") 以Gpipe作為流水線并行的范例進行介紹
以Gpipe作為流水線并行的范例進行介紹
回顧ChatGPT的發(fā)展歷程,我們可以總結(jié)出大語言模型(LLM)取得驚艷效果的要點(重要性從高到低排序):
愿意燒錢,且接受“燒錢 != 好模型”的現(xiàn)實
高質(zhì)量的訓練語料
高效的分布式訓練框架和充沛優(yōu)質(zhì)的硬件資源
算法的迭代創(chuàng)新
在大模型訓練這個系列里,我們將一起探索學習幾種經(jīng)典的分布式并行范式,包括流水線并行(Pipeline Parallelism),數(shù)據(jù)并行(Data Parallelism)和張量并行(Tensor Parallesim)。微軟開源的分布式訓練框架FastSpeed,融合了這三種并行范式,開發(fā)出3D并行的框架,實現(xiàn)了千億級別模型參數(shù)的訓練。
本篇文章將探索流水線并行,經(jīng)典的流水線并行范式有Google推出的Gpipe,和微軟推出的PipeDream。兩者的推出時間都在2019年左右,大體設(shè)計框架一致。主要差別為:在梯度更新上,Gpipe是同步的,PipeDream是異步的。異步方法更進一步降低了GPU的空轉(zhuǎn)時間比。雖然PipeDream設(shè)計更精妙些,但是Gpipe因為其“夠用”和淺顯易懂,更受大眾歡迎(torch的PP接口就基于Gpipe)。因此本文以Gpipe作為流水線并行的范例進行介紹。內(nèi)容包括:
1、優(yōu)化目標
2、模型并行
3、流水線并行
切分micro-batch
Re-materialization (active checkpoint)
4、實驗效果
