") 讓GAN再次偉大!拽一拽關鍵點就能讓獅子張嘴&大象轉身
讓GAN再次偉大!拽一拽關鍵點就能讓獅子張嘴&大象轉身
這兩天,一段AI修圖視頻在國內(nèi)外社交媒體上傳瘋了。
不僅直接躥升B站關鍵詞聯(lián)想搜索第一,視頻播放上百萬,微博推特也是火得一塌糊涂,轉發(fā)者紛紛直呼“PS已死”。
怎么回事?
原來,現(xiàn)在P圖真的只需要“輕輕點兩下”,AI就能徹底理解你的想法!
小到豎起狗子的耳朵:
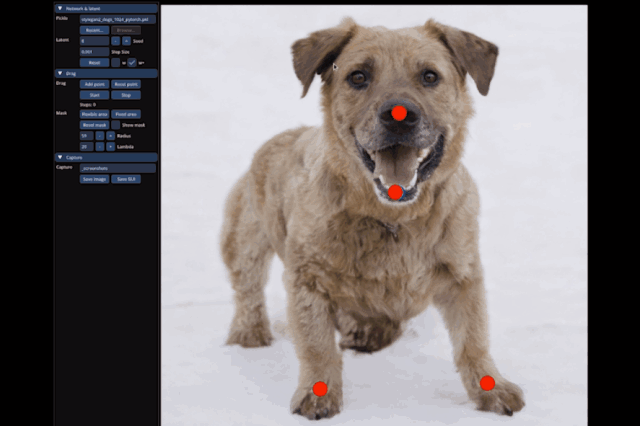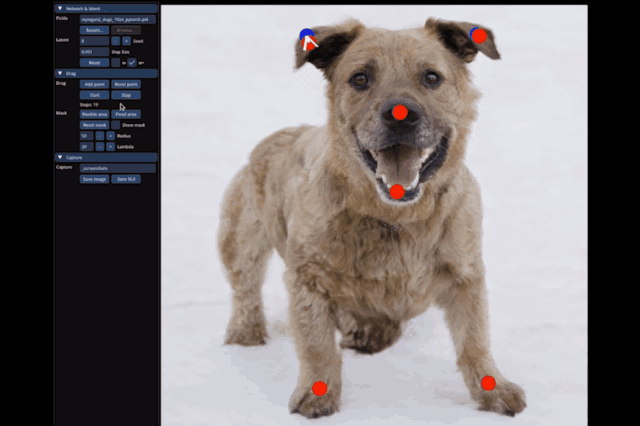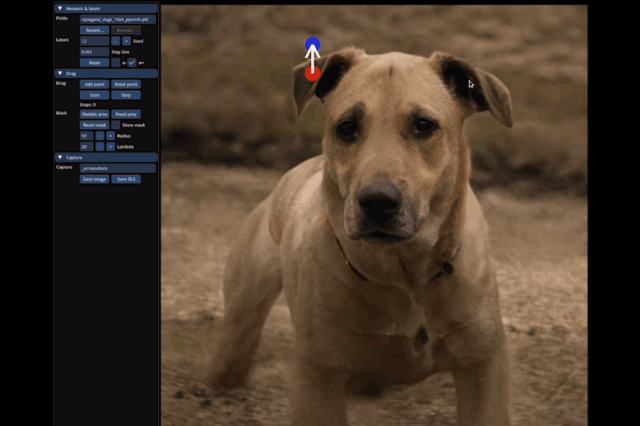