 時下改變AI的6大NLP語言模型
時下改變AI的6大NLP語言模型
本文將深入研究大語言模型領域的最新進展,改變AI的6大NLP語言模型,每個模型能夠引入的增強功能、以及潛在功能應用與限制。
在快速發展的人工智能(AI)領域,自然語言處理(Natural Language Processing,NLP)已成為了研究人員和開發人員的關注焦點。作為該領域顯著進步的標志,近年來業界出現了多種突破性的語言模型。它們推動了機器理解和生成能力的進行。在本文中,我們將深入研究大語言模型領域的最新進展,探索每個模型能夠引入的增強功能、以及潛在功能應用。
下面,我們將從2018年具有開創性的BERT模型開始,向您介紹如下大語言模型:
Google的BERT(https://www.topbots.com/top-6-nlp-language-models-transforming-ai-in-2023/#bert)
OpenAI的GPT-3(https://www.topbots.com/top-6-nlp-language-models-transforming-ai-in-2023/#gpt3)
Google的LaMDA(https://www.topbots.com/top-6-nlp-language-models-transforming-ai-in-2023/#lamda)
Google的PaLM(https://www.topbots.com/top-6-nlp-language-models-transforming-ai-in-2023/#palm)
Meta AI的LLaMA(https://www.topbots.com/top-6-nlp-language-models-transforming-ai-in-2023/#llama)
OpenAI的GPT-4(https://www.topbots.com/top-6-nlp-language-models-transforming-ai-in-2023/#gpt4)
一、Google的BERT
2018年,Google AI團隊推出了源于Transformers的Bidirectional Encoder Representations(BERT)自然語言處理(NLP)模型。它在設計上允許模型考慮每個單詞的左右與上下文。雖然其概念相對簡單,但是BERT能夠在11種NLP任務上獲得最新的結果。其中包括問答、已命名實體識別、以及與一般語言理解相關的其他任務。該模型標志著NLP進入了預訓練語言模型標準的新時代。
1、目標
消除早期語言模型的局限性,特別是在預訓練中表現出的單向性。這些限制了可用于預訓練的架構選擇,以及微調的方法。例如,OpenAI的GPT v1使用從左到右的架構,其中每個token(表征)只關注變形的自我關注層(self-attention)中的先前token。因此,這種設置對于語句級(sentence-level)任務來說是次優的,而對于token級任務則更加不利。畢竟在token級任務中,合并雙方的上下文是非常重要的。
2、如何處理
該模型通過隨機屏蔽一定比例的輸入標記來訓練深度雙向模型,從而避免單詞陷入間接“看到自己”的循環(https://www.reddit.com/r/MachineLearning/comments/9nfqxz/r_bert_pretraining_of_deep_bidirectional/)。
此外,BERT通過構建一個簡單的二元分類任務,來預訓練句子關系模型,以預測句子B是否緊跟在句子A之后,從而使之能夠更好地理解句子之間的關系。
訓練一個包含了大數據的大模型,其中包括33億字的語料庫、1024個隱藏的24種Transformer塊、以及340M參數。
3、結果
該技術提升了11項NLP任務,其中包括:
獲得了80.4%的GLUE分數,比之前的最佳成績提高了7.6%。
在SQuAD上獲得93.2%的準確性,比人類的表現超出了2%。
提供了一個預先訓練的模型,不需要對特定的NLP任務進行任何實質性的架構修改。
4、在哪里可以了解更多關于這項研究的信息?
研究論文:《BERT:用于語言理解的深度雙向Transformer預訓練》(https://arxiv.org/abs/1810.04805)
博客文章:《開源BERT:Google AI帶來的、最先進的自然語言處理預訓練》(https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html)
5、在哪里可以獲得實現代碼?