推薦閱讀: ChatGPT技術(shù)解析系列之:訓練框架InstructGPT ChatGPT技術(shù)解析系列之:GPT1、GPT2與GPT3 ChatGPT技術(shù)解析系列之:賦予GPT寫代碼能力的Codex
一、優(yōu)化目標
當你從單卡窮人變成多卡富翁時,你做分布式訓練的總體目標是什么呢?(雖然手握一張A100怎么能是窮呢)
能訓練更大的模型。理想狀況下,模型的大小和GPU的數(shù)量成線性關(guān)系。即GPU量提升x倍,模型大小也能提升x倍。
能更快地訓練模型。理想狀況下,訓練的速度和GPU的數(shù)量成線性關(guān)系。即GPU量提升x倍,訓練速度也能提升x倍。
這是目標,也是難點,難在于:
訓練更大的模型時,每塊GPU里不僅要存模型參數(shù),還要存中間結(jié)果(用來做Backward)。而更大的模型意味著需要更多的訓練數(shù)據(jù),進一步提高了中間結(jié)果的大小。加重了每塊GPU的內(nèi)存壓力。我們將在下文詳細分析這一點。(對應著GPU中的內(nèi)存限制)
網(wǎng)絡(luò)通訊開銷。數(shù)據(jù)在卡之間進行傳輸,是需要通訊時間的。不做設(shè)計的話,這個通訊時間可能會抹平多卡本身帶來的訓練速度提升。(對應著GPU間的帶寬限制)
明確這兩個訓練目標后,我們來看并行范式的設(shè)計者,是如何在現(xiàn)有硬件限制的條件下,完成這兩個目標的。
二、模型并行
當你有一個單卡裝不下的大模型時,一個直接的解決辦法是,把模型隔成不同的層,每一層都放到一塊GPU上,如下圖:
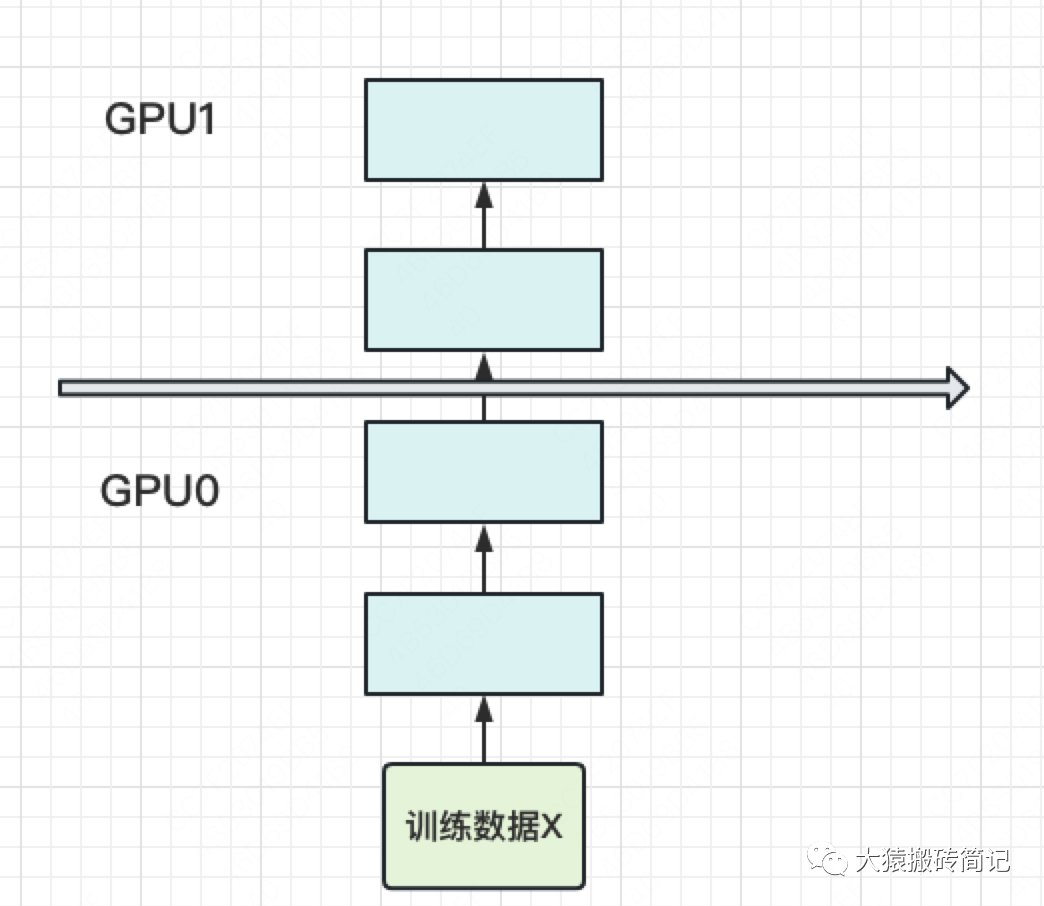
此時,模型做一輪forward和backward的過程如下
