 主流的機器視覺技術又有哪些呢?
主流的機器視覺技術又有哪些呢?
導語:視覺是人類最敏感、最直接的感知方式,在不進行實際接觸的情況下,視覺感知可以使得我們獲取周圍環境的諸多信息。由于生物視覺系統非常復雜,目前還不能使得某一機器系統完全具備這一強大的視覺感知能力。
當下,機器視覺的目標即,構建一個在可控環境中處理特定任務的機器視覺系統。由于工業中的視覺環境可控,并且處理任務特定,所以現如今大部分的機器視覺被應用在工業當中。
人類視覺感知是通過眼睛視網膜的椎體和桿狀細胞對光源進行捕捉,而后由神經纖維將信號傳遞至大腦視覺皮層,形成我們所看到的圖像,而機器視覺卻不然。機器視覺系統的輸入是圖像,輸出是對這些圖像的感知描述。這組描述與這些圖像中的物體或場景息息相關,并且這些描述可以幫助機器來完成特定的后續任務,指導機器人系統與周圍的環境進行交互。
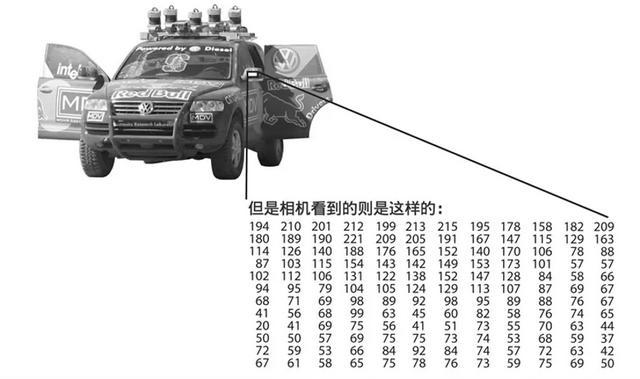
那么,迄今為止,主流的機器視覺技術又有哪些呢?

中流砥柱
卷積神經網絡
卷積神經網絡是目前計算機視覺中使用最普遍的模型結構。引入卷積神經網絡進行特征提取,既能提取到相鄰像素點之間的特征模式,又能保證參數的個數不隨圖片尺寸變化。上圖是一個典型的卷積神經網絡結構,多層卷積和池化層組合作用在輸入圖片上,在網絡的最后通常會加入一系列全連接層,ReLU激活函數一般加在卷積或者全連接層的輸出上,網絡中通常還會加入Dropout來防止過擬合。
自2012年AlexNet在ImageNet比賽上獲得冠軍,卷積神經網絡逐漸取代傳統算法成為了處理計算機視覺任務的核心。
在這幾年,研究人員從提升特征提取能力,改進回傳梯度更新效果,縮短訓練時間,可視化內部結構,減少網絡參數量,模型輕量化, 自動設計網絡結構等這些方面,對卷積神經網絡的結構有了較大的改進,逐漸研究出了AlexNet、ZFNet、VGG、NIN、GoogLeNet和Inception系列、ResNet、WRN和DenseNet等一系列經典模型,MobileNet系列、ShuffleNet系列、SqueezeNet和Xception等輕量化模型。
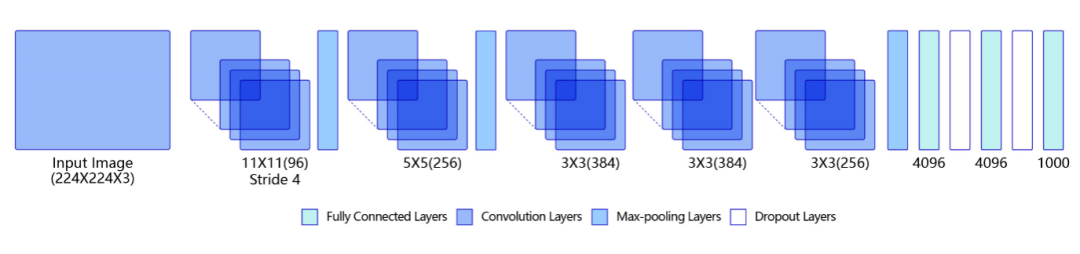
·卷積網絡示意圖
經典模型(AlexNet):
AlexNet是第一個深度神經網絡,其主要特點包括:
1. 使用ReLU作為激活函數。
2. 提出在全連接層使用Dropout避免過擬合。注:當BN提出后,Dropout就被BN替代了。
3. 由于GPU顯存太小,使用了兩個GPU,做法是在通道上分組。
4. 使用局部響應歸一化(Local Response Normalization --LRN),在生物中存在側抑制現象,即被激活的神經元會抑制周圍的神經元。在這里的目的是讓局部響應值大的變得相對更大,并抑制其它響應值相對比較小的卷積核。例如,某特征在這一個卷積核中響應值比較大,則在其它相鄰卷積核中響應值會被抑制,這樣一來卷積核之間的相關性會變小。LRN結合ReLU,使得模型提高了一點多個百分點。
