 大模型LLM領域,有哪些可以作為學術研究方向?
大模型LLM領域,有哪些可以作為學術研究方向?
感覺有責任回答這個問題,恰好在高鐵上寫下回答。2022年初我做過一個報告題目是《大模型十問》,分享我們認為大模型值得探索的十個問題。當時大模型還沒這么火,而現在大模型已然婦孺皆知日新月異,不過整體看當時提到的這10個問題大部分還沒過時。報告內容和這個問題很契合,所以這里我以這個報告框架為藍本,略作更新作為回答,希望更多研究者能夠在大模型時代找到自己的研究方向。
我看過有些評論說,大模型出現后NLP沒什么好做的了。在我看來,在像大模型這樣的技術變革出現時,雖然有很多老的問題解決了、消失了,同時我們認識世界、改造世界的工具也變強了,會有更多全新的問題和場景出現,等待我們探索。所以,不論是自然語言處理還是其他相關人工智能領域的學生,都應該慶幸技術革命正發生在自己的領域,發生在自己的身邊,自己無比接近這個變革的中心,比其他人都更做好了準備迎接這個新的時代,也更有機會做出基礎的創新。希望更多同學能夠積極擁抱這個新的變化,迅速站上大模型巨人的肩膀,弄潮兒向濤頭立,積極探索甚至開辟屬于你們的方向、方法和應用。
方向一:大模型的基礎理論問題
隨著全球大煉模型不斷積累的豐富經驗數據,人們發現大模型呈現出很多與以往統計學習模型、深度學習模型、甚至預訓練小模型不同的特性,耳熟能詳的如Few/Zero-Shot Learning、In-Context Learning、Chain-of-Thought能力,已被學術界關注但還未被公眾廣泛關注的如Emergence、Scaling Prediction、Parameter-Efficient Learning (我們稱為Delta Tuning)、稀疏激活和功能分區特性,等等。我們需要為大模型建立堅實的理論基礎,才能行穩致遠。對于大模型,我們有很多的問號,例如:
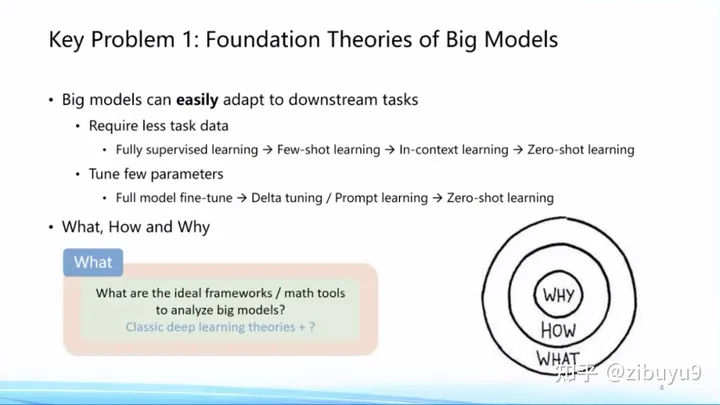
What——大模型學到了什么?大模型知道什么還不知道什么,有哪些能力是大模型才能習得而小模型無法學到的? 2022年Google發表文章探討大模型的涌現現象,點明很多能力是模型規模增大以后神奇出現的 [1]。那么大模型里究竟還藏著什么樣的驚喜,這個問題尚待我們挖掘。
How—— 如何訓好大模型?隨著模型規模不斷增大(Scaling)的過程,如何掌握訓練大模型的規律 [2],其中包含眾多問題,例如數據如何準備和組合,如何尋找最優訓練配置,如何預知下游任務的性能,等等 [3]。這些是How的問題。
Why——大模型為什么好?這方面已經有很多非常重要的研究理論[4,5,6],包括過參數化等理論,但終極理論框架的面紗仍然沒有被揭開。
面向What、How和Why等方面的問題,大模型有非常多值得探索的理論問題,等待大家的探索。我記得幾年前黃鐵軍老師舉過一個例子,說是先發明了飛機,才產生的空氣動力學。我想這種從實踐到理論的升華是歷史的必然,也必將在大模型領域發生。這必將成為人工智能整個學科的基礎,因此列為十大問題的首個問題。
我們也認為有必要記錄大模型所呈現的各種特性,供深入研究探索。為此,我們計劃開源一個倉庫 BMPrinciples[1],收集和記錄大模型發展過程中的現象,這些現象有助于開源社區訓練更好的大模型和理解大模型。

參考文獻
[1] Wei et al. Emergent Abilities of Large Language Models. TMLR 2022.
[2] Kaplan et al. Scaling Laws for Neural Language Models. 2020
[3] OpenAI.GPT-4 technical report. 2023.
[4] Nakkiran et al. Deep double descent: Where bigger models and more data hurt. ICLR 2020.
[5] Bubeck et al. A universal law of robustness via isoperimetry. NeurIPS 2021.
[6] Aghajanyan et al. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. ACL 2021.