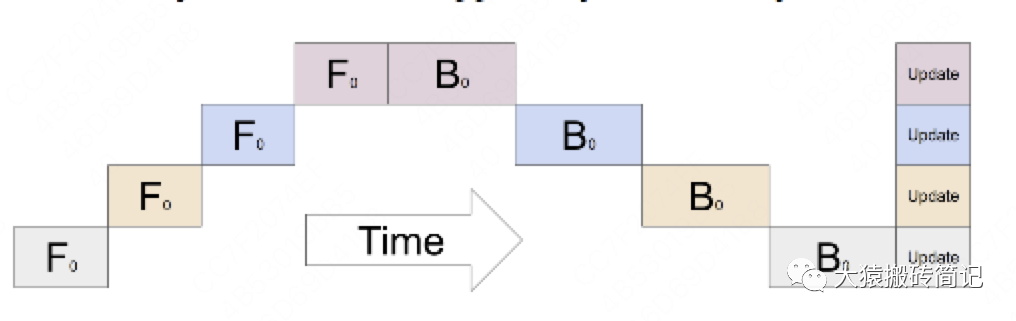
其中下標表示GPU編號,例如表示在GPU0上做foward,表示在GPU0上做backward。圖中的橫軸表示timestep。
這張圖的含義是:我在GPU0上做完一次forward,然后將GPU0上最后一層的輸入傳給GPU1,繼續(xù)做forward,直到四塊GPU都做完forward后,我再依次做backward。等把四塊GPU上的backward全部做完后,最后一個時刻我統(tǒng)一更新每一層的梯度。
這樣做確實能訓更大的模型了,但也帶來了兩個問題:
(1)GPU利用度不夠。
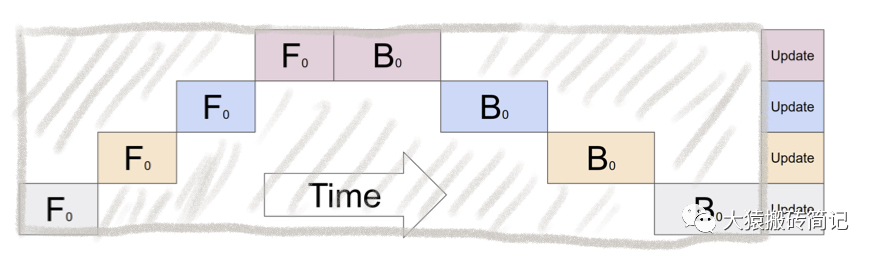
如圖,陰影部分所表示的時間段里,總有GPU在空轉(zhuǎn)。在Gpipe中,將陰影部分定義為bubble。我們來計算一下bubble。假設(shè)有塊GPU,而單塊GPU上做一次forward和backward的時間為:。則:
圖中灰色長方形的整體面積為:(寬=,長=)
圖中實際在做forward和backward的面積為:
圖中陰影部分的面積為:
圖像陰影部分的占比為:
則我們定義出bubble部分的時間復雜度為:,當K越大,即GPU的數(shù)量越多時,空置的比例接近1,即GPU的資源都被浪費掉了。因此這個問題肯定需要解決。
(2)中間結(jié)果占據(jù)大量內(nèi)存
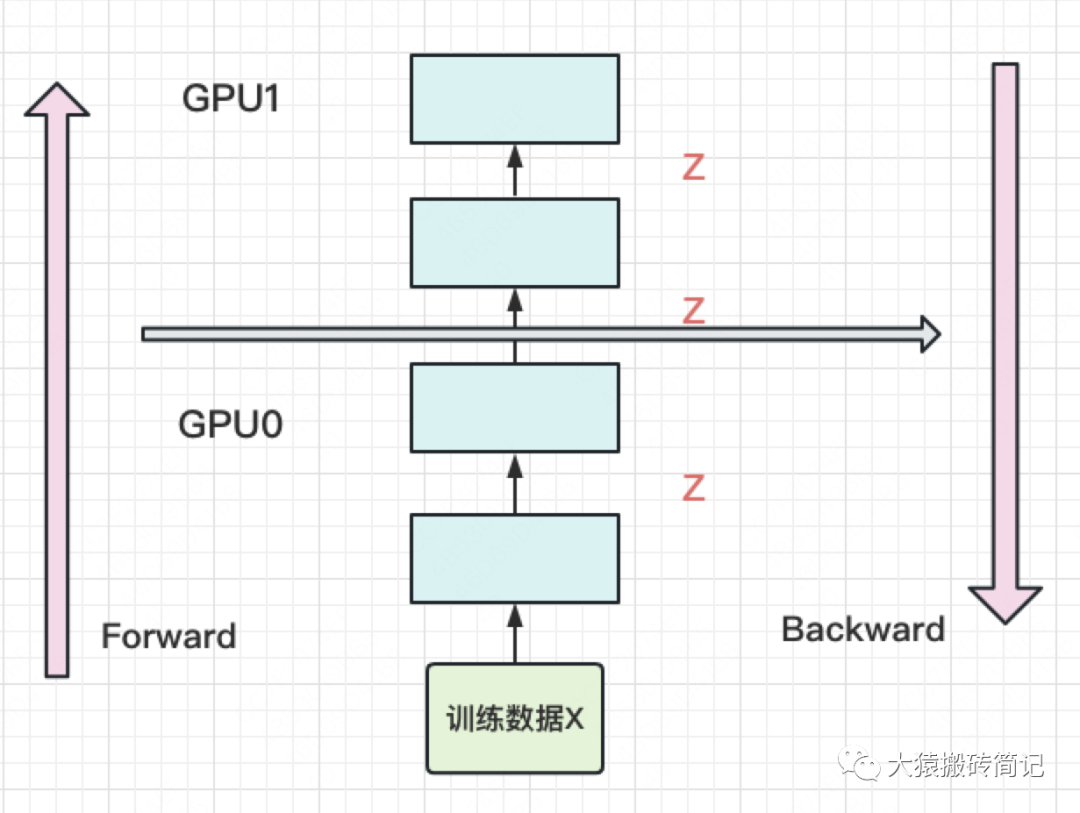
在做backward計算梯度的過程中,我們需要用到每一層的中間結(jié)果z。假設(shè)我們的模型有L層,每一層的寬度為d,則對于每塊GPU,不考慮其參數(shù)本身的存儲,額外的空間復雜度為。從這個復雜度可以看出,隨著模型的增大,N,L,d三者的增加可能會平滑掉K增加帶來的GPU內(nèi)存收益。因此,這也是需要優(yōu)化的地方。
