 FPGA常用運算模塊-加減法器和乘法器
FPGA常用運算模塊-加減法器和乘法器
寫在前面
本文是本系列的第二篇,本文主要介紹FPGA常用運算模塊-加減法器和乘法器,xilinx提供了相關的IP以便于用戶進行開發使用。
加減法器模塊
在xilinx中,有一個IP模塊提供加減法運算的功能,
概述
加法器/減法器IP 提供 LUT 和單個 DSP slice 實現加減法實現。加法器/減法器模塊可以創建加法器(A+B)、減法器(A–B) 和可動態配置的加法器/減法器,用于操作有符號或無符號數據。該功能可以在一個單個 DSP slice 或 LUT(但目前不是兩者的混合)。該模塊可以流水線化。支持fabric實現輸入范圍從1到256位寬,該IP核支持DSP片實現,輸入高達58位。可選進位輸入和輸出、時鐘啟用和同步清除、旁路(負載)能力、設置B值為一個常量。
IP核圖示以及端口介紹
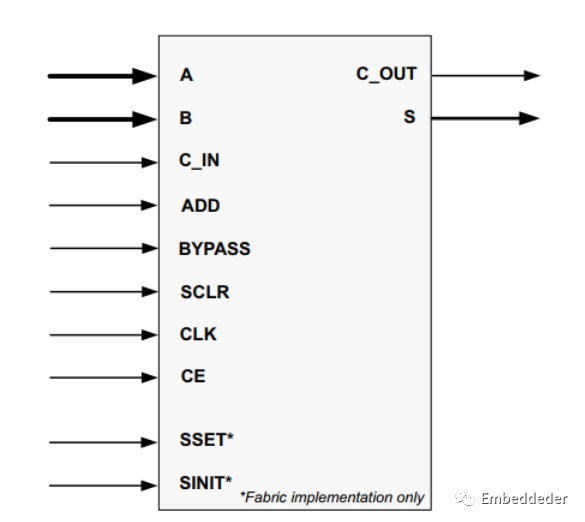
| Name | Direction | Description |
|---|---|---|
| A[N:0] | Input | 輸入端口A,位寬為N+1 |
| B[M:0] | Input | 輸入端口B,位寬為M+1 |
| ADD | Input | 控制加法器/減法器執行的操作(1=加法,0=減法) |
| C_IN | Input | 進位輸入 |
| C_OUT | Output | 進位輸出 |
| S[P:0] | Output | 結果輸出 |
| BYPASS | Input | 旁路控制,將B輸出給S |
| CE | Input | 時鐘使能,高有效 |
| CLK | Input | 時鐘信號,上升沿有效 |
| SCLR | Input | 同步復位,將重置核心中的所有寄存器,定制內核時可以選擇SCLR和CE引腳的優先級 |
| SINIT | Input | Synchronous Initialization - forces outputs to a user defined state when driven High |
| SSET | Input | Synchronous Set - forces outputs to a High state when driven High |
如果Constant Input = TRUE and Bypass = FALSE,則B端口不存在。一個用戶定義的核心內部常量被應用到B操作數的位置。
輸出位寬設計
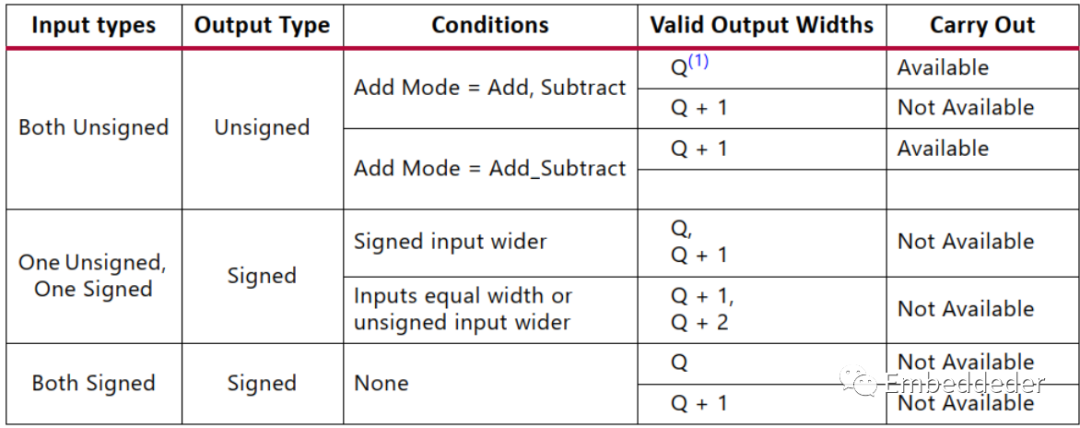
Q的值等于AB輸入兩者之間的最大值。
流水線操作
