 Cortex-M核心寄存器和位域
Cortex-M核心寄存器和位域
我相信昨天的文章你一定大飽眼福了,沒關系,接下來的更精彩,也會對C語言有個全新的理解。
今天這個文件屬于CM3核心定義:有CMSIS核心的所有結構和符號
Cortex-M核心寄存器和位域,Cortex-M核心外設基址。
今天的對象在這里
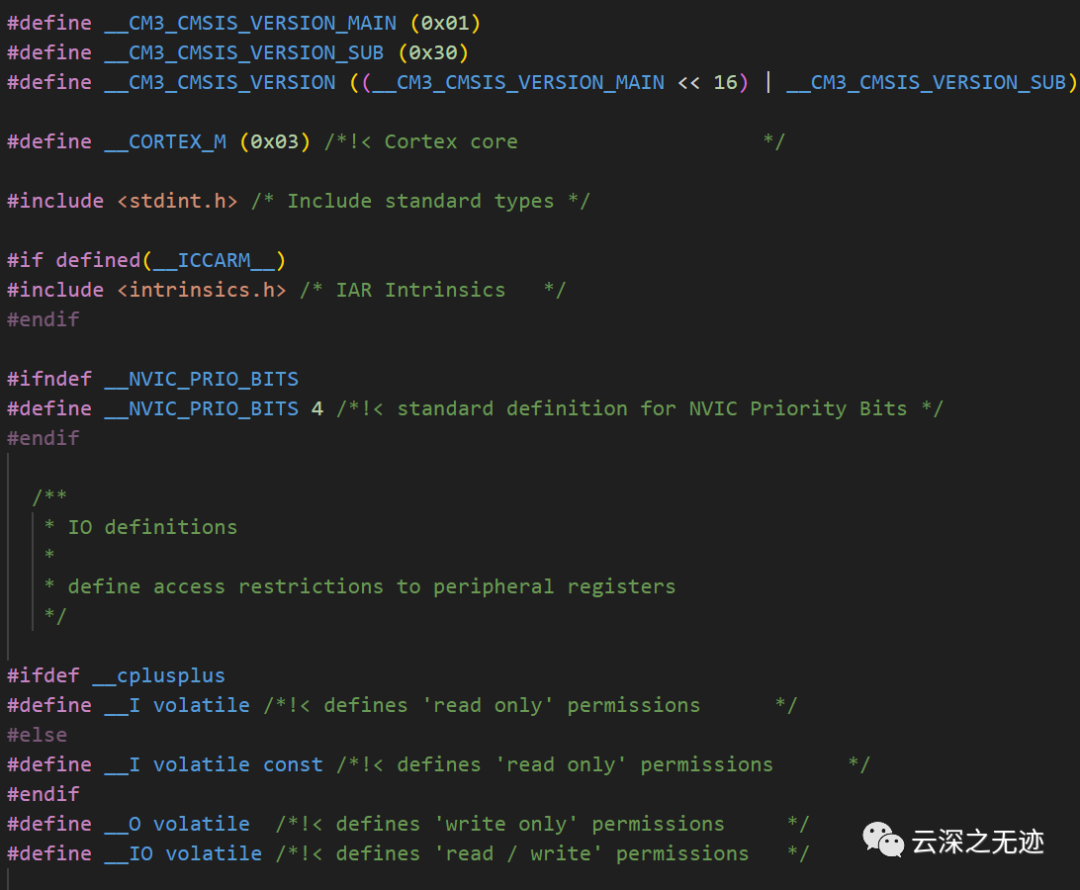
先看h文件的前面幾行
根據前面三行宏定義,最終計算出的CMSIS HAL庫完整版本號為:__CM3_CMSIS_VERSION = (0x01 << 16) | 0x30 = 0x010030所以,完整的版本號為0x010030。
其中:__CM3_CMSIS_VERSION_MAIN = 0x01,主版本號為0x01__CM3_CMSIS_VERSION_SUB = 0x30,子版本號為0x30通過左移16位實現主版本號 occupies 的高16位,子版本號占低16位,然后按位或生成完整32位的版本號0x010030。
這個32位版本號包含了CMSIS HAL庫的主版本號與子版本號信息,通過該版本號,根據這三行宏定義,可以知道當前使用的CMSIS HAL庫的版本號為0x010030。其中高16位0x01表示主版本號,低16位0x30表示子版本號。
0x010030
= 0x01 * (2^16) + 0x30 * (2^0)
= 1 * 65536 + 48 * 1
= 65536 + 48
= 65680
這是轉成10進制的數字。
其中,主版本號0x01對應的10進制數為1,子版本號0x30對應的10進制數為48。
通過將主版本號的值×2^16,子版本號的值×2^0相加,我們可以得出CMSIS HAL庫完整版本號對應的10進制數65680。
這個10進制數同樣包含了主版本號1和子版本號48的信息,我們可以清楚知道當前使用的CMSIS HAL庫版本號為1.48。
1代表主版本號,48代表子版本號,兩者組合即為完整版本號1.48。
所以,總結來說,CMSIS-HAL庫的版本號0x010030
可以表示為:
Hex: 0x010030
Decimal: 65680
Version: 1.48
那不免有疑問,明明可以直接10進制文件的,為啥這么復雜呢?讓我來斗膽的分析一下。
主要有以下幾個考慮因素:
1. 兼容性:使用位運算生成的版本號格式0x010030與CMSIS HAL庫一致,這樣可以最大限度保證與庫的兼容性。
2. 擴展性:使用位運算,主版本號占高16位,子版本號占低16位,這樣主版本號可以擴展到65536,子版本號也有很高擴展空間,更利于版本的長期維護與擴展。
3. 信息包含:32位的版本號可以同時包含主版本號與子版本號,一目了然,這個信息直接清楚可見。如果只使用1.48形式,無法同時看到主子版本號的值,信息表達不夠直接。
4. 處理方便:位運算生成的版本號可以通過簡單的移位與位運算提取主版本號與子版本號的值,這在編程處理時比較方便。
5. 標準形式:0x開頭的十六進制數是MCU編程中常用的標準表達形式,使用起來比較習慣。
所以,總體來說,雖然直接使用1.48的形式更簡單直觀,但使用位運算生成0x010030格式的版本號,可以在兼容性、擴展性、信息包含以及處理方便性等方面獲得優勢,也符合編程習慣的標準表達形式。考慮到CMSIS HAL庫作為MCU的底層支撐庫,需要長期維護與迭代,所以選擇使用位運算生成版本號格式可以獲得更多優點,這可能也是CMSIS HAL庫設計者選擇這種版本號格式的主要考量因素。
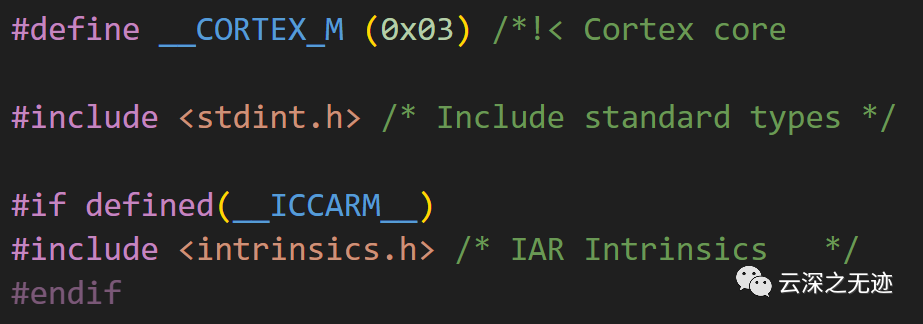
接下來看這個
這段代碼主要完成了MCU內核類型與數據類型的定義。
__CORTEX_M (0x03) 此宏定義指定了內核類型為Cortex-M3,其十六進制值為0x03。
#include 此行包含stdint.h頭文件,用于定義標準數據類型,如Uint8_t、int32_t等。
