") 大模型訓(xùn)練和部署的關(guān)鍵技術(shù)
大模型訓(xùn)練和部署的關(guān)鍵技術(shù)
電子發(fā)燒友網(wǎng)報(bào)道(文/李彎彎)ChatGPT的出現(xiàn)讓大模型迅速出圈,事實(shí)上,在過(guò)去這些年中,模型規(guī)模在快速提升。數(shù)據(jù)顯示,自2016年至今,模型大小每18個(gè)月增長(zhǎng)40倍,自2019年到現(xiàn)在,更是每18個(gè)月增長(zhǎng)340倍。
然而相比之下,硬件增長(zhǎng)速度較慢,自2016年至今,GPU的性能增長(zhǎng)每18個(gè)月1.7倍,模型大小和硬件增長(zhǎng)的差距逐漸擴(kuò)大。顯存占用大、算力消費(fèi)大、成本高昂等瓶頸嚴(yán)重阻礙AIGC行業(yè)的快速發(fā)展。在此背景下,潞晨科技創(chuàng)始人尤洋認(rèn)為,分布式訓(xùn)練勢(shì)在必行。
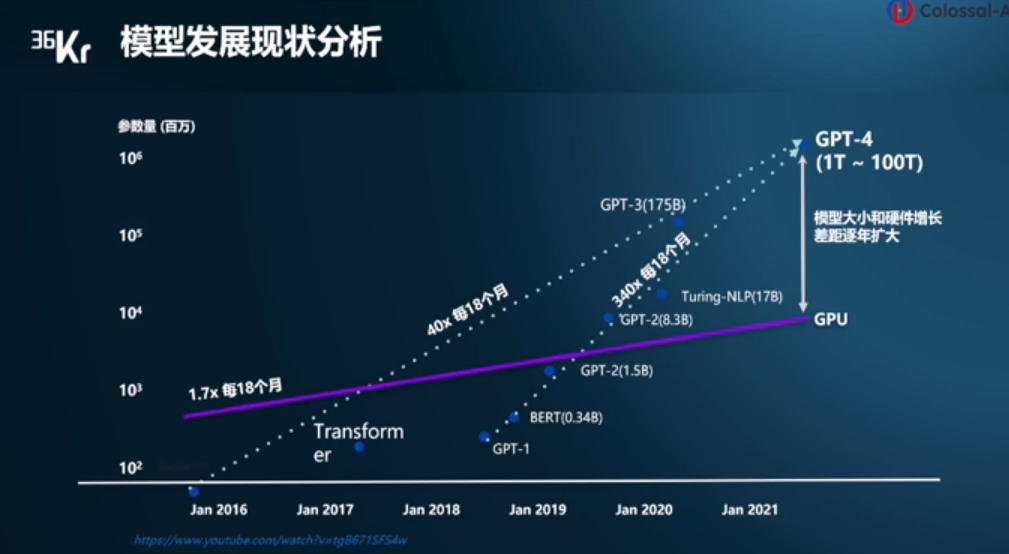
圖:潞晨科技創(chuàng)始人尤洋演講
基礎(chǔ)大模型結(jié)構(gòu)為模型訓(xùn)練提供了基礎(chǔ)架構(gòu)
其一、Google首創(chuàng)的Transformer大模型,是現(xiàn)在所有大模型最基礎(chǔ)的架構(gòu)。現(xiàn)在Transformer已經(jīng)成為除了MLP、CNN、RNN以外第四種最重要的深度學(xué)習(xí)算法架構(gòu)。
其二、Google發(fā)布的首個(gè)預(yù)大模型BERT,從而引爆了預(yù)練大橫型的潮流和的勢(shì),BERT強(qiáng)調(diào)了不再像以往一樣采用傳統(tǒng)的單向語(yǔ)言模型或者把兩個(gè)單向語(yǔ)言橫型進(jìn)行淺層拼接的方法進(jìn)行預(yù)認(rèn)訓(xùn)練,而是采用新的masked language model(MLM),以致能生成深度的雙向語(yǔ)言表征。
其三、ViT Google提出的首個(gè)使用Transformert的視覺(jué)大模型,ViT作為視覺(jué)轉(zhuǎn)換器的使用,而不是CNN威混合方法來(lái)執(zhí)行圖像任務(wù),作者假設(shè)進(jìn)一步的預(yù)認(rèn)訓(xùn)練可以提高性能,因?yàn)榕c其他現(xiàn)有技術(shù)模型相比,ViT具有相對(duì)可擴(kuò)展性。
其四、Google將Transformer中的Feedforward Network(FFN)層替換成了MoE層,并且將MoE層和數(shù)據(jù)并行巧妙地結(jié)合起來(lái),在數(shù)據(jù)并行訓(xùn)練時(shí),模型在訓(xùn)練集群中已經(jīng)被復(fù)制了若干份,通過(guò)在多路數(shù)據(jù)并行中引入Al-to-Al通信來(lái)實(shí)現(xiàn)MoE的功能。
在這些基礎(chǔ)大模型結(jié)構(gòu)之上,過(guò)去這些年,在大模型的發(fā)展歷程中,出現(xiàn)了幾個(gè)具有里程碑意義性的大模型包括GPT-3、T5、Swin Transformer、Switch Transformer。
