") 使用可計算SSD加速云原生數(shù)據(jù)庫
使用可計算SSD加速云原生數(shù)據(jù)庫
背景
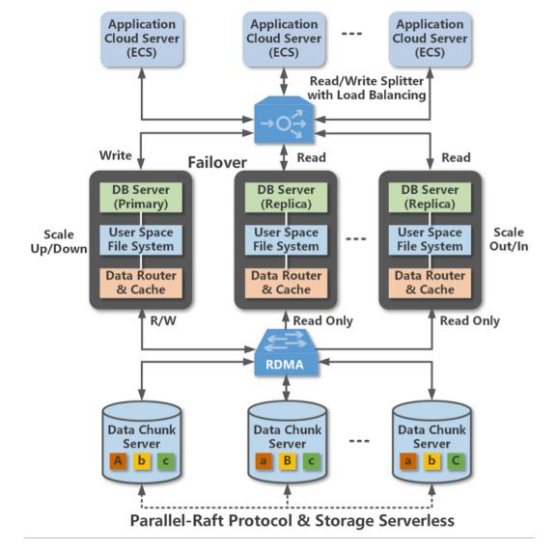
PolarDB是阿里云設(shè)計的云原生OLTP數(shù)據(jù)庫,每個數(shù)據(jù)庫實例由多個數(shù)據(jù)庫節(jié)點和存儲節(jié)點組成,節(jié)點間通過高速RDMA網(wǎng)絡(luò)連接在一起。為了保證原子性,每個POLARDB實例同時僅允許一個數(shù)據(jù)庫節(jié)點處理寫請求,且通過Parallel-Raft協(xié)議在寫入時同時向存儲節(jié)點寫入3個副本。
計算存儲設(shè)備CSD是在具備基本存儲功能同時具備數(shù)據(jù)處理能力的存儲設(shè)備,相比使用CPU處理的模型,CSD采用的異構(gòu)計算架構(gòu)可以達到更好的性能和效率。但是CSD同時存在硬件成本更高、實際部署適配開發(fā)成本更高等問題。
動機
當(dāng)前的POLARDB在數(shù)據(jù)庫節(jié)點中處理表掃描任務(wù),將掃操作下移到存儲節(jié)點可以更好提升數(shù)據(jù)庫處理分析型負(fù)載的性能、降低網(wǎng)絡(luò)流量,而列存儲需要掃描時更高的數(shù)據(jù)處理能力。
關(guān)鍵在于如何擴展存儲節(jié)點使之支持處理額外的掃描任務(wù)。第一種方法是擴展存儲節(jié)點的CPU,然而這會帶來過高的成本問題;第二種方法是使用PCIe卡模式的FPGA擴展,但是這種方式同樣存在:掃描作為數(shù)據(jù)密集型負(fù)載帶來的數(shù)據(jù)傳輸流量過高導(dǎo)致的高功耗、負(fù)載間沖突,以及PCIe擴展卡帶寬瓶頸等問題。最后一種是本文提出方式,即分布式異構(gòu)架構(gòu),將表scan操作分散到每個存儲設(shè)備中,由此帶來的挑戰(zhàn)包括:如何修改整個軟件存儲站以支持掃描操作下移;和如何降低FPGA的成本、提高FPGA并行性。
方法
本文首先解決了如何實現(xiàn)跨軟件棧的掃描下移工作,包括了POLARDB的存儲引擎、下層的分布式文件系統(tǒng)POLARFS以及可計算存儲器CSD。
首先作者講解了如何擴展POLARDB存儲引擎,使得存儲引擎可以將掃描任務(wù)傳遞給下層的POALRFS,并負(fù)責(zé)回收CSD返回的掃描結(jié)果,掃描任務(wù)的參數(shù)包括:被掃描數(shù)據(jù)的位置、被掃描表的結(jié)構(gòu)以及掃描的條件。由于CSD難以支持所有的掃描條件(如LIKE),因此POLARDB的存儲引擎在收到掃描請求時需要首先分析掃描條件,并將CSD可以處理的條件子集傳遞下去,并在收到CSD的結(jié)果后進行二次檢查。
