 ?使用AWS Graviton降低Amazon SageMaker推理成本
?使用AWS Graviton降低Amazon SageMaker推理成本
作者:Sunita Nadampalli
Amazon SageMaker(https://aws.amazon.com/sagemaker/)提供了多種機器學習(ML)基礎設施和模型部署選項,以幫助滿足您的ML推理需求。它是一個完全托管的服務,并與MLOps工具集成,因此您可以努力擴展模型部署,降低推理成本,在生產中更有效地管理模型,并減輕操作負擔。SageMaker提供多個推理選項(https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html#deploy-model-options),因此您可以選擇最適合您工作負載的選項。
新一代CPU由于內置的專用指令在ML推理方面提供了顯著的性能提升。在本文中,我們重點介紹如何利用基于AWS Graviton3(https://aws.amazon.com/ec2/graviton/)的Amazon Elastic Compute Cloud(EC2)C7g實例(https://aws.amazon.com/blogs/aws/new-amazon-ec2-c7g-instances-powered-by-aws-graviton3-processors/),以幫助在Amazon SageMaker上進行實時推理(https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html)時將推理成本降低高達50%,相對于可比較的EC2實例。我們展示了如何評估推理性能并在幾個步驟中將您的ML工作負載切換到AWS Graviton實例。
為了涵蓋廣泛的客戶應用程序,本文討論了PyTorch、TensorFlow、XGBoost和scikit-learn框架的推理性能。我們涵蓋了計算機視覺(CV)、自然語言處理(NLP)、分類和排名場景,以及用于基準測試的ml.c6g、ml.c7g、ml.c5和ml.c6i SageMaker實例。
基準測試結果
AWS Graviton3基于EC2 C7g實例相對于Amazon SageMaker上的可比EC2實例,可以為PyTorch、TensorFlow、XGBoost和scikit-learn模型推理帶來高達50%的成本節省,同時推理的延遲也得到了降低 。
為了進行比較,我們使用了四種不同的實例類型:
? c7g.4xlarge(https://aws.amazon.com/ec2/instance-types/c7g/)
? c6g.4xlarge(https://aws.amazon.com/ec2/instance-types/c6g/)
? c6i.4xlarge(https://aws.amazon.com/ec2/instance-types/c6i/)
? c5.4xlarge(https://aws.amazon.com/ec2/instance-types/c5/)
這四個實例都有16個vCPU和32 GiB內存。
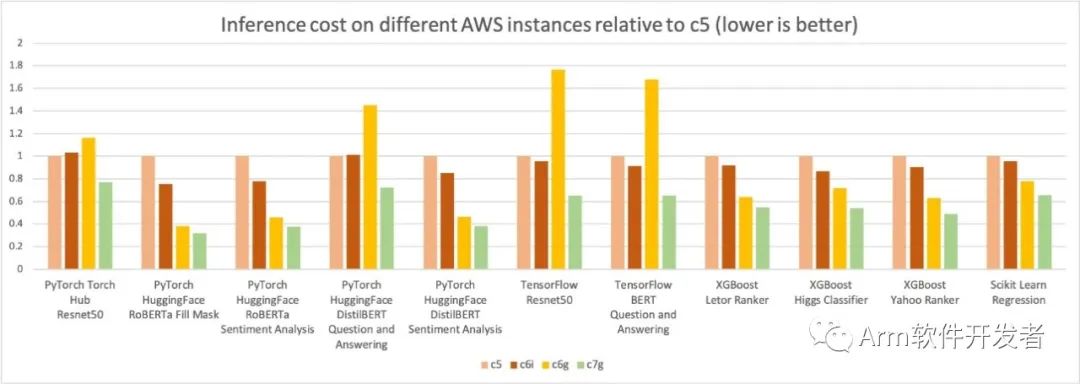
在下面的圖表中,我們測量了四種實例類型每百萬推理的成本。我們進一步將每百萬推理成本結果歸一化為c5.4xlarge實例,該實例在圖表的Y軸上測量為1。您可以看到,對于XGBoost模型,c7g.4xlarge(AWS Graviton3)的每百萬推理成本約為c5.4xlarge的50%,約為c6i.4xlarge的40%;對于PyTorch NLP模型,與c5和c6i.4xlarge實例相比,成本節省約30-50%。對于其他模型和框架,與c5和c6i.4xlarge實例相比,我們測得至少30%的成本節省。
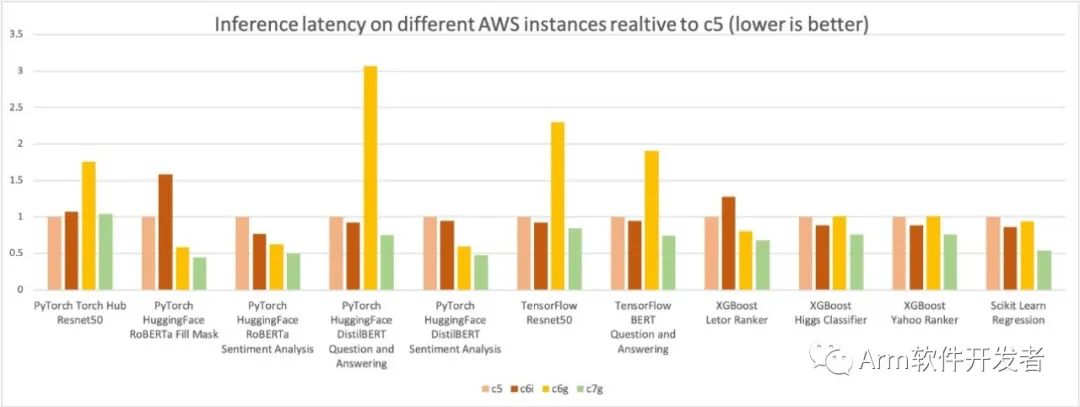
與前面的推理成本比較圖類似,下圖顯示了相同四種實例類型的模型p90延遲。我們進一步將延遲結果標準化為c5.4xlarge實例,在圖表的Y軸中測量為1。c7g.4xlarge(AWS Graviton3)模型推理延遲比在c5.4xlage和c6i.4xla格上測量的延遲高出50%。
遷移到AWS Graviton實例
要將模型部署到AWS Graviton實例,可以使用AWS深度學習容器(DLC)(https://github.com/aws/deep-learning-containers/blob/master/available_images.md#sagemaker-framework-graviton-containers-sm-support-only),也可以自帶與ARMv8.2體系結構兼容的容器(https://github.com/aws/deep-learning-containers#building-your-image)。
