 自訓練Pytorch模型使用OpenVINO?優化并部署在AI愛克斯開發板
自訓練Pytorch模型使用OpenVINO?優化并部署在AI愛克斯開發板
完成人:深圳技術大學 黎逸鵬(中德智能制造學院2021級本科生)
指導教授:張陽(英特爾邊緣計算創新大使,深圳技術大學中德智能制造學院副教授)
簡介
本文章將依次介紹如何將 Pytorch 自訓練模型經過一系列變換變成 OpenVINOIR 模型形式,而后使用 OpenVINO Python API 對 IR 模型進行推理,并將推理結果通過 OpenCV API 顯示在實時畫面上。
本文 Python 程序的開發環境是 Ubuntu20.04 LTS + PyCharm,硬件平臺是 AIxBoard 愛克斯板開發者套件。
本文項目背景:針對2023第十一屆全國大學生光電設計競賽賽題2“迷宮尋寶”光電智能小車題目。基于該賽項寶藏樣式,我通過深度學習訓練出能分類四種不同顏色不同標記形狀骨牌的模型,骨牌樣式詳見圖1.1。
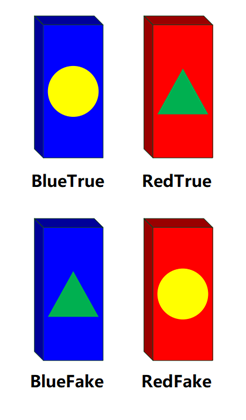
圖1.1 四種骨牌類型
完整指導視頻
1.2/Pytorch pth 模型轉換成
OpenVINO IR模型
Pytorch是 一個基于 Torch 的開源 Python 學習庫,是一個以 Python 優先的深度學習框架。Pth 模型文件是 Pytorch 進行模型保存時的一種模型格式,OpenVINO 暫不支持直接對 Pth 模型文件進行推理,所以我們要將 Pth 格式的模型先轉換成 ONNX 格式文件,再通過 OpenVINO 自帶的 Model Optimizer(模型優化器)進一步轉變成 OpenVINO IR 模型。處理過程如下所示:
1. 通過 Pytorch 將 Pth 模型轉換成 ONNX 模型
轉換后的文件(Pth —> ONNX):
import torch.onnx
# SZTU LIXROBO 23.5.14 #
#******************************************#
# 1. 模型加載
model = torch.load('Domino_best.pth', map_location=torch.device('cpu'))
# 2. 設置模型為評估模式而非訓練模式
model.eval()
# 3. 生成隨機從標準正態分布抽取的張量
dummy_input = torch.randn(1,3,224,224,device='cpu')
# 4. 導出ONNX模型(保存訓練參數權重)
torch.onnx.export(model,dummy_input,"Domino_best.onnx",export_params=True)
2. 通過終端來將 ONNX 模型轉化成 OpenVINO IR 模型格式
在終端中輸入(Terminal):
mo --input_model Domino_best.onnx --compress_to_fp16
# mo 啟動OpenVINO 的Model Optimizer(模型優化器)
# input_model 輸入您轉換的ONNX模型內容根的路徑
# compress _to_fp16 將模型輸出精度變為FP16
等后一會,終端輸出:

代表 ONNX 模型轉換成 OpenVINO IR 模型成功。這里的信息告訴我們該 Model 是 IR 11 的形式,并分別保存在 .xml 和 .bin 文件下。
轉換后的文件(ONNX —> IR 11):
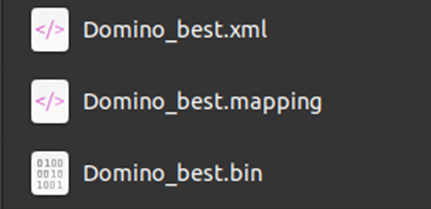
mapping 文件是一些轉換信息,暫時不會用到該文件。
至此,我們模型轉換的全部工作已經完成,接下來就是運用 OpenVINO Runtime 對 IR 11 模型進行推理。
1.3/用OpenVINORuntime
對 IR 11 模型進行推理
在這一章節里我們將在 Pycharm 中使用 OpenVINO Runtime 對我們在1.2章中轉換得來的 IR 11 模型進行推理,并將推理結果實時展現在攝像頭畫面中。
在開始之前,我們不妨了解推理程序的整個工作流程:
導入必要的功能庫(如 openvino.runtime 以及 cv2和 numpy)
探測硬件平臺所能使用的可搭載設備
創建核心對象以及加載模型和標簽
輸入圖像進行預處理,正則化,轉變成網絡輸入形狀
將處理后的圖像交由推理程序進行推理,得到推理結果和處理時間并顯示出來
1.3.1. 導入功能包
import openvino.runtime as ov
import numpy as np
import cv2
import time
這里一共導入4個功能包
openvino.runtime 這是 openvino runtime 推理的主要功能包,也可用 openvino.inference_engine 進行推理,過程大體是一致的。
numpy 這是常用的一個 Python 開源科學計算庫
cv2 也即 OpenCV,用來處理有關圖像的一些信息
time 記錄系統運行時間
1.3.2 設備檢測以及模型載入
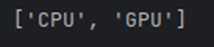
我們可以使用 Core 對象中的 available_devices 函數來獲取當前硬件平臺可供推理引擎使用的設備。
core = ov.Core()
print(core.available_devices)
如圖所示我們能得到在 AlxBoard 愛克斯開發板上可供我們使用的推理設備有 CPU 和 GPU。
將模型進行載入:
# SZTU LIXROBO 23.5.19 #
#************************************#
# 1. 創建核心對象
core = ov.Core()
# 2. 規定IR 11模型的模型文件和權重文件
model = "Domino_best.xml"
weights = "Domino_best.bin"
# 3. 將模型文件和權重文件進行讀取
model_ir = core.read_model(model= model,weights=weights)
# 4. 把模型加載到設備上
(此處使用HETERO插件進行異構,加載到GPU和CPU上)
com_model_ir= core.compile_model(model=model_ir,device_name="HETERO:GPU,CPU")
# 5. 獲取模型輸出層
output_layer_ir = com_model_ir.outputs[0]
# 6. 由于是簡單模型,故label手動注入,也可使用導入標簽文件等其他方式
label = ['BlueFake','BlueTrue','RedFake','RedTrue']
1.3.3 圖像預處理
得到的圖像我們需要做一些預先處理才能輸入到推理引擎中進行推理并得到結果。這一小節我們將展示如何把圖像進行處理。
#************************************#
# 圖像預處理、歸一化 #
def normalize(img: np.ndarray) ->np.ndarray:
# 1. 類型轉換成np.float32
img = img.astype(np.float32)
# 2. 設置常用均值和標準差來正則化
mean =(0.485,0.456,0.406)
std =(0.299,0.224,0.255)
img /=255.0
img -=mean
img /=std
# 3. 返回處理后的img
return img
#************************************#
# 圖像處理函數 #
def img_pre(img):
# 1. 對OV輸入圖像顏色模型從BGR轉變成RGB
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# 2. 對圖像進行裁切
res_img = cv2.resize(img, (224, 224))
# 3. 使用我們定義的預處理函數對圖像進行處理
nor_img = normalize(res_img)
# 4. 將處理好的圖像轉變為網絡輸入形狀
nor_input_img = np.expand_dims(np.transpose(nor_img, (2, 0, 1)), 0)
# 5. 返回處理結果
return nor_input_img
1.3.4 推理過程以及結果展示
在上一節中我們把輸入圖像所要進行的預處理圖像進行了一個定義,在這一小節則是 OpenVINO Runtime 推理程序的核心。