加法器/減法器模塊可以選擇流水線操作用來提高速度。 流水線操作由延遲參數控制。 將延遲配置設置為自動,以實現最優的流水線速度。 將延遲配置設置為手動,以允許在延遲參數中輸入有效數量的流水線層級數。
DSP片
對于DSP片的實現方式,單個的DSP片可以用0、1或2級寄存器進行流水線操作。 Latency Configuration = Automatic ,此時優化速度延遲獲得最優的流水操作速度; 如果Latency = 1, 只有輸出寄存器存在。 Latency = 2,輸出和輸入寄存器都存在。
Fabric 實現
對于使用PFGA的邏輯資源的實現方式,流水線操作是通過將輸入總線 分成許多總線片(等于流水線階段的數量)來實現的。 在第一階段,對每個總線片做盡可能多的工作,將它們加在一起,并存儲結果和每個結果的進位輸出。 在第二階段,從最低有效位的部分得到的進位被輸入到下一個較高有效位的結果中,它產生一個進位被輸入到下一個階段的下一個結果中,直到進位被傳播到頂部。
因為需要存儲的數據較少,所以這比存儲每個切片的輸入直到生成該切片的進位的更直觀的技術更有效。 此外,該設計更小且更易于布線。
上電或復位后,流水線模塊需要幾個時鐘周期才使輸出變為有效,由延遲控制參數指定。
如果在流水線模塊上請求旁路,則旁路值會在延遲控制指定的時鐘周期數之后出現在輸出上。 如果同時請求旁路和時鐘使能,則必須設置旁路優先級,以便旁路不會覆蓋時鐘使能。 對于流水線模塊,資源使用率大約是非流水線模塊的延遲倍數。 為了提高時鐘速度,流水線導致面積使用量的顯著增加。 如果需要延遲但面積比速度更重要,請在此模塊的 S 輸出中添加一個基于 SRL16 的移位寄存器,以優化面積使用。
加法器IP配置
加法器IP配置如圖所示,
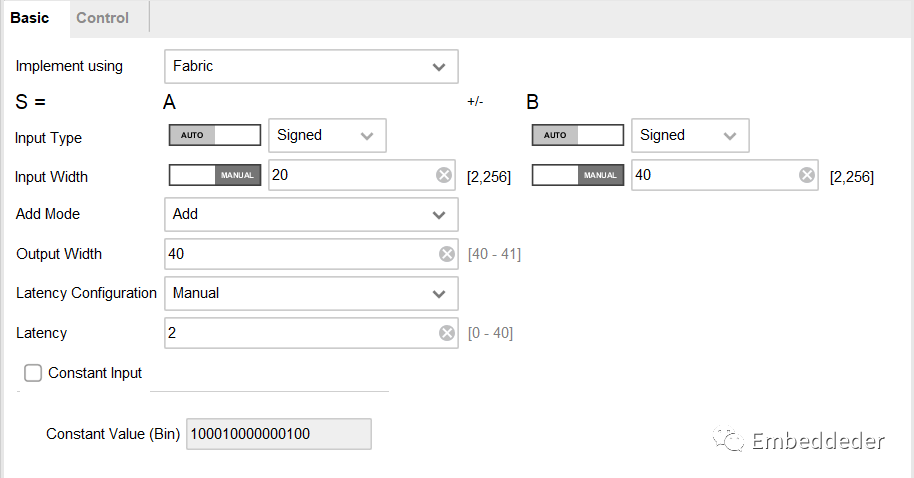
在basic界面,可以對IP的實現方式,輸入的數據類型,位寬,IP的方式(加法器、減法器、加減法器)、流水操作延遲方式和延時周期,常數輸入進行配置。
Constant Input and Constant Value :當常量輸入為 TRUE 時,端口 B 設置為參數 Constant Value 指定的值。 常數值必須是以二進制格式輸入且不得超過 B 輸入寬度。 在大多數情況下指定端口 B 是一個常量時候,會自動創建一個沒有端口 B 的模塊。 但是在當請求旁路功能時,因為需要端口 B 來提供旁路數據。 默認是端口 B 提供的端口 B 值。 會生成B端口。
加減法器的控制配置界面如下,
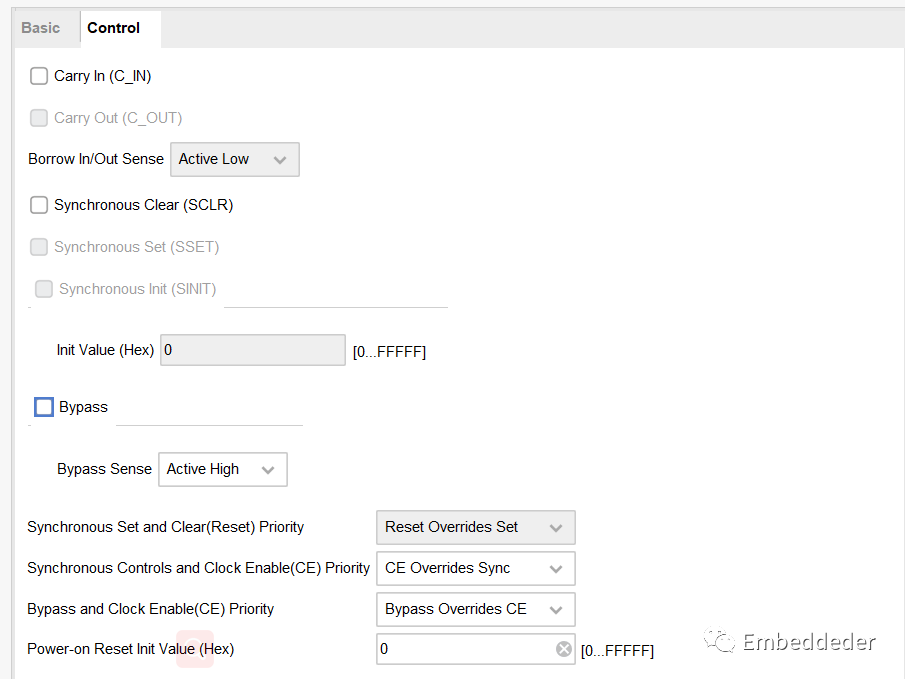
在控制界面可以配置加減法器進位、旁路、復位等控制操作。