將模型遷移(或新部署)到AWS Graviton實例很簡單,因為AWS不僅為使用PyTorch、TensorFlow、scikit-learn和XGBoost托管模型提供容器,而且模型在架構上也是不可知的。您也可以帶上自己的庫,但請確保您的容器是用支持ARMv8.2體系結構的環境構建的。有關更多信息,請參閱構建自己的算法容器(https://sagemaker-examples.readthedocs.io/en/latest/advanced_functionality/scikit_bring_your_own/scikit_bring_your_own.html)。
您需要完成三個步驟才能部署模型:
1.創建SageMaker模型。除其他參數外,它將包含有關模型文件位置、將用于部署的容器以及推理腳本的位置的信息。(如果已經在計算優化推理實例中部署了現有模型,則可以跳過此步驟。)
2.創建端點配置。這將包含有關端點所需的實例類型的信息(例如,對于AWS Graviton3,為ml.c7g.xlarge)、在上一步中創建的模型的名稱以及每個端點的實例數。
3.使用在上一步中創建的端點配置啟動端點。
有關詳細說明,請參閱使用Amazon SageMaker在基于AWS Graviton的實例上運行機器學習推理工作負載(https://aws.amazon.com/blogs/machine-learning/run-machine-learning-inference-workloads-on-aws-graviton-based-instances-with-amazon-sagemaker/)。
性能基準管理方法
我們使用Amazon SageMaker Inference Recommender(https://docs.aws.amazon.com/sagemaker/latest/dg/inference-recommender.html)來自動化不同實例的性能基準測試。該服務根據不同實例的延遲和成本來比較ML模型的性能,并推薦以最低成本提供最佳性能的實例和配置。我們使用推理推薦器收集了上述性能數據。有關更多詳細信息,請參閱GitHub回購。
您可以使用示例筆記本(https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-inference-recommender/huggingface-inference-recommender/huggingface-inference-recommender.ipynb)來運行基準測試并再現結果。我們使用以下模型進行基準測試:
1.PyTorch–ResNet50圖像分類,DistilBERT情感分析,RoBERTa填充掩碼和RoBERTa情感分析。
2.TensorFlow–TF Hub ResNet 50和ML Commons TensorFlow BERT。
3.XGBoost和scikit learn–我們測試了四個模型,以涵蓋分類器、排序器和線性回歸場景。
結論
相對于Amazon SageMaker上的可比EC2實例,AWS使用基于Graviton3的EC2 C7g實例測量了PyTorch,TensorFlow,XGBoost和scikit-learn模型推理高達50%的成本節省。您可以按照本文提供的步驟將現有推理用例遷移到AWS Graviton或部署新的ML模型。您還可以參考AWS Graviton技術指南(https://github.com/aws/aws-graviton-getting-started),該指南提供了優化庫和最佳實踐列表,可幫助您在不同工作負載上使用AWS Graviton實例實現成本效益。
如果您發現使用情況,在AWS Graviton上沒有觀察到類似的性能提升,請與我們聯系。我們將繼續添加更多性能改進,使AWS Graviton成為最具成本效益和高效的通用ML推理處理器。”
-
cpu
+關注
關注
68文章
10826瀏覽量
211160 -
Amazon
+關注
關注
1文章
120瀏覽量
17170 -
AWS
+關注
關注
0文章
427瀏覽量
24315
原文標題:?使用AWS Graviton降低Amazon SageMaker推理成本
文章出處:【微信號:Arm軟件開發者,微信公眾號:Arm軟件開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問ESP32-WROVER-KIT如何通過AWS IoT Device Tester (IDT) 的測試?