三、訓練數(shù)據(jù)與訓練方法
樸素的模型并行存在GPU利用度不足,中間結(jié)果消耗內(nèi)存大的問題。而Gpipe提出的流水線并行,就是用來解決這兩個主要問題的。
3.1 切分micro-batch
流水線并行的核心思想是:在模型并行的基礎(chǔ)上,進一步引入數(shù)據(jù)并行的辦法,即把原先的數(shù)據(jù)再劃分成若干個batch,送入GPU進行訓練。未劃分前的數(shù)據(jù),叫mini-batch。在mini-batch上再劃分的數(shù)據(jù),叫micro-batch。
圖例如下:
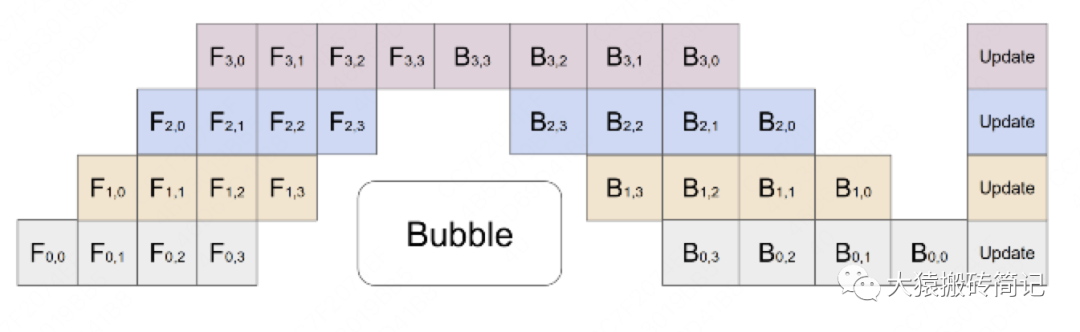
其中,第一個下標表示GPU編號,第二個下標表示micro-batch編號。假設(shè)我們將mini-batch劃分為M個,則流水線并行下,bubble的時間復雜度為(推導過程略,可參照第二部分的bubble推導流程)。Gpipe通過實驗證明,當$M>=4K時,bubble產(chǎn)生的空轉(zhuǎn)時間占比對最終訓練時長影響是微小的,可以忽略不計。
將batch切好,并逐一送入GPU的過程,就像一個流水生產(chǎn)線一樣(類似于CPU里的流水線),因此也被稱為Pipeline Parallelism。
3.2 re-materialization(active checkpoint)
解決了GPU的空置問題,提升了GPU計算的整體效率。接下來,就要解決GPU的內(nèi)存問題了。