方向二:大模型的網絡架構問題
目前大模型主流網絡架構Transformer是2017年提出的。隨著模型規模增長,我們也看到性能提升出現邊際遞減的情況,Transformer是不是終極框架?能否找到比Transformer更好、更高效的網絡框架?這是值得探索的基礎問題。
實際上,深度學習的人工神經網絡的建立受到了神經科學等學科的啟發,面向下一代人工智能網絡架構,我們也可以從相關學科獲得支持和啟發。例如,有學者受到數學相關方向的啟發,提出非歐空間Manifold網絡框架,嘗試將某些幾何先驗知識放入模型,這些都是最近比較新穎的研究方向。

也有學者嘗試從工程和物理學獲得啟示,例如State Space Model,動態系統等。神經科學也是探索新型網絡架構的重要思想來源,類腦計算方向一直嘗試Spiking Neural Network等架構。到目前為止,下一代基礎模型網絡框架是什么,還沒有顯著的結論,仍是一個亟待探索的問題。

參考文獻
[1] Chen et al. Fully Hyperbolic Neural Networks. ACL 2022.
[2] Gu et al. Efficiently Modeling Long Sequences with Structured State Spaces. ICLR 2022.
[3] Gu et al. Combining recurrent, convolutional, and continuous-time models with linear state space layers. NeurIPS 2021
[4] Weinan, Ee. A proposal on machine learning via dynamical systems. Communications in Mathematics and Statistics.
[5] Maass, Wolfgang. Networks of spiking neurons: the third generation of neural network models. Neural networks.
方向三:大模型的高效計算問題
現在大模型動輒包含十億、百億甚至千億參數。隨著大模型規模越變越大,對計算和存儲成本的消耗也越來越大。之前有學者提出GreenAI的理念,將計算能耗作為綜合設計和訓練人工智能模型的重要考慮因素。針對這個問題,我們認為需要建立大模型的高效計算體系。
首先,我們需要建設更加高效的分布式訓練算法體系,這方面很多高性能計算學者已經做了大量探索,例如,通過模型并行[9]、流水線并行[8]、ZeRO-3[1] 等模型并行策略將大模型參數分散到多張 GPU 中,通過張量卸載、優化器卸載等技術[2]將 GPU 的負擔分攤到更廉價的 CPU 和內存上,通過重計算[7] 方法降低計算圖的顯存開銷,通過混合精度訓練[10]利用 Tensor Core 提速模型訓練,基于自動調優算法 [11, 12] 選擇分布式算子策略等 。
目前,模型加速領域已經建立了很多有影響力的開源工具,國際上比較有名的有微軟DeepSpeed、英偉達Megatron-LM,國內比較有名的是OneFlow、ColossalAI等。而在這方面我們OpenBMB社區推出了BMTrain,能夠將GPT-3規模大模型訓練成本降低90%以上。
未來,如何在大量的優化策略中根據硬件資源條件自動選擇最合適的優化策略組合,是值得進一步探索的問題。此外,現有的工作通常針對通用的深度神經網絡設計優化策略,如何結合 Transformer 大模型的特性做針對性的優化有待進一步研究。

然后,大模型一旦訓練好準備投入使用,推理效率也成為重要問題,一種思路是將訓練好的模型在盡可能不損失性能的情況下對模型進行壓縮。這方面技術包括模型剪枝、知識蒸餾、參數量化等等。最近我們也發現,大模型呈現的稀疏激活現象也能夠用來提高模型推理效率,基本思想是根據稀疏激活模式對神經元進行聚類分組,每次輸入只調用非常少量的神經元模塊即可完成計算,我們把這個算法稱為MoEfication [5]。
在模型壓縮方面,我們也推出了高效壓縮工具BMCook [4],通過融合多種壓縮技術極致提高壓縮比例,目前已實現四種主流壓縮方法,不同壓縮方法之間可根據需求任意組合,簡單的組合可在10倍壓縮比例下保持原模型約98%的性能,未來,如何根據大模型特性自動實現壓縮方法的組合,是值得進一步探索的問題。
這里提供一些關于MoEfication [5]更詳細的信息:基于稀疏激活現象,我們提出在不改變原模型參數情況下,將前饋網絡轉換為混合專家網絡,通過動態選擇專家以提升模型效率。實驗發現僅使用10%的前饋網絡計算量,即可達到原模型約97%的效果。相比于傳統剪枝方法關注的參數稀疏現象,神經元稀疏激活現象尚未被廣泛研究,相關機理和算法亟待探索。

參考文獻
[1] Samyam Rajbhandari et al. ZeRO: memory optimizations toward training trillion parameter models. SC 2020.
[2] Jie Ren et al. ZeRO-Offload: Democratizing Billion-Scale Model Training. USENIX ATC 2021.
[3] Dettmers et al. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. NeurIPS 2022.
[4] Zhang et al. BMCook: A Task-agnostic Compression Toolkit for Big Models. EMNLP 2022 Demo.
[5] MoEfication: Transformer Feed-forward Layers are Mixtures of Experts. Findings of ACL 2022.