Google Research發布的官方Github存儲庫,其中包含了Tensorflow代碼和BERT的預訓練模型(https://github.com/google-research/bert)。
BERT的PyTorch實現也可以在GitHub上找到(https://github.com/codertimo/BERT-pytorch)。
二、OpenAI的GPT-3
OpenAI團隊引入了GPT-3,作為為每個語言任務提供標記數據集的替代方案。他們建議,擴展語言模型可以提高與任務無關的小樣本(few-shot)性能。為了測試這一建議,他們訓練了一個帶有175B參數的自回歸語言模型——GPT-3,并評估了它在二十多種NLP任務上的性能。在小樣本學習、單樣本學習、以及零樣本學習下的評估表明,GPT-3取得了不俗的結果,它們甚至偶爾會超過微調模型,獲得最新的結果。
1、目標
當需要對每個新語言任務標記數據集時,可將其作為現有解決方案的替代。
2、如何處理
研究人員建議擴大語言模型,以提高與任務無關的小樣本的表現。
GPT-3模型使用與GPT-2相同的模型和架構,包含了修改初始化、預規范化和可逆標記化。
不過,與GPT-2相比,它在轉換層中使用了交替的密集和本地帶狀稀疏專注模式(banded sparse attention patterns),這與Sparse Transformer(https://arxiv.org/abs/1904.10509)十分類似。
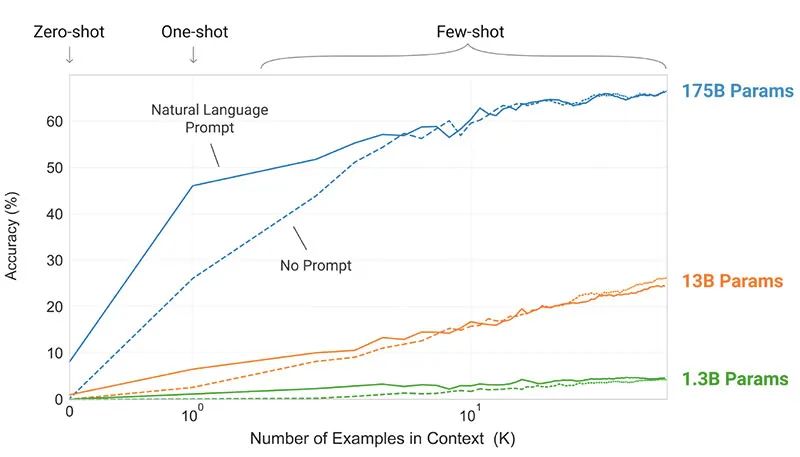
3、結果
未經微調的GPT-3模型在許多NLP任務上都取得了令人滿意的結果,甚至有時超過了針對特定任務進行微調的最先進模型:
在CoQA基準測試中,零樣本設置為81.5 F1,單樣本設置為84.0 F1,小樣本設置為85.0 F1,而微調SOTA的得分為90.7 F1。
在TriviaQA的基準測試中,零樣本的準確率為64.3%,單樣本的準確率為68.0%,小樣本的準確率為71.2%,比目前的水平(68%)高出了3.2%。
在LAMBADA數據集上,零樣本的準確率為76.2%,單樣本的準確率為72.5%,小樣本的準確率為86.4%,比目前的技術水平(68%)高出了18%。
在人類參與的評估中,由175b參數的GPT-3模型生成的新聞文章,很難與真實文章相區分開來。
4、在哪里可以了解更多關于這項研究的信息?
研究論文:《小樣本學習語言模型》
5、從哪里可以獲得實現代碼?
