 清華朱軍團隊提出ProlificDreamer:直接文本生成高質量3D內容
清華朱軍團隊提出ProlificDreamer:直接文本生成高質量3D內容
清華大學 TSAIL 團隊最新提出的文生 3D 新算法 ProlificDreamer,在無需任何 3D 數據的前提下能夠生成超高質量的 3D 內容。
ProlificDreamer 算法為文生 3D 領域帶來重大進展。利用 ProlificDreamer,輸入文本 “一個菠蘿”,就能生成非常逼真且高清的 3D 菠蘿:

給出稍微難一些的文本,比如 “一只米開朗琪羅風格狗的雕塑,正在用手機讀新聞”,ProlificDreamer 的生成也不在話下:

將 Imagen 生成的照片(下圖靜態圖)和 ProlificDreamer(基于 Stable-Diffusion)生成的 3D(下圖動態圖)進行對比。有網友感慨:短短一年時間,高質量的生成已經能夠從 2D 圖像領域擴展到 3D 領域了!

A blue jay standing on alarge basket of rainbow macarons 這一切都來源于清華大學計算機系朱軍教授帶領的 TSAIL 團隊近期公開的一篇論文《ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation》:

論文鏈接:https://arxiv.org/abs/2305.16213
項目主頁:https://ml.cs.tsinghua.edu.cn/prolificdreamer/
在數字創作和虛擬現實等領域,從文本到三維模型(Text-to-3D)的技術具有重要的價值和廣泛的應用潛力。這種技術可以從簡單的文本描述中生成具體的 3D 模型,為設計師、游戲開發者和數字藝術家提供強大的工具。 然而,為了根據文本生成準確的 3D 模型,傳統方法需要大量的標記 3D 模型數據集。這些數據集需要包含多種不同類型和風格的 3D 模型,并且每個模型都需要與相應的文本描述相關聯。創建這樣的數據集需要大量的時間和人力資源,目前還沒有現成的大規模數據集可供使用。 由谷歌提出的 DreamFusion [1] 利用預訓練的 2D 文本到圖像擴散模型,首次在無需 3D 數據的情況下完成開放域的文本到 3D 的合成。但是 DreamFusion 提出的 Score Distillation Sampling (SDS) [1] 算法生成結果面臨嚴重的過飽和、過平滑、缺少細節等問題。高質量 3D 內容生成目前仍然是非常困難的前沿問題之一。 ProlificDreamer 論文提出了 Variational Score Distillation(VSD)算法,從貝葉斯建模和變分推斷(variational inference)的角度重新形式化了 text-to-3D 問題。具體而言,VSD 把 3D 參數建模為一個概率分布,并優化其渲染的二維圖片的分布和預訓練 2D 擴散模型的分布間的距離。可以證明,VSD 算法中的 3D 參數近似了從 3D 分布中采樣的過程,解決了 DreamFusion 所提 SDS 算法的過飽和、過平滑、缺少多樣性等問題。此外,SDS 往往需要很大的監督權重(CFG=100),而 VSD 是首個可以用正常 CFG(=7.5)的算法。效果展示ProlificDreamer 可以根據文本生成非常高質量的帶紋理的三維網格:

ProlificDreamer 可以根據文本生成非常高質量的三維神經輻射場(NeRF),包括復雜的效果。甚至 360° 的場景也能生成:

ProlificDreamer 還可以在給出同樣文本的情況下生成具有多樣性的 3D 內容:

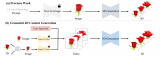
傳統文生 3D 的優化算法給定一個 2D 圖片上預訓練好的擴散模型(例如 stable-diffusion),Dreamfusion [1] 提出可以在不借助任何 3D 數據的情況下實現開放域的文到 3D 內容(text-to-3D)生成。具體而言,對于一個 3D 物體,文生 3D 任務的關鍵是設計一種優化算法,使得 3D 物體在各個視角下投影出來的 2D 圖片與預訓練的 2D 擴散模型匹配,并不斷優化 3D 物體。其中,SDS [1] (也稱為 Score Jacobian Chaining (SJC) [3]) 是目前幾乎所有的零樣本開放域文生 3D 工作所使用的算法。該算法將 3D 物體視為一個單點(single point),并通過隨機梯度下降優化該 3D 物體,優化目標是最大化該渲染的 2D 圖像在預訓練擴散模型下的似然值。值得注意的是,該優化問題的最優解并不等價于從擴散模型中采樣。
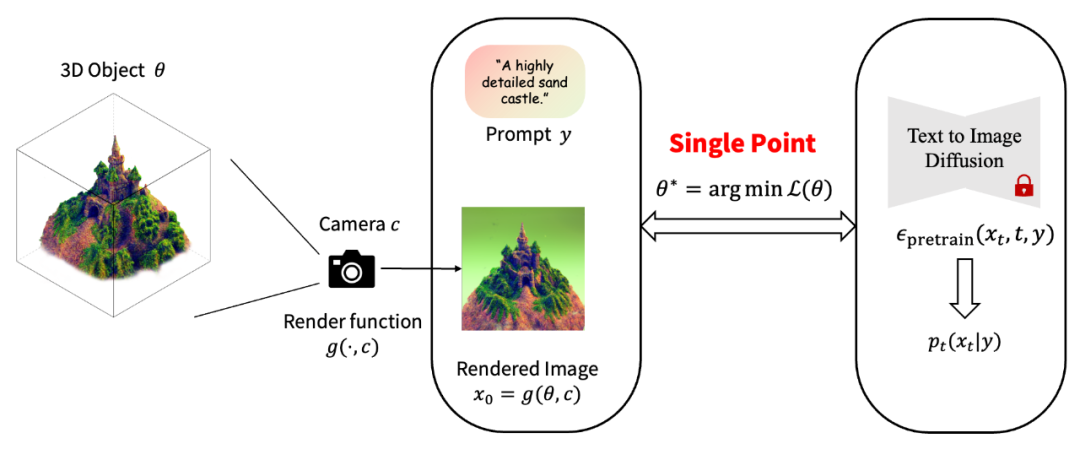
傳統文生 3D 的優化算法示意圖 實驗中,所有基于 SDS/SJC 的方法目前都有一個嚴重的問題:生成的物體過于平滑、過飽和現象嚴重,并且多樣性不高。例如,開源庫 threestudio [4] 將目前主流的 text-to-3D 工作復現至與原論文可比水平,如下圖所示:

由 threestuidio [4] 復現的文生 3D 工作 在此之前,基于 2D 擴散模型的文生 3D 仍然與實踐落地有較大差距。然而,清華大學朱軍團隊提出的 ProlificDreamer 在算法層面解決了 SDS 的上述問題,能夠生成非常逼真的 3D 內容,極大地縮小了這一差距。ProlificDreamer 的原理與以往方法不同,ProlificDreamer 并不單純優化單個 3D 物體,而是優化 3D 物體對應的概率分布。通常而言,給定一個有效的文本輸入,存在一個概率分布包含了該文本描述下所有可能的 3D 物體。
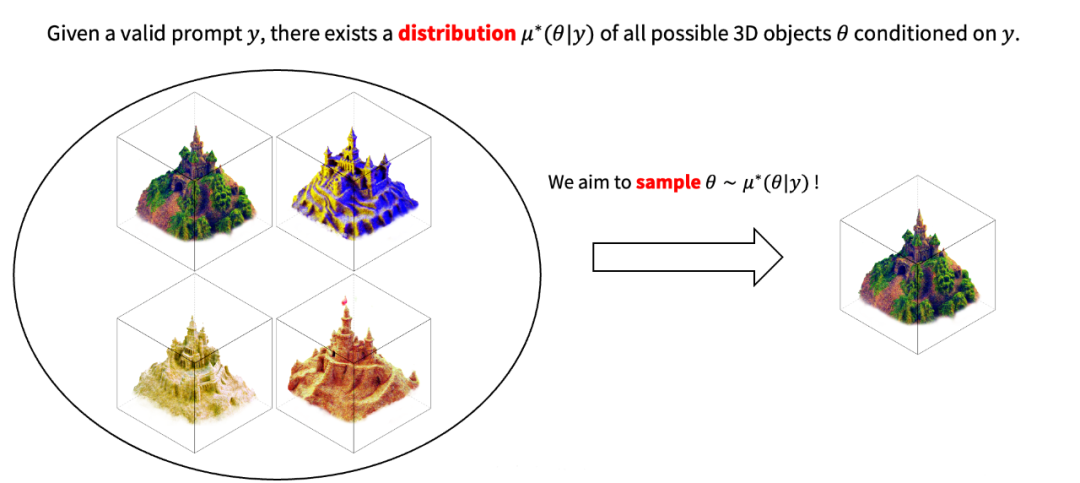
給定文本下的 3D 物體存在一個潛在的概率分布 基于該 3D 概率分布,我們可以進一步誘導出一個 2D 概率分布。具體而言,只需要對每一個 3D 物體經過相機渲染到 2D,即可得到一個 2D 圖像的概率分布。
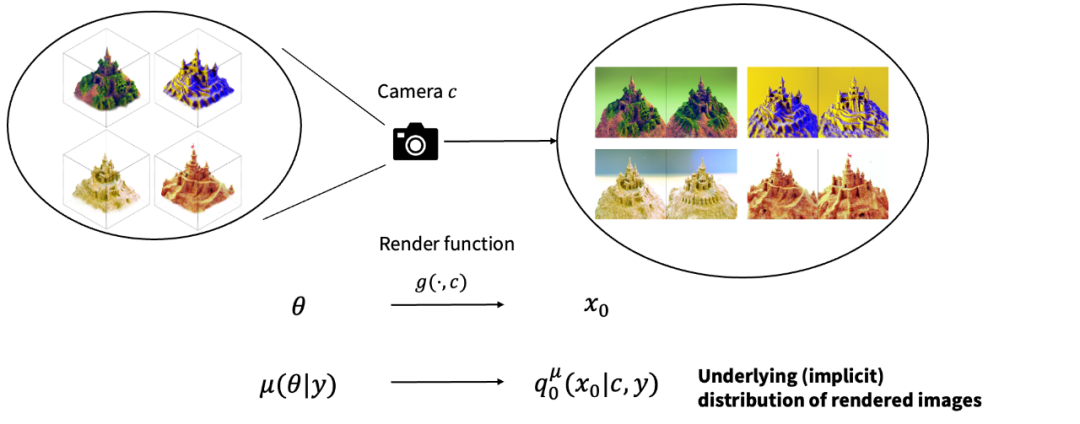
由潛在 3D 分布可以誘導出一個 2D 圖像分布 因此,優化 3D 分布可以被等效地轉換為優化 2D 渲染圖片的概率分布與 2D 擴散模型定義的概率分布之間的距離(由 KL 散度定義)。這是一個經典的變分推斷(variational inference)任務,因此 ProlificDreamer 文中將該任務及對應的算法稱為變分得分蒸餾(Variational Score Distillation,VSD)。
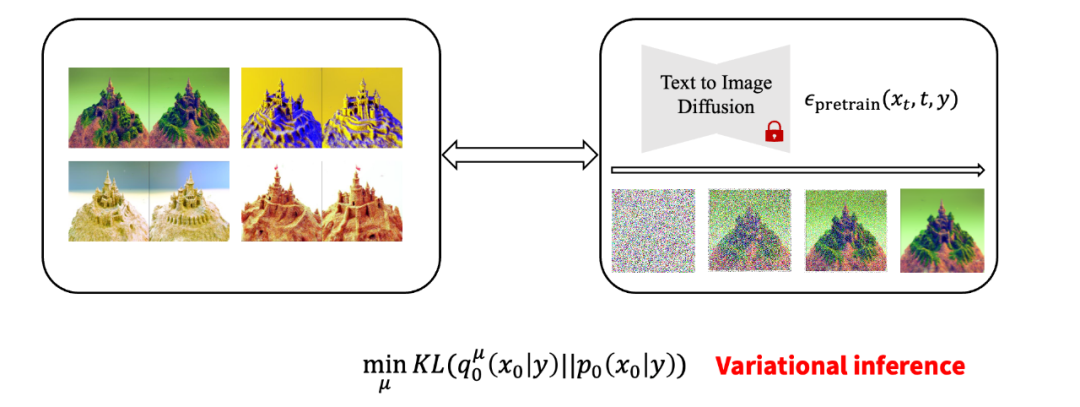