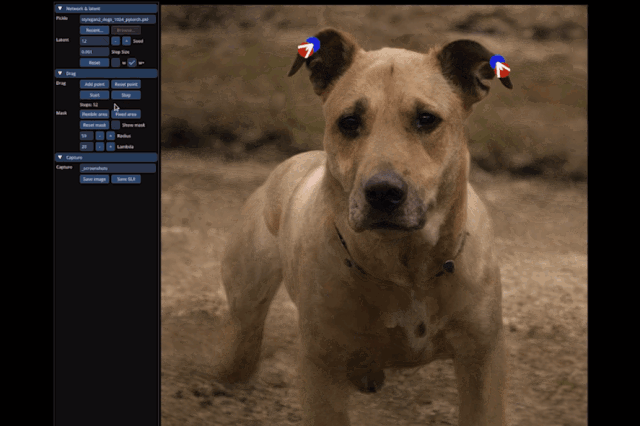
大到讓整只狗子蹲下來,甚至讓馬岔開腿“跑跑步”,都只需要設置一個起始點和結束點,外加拽一拽就能搞定:
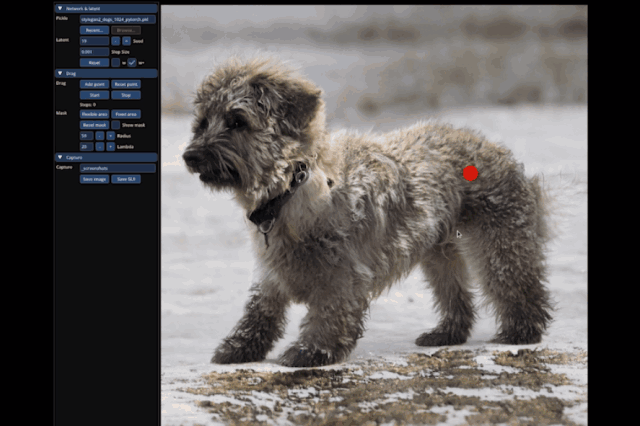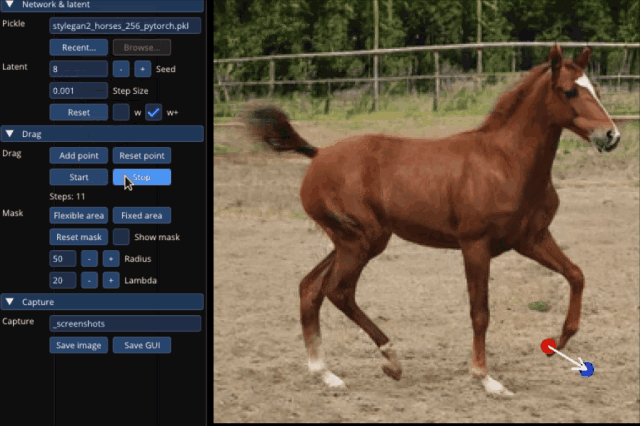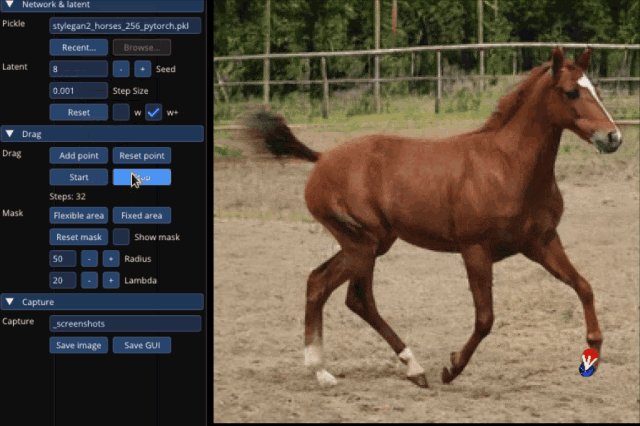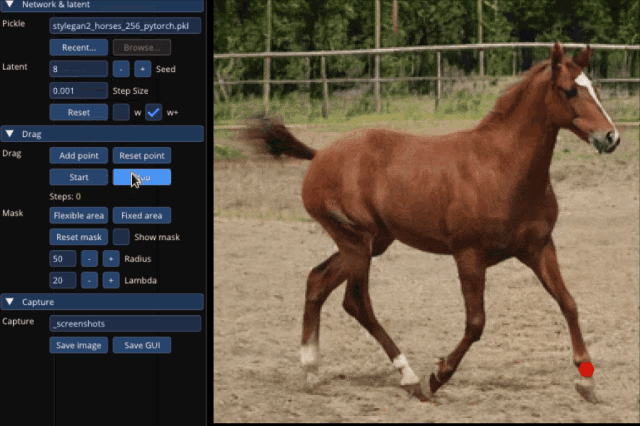
不止是動物的調(diào)整,連像汽車這樣的“非生物”,也能一鍵拉升底座,甚至升級成“加長豪華車”:

這還只是AI修圖的“基操”。
要是想對圖像實現(xiàn)更精準的控制,只需畫個圈給指定區(qū)域“涂白”,就能讓狗子轉個頭看向你:

或是讓照片中的小姐姐“眨眨眼”:
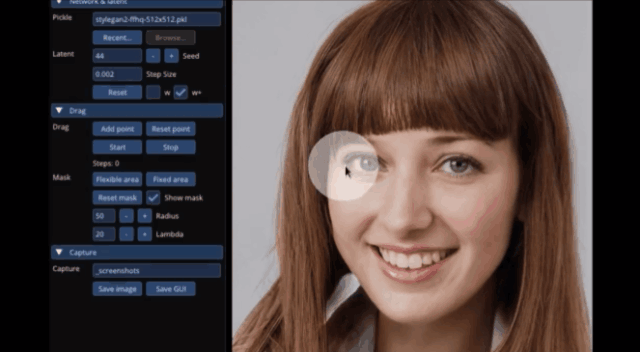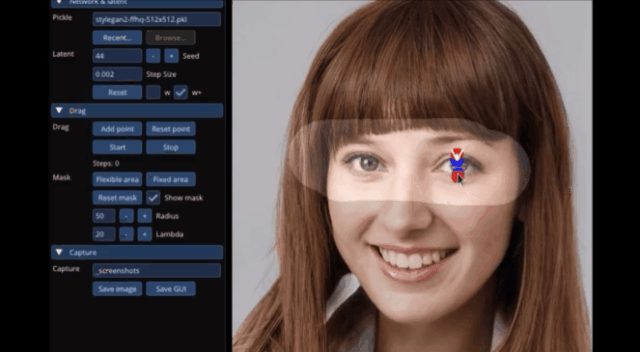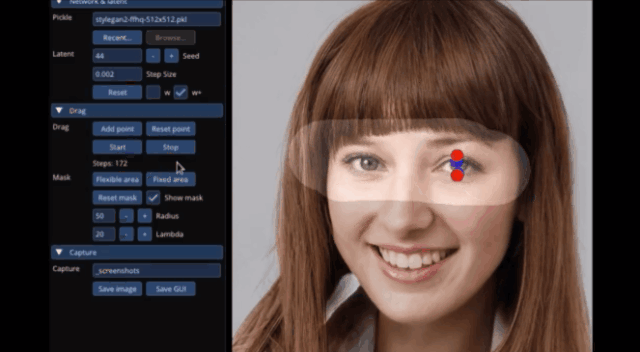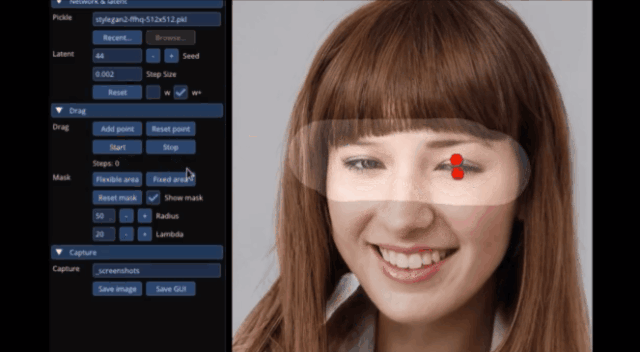