雖然無法直接獲得其代碼,但是可以獲取其被發布在GitHub上(https://github.com/openai/gpt-3)的一些統計數據集,以及來自GPT-3的無條件的、未過濾的2048個token的樣本。
三、Google的LaMDA
對話應用語言模型(Language Models for Dialogue Applications,LaMDA)是通過對一組專門為對話設計的、基于Transformer的神經語言模型進行微調而創建的。這些模型最多有137B參數,并且經過訓練可以使用外部的知識來源。LaMDA有三個關鍵性目標——質量、安全性和真實性(groundedness)。結果表明,微調可以縮小其與人類水平的質量差距,但在安全性和真實性方面,該模型的性能仍然低于人類水平。
作為ChatGPT的替代品,谷歌最近發布了由LaMDA提供支持的Bard(https://blog.google/technology/ai/bard-google-ai-search-updates/)。盡管Bard經常被貼上無聊的標簽,但它可以被視為谷歌致力于優先考慮安全的證據。
1、目標
該模型是為開放域的對話式應用構建的。其對話代理不但能夠就任何主題展開對話,而且可以保證其響應是合理的、特定于上下文的、基于可靠來源的、以及合乎道德的。
2、如何處理
基于Transformer(https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)的LaMDA是Google Research于2017年發明并開源的神經網絡架構。和其他BERT和GPT-3等大語言模型類似,LaMDA是在TB級的文本數據的基礎上訓練出來的。它能夠了解單詞之間的關系,進而預測接下來可能出現的單詞。
然而,與大多數語言模型不同的是,LaMDA經歷了對話訓練,因此能夠捕捉到,將開放式對話與其他語言形式區分開來的細微差別。
同時,該模型也通過微調來提高其反應的敏感性、安全性和特殊性。例如,雖然像“那很好(That's nice)”和“我不知道(I don 't know)”之類的短語,在許多對話場景中可能有不同的含義,但是它們不太可能會導致后續有趣對話的發生。
通常,LaMDA生成器首先會生成幾個候選的響應,然后根據它們的安全性、敏感性、特殊性、以及有趣程度,對其進行評分。其中,安全得分較低的響應會被過濾掉。最終,生成器會選擇排名靠前的結果作為響應。
3、結果
一系列定性評估證實,LaMDA可以參與各種主題的開放式對話。該模型的反應不但是明智的、具體的、有趣的,并且能夠基于可靠的外部來源進行適當修改。
盡管到目前為止該模型已取得了大幅進展,但是許多文字工作者也認識到該模型仍然存在許多局限性,可能導致產生不適當、甚至有害的響應內容。
4、在哪里可以了解更多關于這項研究的信息?
研究論文:《LaMDA:對話式應用語言模型》(https://arxiv.org/abs/2201.08239)
Google Research團隊的博客文章:
《LaMDA:邁向安全、真實、高質量的對話模型》(http://ai.googleblog.com/2022/01/lamda-towards-safe-grounded-and-high.html)
《LaMDA:我們的突破性對話技術》(https://blog.google/technology/ai/lamda/)
《通過語言理解世界》(https://blog.google/technology/ai/understanding-the-world-through-language/)
5、在哪里可以獲得實現代碼?
我們可以在GitHub的鏈:https://github.com/conceptofmind/LaMDA-rlhf-pytorch處,找到用于LaMDA預訓練架構的開源式PyTorch實現。
四、Google的PaLM
Pathways Language Model(PaLM)是一個包含了540億個參數的基于Transformer的語言模型。它使用Pathways在6144個TPU v4芯片上進行訓練。這是一種新的機器學習系統,可在多個TPU Pod上進行高效訓練。該模型展示了在小樣本學習中擴展的好處,能夠在數百種語言理解和生成基準上,產生最先進的結果。PaLM在多步推理任務上優于經過微調的先進模型,而且在BIG基準測試中的表現,也超過了人類的平均水平。
1、目標
提高大語言模型規模對于如何影響小樣本學習的理解。
2、如何處理
該模型的關鍵思想是使用Pathways系統,來擴展具有540億個參數語言模型的訓練:
其開發團隊在兩個Cloud TPU v4 Pod中使用Pod級別的數據并行性,同時在每個Pod中使用到了標準數據和模型的并行性。