Carry In :設置為TRUE時,創建一個C_IN端口。 這是用于加法器的高電平有效進位端口和用于減法器和加/減法器的可編程(高電平有效/低電平有效,帶借入/輸出檢測)進位端口。
Carry Out :當設置為TRUE時,創建一個端口C_OUT。 實現了加法器和加減法器的高有效同步進位,以及可編程(設置高低有效,借入/借出檢測)的減法器和加減法器中的減法器的借位標志。
Bypass :設置為 TRUE 時,創建旁路引腳。 激活 BYPASS 引腳設置輸出為端口 B 上給定的值。 此功能用于創建可加載的計數器和累加器。
Bypass and Clock Enable (CE) Priority :該參數控制是否旁路輸入由時鐘使能限定。 當設置為Bypass_Overrides_CE時,BYPASS 信號的激活也使能寄存器。 當設置為CE_Overrides_Bypass,寄存器必須有 CE 激活才能加載 B 端口數據。
Bypass Sense :控制旁路的敏感電平,是高有效還是低有效,因為高低電平有效在有些時候都能獲得更好的效率。
Borrow In/Out Sense :當設置為Active_Low時,用于減法的C_IN和C_OUT引腳是低有效的。 這符合fabric實現規則,是一個最佳設置。
Synchronous Set :指定是否包含 SSET 引腳。 在DSP實現模式下,SSET 引腳無效。
Synchronous Init :指定是否包含一個SINIT引腳,當斷言時,該引腳同步地將輸出值設置為Init value定義的值。 如果SINIT存在,那么SSET和SCLR都不存在。 在DSP實現模式下,SINIT引腳是無效的。
Init Value :十六進制指定當斷言SINIT時輸出初始化為指定的值。 如果Synchronous Init = false 則忽略。
Power on Reset Init Value :指定(十六進制)S寄存器在上電復位時初始化的值。
Synchronous Controls and Clock Enable (CE) Priority : 該參數控制SCLR(以及邏輯單元模式下的SSET和SINIT)輸入是否由時鐘使能限定。 當設置為 Sync_Overrides_CE 時,同步控制覆蓋 CE 信號。 當設置為 CE_Overrides_Sync 時,控制信號僅在 CE 為高時有效。 請注意,在結構原語上,SCLR 和 SSET 控制覆蓋 CE,因此選擇 CE_Overrides_Sync 通常會導致額外的邏輯。
Sync Set and Clear (Reset) Priority :控制 SCLR 和 SSET 的相對優先級。 當設置為 Reset_Overrides_Set 時,SCLR 會覆蓋 SSET。 默認值是Reset_Overrides_Set,因為這是原語的排列方式。 使 SSET 優先需要額外的邏輯。