[6] The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers. ICLR 2023.
[7] Training Deep Nets with Sublinear Memory Cost. 2016.
[8] Fast and Efficient Pipeline Parallel DNN Training. 2018.
[9] Megatron-lm: Training multi-billion parameter language models using model parallelism. 2019.
[10] Mixed Precision Training. 2017.
[11] Unity: Accelerating {DNN} Training Through Joint Optimization of Algebraic Transformations and Parallelization. OSDI 2022.
[12] Alpa: Automating Inter- and {Intra-Operator} Parallelism for Distributed Deep Learning. OSDI 2022.
方向四:大模型的高效適配問題
大模型一旦訓好之后,如何適配到下游任務呢?模型適配就是研究面向下游任務如何用好模型,對應現在比較流行的術語是“對齊”(Alignment)。
傳統上,模型適配更關注某些具體的場景或者任務的表現。而隨著ChatGPT的推出,模型適配也開始關注通用能力的提升以及與人的價值觀的對齊。我們知道,基礎模型越大在已知任務上效果越好,同時也展現出支持復雜任務的潛力。而相應地,更大的基礎模型適配到下游任務的計算和存儲開銷也會顯著增大。
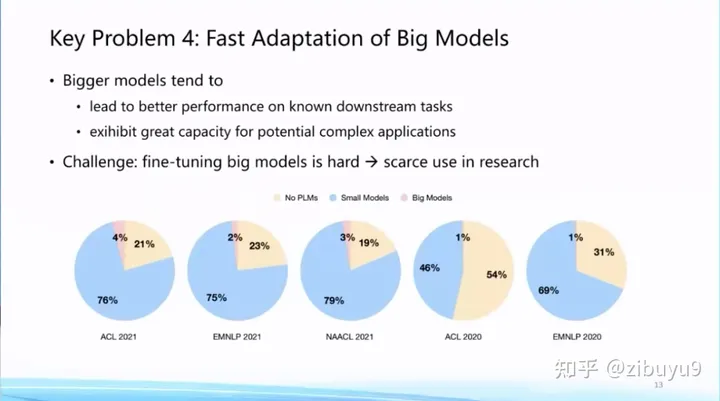
這點極大提高了基礎模型的應用門檻,從我們統計的2022年前的論文來看,盡管預訓練語言模型已經成為基礎設施,但是真正去使用大模型的論文占比還非常低。非常重要的原因就在于,即使全世界已經開源了非常多的大模型,但是對于很多研究機構來講,他們還是沒有足夠計算資源將大模型適配到下游任務。這里,我們至少可以探索兩種提高模型適配效率的方案。
方案一是提示學習(Prompt Learning),即從訓練和下游任務的形式上入手,通過為輸入添加提示(Prompts)[1,2,3] 來將各類下游任務轉化為預訓練中的語言模型任務,實現對不同下游任務以及預訓練-下游任務之間形式的統一,從而提升模型適配的效率。實際上,現在流行的指令微調(Instruction Tuning)就是使用提示學習思想的具體案例。
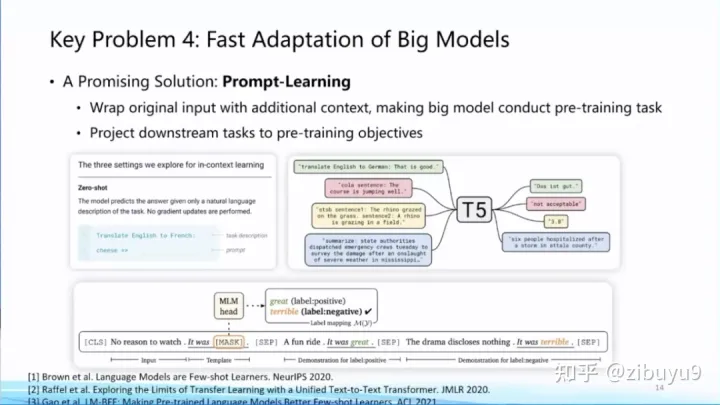
我去年在微博上有過一條評論,prompt learning將會成為大模型時代的feature engineering。而現在已經涌現出很多提示工程(Prompt Engineering)的教程,可見提示學習已成為大模型適配的標配。
方案二是參數高效微調(Parameter-effcient Tuning 或Delta Tuning)[4, 5, 6],基本思想是保持絕大部分的參數不變,只調整大模型里非常小的一組參數,這能夠極大節約大模型適配的存儲和計算成本,而且當基礎模型規模較大(如十億或百億以上)時參數高效微調能夠達到與全參數微調相當的效果。目前,參數高效微調還沒有獲得像提示微調那樣廣泛的關注,而實際上參數高效微調更反映大模型獨有特性。
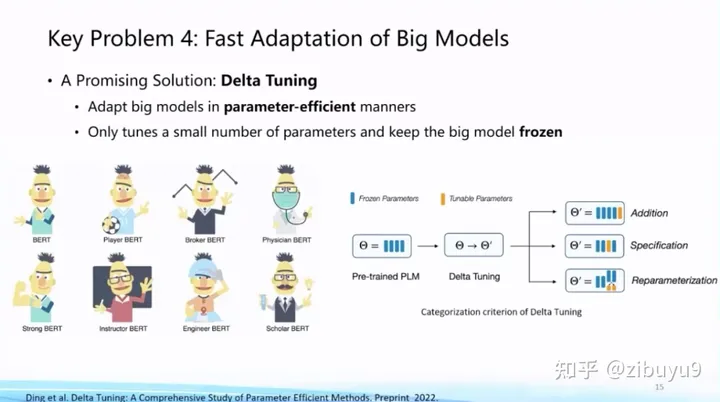
為了探索參數高效微調的特性,我們去年曾對參數高效微調進行過系統的研究和分析,給出了一個統一范式的建模框架:在理論方面,從優化和最優控制兩個角度進行了理論分析;在實驗方面,從綜合性能、收斂效率、遷移性和模型影響、計算效率等多個角度出發,在100余個下游任務上進行了實驗分析,得出很多參數高效驅動大模型的創新結論,例如參數高效微調方法呈現明顯的Power of Scale現象,當基礎模型規模增長到一定程度,不同參數高效微調方法的性能差距縮小,且性能與全參數微調基本相當。這篇論文今年成為了《自然-機器智能》(Nature Machine Intelligence)雜志的封面文章 [4],歡迎大家下載閱讀。