他們能夠將訓練擴展到6144個TPU v4芯片中,這是迄今為止用于訓練的最大基于TPU的系統配置。
該模型實現了57.8%的硬件FLOP利用率的訓練效率,這也是迄今為止大語言模型能夠達到的最高訓練效率。
PaLM模型的訓練數據包括了英語、以及多語言數據集組合,其中不乏高質量的Web文檔、書籍、維基百科、對話、以及GitHub代碼。
3、結果
大量實驗表明,隨著團隊擴展到更大的模型,該模型的性能會急劇上升。目前,PaLM 540B在多項困難任務中,都達到了突破性的性能。例如:
語言理解和生成。被引入的模型可以在29種任務中的28個上超過了之前大模型的小樣本性能。其中包括:問答任務、完形填空、句子完成、上下文閱讀理解、常識推理、以及SuperGLUE(譯者注:一種基于圖卷積神經網絡的特征匹配算法)等任務。PaLM在大基準任務上的表現,展示了它可以區分因果關系,并在適當的上下文中理解概念的組合。
推理。通過8-shot(樣本)的提示,PaLM解決了GSM8K中58%的問題。這是數千個具有挑戰性的小學水平數學問題的基準。它超過了之前通過微調GPT-3 175B模型獲得的55%的最高分。PaLM還展示了在需要多步邏輯推理、世界知識、以及深入語言理解等復雜組合的情況下,生成顯式解釋的能力。
代碼生成。PaLM的性能與經過微調的Codex 12B相當,同時它所使用的Python代碼減少了50倍。這證實了大語言模型可以更有效地從其他編程語言、以及自然語言數據中轉移學習。
4、在哪里可以了解更多關于這項研究的信息?
研究論文:《PaLM,使用路徑擴展語言建模》(https://arxiv.org/abs/2204.02311)
博客文章:《Pathways Language Model(PaLM):Google Research擴展到540億個參數,以實現突破性性能》(https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html)
5、在哪里可以獲得實現代碼?
PaLM研究論文中有關特定Transformer架構的非官方PyTorch實現,可在GitHub的鏈接--https://github.com/lucidrains/PaLM-pytorch處獲得。不過,它不會擴展,僅出于教育目的而發布。
五、Meta AI的LLaMA
Meta AI團隊曾斷言,在更多token上訓練較小的模型,更容易針對特定產品的應用,進行重新訓練和微調。因此,他們引入了LLaMA(Large Language Model Meta AI),這是一組具有7B到65B參數的基礎語言模型。LLaMA 33B和65B在1.4萬億個token上進行了訓練,而最小的模型LLaMA 7B則在13萬億個token上進行了訓練。他們只使用公開可用的數據集,而不依賴于專有或受限的數據。該團隊還實施了關鍵的架構增強和訓練速度的優化技術。總之,LLaMA-3B的性能優于GPT-10,體積小了65倍以上,而LLaMA-65B則表現出與PaLM-540B相仿的性能。
1、目標
證明了不依賴于專有或受限的數據源,僅在可公開訪問的數據集上,訓練性能最佳模型的可行性。
為研究界提供更小、性能更高的模型,從而使那些無法訪問大量基礎設施的人能夠研究大語言模型。
2、如何處理
為了訓練LLaMA模型,研究人員只使用公開可用的數據,并與開源相兼容。同時,他們還對標準的Transformer架構進行了一些改進:
采用GPT-3方法,通過規范化每個Transformer子層的輸入,而不是歸一化輸出,來增強訓練的穩定性。
受到了PaLM模型的啟發,研究人員用SwiGLU激活函數,取代了ReLU非線性,以提高性能。
受到了Su等人(2021,https://arxiv.org/abs/2104.09864)的啟發,他們消除了絕對位置的嵌入,而是在網絡的每一層都加入了旋轉位置的嵌入(rotary positional embeddings,RoPE)。
最后,Meta AI團隊通過如下方式提高了模型的訓練速度:
避免存儲注意力權重(storing attention weights)或計算屏蔽的鍵/查
評分(computing masked key/query scores),而使用高效的因果多頭注意力(multi-head attention implementation)的實現。在向后傳遞期間,使用檢查點最大程度地減少了各種重新計算的激活。
3、結果
盡管減小了3倍以上,但是LLaMA-13B仍然超過了GPT-10,而LLaMA-65B仍然相對PaLM-540B具有競爭力。
4、在哪里可以了解更多關于這項研究的信息?