前文說過,隨著模型的增加,每塊GPU中存儲的中間結(jié)果也會越大。對此,Gpipe采用了一種非常簡單粗暴但有效的辦法:用時間換空間,在論文里,這種方法被命名為re-materalization,后人也稱其為active checkpoint。
具體來說,就是幾乎不存中間結(jié)果,等到backward的時候,再重新算一遍forward,圖例如下:
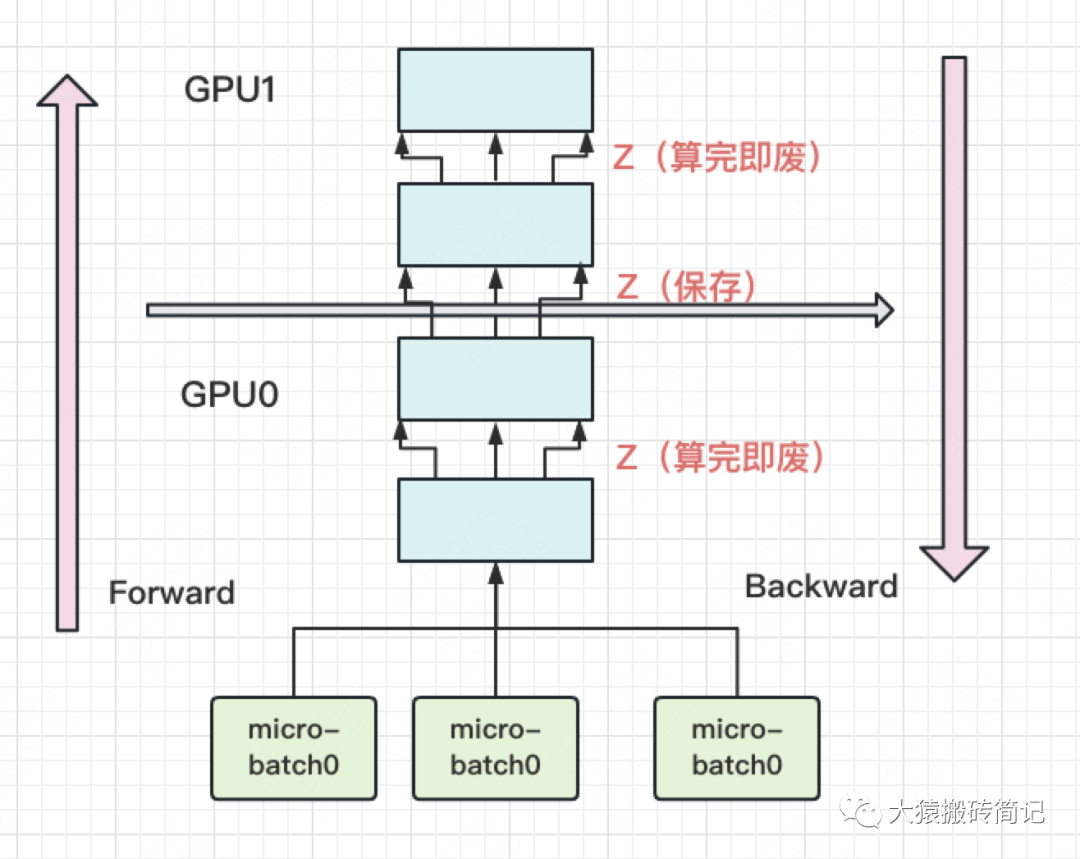
每塊GPU上,我們只保存來自上一塊的最后一層輸入z,其余的中間結(jié)果我們算完就廢。等到backward的時候再由保存下來的z重新進行forward來算出。
現(xiàn)在我們來計算每塊GPU峰值時刻的內(nèi)存:
每塊GPU峰值時刻存儲大小 = 每塊GPU上的輸入數(shù)據(jù)大小 + 每塊GPU在forward過程中的中間結(jié)果大小
每塊GPU上固定需要保存它的起始輸入,我們記起始輸入為(即mini-batch的大小)。
每個micro-batch是流水線形式進來的,算完一個micro-batch才算下一個。在計算一個micro-batch的過程中,我們會產(chǎn)生中間變量,它的大小為(其中M為micro-batch個數(shù))。
因此,每塊GPU峰值時刻的空間復雜度為
將其與樸素模型并行中的GPU空間復雜度比較,可以發(fā)現(xiàn),由于采用了micro-batch的方法,當L變大時,流水線并行相比于樸素模型并行,對GPU內(nèi)存的壓力顯著減小。
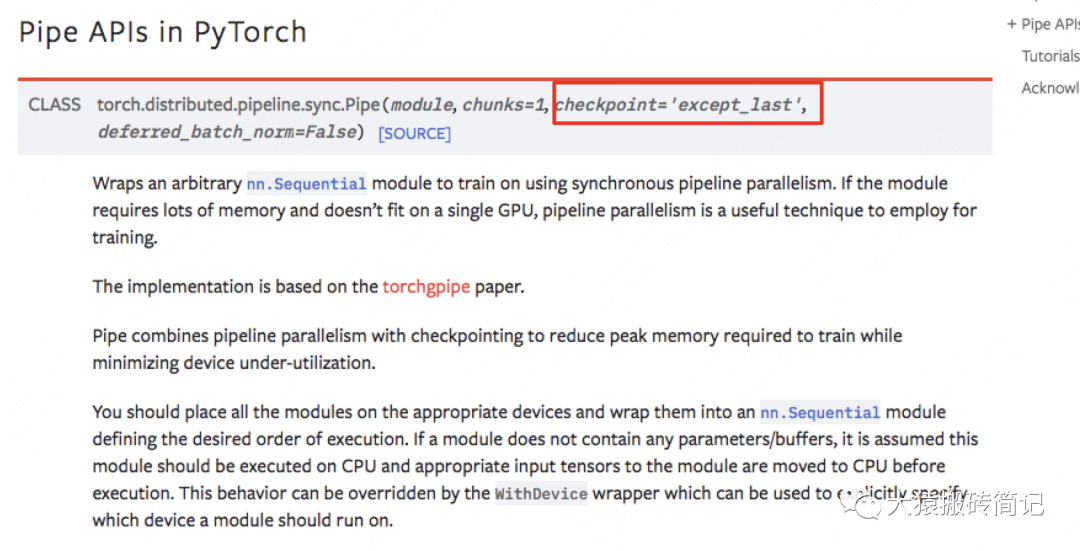
如果你使用Pytorch提供的PP接口,其中有一個參數(shù)叫checkpoint,就是用來做這一項的。