#************************************#
# 推理主程序 #
def image_infer(img):
# 1. 設置記錄起始時間
start_time = time.time()
# 2. 將圖像進行處理
imgb = img_pre(img)
# 3. 輸入圖像進行推理,得到推理結果
res_ir = com_model_ir([imgb])[output_layer_ir]
# 4. 對結果進行歸一化處理,使用Sigmod歸一
Confidence_Level = 1/(1+np.exp(-res_ir[0]))
# 5. 將結果進行從小到大的排序,便于我們獲取置信度最高的類別
result_mask_ir = np.squeeze(np.argsort(res_ir, axis=1)).astype(np.uint8)
# 6. 用CV2的putText方法將置信度最高對應的label以及其置信度繪制在圖像上
img = cv2.putText(img,str(label[result_mask_ir[3]])+' '+ str(Confidence_Level[result_mask_ir[3]]),(50,80), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2,cv2.LINE_AA)
# 7. 記錄推理結束時間
end_time = time.time()
# 8. 計算出攝像頭運行幀數
FPS = 1 / (end_time - start_time)
# 9. 將幀數繪制在圖像上
img = cv2.putText(img, 'FPS ' + str(int(FPS)), (50, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2,cv2.LINE_AA)
# 10. 返回圖像
return img
以上推理函數編寫已經完成。以下是運行主程序:
#********************主程序***********************#
# 1. 獲取攝像頭
cap = cv2.VideoCapture(0)
# 2. 循環判斷
while 1:
# 1. 獲得實時畫面
success,frame = cap.read()
# 2. 把實時畫面交由推理函數進行推理
frame = image_infer(frame)
# 3. 將畫面顯示在窗口
cv2.imshow("img",frame)
cv2.waitKey(1)
當我們運行該程序時,會得到如下畫面。
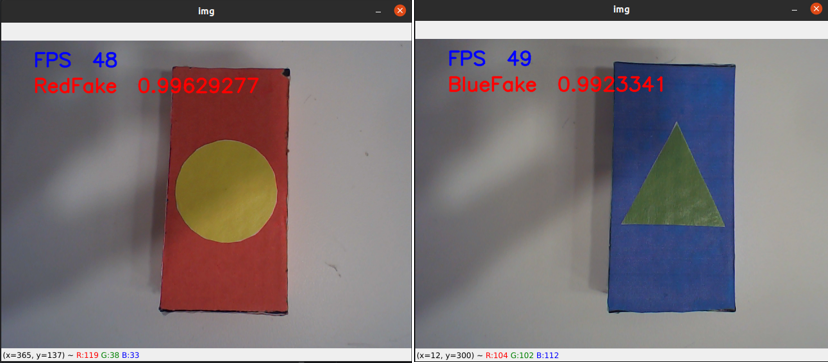
如圖所示,我們的 Pytorch 模型成功在 OpenVINO的優化以及推理下成功部署在 AlxBoard 愛克斯開發板,幀數在40-60之間,推理的結果非常好,很穩定。
1.4/與 Pytorch 模型
CPU 推理進行比較
原先推理的過程我們是通過 torch 功能庫進行推理,我們將兩者進行比較。
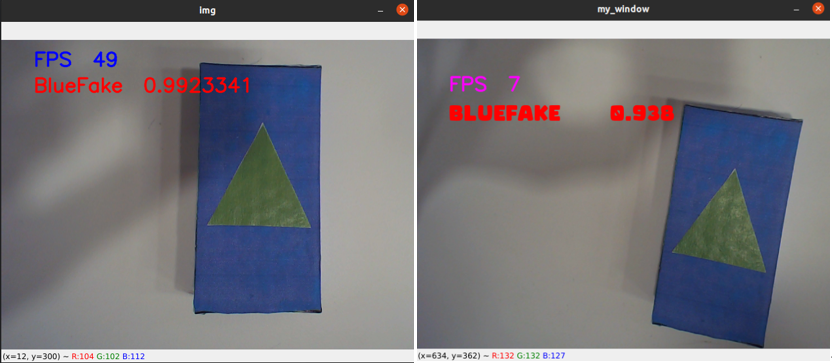
(左為 OpenVINO 優化推理,右為 torch 推理)
如圖所示 OpenVINO 優化推理過后的結果從實際幀數上看大約有5-8倍的提升,推理精度也有少許加強。
1.5結論
自訓練 Pytorch 模型在通過 OpenVINOModel Optimizer 模型優化后用 OpenVINO Runtime 進行推理,推理過程簡單清晰。推理僅需幾個核心函數便可實現基于自訓練 Pytorch 模型的轉化以及推理程序。
OpenVINO 簡單易上手,提供了強大的資料庫供學者查閱,其包含了從模型建立到模型推理的全過程。
審核編輯:湯梓紅
-
AI
+關注
關注
87文章
30106瀏覽量
268399 -
開發板
+關注
關注
25文章
4943瀏覽量
97188 -
模型
+關注
關注
1文章
3171瀏覽量
48711 -
python
+關注
關注
56文章
4782瀏覽量
84449 -
pytorch
+關注
關注
2文章
803瀏覽量
13145
原文標題:自訓練Pytorch模型使用OpenVINO?優化并部署在AI愛克斯開發板| 開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
怎樣使用PyTorch Hub去加載YOLOv5模型
【KV260視覺入門套件試用體驗】Vitis AI 構建開發環境,并使用inspector檢查模型
在C++中使用OpenVINO工具包部署YOLOv5模型

在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型


在AI愛克斯開發板上用OpenVINO?加速YOLOv8-seg實例分割模型
如何將Pytorch自訓練模型變成OpenVINO IR模型形式

在AI愛克斯開發板上用OpenVINO?加速YOLOv8-seg實例分割模型
使用OpenVINO優化并部署訓練好的YOLOv7模型
基于OpenVINO在英特爾開發套件上實現眼部追蹤
基于Pytorch訓練并部署ONNX模型在TDA4應用筆記

使用OpenVINO Model Server在哪吒開發板上部署模型





 工商網監
工商網監
評論