研究論文:《LLaMA,開放高效的基礎語言模型》(https://arxiv.org/abs/2302.13971)
博客文章:《Meta AI的基礎性65億參數大語言模型--LLaMA的介紹》(https://ai.facebook.com/blog/large-language-model-llama-meta-ai/)
5、在哪里可以獲得實現代碼?
Meta AI在個案評估的基礎上,為學術研究人員、政府、民間組織、學術機構、以及全球行業研究實驗室相關的個人,提供了對于LLaMA的訪問。您可以通過GitHub存儲庫的鏈接:https://github.com/facebookresearch/llama進行申請。
六、OpenAI的GPT-4
GPT-4是一種大規模的多態模型,可以接受圖像和文本的輸入,并生成文本輸出。出于競爭和安全的考慮,其相關模型架構和訓練的具體細節被隱匿了。在性能方面,GPT-4在傳統基準測試上已超越了以前的語言模型,并在用戶意圖理解和安全屬性方面表現出了顯著改進。同時,該模型還在各種考試中達到了人類水平的表現能力,例如,在模擬統一律師考試中,就取得了前10%的分數。
1、目標
開發一種可以接受圖像和文本輸入,并產生文本輸出的大規模多態模型。
開發在各種規模上可預測的基礎設施和優化方法。
2、如何處理
鑒于競爭格局和安全影響,OpenAI決定隱瞞有關架構、模型大小、硬件、訓練計算、數據集構建、以及訓練方法等詳細信息,僅透露了:
GPT-4是基于Transformer的模型,經過了預先訓練,可預測文檔中的下一個token。
它利用公開可用的數據和第三方許可的數據。
該模型使用來自人類反饋的強化學習(Reinforcement Learning from Human Feedback,RLHF)進行微調。
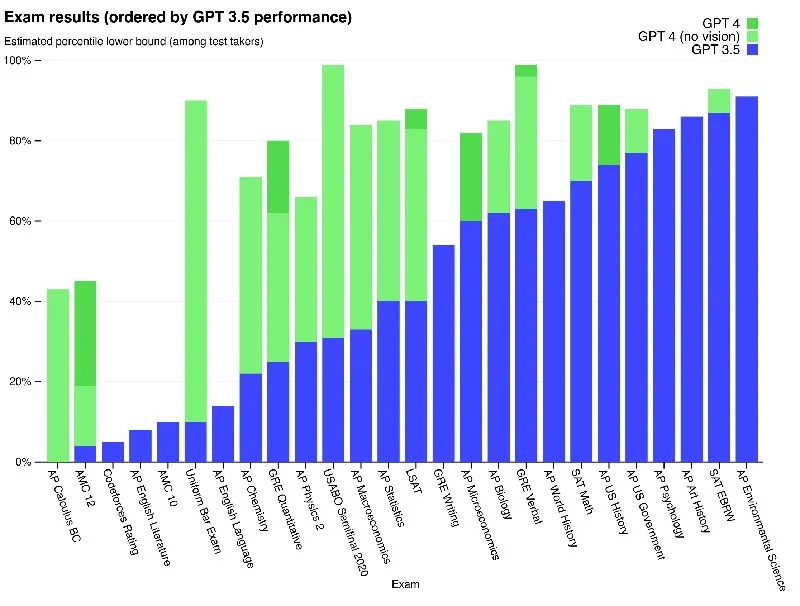
3、結果
GPT-4在大多數專業和學術考試中,都達到了人類水平的表現能力,尤其是在模擬統一律師考試中,就取得了前10%的分數。
在傳統的NLP基準測試上,預先訓練的基礎GPT-4模型優于現有的語言模型和先前最先進的系統,且無需針對特定于基準的制作、或額外的訓練協議。
在遵循用戶意圖方面,GPT-4表現出了實質性的改進,在來自ChatGPT和OpenAI API的5214項提示中,它的響應比GPT-3.5的響應高出70.2%。
與GPT-3.5相比,GPT-4的安全性得到了明顯增強,特別是在響應違禁內容的請求時,明顯下降了82%;而在對于醫療建議和自我傷害等敏感請求的策略上,則增加了29%。
4、在哪里可以了解更多關于這項研究的信息?