#if defined(__ICCARM__) 此行條件判斷是否使用IAR編譯器,如果使用則包含intrinsics.h頭文件。
#include 此行包含intrinsics.h頭文件,該頭文件定義了IAR C/C++編譯器的內嵌匯編指令。
所以,這段代碼主要完成了兩方面的工作:
1. 通過__CORTEX_M宏定義指定了MCU使用的內核類型為Cortex-M3。2. 包含stdint.h頭文件,定義了標準的數據類型,用于MCU開發時使用。
3. 如果使用IAR編譯器,則額外包含intrinsics.h頭文件,可以使用IAR編譯器提供的內嵌匯編指令。
這段簡短的代碼定義和包含了MCU開發最基礎的信息:
1. 內核類型:我們知道目標MCU使用的內核是Cortex-M3。
2. 數據類型:通過stdint.h我們可以使用標準的數據類型,如Uint32_t等。
3. 如果使用IAR編譯器,可以使用內嵌匯編指令來優化程序。
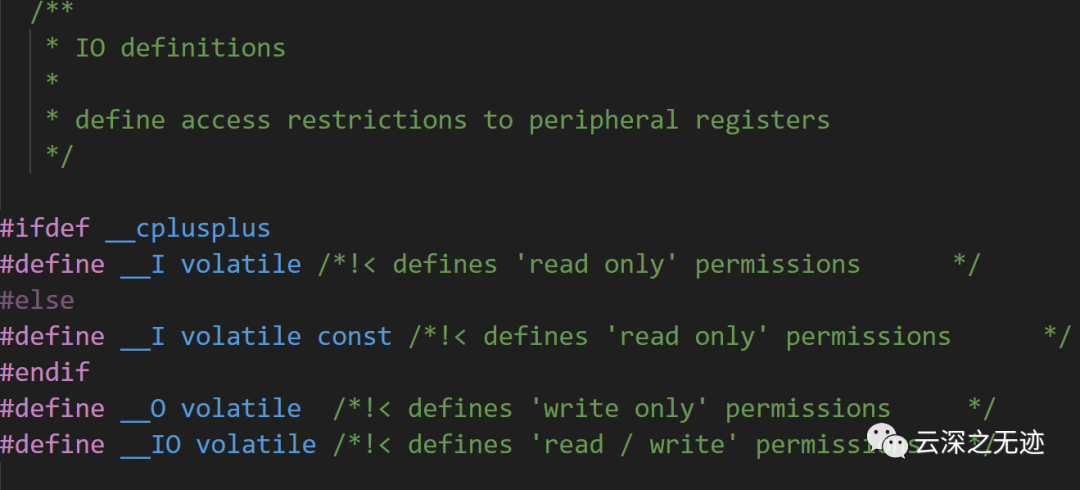
這幾個macro是頻繁出現的,細說一下
這段代碼主要定義了中斷優先級位數和IO操作權限。
#ifndef __NVIC_PRIO_BITS
#define __NVIC_PRIO_BITS 4
#endif
這兩行定義了中斷優先級位數為4,如果__NVIC_PRIO_BITS未定義,則進行定義,否則忽略。
#ifdef __cplusplus
#define __I volatile
#else
#define __I volatile const
#endif
這幾行判斷是否使用C++編譯器,如果使用C++編譯器,__I定義為volatile,否則定義為volatile const,表示只讀屬性。
#define __O volatile
此行定義__O為volatile,表示只寫屬性。
#define __IO volatile
此行定義__IO為volatile,表示讀寫屬性。
所以,這段代碼主要完成了:
1. 如果__NVIC_PRIO_BITS未定義,則定義中斷優先級位數為4。否則忽略。
2. 根據編譯器選擇定義只讀屬性__I為volatile或volatile const。
3. 定義只寫屬性__O為volatile。
4. 定義讀寫屬性__IO為volatile。
5. 這四個屬性主要用于定義外設寄存器的訪問權限,以確保編譯器不會對訪問的代碼作優化,影響讀取的準確性。
也就是說,這段代碼為寄存器的訪問屏蔽了編譯器的優化,在編譯過程中讓編譯器明確區分:
這是一個只讀寄存器,值可能會被其他因素改變,讀取時總是獲取最新值。
這是一個只寫寄存器,每次寫入的值必須被外設接收。
這個寄存器是可讀寫的,讀取與寫入都必須準確地映射到外設。這樣可以最大限度地確保我們的程序以預期的方式使用這些寄存器,也不會因為編譯器的優化而導致意外的結果。
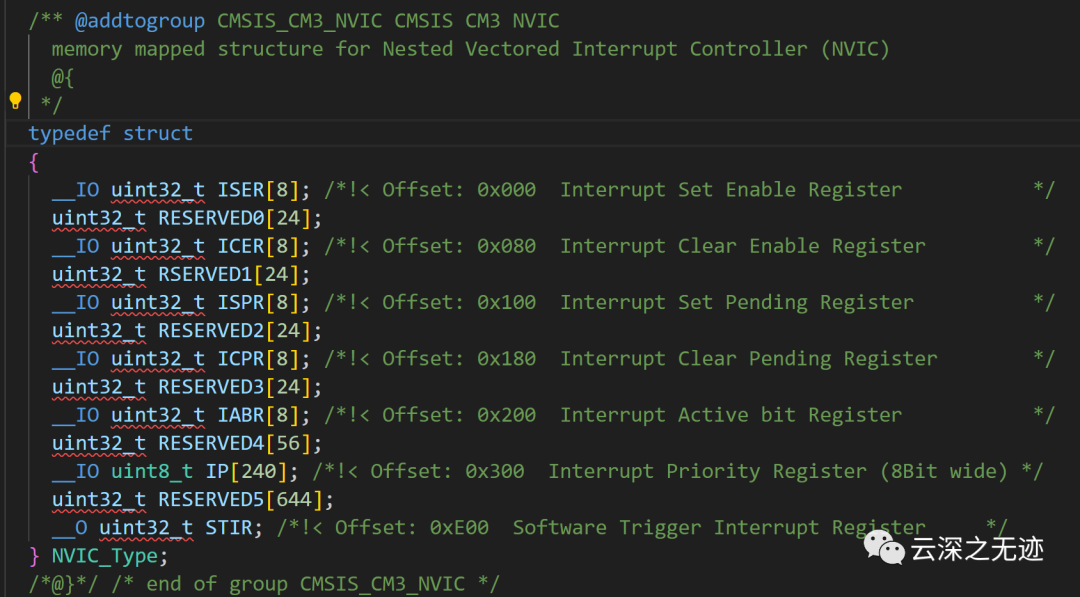
接下來我們看這個,知識點有點密集

中斷到中斷向量的映射
顯示了中斷(或IRQ號)如何映射到中斷寄存器和相應的CMSIS變量(每個中斷有一位)。
這段代碼定義了NVIC_Type結構體,用于表示NVIC(嵌套向量中斷控制器)的控制與狀態寄存器。
NVIC_Type結構體包含以下成員:
__IO uint32_t ISER[8]; 中斷使能置位寄存器,用于使能中斷,數組8個成員對應NVIC的8個中斷組。
__IO uint32_t ICER[8]; 中斷清除使能寄存器,用于禁止中斷,數組8個成員對應NVIC的8個中斷組。
__IO uint32_t ISPR[8]; 中斷待處理置位寄存器,用于置位某中斷的待處理標志,數組8個成員對應NVIC的8個中斷組。
__IO uint32_t ICPR[8]; 中斷待處理清除寄存器,用于清除某中斷的待處理標志,數組8個成員對應NVIC的8個中斷組。
__IO uint32_t IABR[8]; 中斷激活寄存器,指示哪些中斷被激活,數組8個成員對應NVIC的8個中斷組。
__IO uint8_t IP[240]; 中斷優先級寄存器,設置優先級,共240個成員,每個成員1字節,對應MCU中的240個中斷優先級設置。
__O uint32_t STIR; 軟件觸發中斷寄存器,用于軟件觸發指定的中斷。
所以,這個結構體包含了NVIC所有的控制與狀態寄存器,通過這些寄存器,我們可以完成:
1. 中斷使能與失能設置。
2. 中斷待處理標志的置位與清除。
3. 檢測哪些中斷被激活。
4. 設置各個中斷的優先級。
5. 軟件觸發某個指定的中斷。
簡單來說,這個結構體高度抽象和集成地代表了NVIC及其所有的功能與控制寄存器,使用時直接通過相應的成員來操作寄存器。
這個NVIC_Type結構體代表的不是某個具體的存儲區域,而是概念性地將NVIC所有的寄存器集成在一個結構體中,以方便我們管理和訪問這些寄存器。
結構體中的每個成員,如__IO uint32_t ISER[8]都代表NVIC中的一個實際的32位寄存器。
這些寄存器的地址在MCU的外設地址映射中已經固定,結構體將它們邏輯上集成在一起,方便我們按功能管理和訪問。
所以,當我們需要操作NVIC使能某個中斷時,只需要像下面這樣使用ISER成員:
NVIC->ISER[2]|=(1<
在MDK或IAR等IDE中,這些寄存器的具體地址將在外設地址映射Memap窗口中顯示。
例如,ISER[2]可能映射到0xE000E200這樣的實際地址,這個地址上的32位寄存器包含對應的位用于使能第6個中斷。
所以,總結來說:
1. NVIC_Type 結構體邏輯上將NVIC的所有寄存器集成在一起,方便管理和訪問,但本身不代表實際的存儲區域。
2. 結構體中的每個成員代表NVIC中的一個實際物理寄存器,映射到固定的地址。
3. 我們通過結構體操作這些寄存器,然后編譯器會將其映射到實際的物理地址上。
4. 這些寄存器的具體地址將在MCU的外設地址映射中指定,我們可以在IDE的Memap窗口中查看。
5. 所以結構體更像是一個邏輯上的抽象,將NVIC的寄存器方便地集成在一起,在程序中按功能管理和訪問。
 更多詳細的內容得看這個
更多詳細的內容得看這個

嵌套中斷矢量控制器
Cortex-M3 NVIC寄存器的CMSIS映射為了提高軟件效率,CMSIS簡化了NVIC寄存器的表示。
在CMSIS中:Set-enable, Clear-enable, Set-pending, Clear-pending和Active Bit寄存器映射到32位整數數組,因此:
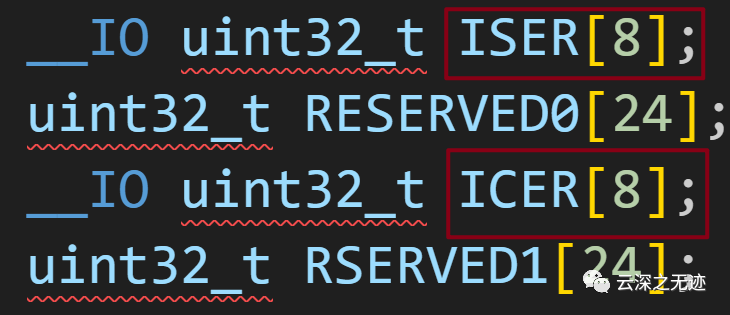
看這個IS,IC,下面就不放了
數組ISER[O] ~ ISER[2]對應寄存器ISERO-ISER2,
數組ICER[O] ~ ICER[2]對應寄存器ICERO-ICER2,
數組ISPR[0] ~ ISPR[2]對應寄存器ISPRO-ISPR2,
數組ICPR[O] ~ ICPR[2]對應寄存器ICPRO-ICPR2,
數組IABR[O] ~ IABR[2]對應寄存器IABRO-IABR2。
中斷優先級寄存器的8位字段映射到一個8位整數數組,因此數組IP[O]到IP[67]對應于寄存器IPRO-IPR67,數組]條目IP[n]保持中斷n的中斷優先級。
CMSIS提供線程安全的代碼,提供對中斷優先級寄存器的原子訪問。
我繼續說更多的細節,__IO uint32_t ISER[8];比如這種寫法前面的__IO 是干嘛用的?我來解釋一下,看不懂的應該是沒學過C。
__IO的定義如下:
#define __IO volatile
它被定義為volatile,意味著ISER[8]成員所代表的寄存器是一個讀寫寄存器。
