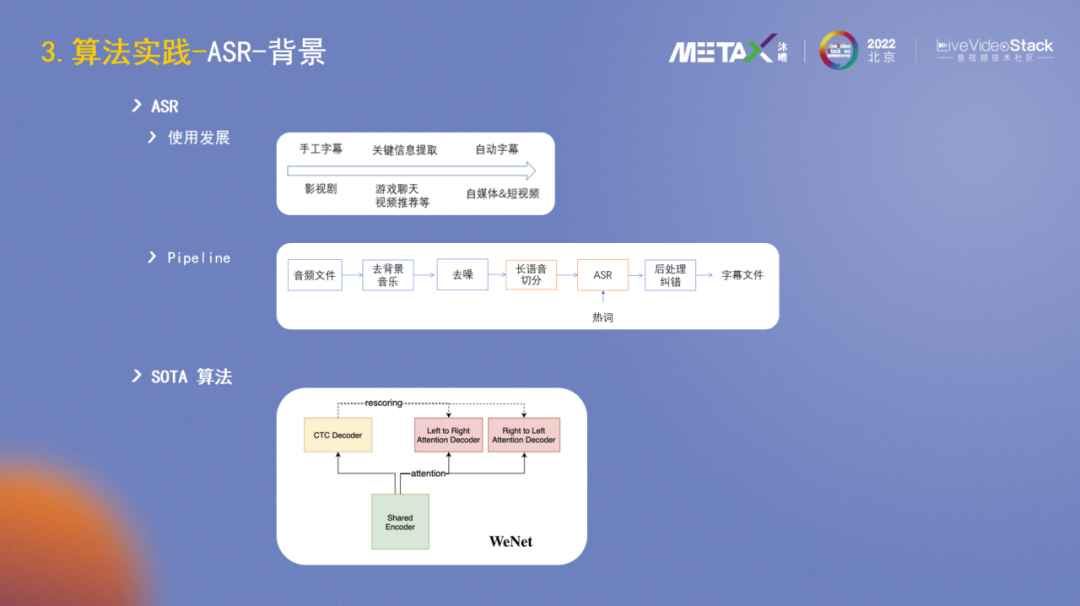
最后介紹下ASR方面的一些實踐。ASR的一個重要應用場景是字幕。影視劇早期是手工字幕,隨著互聯網平臺的發展壯大,ASR在內容審核側會做一些關鍵詞的提取,在自媒體時代,短視頻和直播蓬勃發展,ASR被廣泛用來自動生成字幕。
字幕生成的Pipeline大致可分為:去背景音樂、去噪、長語音切分、ASR識別、后處理糾錯和輸出字幕文件。
ASR的SOTA算法是WeNet(2),它很好地將實時語音識別和離線語音識別兩個分支進行了統一。

然后我們主要在長音頻的切分和ASR算法上做了一些改進嘗試,具體包括熱詞(來自演員表或手動設置),語音增強(去背景音,去噪),短音頻合并成長音頻優化(適當合并短音頻成長音頻,10-15s),WeNet模型加噪聲以及背景音語料微調,解碼參數微調(模型層面提升對噪聲和背景音的魯棒性)。
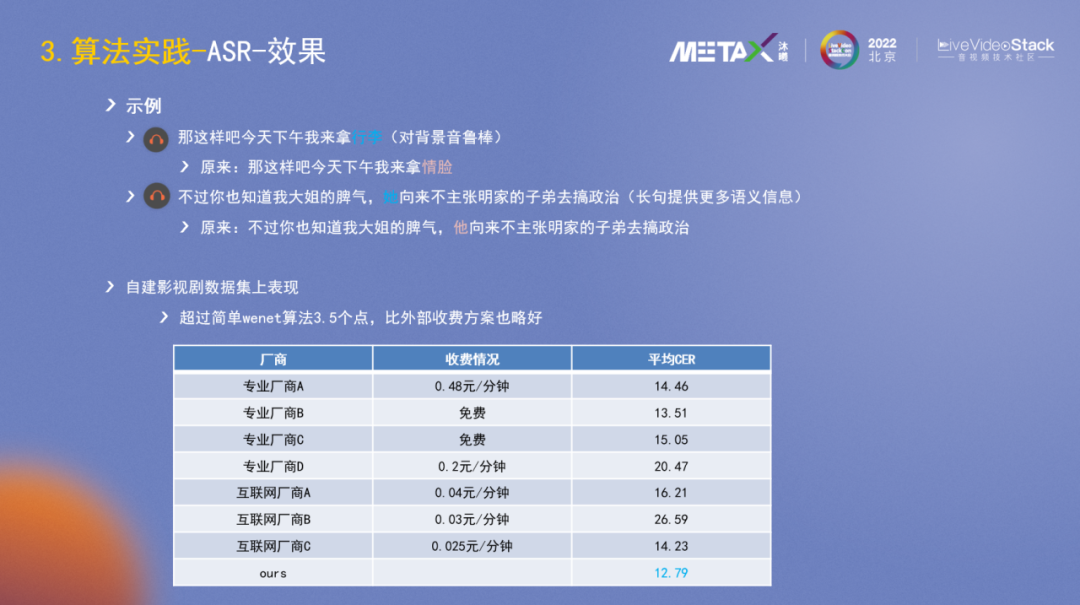
這里是一些效果示例:
示例1,背景音去除后能聽清最后兩個字;
示例2,這里是男的他,變長句后結合上下文能識別出是女的她。
上圖表格數據是在影視局數據集上的測試結果,總的來說效果還不錯。
-04-
后續工作

后續工作,在算力方面,曦思N100已進入小規模量產階段,接下來會繼續優化提升軟件棧等來提升全局性能。在解決方案(算法)方面主要包括:
協同優化效果:在核心場景,譬如智能視頻編碼,在模塊間更好地上下協同,提升效果;
系統性性能優化:結合N100芯片的特點,優化算法的網絡結構乃至方案等;
SDK化部署:整合智能編碼、超分、ASR等的能力,提供基礎的sdk能力作為第三方的基礎解決方案。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4554瀏覽量
92037 -
視頻處理
+關注
關注
2文章
97瀏覽量
18777 -
視覺
+關注
關注
1文章
144瀏覽量
23778
原文標題:海量視頻處理的應對和算法實踐
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于DSP的視頻采集驅動程序的設計
電子信息海量經典學習視頻
自制開源軟核處理器OpenMIPS實踐版發布,附講解視頻
算法工程師(通信 視頻 音頻 圖像)-廣東
請問基于mcfw的視頻圖像處理加一些自己的視頻圖像處理的算法,應該放在什么位置?
視頻壓縮算法的特點和處理流程是怎樣的?
基于Simulink的視頻與圖像處理算法的快速實現
基于切片原理的海量點云并行簡化算法
海量嘈雜數據決策樹算法
如何在MATLAB中開發基于像素的視頻和圖像處理算法





 工商網監
工商網監
評論