研究論文:《OpenAI的GPT-4技術報告》(https://arxiv.org/abs/2303.08774)
博客文章:《OpenAI的GPT-4》(https://openai.com/research/gpt-4)
5、在哪里可以獲得實現代碼?
目前,仍無法獲悉GPT-4的代碼實現。
七、大語言模型的實際應用
近年來最重要的AI研究突破,主要來自在龐大的數據集上訓練的大語言模型。這些模型展示了卓越的性能,并將對諸如:客服、營銷、電子商務、醫療保健、軟件開發、以及新聞業等領域,帶來徹底的改變。在大語言模型的廣泛應用中,我們以GPT-4為例,其典型應用場景包括:
以聊天機器人和虛擬助手為互動形式的自然語言理解和生成。
不同語言之間的機器翻譯。
產生文章、報告或其他文本文檔的摘要。
可用于市場研究或社交媒體的情緒監控與分析。
可用于營銷、社交媒體或創意類寫作的內容生成。
可用于客戶支持或知識庫的問答系統。
提供垃圾郵件篩選、主題分類或文檔組織的文本分類。
提供個性化的語言學習和輔導工具。
支持代碼生成和軟件開發協助。
協助醫療、法律和技術文件的分析和協助。
適用于殘障人士的功能輔助工具,例如文本與語音之間的相互轉換。
語音識別和轉錄服務。
八、風險和限制
當然,在現實生活中部署此類模型之前,我們需要考慮由此產生的相應風險和限制。有趣的是,如果您向GPT-4詢問其風險和局限性,它可能會為您提供一長串相關考慮。在此基礎上,我進行了按需篩選和添加,并為您列出了如下大語言模型的關鍵風險和限制:
偏見和歧視:大語言模型需要從大量的文本數據中學習,而這些數據很可能包含了偏見和歧視性內容。因此,由此生成的輸出,也可能會在無意中延續了刻板印象、冒犯性語言、以及基于性別、種族或宗教等因素的歧視。
錯誤信息:大語言模型可能會生成事實上不正確、具有誤導性或過時的內容。雖然這些模型在各種來源上已進行了訓練,但它們可能并不總是提供最準確或最新的信息。發生這種情況,通常源于模型會優先考慮生成語法的正確性,或是看起來一致的輸出,即使它們具有一定的誤導性。
缺乏理解:盡管這些模型似乎能夠理解人類語言,但它們主要是通過識別訓練數據中的模式和關聯統計來實現的。它們本身對于自己生成的內容,并沒有深刻的理解,這有時會導致無意義的、或不相關的輸出。
不當內容:雖然開發者努力減少大語言模型生成冒犯性、有害或不適當的內容,但是由于訓練數據的性質、以及模型無法識別上下文或用戶意圖,因此此類情況仍有發生的可能。
九、小結
綜上所述,大語言模型能夠生成類似人類的文本、自動執行的日常任務、以及在創意和分析過程中提供各項幫助。這使得它們已成為了如今快節奏的、技術驅動的世界中,不可或缺的工具。它們不但徹底改變了自然語言處理領域,并且在提高各類角色和行業的生產力方面,顯示出了巨大的潛力。
當然,正如上文提到的,鑒于大模型的相關局限性與風險,以及可能出現的偏見、錯誤、甚至是惡意使用等問題也不容忽視。隨著我們持續將AI驅動的技術,整合到日常生活中,必須在利用其能力和確保人類監管之間取得平衡。我們只有負責任地去謹慎采用生成式人工智能技術,才能為人類更美好的未來鋪平道路。
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
508瀏覽量
10245 -
nlp
+關注
關注
1文章
487瀏覽量
22012
原文標題:時下改變AI的6大NLP語言模型
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論