甚至是讓獅子張大嘴,連牙齒都不需要作為素材放入,AI自動就能給它“安上”:
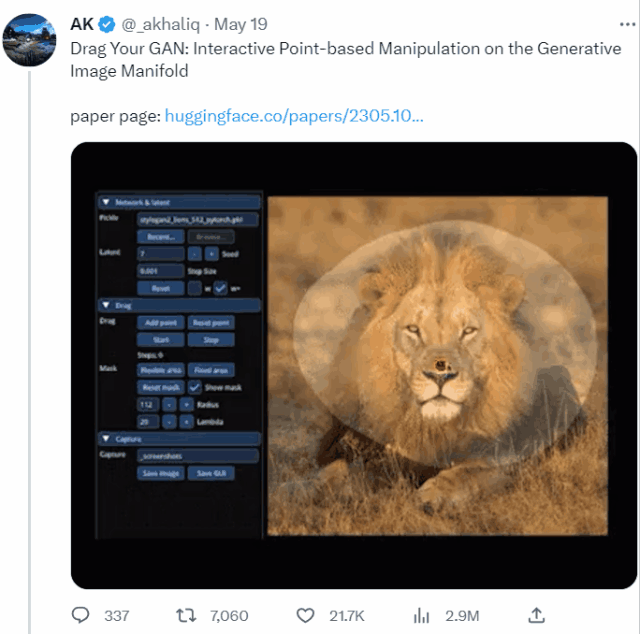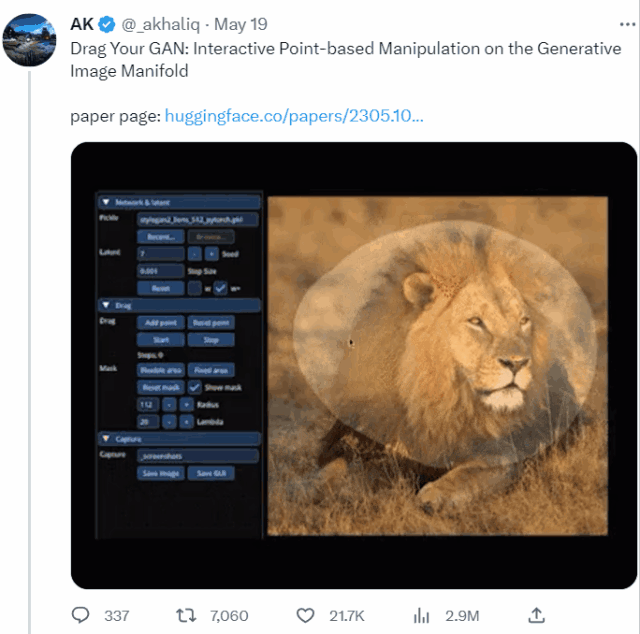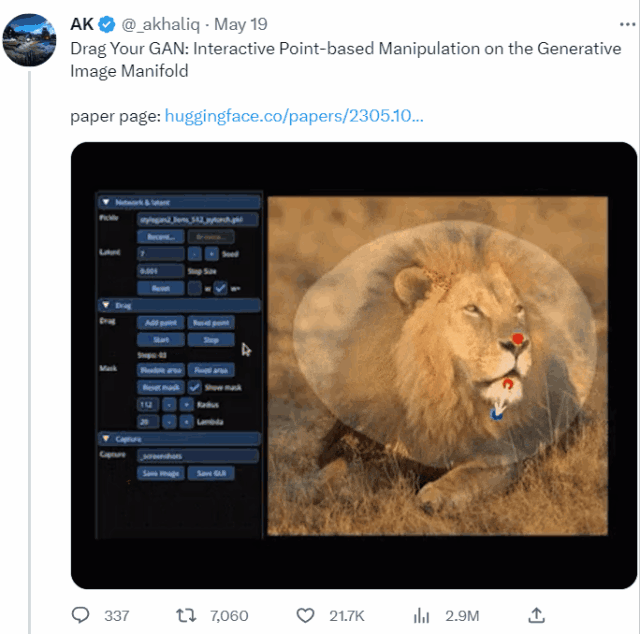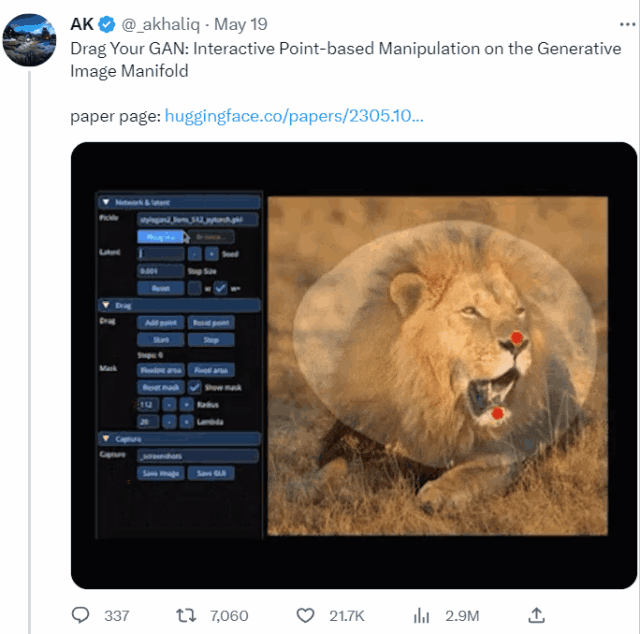
如此“有手就能做”的修圖神器,來自一個MIT、谷歌、馬普所等機構聯(lián)手打造的DragGAN新模型,論文已入選SIGGRAPH 2023。

