 在一個簡單的Mean Teacher架構中雙向復制粘貼標記和未標記的數據
在一個簡單的Mean Teacher架構中雙向復制粘貼標記和未標記的數據
導讀
在半監督醫學圖像分割中,標記和未標記數據分布之間存在經驗不匹配問題。本文提出了一種簡單的方法來緩解這個問題—在一個簡單的 Mean Teacher 架構中雙向復制粘貼標記和未標記的數據。

Bidirectional Copy-Paste for Semi-Supervised Medical Image Segmentation
論文鏈接:https://arxiv.org/pdf/2305.00673.pdf
源碼鏈接:https://github.com/DeepMed-Lab-ECNU/BCP
簡介
從CT或MRI等醫療圖像中分割內部結構對于許多臨床應用至關重要。已經提出了各種基于監督學習的醫療圖像分割技術,這通常需要大量標注數據。然而由于在標注醫療圖像時手動輪廓繪制過程繁瑣且昂貴,近年來,半監督分割越來越受到關注,并在醫療圖像分析領域變得無處不在。
一般地,在半監督醫療分割領域,標簽數據和無標簽數據從相同分布抽取。但在現實世界中,很難從標記數據中估計準確的分布,因為它們數據很少。因此,在大量未標注數據和極少量標注數據宗師存在經驗分布不匹配。半監督分割方法總是嘗試以一致的方式對稱地訓練標注和未標注數據。例如子訓練生成為標簽,以偽監督方式監督未標注數據。基于Mean Teacher的算法采用一致性損失來監督具有強增強的未標注數據,類似于監督具有GT的標注數據。ContrastMask在標注數據和未標注數據上應用密集對比學習。但是大部分已有的半監督算法在不同學習范式下使用標注和未標注數據。
CutMix是一種簡單但強大的數據處理方法,也被稱為復制黏貼(CP),它有可能鼓勵未標注的數據從標注數據中學習常見的語義,因為同一圖中的像素共享的語義更接近。在半監督學習中,未標注數據的弱-強增強對之間的強制一致性被廣泛使用,并且CP通常被用作強增強。但現有的CP方法未考慮CP較差未標注數據,或者簡單地將標注數據中物體復制為前景并黏貼到另一個數據。它們忽略了為標記數據和未標記數據設計一致的學習策略,這阻礙了其在減少分布差距方面使用。同時,CP試圖通過增加未標注數據的多樣性來增強網絡泛化能力,但由于CutMix圖像僅由低精度偽標簽監督,因此很難實現高性能。