所以,__IO的作用是:
1.通知編譯器ISER[8]成員所對應寄存器的讀寫屬性,是可讀可寫的。
2.阻止編譯器對讀寫這些寄存器的代碼做優化。因為這些寄存器的值可能會被其他因素改變,每次讀寫的值必須準確對應于寄存器的當前值。如果不使用__IO對其進行修飾,編譯器在編譯過程中可能會對訪問這些寄存器的代碼作優化,這會導致我們讀到的值不是寄存器的真實值,產生意外的后果。
所以,__IO關鍵字通過定義為volatile,告訴編譯器:
1. ISER[8]成員代表的寄存器是可讀可寫的。
2. 每次讀取該寄存器必須從外設獲取最新值,寫入時必須將新值準確寫入外設。
3. 編譯器在編譯過程中不得對其進行任何優化。
簡單來說,__IO關鍵字修飾uint32_t ISER[8]成員,目的是通知編譯器其對應的寄存器屬性和訪問要求,進而阻止編譯器的優化,確保我們的程序以預期的方式正確訪問這些寄存器。這有利于我們編寫的代碼正常工作,不會因為編譯器的優化引入意外的副作用,訪問寄存器時總是獲取最新的準確值。
說完了嗎?還沒有,我還想bibi幾句:
在C語言中,__IO這樣在標識符(如結構體成員名)前面加上的關鍵字被稱為修飾符(qualifier)。修飾符的作用是為標識符添加某種屬性或額外的語義。__IO 就是一個典型的修飾符例子,它被用來表示標識符代表的是一個讀寫寄存器,并禁止編譯器對其優化。
所以,__IO 在這里相當于一個寄存器的修飾符,為其添加讀寫以及volatile 的屬性。
在C語言中,常見的修飾符還有:
1.const:常量修飾符,用于表示標識符是一個常量。
2.volatile:指示值可能會被其他因素改變的修飾符,告訴編譯器每次讀取該值必須重新從內存中獲取。
3.restrict:表示某指針是唯一訪問某塊內存的手段,可以用來提高效率。
4.inline:表示該函數是內聯函數,由編譯器直接將函數體插入調用處。
5. extern:表示該標識符(如變量或函數)的定義在其他地方,extern int a;
所以,總結來說:
1.修飾符是放在標識符(如變量名、函數名、結構體成員名)前面的關鍵字。2.修飾符的作用是為標識符添加某種屬性或語義。
3.__IO 是作為寄存器修飾符使用的,表示寄存器是可讀寫的,并禁止編譯器對其優化。
4.const、volatile、restrict、inline、extern都是常見的修飾符,用來表示常量性、值變化、函數內聯等屬性。
5.使用修飾符可以為程序添加重要的額外信息,引導編譯器作出正確的處理。
再擴展一些,這個東西可以在函數上面用嗎?我這里先噴,以前不懂這個群里面問半天,結果都雞兒半桶水,讓我寫什么程序自己實驗,真心累啊。
在C語言中修飾符也可以用于修飾函數。
常見的用于修飾函數的修飾符有:
1. inline:表示該函數是內聯函數,主要作用是鼓勵編譯器將函數體直接插入所有調用點,以減少函數調用的開銷。
2. extern:表示該函數的定義在其他地方,用于函數前向聲明。例如: inline void func1() { ... } // 內聯函數
extern void func2(); // 函數前向聲明
void func2() { ... } // 函數定義 在這個例子中:
func1被inline修飾,表示其是一個內聯函數,編譯器可以選擇將其函數體插入調用處。
func2首先被extern修飾,進行前向聲明,然后給出函數定義。
另外,static、volatile 等修飾符也可以用于修飾函數,區別如下:
static:static修飾的函數只在定義它的文件內可見,表示私有函數。
volatile:volatile修飾的函數其地址可能改變,每次調用時必須從內存中獲取最新地址。
主要用于嵌入式中斷函數等。所以,總結來說:
1.C語言中的修飾符不僅可以用于修飾變量,也可以用于修飾函數。