優化 3D 分布可以被等效地轉換為優化 2D 圖片之間的概率分布 具體而言,VSD 的算法流程圖如下所示。其中,3D 物體的迭代更新需要使用兩個模型:一個是預訓練的 2D 擴散模型(例如 Stable-Diffusion),另一個是基于該預訓練模型的 LoRA(low-rank adaptation)。該 LoRA 估計了當前 3D 物體誘導的 2D 圖片分布的得分函數(score function),并進一步用于更新 3D 物體。該算法實際上在模擬 Wasserstein 梯度流,并可以保證收斂得到的分布滿足與預訓練的 2D 擴散模型的 KL 散度最小。
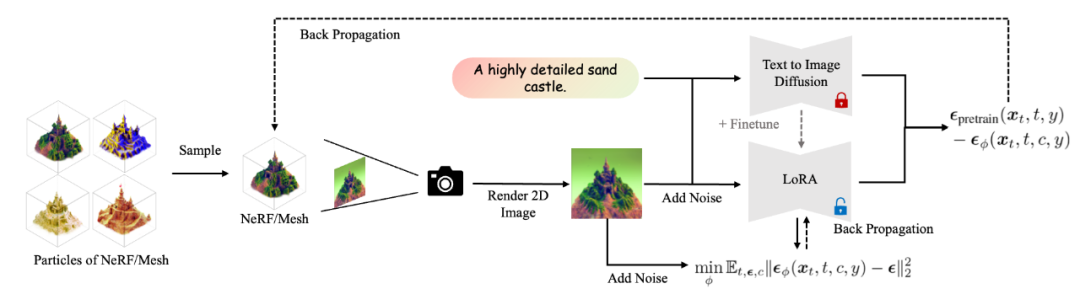
VSD 的訓練流程圖 與傳統的 SDS/SJC 算法相比,可以發現 VSD 僅僅需要把原來的高斯噪聲項換成 LoRA 項即可。由于LoRA 提供了比高斯噪聲更精細的更新方向(例如,LoRA 可以利用文本 y、相機視角 c、擴散時間 t 等的先驗信息),VSD 在實踐中可以得到遠超 SDS 的精細結果。并且,論文作者提出,SDS/SJC 實際上是 VSD 使用一個單點 Dirac 分布作為變分分布的特例,而 VSD 擴展到了由 LoRA 定義的更復雜的概率分布,因此可以得到更好的結果。此外,VSD 還對監督權重(CFG)更友好,可以使用與 2D 擴散模型一樣的監督權重(例如 stable-diffusion 常用的 CFG=7.5),因此可以達到和 2D 擴散模型類似的采樣質量。這一結果首次解決了 SDS/SJC 中的超大 CFG(一般為 100)的問題,也同時說明 VSD 這種基于分布優化的思想與預訓練的 2D 擴散模型更適配。
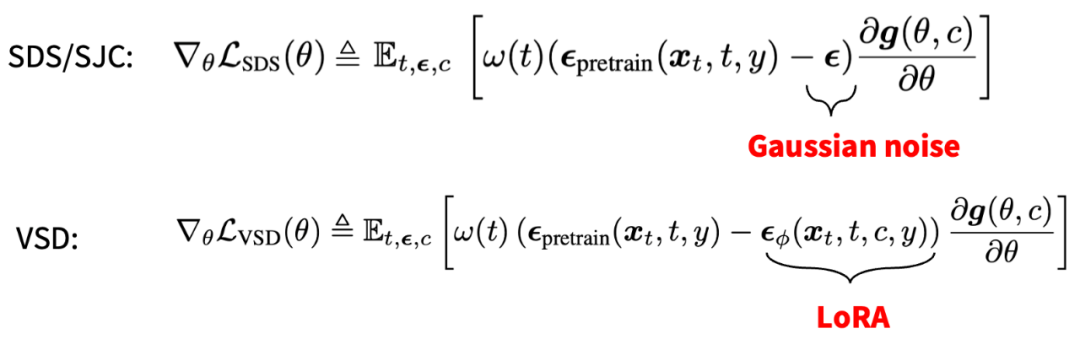