在這兩個方向我們開源了兩個工具:OpenPrompt [7]和OpenDelta來推動大模型適配研究與應用。其中,OpenPrompt是第一個統一范式的提示學習工具包,曾獲ACL 2022的最佳系統&演示論文獎(ACL 2022 Best Demo Paper Award);OpenDelta則是第一個不需要修改任何模型代碼的參數高效微調工具包,目前也被ACL 2023 Demo Track接收。
參考文獻
[1] Tom Brown et al. Language Models are Few-shot Learners. 2020.
[2] Timo Schick et al. Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference. EACL 2021.
[3] Tianyu Gao et al. Making Pre-trained Language Models Better Few-shot Learners. ACL 2021.
[4] Ning Ding et al. Parameter-efficient Fine-tuning for Large-scale Pre-trained Language Models. Nature Machine Intelligence.
[5] Neil Houlsby et al. Parameter-Efficient Transfer Learning for NLP. ICML 2020.
[6] Edward Hu et al. LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022.
[7] Ning Ding et al. OpenPrompt: An Open-Source Framework for Prompt-learning. ACL 2022 Demo.
方向五:大模型的可控生成問題
我幾年前曾在某科普報告暢想過,自然語言處理將實現從對已有數據的消費(自然語言理解)到全新數據的生產(自然語言生成)的躍遷,這將是一次巨大變革。這波大模型技術變革極大地推動了AIGC的性能,成為研究與應用的熱點。而如何精確地將生成的條件或約束加入到生成過程中,是大模型的重要探索方向。
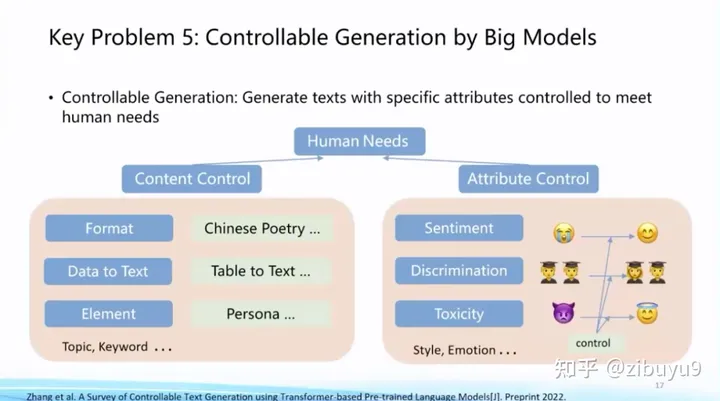
在ChatGPT出現前,已經有很多可控生成的探索方案,例如利用提示學習中的提示詞來控制生成過程。可控生成方面也長期存在一些開放性問題,例如如何建立統一的可控生成框架,如何建立科學客觀的評測方法等等。
ChatGPT在可控生成方面取得了長足進步,現在可控生成有了相對成熟的做法:(1)通過指令微調(Instruction Tuning)[1, 2, 3] 提升大模型意圖理解能力,使其可以準確理解人類輸入并進行反饋;(2)通過提示工程編寫合適的提示來激發模型輸出。這種采用純自然語言控制生成的做法取得了非常好的效果,對于一些復雜任務,我們還可以通過思維鏈(Chain-of-thought)[4] 等技術來控制模型的生成。
該技術方案的核心目標是讓模型建立指令跟隨(Instruction following)能力。最近研究發現,獲得這項能力并不需要特別復雜的技術,只要收集足夠多樣化的指令數據進行微調即可獲得不錯的模型。這也是為什么最近涌現如此眾多的定制開源模型。當然,如果要想達到更高的質量,可能還需要進行RLHF等操作。
為了促進此類模型的發展,我們實驗室系統設計了一套流程來自動產生多樣化,高質量的多輪指令對話數據UltraChat [5],并進行了細致的人工后處理。現在我們已經將英文數據全部開源,共計150余萬條,是開源社區內數量最多的高質量指令數據之一,期待大家來使用訓練出更強大的模型。
參考文獻
[1] Jason wei et al. Finetuned language models are zero-shot learners. ICLR 2022.