5. 使用重疊池化。作者認為使用重疊池化會提升特征的豐富性,且相對來說會更難過擬合。
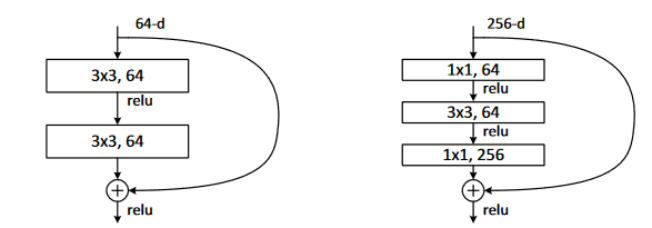
集大成之作(ResNet):
一般而言,網絡越深越寬會有更好的特征提取能力,但當網絡達到一定層數后,隨著層數的增加反而導致準確率下降,網絡收斂速度更慢。
傳統的卷積網絡在一個前向過程中每層只有一個連接,ResNet增加了殘差連接從而增加了信息從一層到下一層的流動。FractalNets重復組合幾個有不同卷積塊數量的并行層序列,增加名義上的深度,卻保持著網絡前向傳播短的路徑。相類似的操作還有Stochastic depth和Highway Networks等。這些模型都顯示一個共有的特征,縮短前面層與后面層的路徑,其主要的目的都是為了增加不同層之間的信息流動。
后起之秀
Transformers
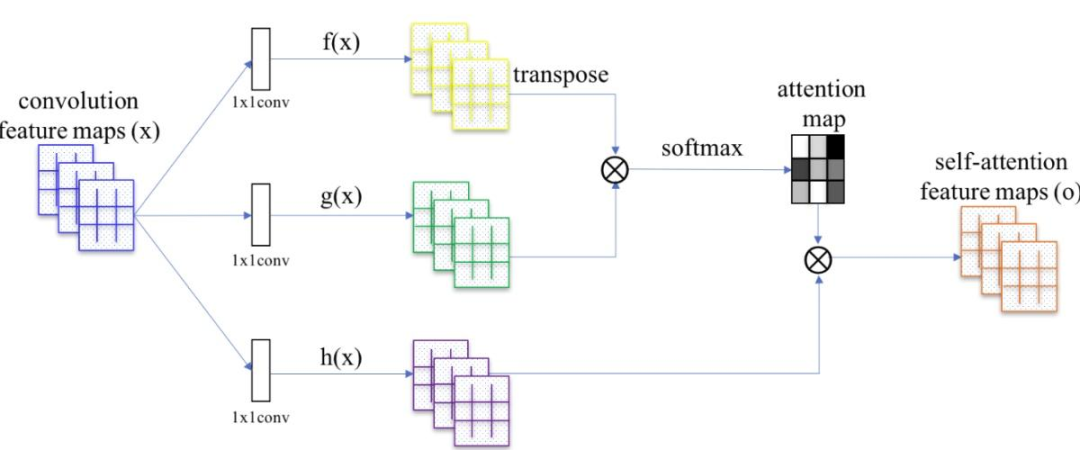
Transformer是一種self-attention(自注意力)模型架構,2017年之后在NLP領域取得了很大的成功,尤其是序列到序列(seq2seq)任務,如機器翻譯和文本生成。2020年,谷歌提出pure transformer結構ViT ,在ImageNet分類任務上取得了和CNN可比的性能。之后大量ViT衍生的Transformer架構在ImageNet上都取得了成功。
Transformer 與 CNN相比優點是具有較少的歸納性與先驗性,因此可以被認為是不同學習任務的通用計算原語,參數效率與性能增益與 CNN 相當。不過缺點是在預訓練期間,對大數據機制的依賴性更強,因為 Transformer 沒有像 CNN 那樣定義明確的歸納先驗。因此當下出現了一個新趨勢:當 self-attention 與 CNN 結合時,它們會建立強大的基線( BoTNet )。
Vision Transformer(ViT)將純Transformer架構直接應用到一系列圖像塊上進行分類任務,可以取得優異的結果。它在許多圖像分類任務上也優于最先進的卷積網絡,同時所需的預訓練計算資源大大減少。
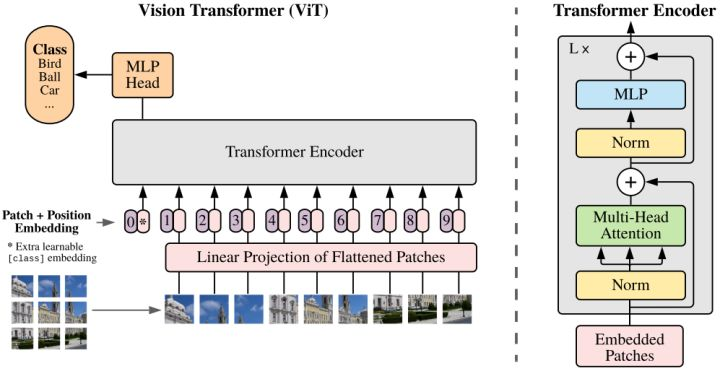
DETR是第一個成功地將Transformer作為pipeline中的主要構建塊的目標檢測框架。它與以前的SOTA方法(高度優化的Faster R-CNN)的性能匹配,具有更簡單和更靈活的pipeline。
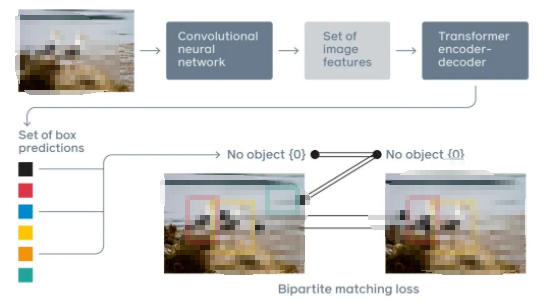