最后,再提一點,在micro-batch的劃分下,我們在計算Batch Normalization時會有影響。Gpipe的方法是,在訓練時計算和運用的是micro-batch里的均值和方差,但同時持續(xù)追蹤全部mini-batch的移動平均和方差,以便在測試階段進行使用。Layer Normalization則不受影響。
四、實驗效果
回顧第二部分的兩個目標,Gpipe真的實現(xiàn)了嗎?如果實現(xiàn)不了,又是因為什么原因呢?我們來看下實驗效果。
4.1 GPU數(shù)量 VS 模型大小
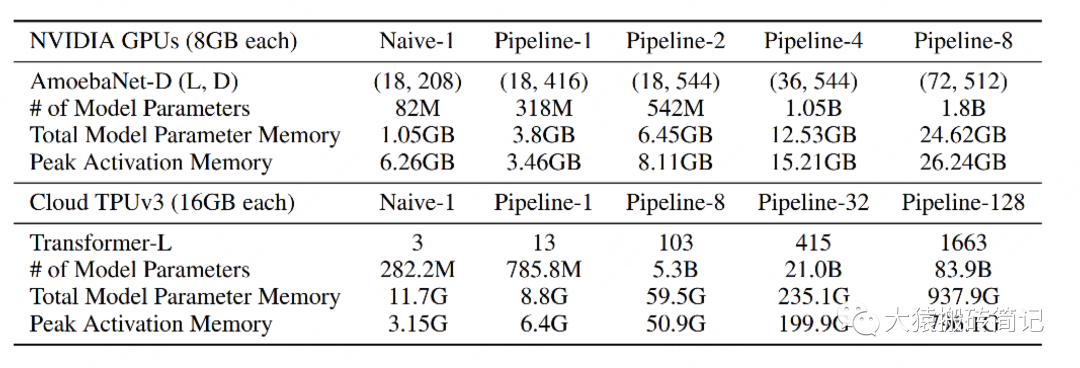
Gpipe分別在AmoebaNet(圖像)和Transformer(自然語言)兩個大模型上做了實驗。
Naive表示單卡
Pipeline-N表示re-materalization + N卡。
AmeobaNet-D和Trasformer-L一行表示超參數(shù)的量
of Model Parameter表示模型的參數(shù)量
Total Model Parameter Memory表示模型參數(shù)所占內(nèi)存大小
Peak Activation Memory表示峰值時中間結(jié)果大小。可以發(fā)現(xiàn),中間結(jié)果占據(jù)的內(nèi)存大小是相當可觀的。
從實驗結(jié)果里,我們可以發(fā)現(xiàn):
在Transformer上,Gpipe基本實現(xiàn)了模型大小(參數(shù)量)和GPU個數(shù)之間的線性關(guān)系。例如從32卡增到128卡時,模型的大小也從21.08B增加到82.9B,約擴4倍