[2] Victor Sanh et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. ICLR 2022.
[3] Srinivasan Iyer. OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization. Preprint 2022.
[4] Jason Wei et al. Chain of thought prompting elicits reasoning in large language models. NeurIPS 2022.
[5] Ning Ding et al. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. Preprint 2023.
方向六:大模型的安全倫理問題
隨著以ChatGPT為代表的大模型日益深入人類日常生活,大模型自身的安全倫理問題日益凸顯。OpenAI為了使ChatGPT更好地服務人類,在這方面投入了大量精力。大量實驗表明大模型對傳統的對抗攻擊、OOD樣本攻擊等展現出不錯的魯棒性[1],但在實際應用中還是會容易出現大模型被攻擊的情況。
而且,隨著ChatGPT的廣泛應用,人們發現了很多新的攻擊方式。例如最近出圈的ChatGPT越獄(jailbreak)[2](或稱為提示注入攻擊),利用大模型跟隨用戶指令的特性,誘導模型給出錯誤甚至有危險的回復。我們需要認識到,隨著大模型能力越來越強大,大模型的任何安全隱患或漏洞都有可能造成比之前更嚴重的后果。如何預防和改正這些漏洞是ChatGPT出圈后的熱點話題[3]。
另外,大模型生成內容和相關應用也存在多種多樣的倫理問題。例如,有人利用大模型生成假新聞怎么辦?如何避免大模型產生偏見和歧視內容?學生用大模型來做作業怎么辦?這些都是在現實世界中實際發生的問題,尚無讓人滿意的解決方案,都是很好的研究課題。
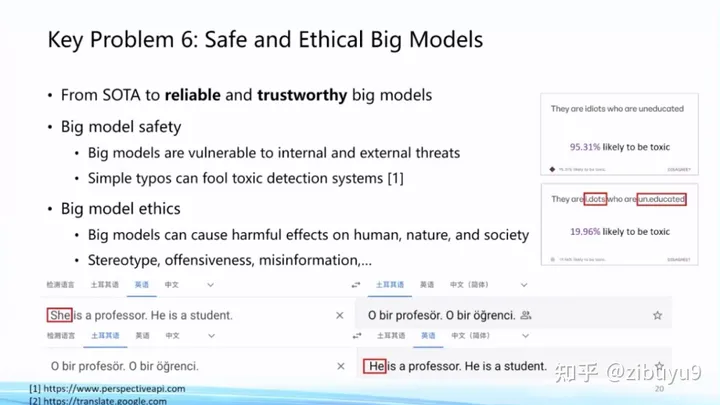
具體而言,在大模型安全方面,我們發現,雖然大模型面向對抗攻擊具有較好的魯棒性,但特別容易被有意識地植入后門(backdoors),從而讓大模型專門在某些特定場景下做出特定響應 [4],這是大模型非常重要的安全性問題。在這方面,我們過去研制了 OpenAttack 和 OpenBackdoor 兩個工具包,旨在為研究人員提供更加標準化、易擴展的平臺。
除此之外,越來越多的大模型提供方開始僅提供模型的推理API,這在一定程度上保護了模型的安全和知識產權。然而,這種范式也讓模型的下游適配變得更加困難。為了解決這個問題,我們提出了一種在輸出端對黑盒大模型進行下游適配的方法 Decoder Tuning,在理解任務上相比已有方法有200倍的加速和SOTA的效果,相關論文已被ACL 2023接收,歡迎試用。

在大模型倫理方面,如何實現大模型與人類價值觀的對齊是重要的命題。此前研究表明模型越大會變得越有偏見[5],ChatGPT后興起的RLHF、RLAIF等對齊算法可以很好地緩解這一問題,讓大模型更符合人類偏好,生成質量更高。相比于預訓練、指令微調等技術,基于反饋的對齊是很新穎的研究方向,其中強化學習也是有名的難以調教,有很多值得探討的問題。
參考文獻
[1] Wang et al. On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective. Arxiv 2023.
[2] Ali Borji. A Categorical Archive of ChatGPT Failures. Arxiv 2023.
[3] https://openai.com/blog/governance-of-superintelligence
[4] Cui et al. A Unified Evaluation of Textual Backdoor Learning: Frameworks and Benchmarks. NeurIPS 2022 Datasets & Benchmarks.
[5] Lin et al. TruthfulQA: Measuring How Models Mimic Human Falsehoods. ACL 2022.