Transformer的變體模型是目前的研究熱點,主要分為以下幾個類型:1)模型輕量化;2)加強跨模塊連接;3)自適應的計算時間;4)引入分而治之的策略;4)循環Transformers;5)等級化的Transformer。
欺騙機器的眼睛
對抗性示例
最近引起研究界注意的一個問題是這些系統對對抗樣本的敏感性。一個對抗性的例子是一個嘈雜的圖像,旨在欺騙系統做出錯誤的預測。為了在現實世界中部署這些系統,它們必須能夠檢測到這些示例。為此,最近的工作探索了通過在訓練過程中包含對抗性示例來使這些系統更強對抗性攻擊的可能性。
現階段對模型攻擊的分類主要分為兩大類,即攻擊訓練階段和推理階段。
訓練階段的攻擊
訓練階段的攻擊(Training in Adversarial Settings),主要的方法就是針對模型的參數進行微小的擾動,從而達到讓模型的性能和預期產生偏差的目的。例如直接通過對于訓練數據的標簽進行替換,讓數據樣本和標簽不對應,從而最后訓練的結果也一定與預期的產生差異,或者通過在線的方式獲得訓練數據的輸入權,操縱惡意數據來對在線訓練過程進行擾動,最后的結果就是產出脫離預期。
推理階段的攻擊
推理階段的攻擊(Inference in Adversarial Settings),是當一個模型被訓練完成后,可以將該模型主觀的看作是一個盒子,如果該盒子對我們來說是透明的則可以將其看成“白盒”模型,若非如此則看成“黑盒”模型。所謂的“白盒攻擊”,就是我們需要知道里面所有的模型參數,但這在實際操作中并不現實,卻有實現的可能,因此我們需要有這種前提假設。黑盒攻擊就比較符合現實生活中的場景:通過輸入和輸出猜測模型的內部結構;加入稍大的擾動來對模型進行攻擊;構建影子模型來進行關系人攻擊;抽取模型訓練的敏感數據;模型逆向參數等等。
對抗攻擊的防御機制。抵御對抗樣本攻擊主要是基于附加信息引入輔助塊模型(AuxBlocks)進行額外輸出來作為一種自集成的防御機制,尤其在針對攻擊者的黑盒攻擊和白盒攻擊時,該機制效果良好。除此之外防御性蒸餾也可以起到一定的防御能力,防御性蒸餾是一種將訓練好的模型遷移到結構更為簡單的網絡中,從而達到防御對抗攻擊的效果。
對抗學習的應用舉例,1、自動駕駛;2、金融欺詐。
自動駕駛是未來智能交通的發展方向,但在其安全性獲得完全檢驗之前,人們還難以信任這種復雜的技術。雖然許多車企、科技公司已經在這一領域進行了許多實驗,但對抗樣本技術對于自動駕駛仍然是一個巨大的挑戰。幾個攻擊實例:對抗攻擊下的圖片中的行人在模型的面前隱身,對抗樣本使得模型“無視”路障;利用 AI 對抗樣本生成特定圖像并進行干擾時,特斯拉的 Autopilot 系統輸出了「錯誤」的識別結果,導致車輛雨刷啟動;在道路的特定位置貼上若干個對抗樣本貼紙,可以讓處在自動駕駛模式的汽車并入反向車道;在Autopilot 系統中,通過游戲手柄對車輛行駛方向進行控制;對抗樣本使得行人對于機器學習模型“隱身”。
自學也能成才
自監督學習