Arm Neoverse V1的AWS Graviton3在深度學習推理工作負載方面的作用
在AWS云中使用Arm處理器設計Arm處理器
使用Arm服務器減少基因組學的時間和成本
DBS x AWS DeepRacer League將完全在線運行
AWS機器學習服務GPU成本大幅度降低,高達18%
AWS發布新一代Amazon Aurora Serverless
AWS基于Arm架構的Graviton 2處理器落地中國
中科創達成為Amazon SageMaker服務就緒計劃首批認證合作伙伴
使用AWS Graviton處理器優化的PyTorch 2.0推理
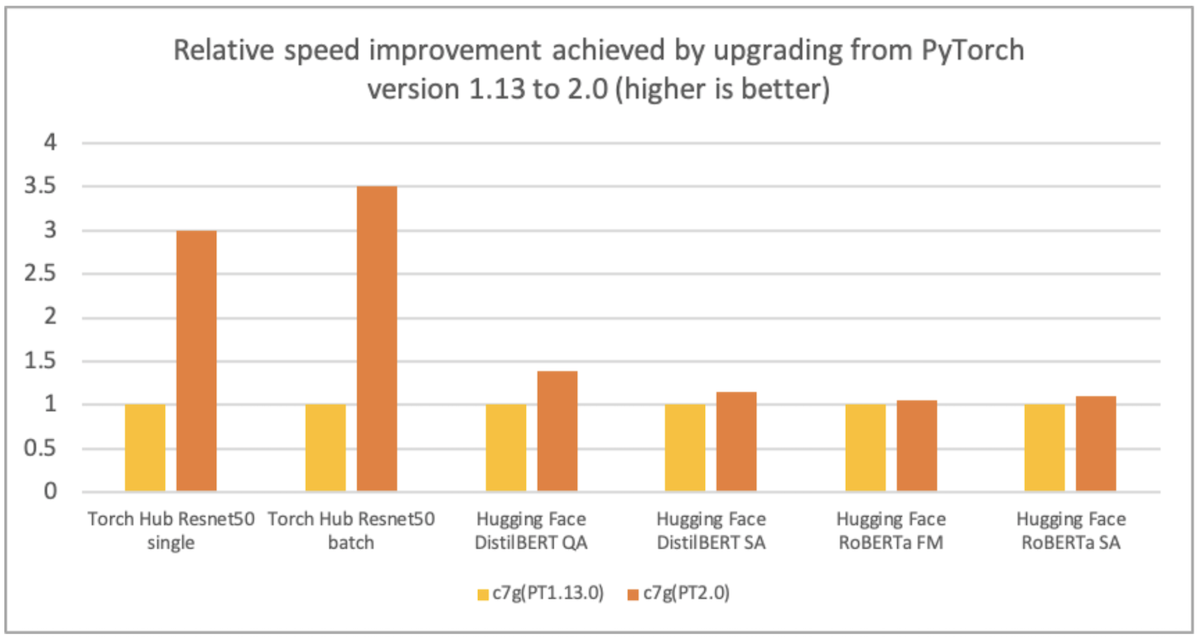
Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例






 工商網監
工商網監
評論