接著作者描述了如何擴展作為存儲底層的分布式文件系統(tǒng)POLARFS,POLARFS負(fù)責(zé)管理所有存儲節(jié)點上的數(shù)據(jù)。為了盡可能讓文件的大部分?jǐn)?shù)據(jù)塊落在同一個CSD上,POLARFS采用了大粒度(4MB)條帶,當(dāng)出現(xiàn)極少數(shù)的一個壓縮條帶橫跨兩個CSD時,存儲節(jié)點采用CPU處理對應(yīng)的scan操作。在傳遞scan請求時,POLARDB存儲引擎?zhèn)鬟f給POLARFS的是文件偏移表示的被掃描數(shù)據(jù)位置,而CSD僅能定位以LBA形式的數(shù)據(jù)位置,因此,POLARFS在收到POLARDB存儲引擎的掃描請求書,會將橫跨m個CSD的請求分割成m個掃描請求,并將掃描請求中的偏移轉(zhuǎn)換到CSD的LBA。
之后作者描述了如何擴展CSD功能。CSD通過內(nèi)核空間的驅(qū)動進行管理,每個CSD都暴露為一個塊設(shè)備。驅(qū)動將收到的POLARFS轉(zhuǎn)發(fā)的掃描請求分割成多個子任務(wù),以解決大掃描任務(wù)長期占據(jù)NAND帶寬,影響普通IO請求延遲性能的問題。同時,子任務(wù)有助于降低硬件資源的使用率,提高NAND訪問的并行性,同時降低后臺GC可能的過高延遲。
為了更好的降低成本,作者修改了POLARDB存儲的數(shù)據(jù)塊格式,以充分利用FPGA實現(xiàn)掃描功能。增加了1字節(jié)壓縮類型,4字節(jié)的鍵值對數(shù)量和restarts鍵數(shù)量,這樣使得CSD不需要POLARDB存儲引擎?zhèn)鬟f塊大小即可直接解壓,同時可以高效處理restarts,并探測塊結(jié)束情況。
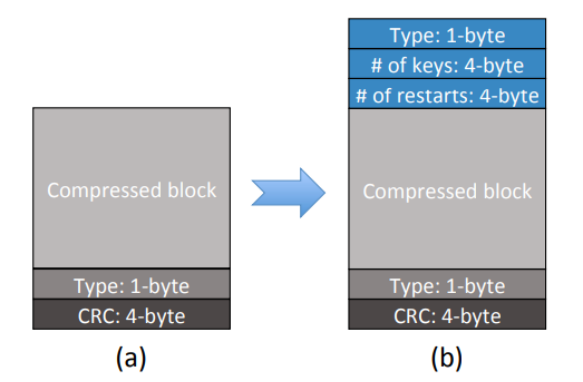
由于FPGA難以實現(xiàn)多類型比較器,因此作者進一步修改POLARDB存儲引擎,將所有數(shù)據(jù)都存儲成同一的可比較格式,這樣CSD只需要實現(xiàn)單一類型比較器,有助于降低FPGA資源開銷。
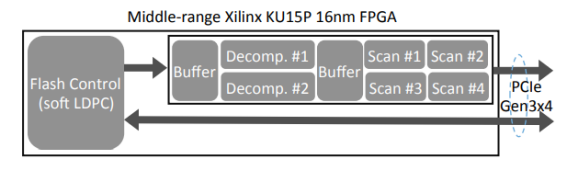
在實現(xiàn)時,作者采用了終端的FPGA同時用作閃存管理和存儲計算單元,集成了軟LDPC編碼器,因此可以使用低成本的3D TLC/QLC以降低成本。作者使用FPGA實現(xiàn)了2個數(shù)據(jù)解壓引擎和3個數(shù)據(jù)掃描引擎,支持 支持Snappy解壓和=, ≠、>、≥、<、≤、NULL和!NULL條件。
評估
為了實際可用,CSD需要在滿足存儲計算的同時提供一流的IO性能,因此作者使用64層3D-TLC閃存,并支持了PCIe GEN3x4接口,達到了3.0GB/s和2.2GB/s的順序讀、寫帶寬,并做到在滿盤、GC觸發(fā)時590K/160K的4K隨機讀、寫IOPS。在解壓性能上,CSD的兩個解壓引擎實現(xiàn)了在60%和30%壓縮率下,2.3GB/s和2.8GB/s的總解壓吞吐量。