2.常見的用于修飾函數的修飾符有inline、extern、static、volatile等。3.inline表示內聯函數,extern表示函數前向聲明,static表示私有函數,volatile表示地址可能改變的函數。
4.使用修飾符可以為函數添加額外的屬性和語義,引導編譯器生成我們期望的代碼,這在優化程序性能方面具有很好的作用。
那我在這個函數前面就放一個用宏定義的修飾符,宏什么都不定義。這個會報錯了,一定要記住程序是最確定的東西。
#define __MY_MODIFIER
__MY_MODIFIER void func() { ... }
這里的__MY_MODIFIER宏未進行任何定義,所以編譯器并不知道它表示什么屬性或語義。在編譯這個代碼時,編譯器會報類似下面的錯誤:undefined identifier '__MY_MODIFIER'這是因為編譯器并不識別__MY_MODIFIER這個未定義標識符,所以不明白它作為函數修飾符的作用,這會導致編譯錯誤。要使用我們自己定義的修飾符,需要為其給出明確的定義,例如:
#define __MY_MODIFIER static
__MY_MODIFIER void func() { ... }
這里我們定義__MY_MODIFIER為static,這樣編譯器就能理解其作用,并將func函數定義為靜態的。所以,總結來說:1. 若要使用自定義的修飾符,必須為其給出明確的定義,否則編譯器無法理解其作用,會報錯。2.自定義修飾符的定義可以通過#define來實現,例如#define __MY_MODIFIER static。3. 定義后,修飾符可以用于修飾變量、函數等,編譯器會根據其定義來理解其修飾的作用。4. 未定義的修飾符會導致編譯錯誤,因為編譯器不知道如何處理這個未知的標識符。5. 自定義修飾符的一個重要應用就是,當標準修飾符無法滿足需要時,我們可以定義自己的修飾符來擴展語言和表達程序語義。

對于這個中斷的寄存器就是這些,不要陷入太深,繼續往下看
系統控制塊(SCB)系統控制塊(System control block, SCB)提供系統實現信息和系統控制。這包括系統異常的配置、控制和報告。
Cortex-M3 SCB寄存器的CMSIS映射為了提高軟件效率,CMSIS簡化了SCB寄存器的表示。
在CMSIS中,字節數組SHP[0]到SHP[12]對應寄存器SHPR1-SHPR3。
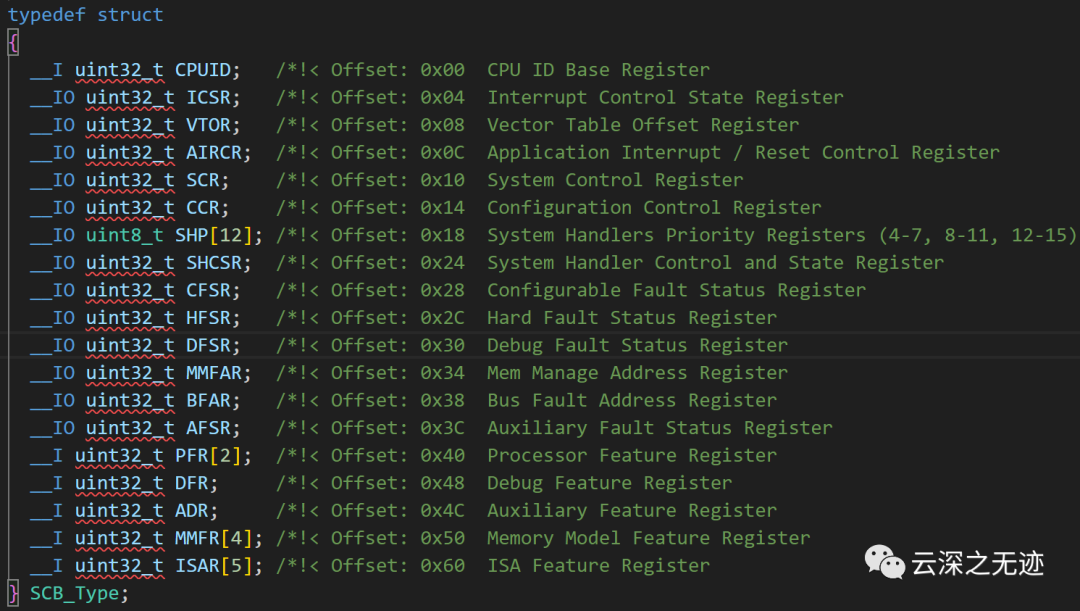
接著就是這個了
這個結構體定義了SCB(系統控制塊)的寄存器集。SCB模塊是Cortex-M內核的一部分,用于系統控制與配置。
SCB_Type 結構體包含以下主要成員:
__I uint32_t CPUID; CPUID寄存器,包含設備ID和修訂信息。
__IO uint32_t ICSR; 中斷控制狀態寄存器,用于中斷使能、優先級設置和掛起狀態控制。
__IO uint32_t VTOR; 向量表偏移寄存器,配置中斷/異常向量表的位置和偏移。
__IO uint32_t AIRCR; 應用中斷/復位控制寄存器,用于配置中斷優先級組和系統復位。
__IO uint32_t SCR; 系統控制寄存器,用于配置中斷優先級組、SLEEPDEEP位等。
__IO uint32_t CCR; 配置控制寄存器,用于配置存儲器mapped模式和無效指令報告位。
__IO uint8_t SHP[12]; 系統句柄程序優先級寄存器,設置不同異常的優先級。
__IO uint32_t SHCSR; 系統句柄控制和狀態寄存器,報告不同異常的掛起和激活狀態。
CFSR、HFSR、DFSR; 可配置故障狀態寄存器,用于報告各種故障和異常的狀態。
MMFAR、BFAR;內存錯誤和總線故障地址寄存器,報告相關故障的地址。PFR、DFR、ADR; 寄存器用于報告處理器特征、調試功和輔助功能。MMFR、ISAR; 寄存器用于報告內存模型和指令集架構的特征。