沒錯,在擴散模型獨領風騷的時代,竟然還能有人把GAN玩出新花樣!

目前這個項目在GitHub上已經(jīng)有5k+ Star,熱度還在不斷上漲中(盡管一行代碼還沒發(fā))。

所以,DragGAN模型究竟長啥樣?它又如何實現(xiàn)上述“神一般的操作”?

拽一拽關鍵點,就能修改圖像細節(jié)
這個名叫DragGAN的模型,本質上是為各種GAN開發(fā)的一種交互式圖像操作方法。
論文以StyleGAN2架構為基礎,實現(xiàn)了點點鼠標、拽一拽關鍵點就能P圖的效果。
具體而言,給定StyleGAN2生成的一張圖像,用戶只需要設置幾個控制點(紅點)和目標點(藍點),以及圈出將要移動的區(qū)域(比如狗轉頭,就圈狗頭)。
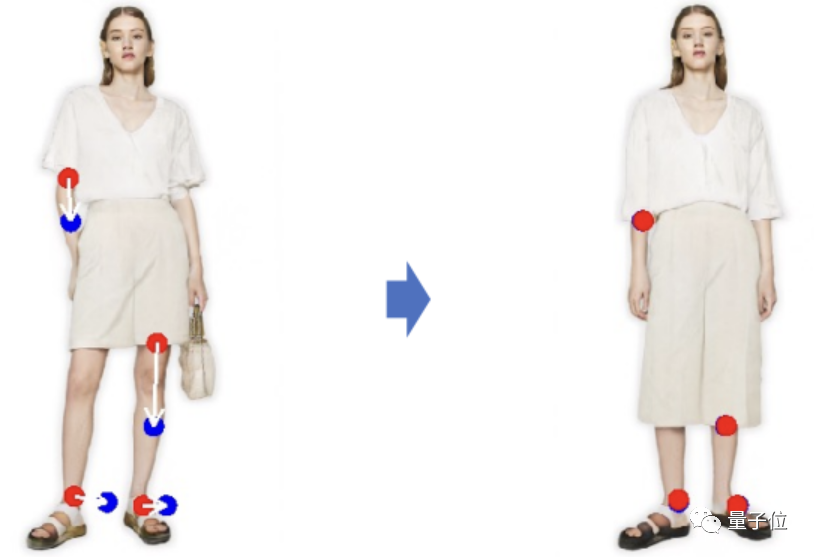
然后模型就將迭代執(zhí)行運動監(jiān)督和點跟蹤這兩個步驟,其中運動監(jiān)督會驅動紅色的控制點向藍色的目標點移動,點跟蹤則用于更新控制點來跟蹤圖像中的被修改對象。
這個過程一直持續(xù)到控制點到達它們對應的目標點。
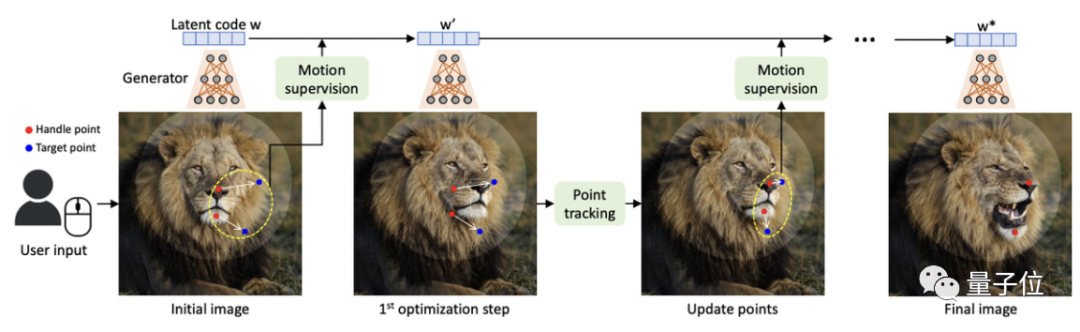
不錯,運動監(jiān)督和點跟蹤就是我們今天要講的重點,它是DragGAN模型中最主要的兩個組件。
先說運動監(jiān)督。在此之前,業(yè)界還沒有太多關于如何監(jiān)督GAN生成圖像的點運動的研究。
在這項研究中,作者提出了一種不依賴于任何額外神經(jīng)網(wǎng)絡的運動監(jiān)督損失(loss)。