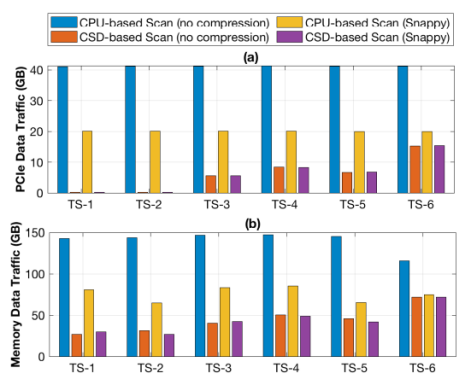
在使用TPC-H基準(zhǔn)測試的LINEITEM表作為測試負(fù)載測試下,作者分別對比了下移掃描任務(wù)前后整體的掃描延遲和PCIe數(shù)據(jù)流量。對比項共有4個,分別是基于CPU、不進行壓縮的掃描下移;基于CSD,無壓縮的掃描下移;基于CPU有Snappy壓縮的掃描下移以及基于CSD、有Snappy壓縮的掃描下移。測試結(jié)果表明:相對于基于CPU的掃描下移,CSD將平均掃描延遲從55s降低到39s,同時CPU占用率從514%降低到140%,收益最低的TS-6測試項中,延遲依然從65s下降到53s,同時CPU利用率從558%降低到374%。測試同時發(fā)現(xiàn),基于CSD的負(fù)載中,CPU負(fù)載與數(shù)據(jù)選擇性正相關(guān),即傳輸?shù)紺PU的數(shù)據(jù)越少,CPU負(fù)載越低,而基于CPU的掃描則與數(shù)據(jù)選擇性無關(guān)。這說明基于CSD的掃描效率更高,且效率隨著CSD規(guī)模增加可以擴展。
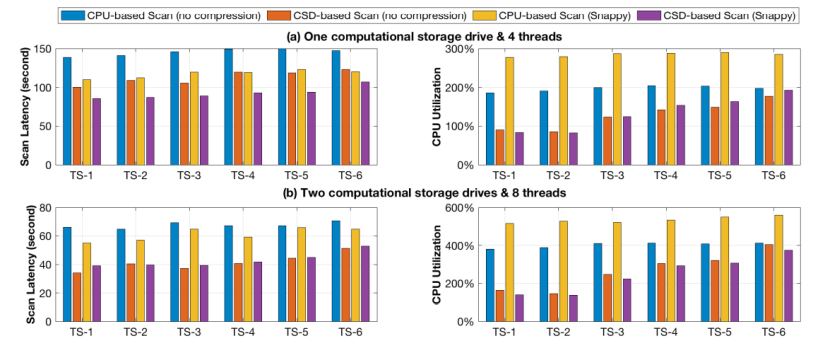
而從PCIe流量對比中可以發(fā)現(xiàn),CSD的數(shù)據(jù)移動量更少,因此額外功耗更低。
之后作者進行了系統(tǒng)級評估,在POLARDB的云實例上運行TPC-H負(fù)載進行測試。每個實例運行32個SQL引擎容器,分布在7個數(shù)據(jù)庫節(jié)點和3個后端存儲節(jié)點上,每個存儲節(jié)點包括12個3.7TB的CSD。分別考慮3個場景:1. 基準(zhǔn)場景,即所有數(shù)據(jù)由存儲節(jié)點傳輸?shù)綌?shù)據(jù)庫節(jié)點進行處理;2. 基于CPU的下移場景,即掃描任務(wù)下移到存儲節(jié)點的CPU上;3. 基于CSD的下移場景,即掃描任務(wù)下移到CSD上。
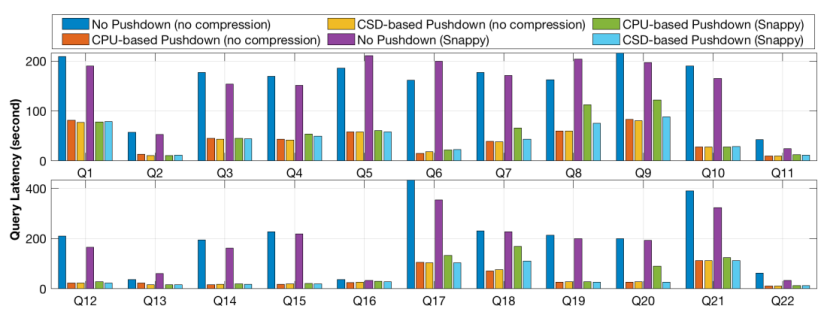
測試結(jié)果表明,隨著請求數(shù)量增加,基于CSD的下移相比基于CPU的下移帶來更多的延遲性能提升,這是由于隨著并行請求數(shù)量增長,每個存儲節(jié)點有更多的并行掃描任務(wù),更利于硬件并行化;另外,基于CSD的下移在表進行壓縮時表現(xiàn)出更高的性能提升,這是由于基于CPU的下移需要更多資源進行解壓。
流量測試結(jié)果表明,基于CSD的掃描下移相比與基于CPU的掃描下移,在7個TPC-H并行查詢時可以降低50%的PCIe流量,最大PCIe傳輸流量降低了97%,而12個并行TPC-H查詢的網(wǎng)絡(luò)總流量降低了70%。
總結(jié)