所以,SCB_Type結構體包含SCB模塊所有的控制/狀態寄存器和ID寄存器,通過這些寄存器我們可以完成:
1. 中斷控制(使能/禁止)和優先級設置。
2. 配置向量表位置和系統復位。
3. 設置不同異常的優先級別。
4. 獲取設備ID、內核修訂版本以及各種特征信息。
5. 獲取并處理不同類型的故障和異常。
6. 配置系統控制位,如SLEEPDEEP。
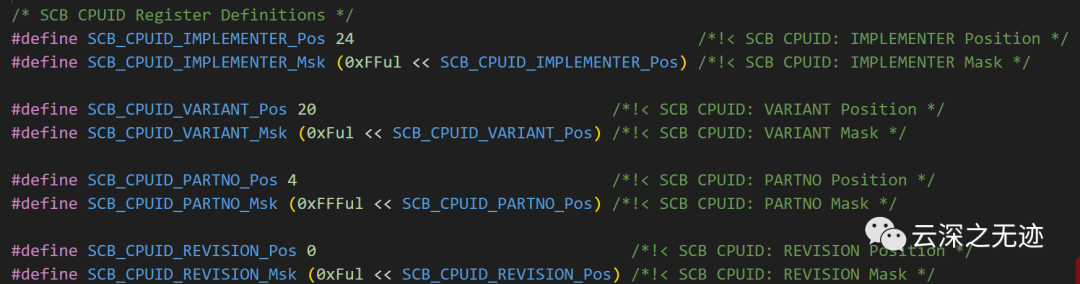
接下來定義的是這樣的東西,本來這種細節的東西就不寫了,但是為了精通這個小目標是要寫的。
上面這個代碼可能看起來有點懵逼,這里其實都是底層的寄存器,不妨去看看這個:
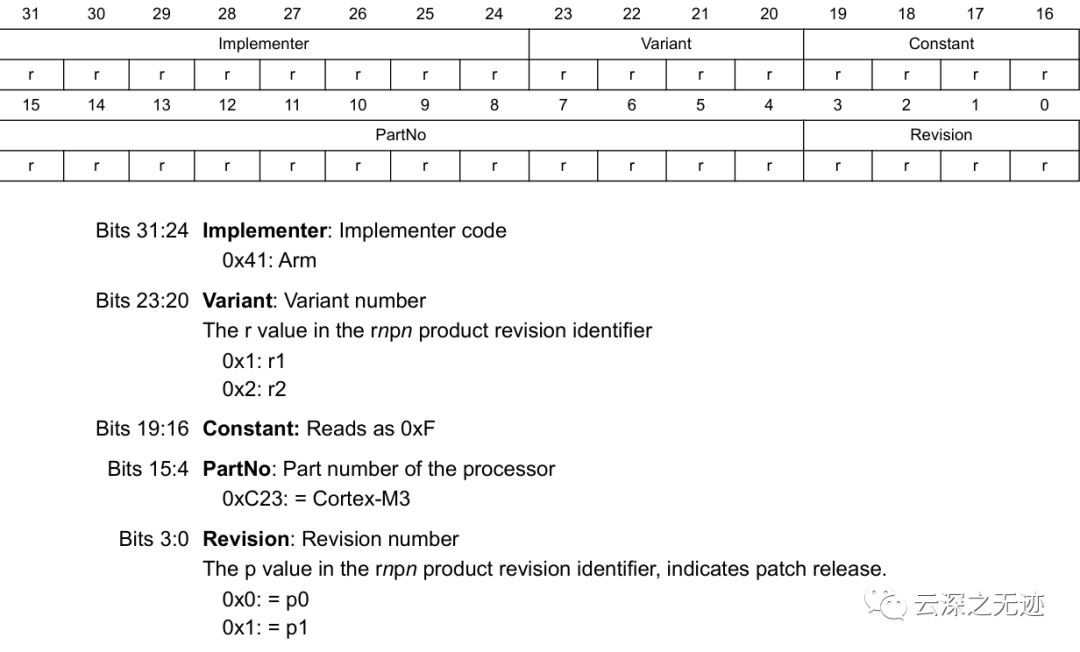 這個就是對應的寄存器布局,我們只是想知道里面是啥而已
這個就是對應的寄存器布局,我們只是想知道里面是啥而已
這些宏定義用于讀取SCB->CPUID寄存器中的設備ID和修訂信息。其中:SCB_CPUID_IMPLEMENTER_Pos和SCB_CPUID_IMPLEMENTER_Msk用于讀取IMPLEMENTER字段,該字段包含CPU的制造商ID。SCB_CPUID_VARIANT_Pos和SCB_CPUID_VARIANT_Msk用于讀取VARIANT字段,該字段包含CPU的變體編號。SCB_CPUID_PARTNO_Pos和SCB_CPUID_PARTNO_Msk用于讀取PARTNO字段,該字段包含CPU的具體型號。SCB_CPUID_REVISION_Pos和SCB_CPUID_REVISION_Msk用于讀取REVISION字段,該字段包含CPU的修訂版本。所以,通過這些宏,我們可以從SCB->CPUID寄存器中提取關鍵的設備信息:制造商ID:
uint32_t implementer = (SCB->CPUID & SCB_CPUID_IMPLEMENTER_Msk) >> SCB_CPUID_IMPLEMENTER_Pos;
變體編號:
uint32_t variant = (SCB->CPUID & SCB_CPUID_VARIANT_Msk) >> SCB_CPUID_VARIANT_Pos;
CPU型號:
uint32_t partNo = (SCB->CPUID & SCB_CPUID_PARTNO_Msk) >> SCB_CPUID_PARTNO_Pos;
CPU修訂版本:
uint32_t revision = (SCB->CPUID & SCB_CPUID_REVISION_Msk) >> SCB_CPUID_REVISION_Pos;
ARM Cortex-M內核的CPUID寄存器包含這些關鍵字段,方便識別和區分不同的芯片,并獲取其精確的型號與修訂信息。宏定義極大地簡化提取這些信息的過程,只需要通過位域操作和移位就可以獲得所需要的ID參數,這在很大程度上增強了代碼的可讀性。

不在乎含義,在乎寫法,接下來看寫法
SCB_CPUID_IMPLEMENTER_Pos代表:
IMPLEMENTER字段在CPUID寄存器中的起始位置(偏移),其值為24。
SCB_CPUID_IMPLEMENTER_Msk代表:
IMPLEMENTER字段的掩碼,通過將0xFF左移24位得到,其值為0xFF000000。所以,要讀取IMPLEMENTER字段,我們可以像下面這樣使用這兩個宏:
uint32_t implementer = (SCB->CPUID & SCB_CPUID_IMPLEMENTER_Msk) >> SCB_CPUID_IMPLEMENTER_Pos;
該語句通過與SCB_CPUID_IMPLEMENTER_Msk的位與操作獲取IMPLEMENTER字段,然后右移SCB_CPUID_IMPLEMENTER_Pos(24)位,將其移到最低8位,obtaining the implementer code.