深度學習需要干凈的標記數據,這對于許多應用程序來說很難獲得。注釋大量數據需要大量的人力勞動,這是耗時且昂貴的。此外,數據分布在現實世界中一直在變化,這意味著模型必須不斷地根據不斷變化的數據進行訓練。自監督方法通過使用大量原始未標記數據來訓練模型來解決其中的一些挑戰。在這種情況下,監督是由數據本身(不是人工注釋)提供的,目標是完成一個間接任務。間接任務通常是啟發式的(例如,旋轉預測),其中輸入和輸出都來自未標記的數據。定義間接任務的目標是使模型能夠學習相關特征,這些特征稍后可用于下游任務(通常有一些注釋可用)。
自監督學習是一種數據高效的學習范式。監督學習方法教會模型擅長特定任務。另一方面,自監督學習允許學習不專門用于解決特定任務的一般表示,而是為各種下游任務封裝更豐富的統計數據。在所有自監督方法中,使用對比學習進一步提高了提取特征的質量。自監督學習的數據效率特性使其有利于遷移學習應用。
目前的自監督學習領域可大致分為兩個分支。一個是用于解決特定任務的自監督學習,例如上次討論的場景去遮擋,以及自監督的深度估計、光流估計、圖像關聯點匹配等。另一個分支則用于表征學習。有監督的表征學習,一個典型的例子是ImageNet分類。而無監督的表征學習中,最主要的方法則是自監督學習。
自監督學習方法依賴于數據的空間和語義結構,對于圖像,空間結構學習是極其重要的,因此在計算機視覺領域中的應用廣泛。一種是將旋轉、拼接和著色在內的不同技術被用作從圖像中學習表征的前置任務。對于著色,將灰度照片作為輸入并生成照片的彩色版本。另一種廣泛用于計算機視覺自監督學習的方法是放置圖像塊。一個例子包括 Doersch 等人的論文。在這項工作中,提供了一個大型未標記的圖像數據集,并從中提取了隨機的圖像塊對。在初始步驟之后,卷積神經網絡預測第二個圖像塊相對于第一個圖像塊的位置。還有其他不同的方法用于自監督學習,包括修復和判斷分類錯誤的圖像。
自2012年AlexNet問世這十年來,機器視覺領域的技術可以說是日新月異。機器視覺在諸多領域也逐漸接近甚至超越了我們人類的眼睛。隨著技術的不斷進步,機器視覺技術也一定會變得更加的強大,無論是安全防護、自動駕駛、缺陷檢測還是目標識別等領域,相信機器視覺會帶給我們更多的驚喜。
審核編輯 :李倩
-
機器視覺
+關注
關注
161文章
4347瀏覽量
120124 -
卷積神經網絡
+關注
關注
4文章
366瀏覽量
11851
發布評論請先 登錄
相關推薦
視覺檢測是什么意思?機器視覺檢測的適用行業及場景有哪些?
什么是機器視覺opencv?它有哪些優勢?
機器視覺的應用實例解析
機器視覺控制軸運動原理是什么?
機器視覺的應用流程是如何實現的
機器視覺的關鍵技術有哪些
機器視覺中常用的光源 影響機器視覺技術速度的因素
機器視覺軟件有哪些 機器視覺軟件的優點
技術科普 | 機器視覺5大關鍵技術及其常見應用






 工商網監
工商網監
評論