SDS/SJC 與 VSD 的更新公式對比 最后,ProlificDreamer 還對 3D 表示的設計空間做了詳細的研究,提出了如下實現。在實踐中,VSD 可以在 512 渲染分辨率的 NeRF 下訓練,并極大地豐富了所得到的 3D 結果的紋理細節。
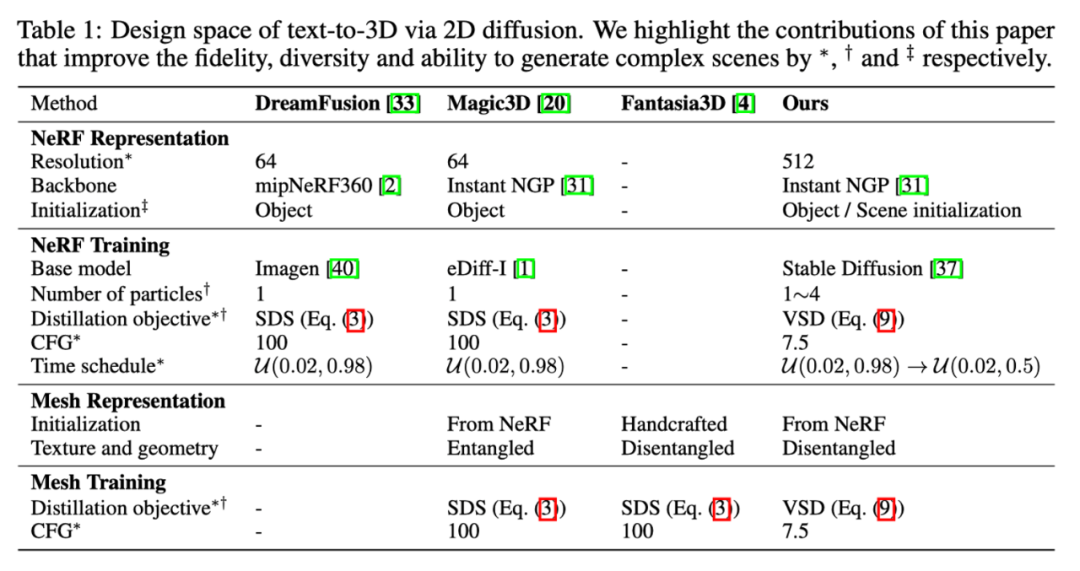
ProlificDreamer 與其它工作的實現細節比較
審核編輯 :李倩
-
3D
+關注
關注
9文章
2863瀏覽量
107328 -
算法
+關注
關注
23文章
4599瀏覽量
92643 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:無需任何3D數據!清華朱軍團隊提出ProlificDreamer:直接文本生成高質量3D內容
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何設計高質量低成本的3D眼鏡_Designing Cost-Effective 3D Technol...
阿里3D AI技術已成功應用諸多場景中,可迅速批量生產高質量3D模型
面向社交媒體的高質量文章內容識別模型
基于視覺注意力的全卷積網絡3D內容生成方法
文本生成任務中引入編輯方法的文本生成

NVIDIA提出Magic3D:高分辨率文本到3D內容創建
Meta提出Make-A-Video3D:一行文本,生成3D動態場景!
面向結構化數據的文本生成技術研究

生成高質量 3D 網格,從重建到生成式 AI

3D人體生成模型HumanGaussian實現原理
Adobe提出DMV3D:3D生成只需30秒!讓文本、圖像都動起來的新方法!






 工商網監
工商網監
評論