例如,如果CPUID的值為0x410FC241,那么:SCB->CPUID = 0x410FC241
SCB_CPUID_IMPLEMENTER_Msk = 0xFF000000
通過與操作:0x410FC241 & 0xFF000000 = 0x41000000
右移24位:0x41000000 >> 24 = 0x41 = 65(十進制)所以,IMPLEMENTER字段的值為65(十進制),表示CPU的制造商是ARM。位域操作通過掩碼獲取目標字段,位移則將其移到需要的位置。
位域和位移都是位運算的概念,用于在二進制位級別操作和訪問數據。位域操作用于在一個數據域(如寄存器)的不同位上訪問多個字段。它通過掩碼來選擇和操作目標字段中的位。
常用的位域操作有:與(&):如果兩個操作數的對應比特位都是1,則該位的結果為1,否則為0。用于選取目標字段。或(|):只要兩個操作數的對應比特位有一個為1,則該位的結果為1。用于修改或設置字段的值。非(~) :反轉操作數的每一位,0變1,1變0。用于對字段取反。
位移則用于將數據的位向左或向右移動給定的位數,實際上是在給定方向上對數據的表示形式進行擴展或截斷。
按方向分為:左移(<<):向左移動,低位補0,用于擴展數據類型或實現乘法。右移(>>):向右移動,根據數據類型,高位或補0或補符號位,用于縮小數據類型或實現除法。
所以,要訪問SCB->CPUID寄存器的不同字段,我們可以:1.使用與操作和掩碼獲取目標字段,例如用SCB_CPUID_IMPLEMENTER_Msk獲取IMPLEMENTER字段。2.必要時使用位移將字段移到需要的位置,例如用SCB_CPUID_IMPLEMENTER_Pos右移24位將IMPLEMENTER移到低8位。3.組合位域操作讀取和修改字段。例如用或操作將某位設置為1,用與操作清0某位。
例如,要讀取CPUID的IMPLEMENTER字段:
uint32_t implementer = (SCB->CPUID & SCB_CPUID_IMPLEMENTER_Msk) >> SCB_CPUID_IMPLEMENTER_Pos;
要設置CPUID的REVISION字段的第3位:
SCB->CPUID |= (1 << 3); // 用或操作將第3位設置為1
要清CPUID的VARIANT字段的低4位:
SCB->CPUID &= ~((0xF) << SCB_CPUID_VARIANT_Pos); // 用與操作和反碼清除低4位
繼續放大鏡看這個代碼,我們看這個1ul的定義方式:

1ul
1ul是一個無符號長整型(unsigned long)常量,其值為1。在C語言中,整型常量的默認類型為int,但可以通過后綴來指定不同的類型。常見的后綴有:無符號(unsigned):- u或U:無符號整型,如1u
- ul或UL:無符號長整型,如1ul長整型(long):- l或L:長整型,如1l無符號長整型(unsigned long):- ul或UL:無符號長整型,如1ul大小寫無關,所以1u、1ul、1U和1UL都是等價的。
使用這些后綴的主要目的是為了在某些情況下指定常量的精確類型,避免由默認類型帶來的怪異行為。例如,在32位系統上,int和unsigned int都是32位,所以1和1u的值相同。
但long可能是32位,而unsigned long是64位,所以1l和1ul的值會不同。所以,當我們需要一個無符號的32/64位整型常量時,就可以使用1u或1ul來指定其精確類型,這可以避免一些潛在的問題。
另外,這些后綴也常用于定義寄存器和位域的掩碼常量,例如:
#define UART_DATA_MASK 0xFFul // 8位無符號數據掩碼 #define UART_PARITY_MASK 0x01ul // 1位無符號奇偶校驗位掩碼
這里使用ul是為了確保掩碼常量被定義為32位,與寄存器大小一致。所以,總結來說:1. 1ul是一個無符號長整型常量,其值為1。2. 后綴u、ul、U和UL用于定義無符號整型和無符號長整型常量。3. 使用這些后綴可以指定常量的精確類型,避免默認類型帶來的問題。4. 這些后綴常用于定義寄存器和位域的掩碼常量,確保其大小與目標寄存器一致。
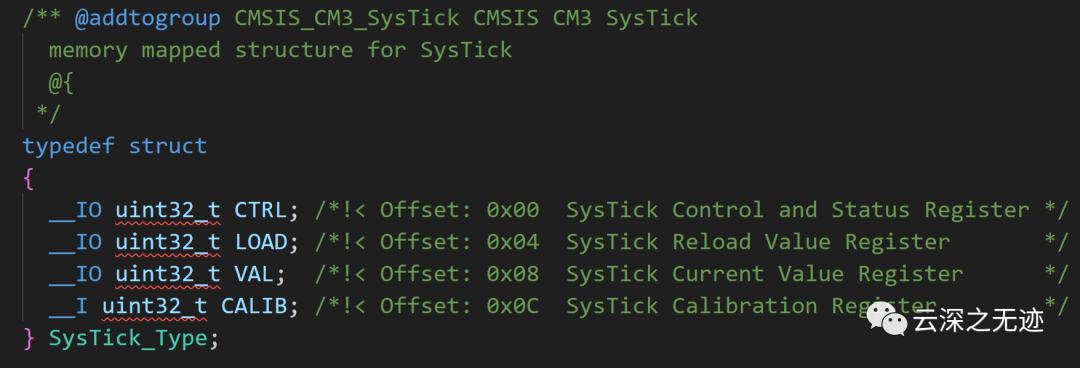
這個結構體定義了SysTick定時器的寄存器集。SysTick是Cortex-M內核的一部分,用于生成定時中斷和延時。
SysTick_Type結構體包含以下成員:
__IO uint32_t CTRL; SysTick控制和狀態寄存器,用于使能SysTick定時器,選擇時鐘源和計數模式。
__IO uint32_t LOAD; SysTick重載值寄存器,設置SysTick定時器的重載值,該值決定定時周期。
__IO uint32_t VAL; SysTick當前值寄存器,在運行過程中存儲SysTick定時器的當前值。
__I uint32_t CALIB; SysTick校準值寄存器,提供設備特定的時鐘頻率信息,用于計算延時。
所以,通過這個結構體,我們可以訪問SysTick定時器的所有控制/狀態寄存器和校準寄存器,并完成:
1. 使能或關閉SysTick定時器。
2. 選擇SysTick的時鐘源,如內核時鐘AHB或外部參考時鐘。
3. 選擇遞減計數模式或遞增計數模式。
4.設置SysTick定時器的重載值,配置其定時周期。
5.讀取當前的計數值VAL。
6.獲取設備的時鐘頻率信息CALIB,用于生成精確延時。
7.SysTick定時器溢出時產生中斷,所以也用作系統的節拍定時器。
SysTicktimer(STK)處理器有一個24位系統計時器SysTick,它從重新加載值開始計數到零,在下一個時鐘邊緣重新加載(封裝到)LOAD寄存器中的值,然后在隨后的時鐘上計數。當處理器停止調試時,計數器不會減少。
再詳細一些介紹這個:
1.最大計數值為24位,所以最大延時為16777216個時鐘周期。
2.可以選擇內核時鐘AHB或外部參考時鐘作為時鐘源。
3.可以選擇遞增計數模式或遞減計數模式。
4.重載值寄存器LOAD用于設置定時周期,每次定時器溢出時重新裝載該值。
5.當前值寄存器VAL存儲定時器的實時計數值。
6.定時器溢出時觸發SysTick異常請求,可以配置為產生中斷。
7.時鐘頻率預分頻因子固定為8,不可配置。
8. 中斷優先級固定為最低級別,僅可屏蔽但不可修改。
9.包含一設備特定的校準寄存器,提供系統時鐘頻率信息,用于實現準確延時。基
于以上特性,我們可以這樣配置和使用SysTick定時器:
1.使能SysTick定時器,選擇AHB時鐘源。
2.配置 SysTick_LOAD寄存器為重載值(如1000),每1000個時鐘周期產生一個中斷。
3.等待SysTick定時器中斷,并在中斷服務程序內進行任務調度或其他定時任務。
4.獲取SysTick_CALIB的值,例如0x0320,表明每個時鐘周期大約為30.5us。
5.要延時100ms,計算需要的時鐘周期數:100ms / 30.5us = 3276。寫入SysTick_LOAD,使能定時器。
6.等待SysTick定時器中斷,表示延時完成。
所以,SysTick模塊為Cortex-M3內核提供了一個簡單而高效的定時器,可用于RTOS的任務調度、軟件延時和其他定時事件。它的24位計數器和微秒級精度可以滿足大多數應用的需要。
和其它的定時器外設比較有什么區別?