其關鍵思想是,生成器的中間特征具有很強的鑒別能力,因此一個簡單的損失就足以監(jiān)督運動。
所以,DragGAN的運動監(jiān)督是通過生成器特征圖上的偏移補丁損失(shifted patch loss)來實現(xiàn)的。
如下圖所示,要移動控制點p到目標點t,就要監(jiān)督p點周圍的一小塊patch(紅圈)向前移動的一小步(藍圈)。
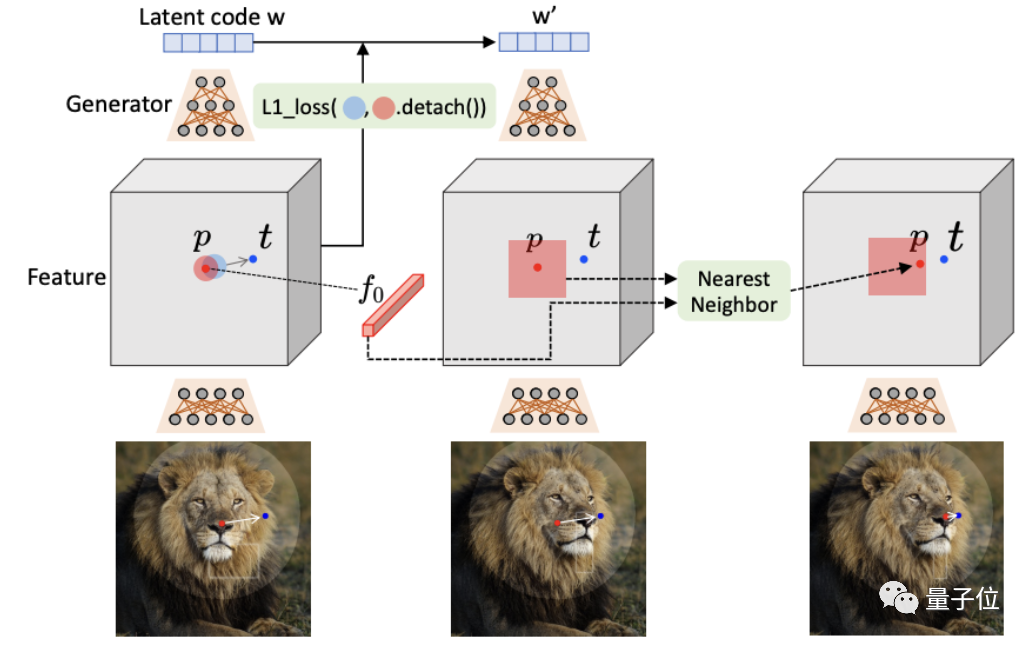
再看點跟蹤。
先前的運動監(jiān)督會產(chǎn)生一個新的latent code、一個新特征圖和新圖像。
由于運動監(jiān)督步驟不容易提供控制點的精確新位置,因此我們的目標是更新每個手柄點p使其跟蹤上對象上的對應點。
此前,點跟蹤通常通過光流估計模型或粒子視頻方法實現(xiàn)。
但同樣,這些額外的模型可能會嚴重影響效率,并且在GAN模型中存在偽影的情況下可能使模型遭受累積誤差。
因此,作者提供了一種新方法,該方法通過最近鄰檢索在相同的特征空間上進行點跟蹤。
而這主要是因為GAN模型的判別特征可以很好地捕捉到密集對應關系。
基于這以上兩大組件,DragGAN就能通過精確控制像素的位置,來操縱不同類別的對象完成姿勢、形狀、布局等方面的變形。
作者表示,由于這些變形都是在GAN學習的圖像流形上進行的,它遵從底層的目標結構,因此面對一些復雜的任務(比如有遮擋),DragGAN也能產(chǎn)生逼真的輸出。
單張3090幾秒鐘出圖
所以,要實現(xiàn)幾秒鐘“精準控圖”的效果,是否需要巨大的算力?
nonono。大部分情況下,每一步拖拽修圖,單張RTX 3090 GPU在數(shù)秒鐘內(nèi)就能搞定。