乘法器
乘法器IP實現高性能、優化的乘法器方案。 可以使用資源和性能權衡選項來為特定的應用程序定制IP。 該IP支持輸入范圍從1到64位,輸出從1到128位。 所有乘法器都可配置延遲。 當使用DSP Slice時,支持對稱四舍五入到無限。
概述
乘法器IP允許設計者精細地構建定點乘法器。 可以使用 DSP Slices、Slice 邏輯或組合的方式進行構建乘法器IP,并且針對性能或資源進行了優化的結構。 常數系數乘法器也可以使用許多不同的邏輯資源選項來實現。 并且可以通過流水線操作層級數量以適應延遲和性能要求。 DSP Slice的對稱舍入特性可用于并行乘法器。
IP核圖示以及端口介紹
| Signal | Direction | Description |
|---|---|---|
| A[N-1:0] | Input | 乘數A,位寬為N |
| B[M-1:0] | Input | 乘數B,位寬為M,只有在parallel multipliers模式下有該端口。 |
| CLK | Input | 時鐘信號 |
| CE | Input | 高有效時鐘使能信號 |
| SCLR | Input | 高有效同步復位信號,(SCLR/CE 優先級可以配置) |
| P[X:Y] | Output | 乘法輸出 |
乘法器IP配置
乘法器IP的basic配置界面如下:
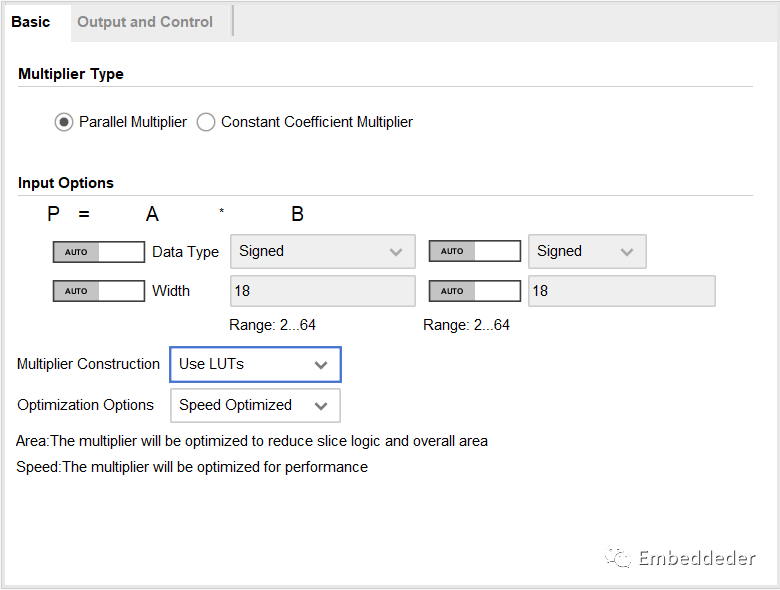
在該界面可以進行配置乘法器的類型,乘數的數據類型,位寬,乘法器的實現方式以及優化方式。
Multiplier Type :在并行和常數系數乘法器選項之間進行選擇。
并行乘法器選項:這些選項只有當選擇的乘法器類型是并行乘法器時才可見。
Multiplier Construction :選擇用于IP實現的結構是LUT還是專用乘法器原語。
優化選項 :
DSP48E1 Slice:可以為高達 47x47 的乘法器大小選擇速度或面積優化。 速度優化 :充分利用乘法器原語來提供最高性能的實現。 面積優化 :混合使用切片邏輯和專用乘法器原語來降低基于 DSP 切片的乘法器利用率,同時仍提供合理的性能。 對于 47x47 以上的尺寸,只允許優化速度。
LUT-based multipliers : 區域優化降低了延遲和LUT利用率,以可實現的時鐘頻率為代價。 當兩個輸入操作數都是無符號且兩個輸入操作數都小于16位時,區域優化是最有效的。
Constant-Coefficient Multiplier Options :這些選項只有當選擇的乘數類型是常數系數乘法器時才可見。