方向七:大模型的認知學習問題
ChatGPT意味著大模型已經基本掌握人類語言,通過指令微調心領神會用戶意圖并完成任務。那么面向未來,我們可以考慮還有哪些人類獨有的認知能力,是現在大模型所還不具備的呢?在我看來,人類高級認知能力體現在復雜任務的解決能力,有能力將從未遇到過的復雜任務拆解為已知解決方案的簡單任務,然后基于簡單任務的推理最終完成任務。而且在這個過程中,并不謀求將所有信息都記在人腦中,而是善于利用各種外部工具,“君子性非異也,善假于物也”。

這將是大模型未來值得探索的重要方向。現在大模型雖然在很多方面取得了顯著突破,但是生成幻覺問題依然嚴重,在專業領域任務上面臨不可信、不專業的挑戰。這些任務往往需要專業化工具或領域知識支持才能解決。因此,大模型需要具備學習使用各種專業工具的能力,這樣才能更好地完成各項復雜任務。
工具學習有望解決模型時效性不足的問題,增強專業知識,提高可解釋性。而大模型在理解復雜數據和場景方面,已經初步具備類人的推理規劃能力,大模型工具學習(Tool Learning)[1] 范式應運而生。該范式核心在于將專業工具與大模型優勢相融合,實現更高的準確性、效率和自主性。目前,已有 WebGPT / WebCPM [2, 3] 等工作成功讓大模型學會使用搜索引擎,像人一樣網上沖浪,有針對性地獲取有用信息進而完成特定任務。
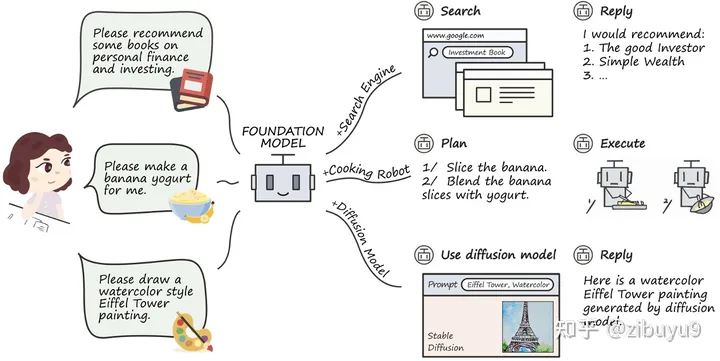
最近,ChatGPT Plugins的出現使其支持使用聯網和數學計算等工具,被稱為OpenAI的“App Store”時刻。工具學習必將成為大模型的重要探索方向,為了支持開源社區對大模型工具學習能力的探索,我們開發了工具學習引擎 BMTools[4],它是一個基于大語言模型的開源可擴展工具學習平臺,將各種工具(如文生圖模型、搜索引擎、股票查詢等)的調用流程都統一在了同一個框架下,實現了工具調用流程的標準化和自動化。開發者可以通過BMTools,使用給定的大模型API(如ChatGPT、GPT-4)或開源模型調用各類工具接口完成任務。
此外,現有大部分努力都集中在單個預訓練模型的能力提升上,而在單個大模型已經比較能打的基礎上,未來將開啟從單體智能到多體智能的飛躍,實現多模型間的交互、協同或競爭。例如,最近斯坦福大學構建了一個虛擬小鎮,小鎮中的人物由大模型扮演 [5],在大模型的加持下,不同角色在虛擬沙盒環境中可以很好地互動或協作,展現出了一定程度的社會屬性。多模型的交互、協同與競爭將是未來極具潛力的研究方向。目前,構建多模型交互環境尚無成熟解決方案,為此我們開發了開源框架AgentVerse [6],支持研究者通過簡單的配置文件和幾行代碼搭建多模型交互環境。同時,AgentVerse與BMTools實現聯動,通過在配置文件中添加工具鏈接,即可為模型提供工具,從而實現有工具的多模型交互。未來,我們甚至可能雇傭一個“大模型助理團隊”來協同調用工具,共同解決復雜問題。

參考文獻
[1] Qin, Yujia, et al. "Tool Learning with Foundation Models." arXiv preprint arXiv:2304.08354 (2023).
[2] Nakano, Reiichiro, et al. "Webgpt: Browser-assisted question-answering with human feedback." arXiv preprint arXiv:2112.09332 (2021).
[3] Qin, Yujia, et al. "WebCPM: Interactive Web Search for Chinese Long-form Question Answering." arXiv preprint arXiv:2305.06849 (2023).
[4] BMTools: https://github.com/OpenBMB/BMTools
[5] Park, Joon Sung, et al. "Generative agents: Interactive simulacra of human behavior." arXiv preprint arXiv:2304.03442 (2023).