SysTick定時器有以下主要用途:
1.提供系統節拍定時器,用于RTOS的任務調度。RTOS可以配置SysTick產生中斷,并在中斷處理程序中進行任務切換。
2.實現軟件延時。我們可以根據SysTick的定時周期計算需要的計數值來生成所需延時。
3.其他定時事件。SysTick定時器可以用于系統的各種定時任務,如定時監測、看門狗喂狗等。
與其他定時器外設相比,SysTick定時器有以下區別:
1.SysTick定時器是Cortex-M內核的一部分,而其他定時器屬于MCU的外設。所以SysTick定時器更輕量,通用性更強。
2.SysTick定時器的時鐘源只能選擇內核時鐘或外部參考時鐘,而其他定時器通常有更多時鐘源選擇。
3.SysTick定時器的計數器只有24位,范圍更小。其他定時器的計數器可以達32位或更高。
4.SysTick定時器的中斷優先級固定為最低,無法配置。其他定時器的中斷通常可以配置優先級。
5.SysTick定時器只有比較基本的控制寄存器,更簡單。其他定時器通常具有更豐富的控制與配置選項。
6.SysTick定時器的溢出事件只能產生中斷,無法產生DMA請求等。部分定時器可以通過多種方式響應溢出事件。
讓我來說下這個計數模式:
遞增計數模式和遞減計數模式是定時器的兩種不同的計數方式:
遞增計數模式:定時器的計數器從初始值(通常為0)開始遞增,當計數器達到重載值時,定時器溢出。然后計數器重載為初始值,重新開始遞增。如果配置為產生中斷,則在計數器達到重載值時觸發中斷。
例如,如果初始值為0,重載值為100,則計數序列為:
0, 1, 2, 3, ... 98, 99, 100 - 觸發中斷 - 0, 1, 2, 3 ...
遞減計數模式:
定時器的計數器從重載值開始遞減,當計數器達到0時,定時器溢出。然后計數器重載為重載值,重新開始遞減。如果配置為產生中斷,則在計數器達到0時觸發中斷。
例如,如果重載值為100,則計數序列為:
100, 99, 98, 97 ... 3, 2, 1, 0 - 觸發中斷 - 100, 99, 98 ...
所以,主要差異在于計數器的初始值和溢出條件不同:
遞增模式:
初始值:通常為0
溢出條件:計數器達到重載值
遞減模式:
初始值:等于重載值
溢出條件:計數器達到0
讓我們來探究一下這個設計意圖,就是定時器的設計意圖。
1.適應開發者的習慣。有的開發者更習慣從0開始遞增計數,有的更習慣從最大值開始遞減計數,所以提供兩種模式以滿足不同習慣。
2.方便實現定時器的溢出中斷。無論是遞增模式從0溢出到重載值,還是遞減模式從重載值溢出到0,都可以很簡單地通過比較計數器與重載值/0來檢測溢出事件并產生中斷。
3.擴展定時范圍。24位的定時器,遞增模式下最大延時為2^24個周期,若選擇遞減模式,最大延時可擴展為2^24 + 重載值個周期,所以可獲得較大的定時范圍。
4. 不同模式下的溢出事件可用于不同用途。例如,可以選擇遞增模式用于周期性中斷,而選擇遞減模式用于超時檢測。兩種事件可以同時使用,擴展定時器的應用。
5. 簡化硬件設計。提供兩種模式而非只有一種,可以在軟件中通過配置來選擇模式,而不需要硬件支持兩套完全不同的定時與計數邏輯,簡化了定時器模塊的設計。
接下來說這個設計上面的簡便性,這個就比較深奧了,之后我如果把玩FPGA我會寫詳細的。
如果SysTick定時器僅支持遞增模式或遞減模式中的一種,則其硬件結構可以簡單設計為:
- 24位計數器寄存器
- 24位重載寄存器
- 比較邏輯,比較計數器與重載寄存器,產生溢出事件
但是,為了支持兩種模式,SysTick定時器的硬件結構可以設計為:
- 24位計數器寄存器
- 24位重載寄存器
- 1位遞增/遞減模式選擇位
- 比較邏輯,當模式選擇位選擇遞增模式時,比較計數器與重載寄存,當選擇遞減模式時, 比較計數器與0,以產生溢出事件。
可以看到,僅添加一個1位的模式選擇邏輯,SysTick定時器就可以支持兩種模式,而不需要實現兩套完全獨立的計數/比較邏輯。在軟件層面,我們只需要設置MODE位為0選擇遞增模式,設置為1選擇遞減模式,然后處理溢出事件中斷即可。
硬件層面已經為兩種模式實現了統一的定時邏輯。可以想象,如果定時器需要同時支持4種或更多種模式,僅靠硬件實現各自獨立的定時機制會變得非常復雜。
而采用類似SysTick的方式,通過軟件配置選擇定時模式,硬件只需實現一套相對通用的定時機制,這無疑可以大大簡化定時器模塊的設計。
-
寄存器
+關注
關注
31文章
5325瀏覽量
120052 -
Cortex
+關注
關注
2文章
202瀏覽量
46449 -
CM3
+關注
關注
0文章
5瀏覽量
1652
原文標題:Cortex-M3精通之路-2(CMSIS核心結構)?
文章出處:【微信號:TT1827652464,微信公眾號:云深之無跡】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
為什么說Cortex-M是低功耗應用的首選
如何選擇正確的Cortex-M處理器?
Cortex-M 系列處理特點和區別詳解
Cortex-M系列MCU錯誤追蹤庫有何作用
如何利用C語言的位域操作去實現對寄存器每一位的控制
如何使用Ozone分析Cortex-M故障?
32位寄存器,32位寄存器是什么意思
米爾科技Cortex-M Prototyping System +介紹

Cortex-M3 內部寄存器

Cortex-M3寄存器等基礎知識






 工商網監
工商網監
評論