對AmoebaNet而言,卻沒有完全實現(xiàn)線性增長。例如從4卡到8卡,模型大小從1.05B到1.8B,不滿足2倍的關(guān)系。本質(zhì)原因是AmoebaNet模型在切割時,沒有辦法像Transformer一樣切得勻稱,保證每一塊GPU上的內(nèi)存使用率是差不多的。因此對于AmoebaNet,當GPU個數(shù)上升時,某一塊GPU可能成為木桶的短板。
GPU數(shù)量 VS 訓練速度
(1)關(guān)掉NVlinks
為了驗證Gpipe框架帶來的收益,實驗中關(guān)掉了NVlinks(GPU間快速通信的橋梁。估計是通過強迫GPU先連CPU然后再連別的GPU做到的)。關(guān)掉的意義在于說明,不靠硬件本身的高效通訊帶來的收益,Gpipe一樣能做的很好。實驗效果如下:
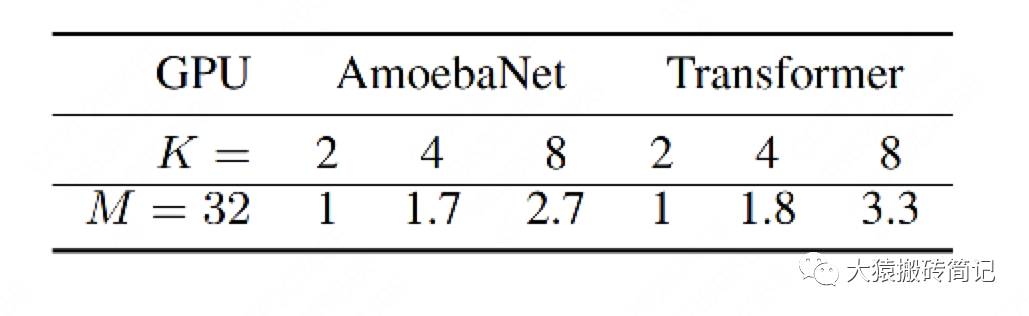
M=32表示micro-batch的數(shù)量為32,K表示GPU數(shù)量。從實驗結(jié)果可知,在關(guān)掉NVlinks的情況下,Gpipe一樣也能實現(xiàn)隨著GPU數(shù)量的增加,訓練速度也增加的效果。雖然這兩者間不是線性的。同樣,因為模型切割不均的原因,AmoebaNet的表現(xiàn)不如Transformer。
(2)開啟NVlinks,并尋找最佳M
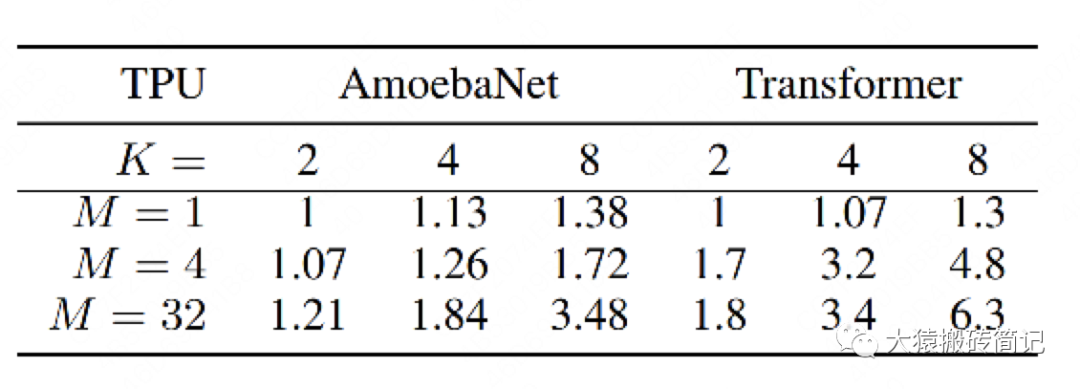
當重新開啟NVlinks后,我們來看M的大小(即流水線的核心)對訓練速度的影響。
當M=1的時候,如前文所說,GPU的空置率太高,因此兩個模型都沒有實現(xiàn)訓練速度和GPU個數(shù)間的線性關(guān)系
當M=4時,表現(xiàn)明顯好轉(zhuǎn)。