為了緩解標注數據和未標注數據之間經驗不匹配問題,一個成功的設計是鼓勵未標注數據從標注數據中學習全面的公共語義,同時通過對標注數據和未標注數據的一致學習策略來促進分布對齊。本文通過提出一種簡單但非常有效的雙向復制黏貼(BCP)方法實現這一點。該方法在Mean Teacher框架中實例化。具體地,為了訓練學生網絡,本文通過將隨機裁剪從標記圖像(前景)復制黏貼到未標注圖像(背景)來增加輸入。繁殖將隨機裁剪從五標注圖像(前景)復制黏貼到標注圖像(背景)來增加輸入。學生網絡由生成的監督信息通過來自教師網絡的未標注圖像偽標簽和標注圖像的標簽圖之間的雙向復制黏貼進行監督。這兩個混合圖像有助于網絡雙向對稱地學習標注數據和未標注數據間通用語義。
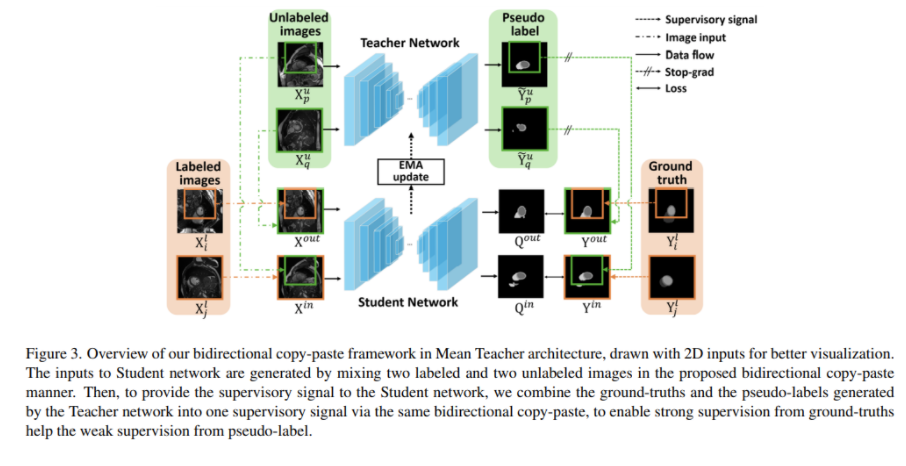
本文方法
定義三維醫療圖像為。醫療圖像半監督語義分割目標是預測每體素標簽映射指示中背景和目標的位置。訓練集包含個標注數據和個未標注數據(),即,,。
在本文的Mean Teacher架構中,隨機選擇兩個未標注圖像,兩個標注圖像。之后從復制黏貼一個隨機塊到生成混合圖像,從到生成另一個混合圖像。無標注圖像能夠從標注圖像中從向內(inward)和向外(outward)方向學習全面的通用語義。圖像和之后傳入學生網絡預測分割掩碼和。通過雙向復制黏貼來自教師網絡的未標注圖像預測和標注圖像標簽圖來監督分割掩碼。
Mean Teacher和訓練策略
在本文BCP框架中,有一個教師網絡和學生網絡。學生網絡由SGD優化,教師網絡是學生網絡的指數移動平均。本文的訓練策略包括三個步驟:首先使用標注數據預訓練一個模型,然后使用預訓練模型作為教師模型為未標注圖像產生偽標簽。在每一個周期,首先使用SGD優化學生網絡參數。最后使用學生參數的指數移動平均更新教師網絡參數。
通過復制-黏貼預訓練
本文對標注數據進行了復制黏貼增廣來訓練監督模型,監督模型在自訓練過程中會為未標注數據生成偽標簽。該策略已被證明能有效提高分割性能。
雙向復制-黏貼
在一堆圖像間執行復制黏貼,首先需要生成零-中心掩碼,指示體素來自前景(0)或背景(1)圖像。零值區域大小為。雙向復制黏貼過程可以描述為:
雙向復制黏貼監督信號
為了訓練學生網絡,監督信號也是由BCP操作產生。無標注的圖像和傳入教師網絡,計算概率圖:
初始的偽標簽由一個通常的二值化分割任務的閾值0.5決定,或者多標簽分割任務使用argmax操作。最后的偽標簽由選擇最大的連接組件,這操作可以有效地移除離群體素。之后提出雙向復制-黏貼無標注圖像偽標簽和有標注GT標簽獲得監督信號。
損失函數
學生網絡的每個輸入圖像由來自標注圖像和未標注圖像分量組成。直觀地,標記圖像的GT掩碼通常比未標注圖像的偽標記更準確。使用控制無標注圖像像素對損失函數的影響:
教師網絡參數更新:
實驗
LA數據集
心房分割挑戰[39]數據集包括100個帶標簽的三維釓增強磁共振圖像掃描(GE MRI)。
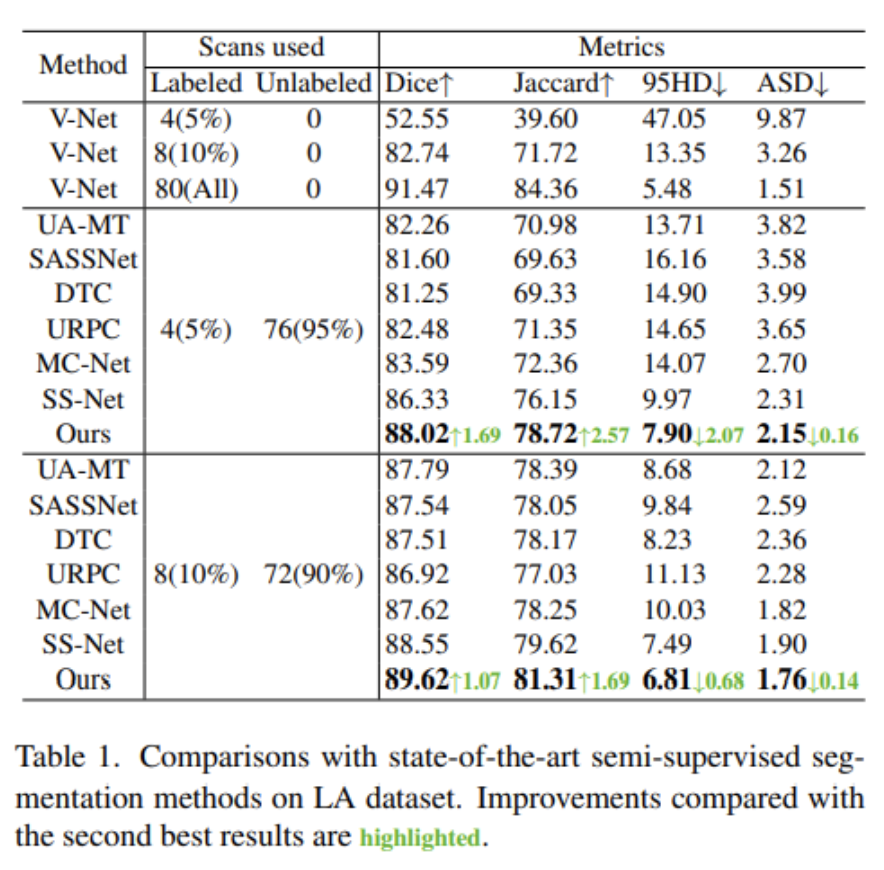
這里選擇UA-MT,SASSNet,DTC,URPC,MC-Net,SS-Net作為比較模型。這里給出了不同標簽率下的實驗結果。表1給出了相關實驗結果。可以看出本文方法在4個評價指標上都獲得最高的性能,大幅度超過比較模型。
Pancreases-NIT數據集
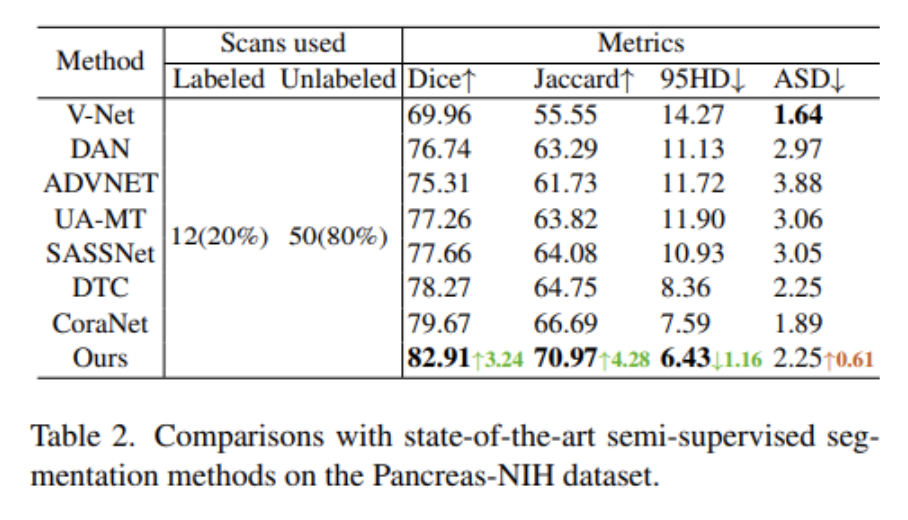
82個人工繪制的腹部CT增強體積。這里選擇V-Net,DAN,ADVNET,UA-MT,SASSNet,DTC和CoraNet作為比較算法。表2給出了相關實驗結果。本文方法BCP在Dice、Jaccard和95HD指標上實現了顯著的改進(即分別以3.24%、4.28%和1.16的優勢超過第二好)。這些結果沒有進行任何后期處理以進行公平比較。
ACDC數據集
四類(即背景、右心室、左心室和心肌)分割數據集,包含100名患者的掃描。表3給出了相關實驗結果。BCP超越了SOTA方法。對于標記比率為5%的設置,我們在Dice指標上獲得了高達21.76%的巨大性能改進

審核編輯 :李倩
-
數據
+關注
關注
8文章
6892瀏覽量
88828 -
架構
+關注
關注
1文章
509瀏覽量
25447 -
圖像分析
+關注
關注
0文章
82瀏覽量
18665
原文標題:實驗
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
dxp2004 復制粘貼 就死機
labview 如何把excel 的內容(包括格式)復制粘貼?
labview 如何把excel 的內容(包括格式)復制粘貼?
可雙向復制粘貼圖片 向日葵Windows客戶端9.0.3發布
一種基于關鍵點的復制粘貼盲檢測算法






 工商網監
工商網監
評論