本文報告了跨軟-硬件協(xié)同的阿里云關(guān)系型數(shù)據(jù)庫POLARDBDA設(shè)計優(yōu)化,以更高效處理分析型負(fù)載。其基本思想是將高開銷的表掃描操作分發(fā)到CSD中,核心思想簡單且與當(dāng)前異構(gòu)計算的工業(yè)趨勢吻合。測試結(jié)果表明本文的設(shè)計在查詢測試中可以獲得超過30%的延遲性能提升,同時減少50%的存儲-內(nèi)存數(shù)據(jù)移動。作者表示,希望本工作可以激勵更多關(guān)于如何在云基礎(chǔ)設(shè)施更好利用CSD的探索。
The End
致謝
感謝本次論文解讀者,來自華東師范大學(xué)的碩士生黃奕陽,主要研究方向為存儲壓縮、存儲計算。
審核編輯:湯梓紅
-
存儲
+關(guān)注
關(guān)注
13文章
4127瀏覽量
85286 -
SSD
+關(guān)注
關(guān)注
20文章
2791瀏覽量
116669 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3712瀏覽量
64030 -
阿里云
+關(guān)注
關(guān)注
3文章
923瀏覽量
42780 -
云原生
+關(guān)注
關(guān)注
0文章
238瀏覽量
7919
原文標(biāo)題:使用可計算SSD加速云原生數(shù)據(jù)庫
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
ICDE:POLARDB定義云原生數(shù)據(jù)庫
直擊DTCC2018 阿里數(shù)據(jù)庫技術(shù)干貨全面解析
數(shù)據(jù)庫廠商都怕低價競爭?阿里云說并不可懼
重新定義數(shù)據(jù)庫的時刻,阿里云數(shù)據(jù)庫專家?guī)懔私釶OLARDB
云棲干貨回顧 | 云原生數(shù)據(jù)庫POLARDB專場“硬核”解析
性能提升1倍,成本直降50%!基于龍蜥指令加速的下一代云原生網(wǎng)關(guān)
企業(yè)如何選擇云計算數(shù)據(jù)庫?
OLAP數(shù)據(jù)庫將全面地進入云原生時代,實現(xiàn)會數(shù)據(jù)庫就會大數(shù)據(jù)
阿里云PolarDB數(shù)據(jù)庫將云原生進行到底!業(yè)內(nèi)首次實現(xiàn)三層池化

NVIDIA引入云原生超級計算架構(gòu)
華為云云原生數(shù)據(jù)庫,激發(fā)數(shù)據(jù)活力
深耕數(shù)據(jù)庫根技術(shù),華為云云原生數(shù)據(jù)庫推動汽車產(chǎn)業(yè)數(shù)智升級

云原生數(shù)據(jù)庫GaiaDB架構(gòu)設(shè)計解析
華為云原生多模數(shù)據(jù)庫 GeminiDB 架構(gòu)與應(yīng)用實踐

- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論