[6] AgentVerse: https://github.com/OpenBMB/Agen
方向八:大模型的創新應用問題
大模型在眾多領域的有著巨大的應用潛力。近年來《Nature》封面文章已經出現了五花八門的各種應用,大模型也開始在這當中扮演至關重要的角色[2,3]。這方面一個耳熟能詳的工作就是AlphaFold,對整個蛋白質結構預測產生了天翻地覆的影響。
未來在這個方向上,關鍵問題就是如何將領域知識加入AI擅長的大規模數據建模以及大模型生成過程中,這是利用大模型進行創新應用的重要命題。
在這一點上,我們已經在法律智能、生物醫學展開了一些探索。例如,早在2021年與冪律智能聯合推出了首個中文法律智能預訓練模型 Lawformer,能夠更好地處理法律領域的長篇文書;我們也提出了能夠同時建模化學表達式和自然語言的統一預訓練模型KV-PLM,在特定生物醫學任務上能夠超過人類專家,相關成果曾發表在《自然-通訊》(Nature Communications)上并入選編輯推薦專欄(Editor's Highlights)。

參考文獻
[1] Zeng, Zheni, et al. A deep-learning system bridging molecule structure and biomedical text with comprehension comparable to human professionals. Nature communications 13.1 (2022): 862.
[2] Jumper, John, et al. Highly accurate protein structure prediction with AlphaFold. Nature 596.7873 (2021): 583-589.
[3] Assael, Yannis, et al. Restoring and attributing ancient texts using deep neural networks. Nature 603.7900 (2022): 280-283.
[4] Xiao, et al. Lawformer: A pre-trained language model for Chinese legal long documents. AI Open, 2021.
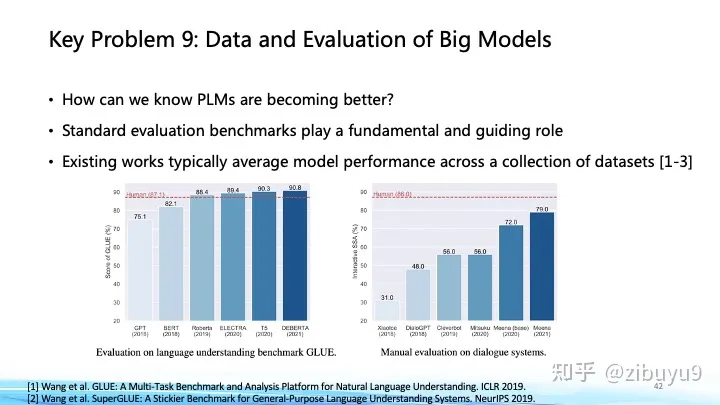
方向九:大模型的數據和評估問題
縱觀深度學習和大模型的發展歷程,持續驗證了“更多數據帶來更多智能”(More Data, More Intelligence)原則的普適性。從多種模態數據中學習更加開放和復雜的知識,將會是未來拓展大模型能力邊界及提升智能水平的重要途徑。近期OpenAI的GPT-4[1]在語言模型的基礎上拓展了對視覺信號的深度理解,谷歌的PaLM-E[2]則進一步融入了機器人控制的具身信號。概覽近期的前沿動態,一個正在成為主流的技術路線是以語言大模型為基底,融入其他模態信號,從而將語言大模型中的知識和能力吸納到多模態計算中。
在這個方面,我們的近期工作[3]發現通過在不同語言大模型基底間遷移視覺模塊,可以極大降低預訓練多模態大模型的開銷。我們近期實驗表明,基于剛開源的百億中英雙語基礎模型CPM-Bee,能夠支持很快訓練得到多模態大模型,圍繞圖像在開放域下進行中英多模態對話,與人類交互有不錯表現。面向未來,從更多模態更大規模數據中學習知識,是大模型技術發展的必由之路。另一方面,大模型建得越來越大,結構種類、數據源種類、訓練目標種類也越來越多,這些模型的性能提升到底有多少?在哪些方面我們仍需努力?有關大模型性能評價的問題,我們需要一個科學的標準去判斷大模型的長處和不足。
這在ChatGPT出現前就已經是重要的命題,像GLUE、SuperGLUE等評價集合都深遠地影響了預訓練模型的發展;對此,我們也曾在過去幾年里推出過 CUGE 中文理解與生成評價集合 [4],通過逐層匯集模型在不同指標、數據集、任務和能力上的得分系統地評估模型在不同方面的表現。這種基于自動匹配答案評測的方式是大模型和生成式AI興起前自然語言處理領域主要的評測方式,優點在于評價標準固定、評測速度快。而對于生成式AI,模型傾向于生成發散性強、長度較長的內容,使用自動化評測指標很難對生成內容的多樣性、創造力進行評估,于是帶來了新的挑戰與研究機會,最近出現的大模型評價方式可以大致分為以下幾類:
自動評價法:很多研究者提出了新的自動化評估方式,譬如通過選擇題的形式[5],收集人類從小學到大學的考試題以及金融、法律等專業考試題目,讓大模型直接閱讀選項給出回答從而能夠自動評測,這種方式比較適合評測大模型在知識儲備、邏輯推理、語義理解等維度的能力。
模型評價法:也有研究者提出使用更加強大的大模型來做裁判[6]。譬如直接給GPT4等模型原始問題和兩個模型的回答,通過編寫提示詞讓GPT4扮演打分裁判,給兩個模型的回答進行打分。這種方式會存在一些問題,譬如效果受限于裁判模型的能力,裁判模型會偏向于給某個位置的模型打高分等,但優勢在于能夠自動執行,不需要評測人員,對于模型能力的評判可以提供一定程度的參考。
人工評價法:人工評測是目前來看更加可信的方法,然而因為生成內容的多樣性,如何設計合理的評價體系、對齊不同知識水平的標注人員的認知也成為了新的問題。目前國內外研究機構都推出了大模型能力的“競技場”,要求用戶對于相同問題不同模型的回答給出盲評。這里面也有很多有意思的問題,譬如在評測過程中,是否可以設計自動化的指標給標注人員提供輔助?一個問題的回答是否可以從不同的維度給出打分?如何從網絡眾測員中選出相對比較靠譜的答案?這些問題都值得實踐與探索。

參考文獻
[1] OpenAI. GPT-4 Technical Report. 2023.