具體到生成圖像的效果上,實際評估(均方誤差MSE、感知損失LPIPS)也超越了一系列類似的“AI修圖”模型,包括RAFT和PIPs等等:
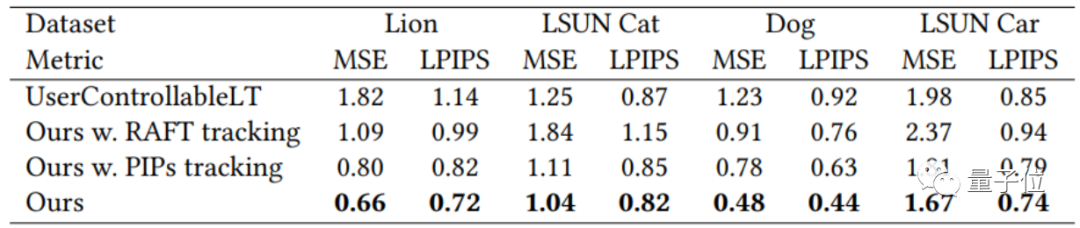
如果說文字的還不太直觀,具體到視覺效果上就能感受到差異了:

值得一提的是,DragGAN的“潛力”還不止于此。
一方面,如果增加關鍵點的數(shù)量,還能實現(xiàn)更加精細的AI修圖效果,用在人臉這類對修圖要求比較嚴格的照片上,也是完全沒問題:

另一方面,不止開頭展示的人物和動物,放在汽車、細胞、風景和天氣等不同類型的圖像上,DragGAN也都能精修搞定。

除了不同的照片類型,從站到坐、從直立到跑步、從跨站到并腿站立這種姿勢變動較大的圖像,也能通過DragGAN實現(xiàn):

也難怪網(wǎng)友會調(diào)侃“遠古的PS段子成真”,把大象轉個身這種甲方需求也能實現(xiàn)了。

不過,也有網(wǎng)友指出了DragGAN目前面臨的一些問題。
例如,由于它是基于StyleGAN2生成的圖像進行P圖的,而后者訓練成本很高,因此距離真正商業(yè)落地可能還有一段距離。

除此之外,在論文中提到的“單卡幾秒鐘修圖”的效果,主要還是基于256×256分辨率圖像:

至于模型是否能擴展到256×256以外圖像,生成的效果又是如何,都還是未知數(shù)。
有網(wǎng)友表示“至少高分辨率圖像從生成時間來看,肯定還要更長”。
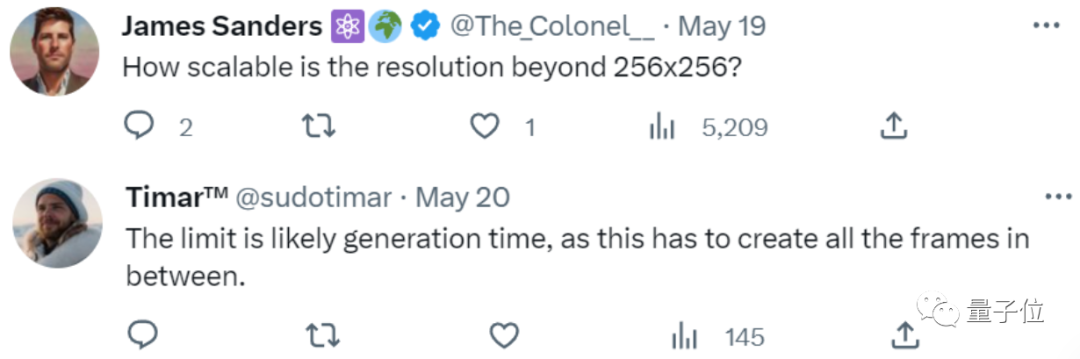
實際上手的效果究竟如何,我們可以等6月論文代碼開源后,一測見真章。
團隊介紹
DragGAN的作者一共6位,分別來自馬克斯?普朗克計算機科學研究,薩爾布呂肯視覺計算、交互與AI研究中心,MIT,賓夕法尼亞大學和谷歌AR/VR部門。

其中包括兩位華人:
一作潘新鋼,他本科畢業(yè)于清華大學(2016年),博士畢業(yè)于香港中文大學(2021年),師從湯曉鷗教授。
現(xiàn)在是馬普計算機科學研究所的博士后,今年6月,他將進入南洋理工大學擔任助理教授(正在招收博士學生)。

另一位是Liu Lingjie,香港大學博士畢業(yè)(2019年),后在馬普信息學研究所做博士后研究,現(xiàn)在是賓夕法尼亞大學助理教授(也在招學生),領導該校計算機圖形實驗室,也是通用機器人、自動化、傳感與感知 (GRASP)實驗室成員。

值得一提的是,為了展示DragGAN的可控性,一作還親自上陣,演示了生發(fā)、瘦臉和露齒笑的三連P圖效果:

是時候給自己的主頁照片“修修圖”了(手動狗頭)。
審核編輯 :李倩
-
AI
+關注
關注
87文章
30172瀏覽量
268434 -
GaN
+關注
關注
19文章
1919瀏覽量
73010 -
GitHub
+關注
關注
3文章
466瀏覽量
16387
原文標題:讓GAN再次偉大!拽一拽關鍵點就能讓獅子張嘴&大象轉身,DragGAN爆火
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
能力再次提升! 迅為RK3588/RK3568開發(fā)板&核心板新增定制分區(qū)鏡像

北美運營商AT&amp;amp;T認證的費用受哪些因素影響

onsemi LV/MV MOSFET 產(chǎn)品介紹 &amp;amp; 行業(yè)應用

【直播預告】ADI &amp;amp; WT·世健MCU痛點問題探索季:MCU應用難題全力擊破!

從邊緣到云端,合宙DTU&amp;amp;RTU打造無縫物聯(lián)網(wǎng)解決方案
Allegro X 23.11 版本更新 I PCB 設計:一鍵移除評審內(nèi)容 &amp;amp; 導入ODB++

FS201資料(pcb &amp; DEMO &amp; 原理圖)
北美運營商AT&amp;amp;T認證入庫產(chǎn)品范圍名單相關

室外抗拉防拽鎧裝單模光纜4芯詳情介紹
解讀北美運營商,AT&amp;amp;T的認證分類與認證內(nèi)容分享
國顯科技榮獲“深圳知名品牌&amp;amp;灣區(qū)知名品牌”

Open RAN的未來及其對AT&amp;T的意義

電機不跳閘,還有電流是為什么?
開關模式下的電源電流如何檢測?這12個電路&amp;10個知識點講明白了





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論