當M=32時,表現(xiàn)最佳,且Transformer基本實現(xiàn)了訓練速度和GPU個數(shù)的線性關(guān)系。
4.3 Gpipe下時間消耗分布
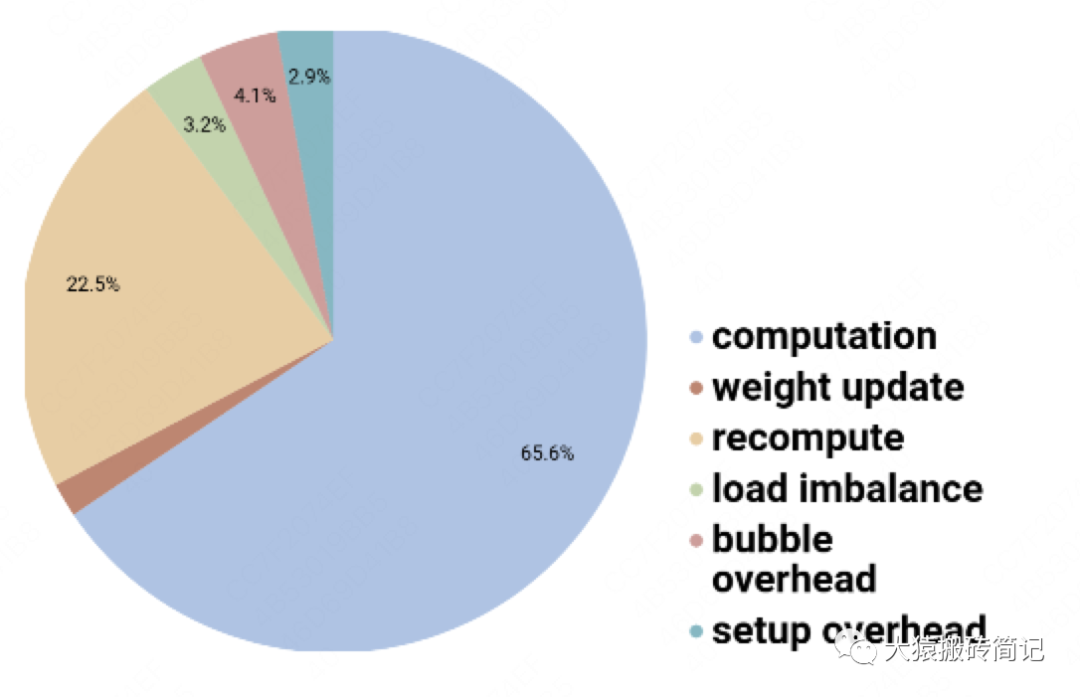
對每塊GPU來說,約2/3的時間,是真正花在計算上的。
其余1/3的時間,大部分花在re-materalization策略下的重計算上。因為采用流水線的方法,bubble的時間也被壓縮到很短,可以忽略不計。
-
3D
+關(guān)注
關(guān)注
9文章
2863瀏覽量
107324 -
開源
+關(guān)注
關(guān)注
3文章
3247瀏覽量
42402 -
語言模型
+關(guān)注
關(guān)注
0文章
506瀏覽量
10245
原文標題:圖解大模型訓練之:流水線并行(Pipeline Parallelism),以GPipe為例
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
FPGA中的流水線設(shè)計
基于流水線技術(shù)的并行高效FIR濾波器設(shè)計
CPU流水線的定義
Verilog基本功之:流水線設(shè)計Pipeline Design
FPGA之為什么要進行流水線的設(shè)計
各種流水線特點及常見流水線設(shè)計方式
如何選擇合適的LED生產(chǎn)流水線輸送方式
嵌入式_流水線

GTC 2023:深度學習之張星并行和流水線并行
什么是流水線 Jenkins的流水線詳解
Google GPipe為代表的流水線并行范式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論