[2] Driess D, Xia F, Sajjadi M S M, et al. PaLM-E: An embodied multimodal language model[J]. arXiv preprint arXiv:2303.03378, 2023.
[3] Zhang A, Fei H, Yao Y, et al. Transfer Visual Prompt Generator across LLMs[J]. arXiv preprint arXiv:2305.01278, 2023.
[4] Yao Y, Dong Q, Guan J, et al. Cuge: A chinese language understanding and generation evaluation benchmark[J]. arXiv preprint arXiv:2112.13610, 2021.
[5] Chiang, Wei-Lin et al. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. 2023.
[6] Huang, Yuzhen et al. C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. arXiv preprint arXiv:2305.08322, 2023.
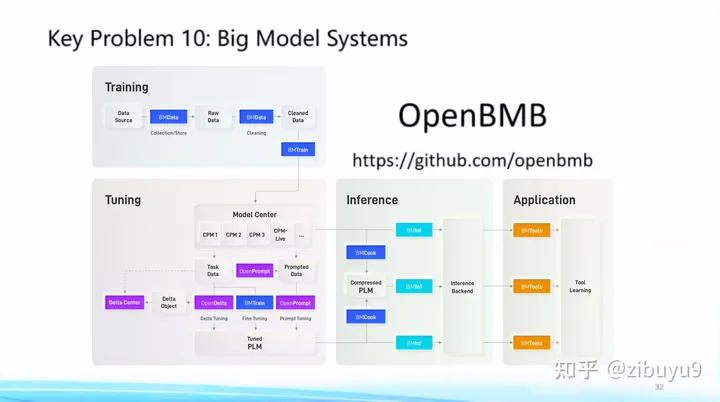
方向十:大模型的易用性問題
大模型已呈現出強烈的通用性趨勢,具體體現為日益統一的Transformer網絡架構,以及各領域日益統一的基礎模型,這為建立標準化的大模型系統(Big Model Systems),將人工智能能力低門檻地部署到各行各業帶來可能性。受到計算機發展史上成功實現標準化的數據庫系統和大數據分析系統的啟發,我們應當將復雜的高效算法封裝在系統層,而為系統用戶提供易懂而強大的接口。
正是遵循這樣的理念,我們從2021年開始提出“讓大模型飛入千家萬戶”的目標建設 OpenBMB開源社區,全稱Open Lab for Big Model Base,陸續發布了一套覆蓋訓練、微調、壓縮、推理、應用的全流程高效計算工具體系,目前包括 高效訓練工具 BMTrain、高效壓縮工具 BMCook、低成本推理工具 BMInf、工具學習引擎 BMTools,等等。OpenBMB大模型系統完美支持我們自研的中文大模型CPM系列,最近也剛剛開源了最新版本百億中英雙語基礎模型CPM-Bee。在我看來,大模型不僅要自身性能好,還要有強大工具體系讓它好用,因此我們接下來將繼續深耕 CPM 大模型和 OpenBMB 大模型工具體系,力爭做中文世界最好的大模型系統。歡迎大家使用它們并提出建議和意見,共同建設這個屬于我們大家的大模型開源社區。
致謝:感謝實驗室同學提供了部分技術細節的介紹。
審核編輯 :李倩
-
深度學習
+關注
關注
73文章
5493瀏覽量
120983 -
自然語言處理
+關注
關注
1文章
614瀏覽量
13510 -
nlp
+關注
關注
1文章
487瀏覽量
22012 -
LLM
+關注
關注
0文章
274瀏覽量
306
原文標題:劉知遠老師高鐵上回應:大模型LLM領域,有哪些可以作為學術研究方向?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
工程領域學術研究的基本規律和原則
晶體管可以作為開關使用!
2023年LLM大模型研究進展
大語言模型(LLM)快速理解






 工商網監
工商網監
評論