Coefficient :在顯示的范圍內輸入系數的整數值。 支持正系數和負系數。 常量 (B) 端口的輸入類型(有符號或無符號)由 Vivado IDE 根據輸入的整數常量自動配置。 可以選擇 A 端口是有符號的還是無符號的。
Memory Options : 選擇乘法器是使用分布式內存、塊內存還是使用 DSP Slices 來實現。
乘法器IP的輸出控制配置界面如下:
Output Product Range: 根據輸入操作數的寬度自動配置輸出產品寬度。
Use Custom Output Width :如果通過設置 MSB 和 LSB 范圍,對輸出進行切片。
Use Symmetric Rounding :對于基于 DSP Slice 的并行乘法器,如果需要,可以將乘積對稱舍入到無窮大。這與MATLAB的 round 函數的行為相同。
流水線和控制信號:
流水線階段:
為乘數實例選擇流水線操作的層級。右邊的標簽提供了關于實現最佳性能的流水操作的最佳數量的反饋。
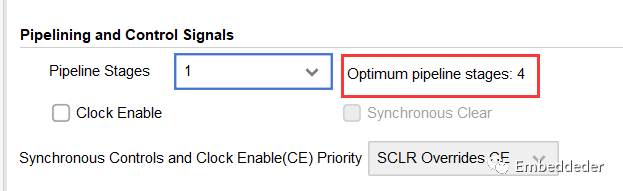
Pipeline Stages = 0 意味著IP是組合的。
Pipeline Stages = 1 意味著IP的輸出是寄存器型的。
Pipeline Stages > 1 使寄存器插入到輸入和輸出之間,直到最優的流水線操作的層級。添加更多寄存器可以提高可實現的時鐘速度,同時增加延遲。
流水線操作的層級設置的值大于最優值的值,將導致在輸出時添加基于SRL16的移位寄存器,以實現額外的延遲。
Clock Enable :選擇設計中的所有寄存器是否都具有時鐘使能控制。
Synchronous Clear :選擇是否該設計中的所有寄存器都具有同步復位控制。
SCLR/CE Priority :當SCLR和CE引腳同時存在時,可以選擇scr和CE的優先級。選擇 SCLR overrides CE ,使用的資源最少,實現的性能最好。
-
dsp
+關注
關注
552文章
7962瀏覽量
348308 -
FPGA
+關注
關注
1626文章
21678瀏覽量
602031 -
Xilinx
+關注
關注
71文章
2164瀏覽量
121039 -
乘法器
+關注
關注
8文章
205瀏覽量
36984 -
減法器
+關注
關注
1文章
26瀏覽量
16826
發布評論請先 登錄
相關推薦
怎么設計基于FPGA的WALLACETREE乘法器?
乘法器對數運算電路應用


基于IP核的乘法器設計
進位保留Barrett模乘法器設計

乘法器原理_乘法器的作用

FPGA常用運算模塊-復數乘法器






 工商網監
工商網監
評論