GPT-3:OpenAI發(fā)布的首個(gè)百億規(guī)模的大模型,應(yīng)該非常具有開(kāi)創(chuàng)性意義,現(xiàn)在的大模型都是對(duì)標(biāo)GPT-3,GPT-3依舊延續(xù)自己的單向語(yǔ)言模型認(rèn)訓(xùn)練方式,只不過(guò)這次把模型尺寸增大到了1750億,并且使用45TB數(shù)據(jù)進(jìn)行訓(xùn)練。
T5(Text-To-Text Transfer Transformer):Google T5將所有NLP任務(wù)都轉(zhuǎn)化成Text-to-Text(文本到文本)任務(wù)。它最重要作用給整個(gè)NLP預(yù)訓(xùn)型領(lǐng)城提供了一個(gè)通用框架,把所有任務(wù)都轉(zhuǎn)化成一種形式。
Swin Transformer:微軟亞研提出的Swin Transformer的新型視覺(jué)Transformer,它可以用作計(jì)算機(jī)視的通用backbone。在個(gè)領(lǐng)域之同的差異,例如視覺(jué)實(shí)體尺度的巨大差異以及與文字中的單詞相比,圖像中像素的高分率,帶來(lái)了使Transformer從語(yǔ)言適應(yīng)視覺(jué)方面的挑戰(zhàn)。
超過(guò)萬(wàn)億規(guī)模的稀疏大模型Switch Transformer:能夠訓(xùn)練包含超過(guò)一萬(wàn)億個(gè)參數(shù)的語(yǔ)言模型的技術(shù),直接將參數(shù)量從GPT-3的1750億拉高到1.6萬(wàn)億,其速度是Google以前開(kāi)發(fā)的語(yǔ)言模型T5-XXL的4倍。
另外,更具里程碑意義的大模型,在Pathways上實(shí)現(xiàn)的大預(yù)言模型PaLM。
分布式框架Pathways:Pathways的很多重要思想來(lái)源于現(xiàn)有系統(tǒng),包括用于表達(dá)和執(zhí)行TPU計(jì)算的XLA、用于表征和執(zhí)行分布式CPU計(jì)算的TensorFlow圖和執(zhí)行器、基于Python編程框架的JAX以及TensorFlowAPL,通過(guò)有效地使用這些模塊,Pathways不需要對(duì)現(xiàn)有橫型進(jìn)行很多改動(dòng)就能運(yùn)行。
PaLM模型:PaLM吸引人眼球的是該模型具有5400億參數(shù)以及果用新一代AI框架Pathways訓(xùn)練。模型結(jié)構(gòu)也給出了很多方面優(yōu)化,這些技術(shù)優(yōu)化工作汲取了現(xiàn)有突出的研究成果,具體包括SwiGLU激活函數(shù)代替ReLU、層并行技術(shù)(Parallel Layers)、多查詢注意力(Multi-Query Attention),旋轉(zhuǎn)位置編碼(RoPE)、共享輸入和輸出詞嵌入、去掉偏置參數(shù)(No Biases)等。

PaLM模型也是通過(guò)堆疊Transformer中的Decoder部分而成,該模型具有5400億參數(shù)以及采用新一代AI框架Pathways訓(xùn)練。
大規(guī)模分布式訓(xùn)練當(dāng)前主要技術(shù)路線
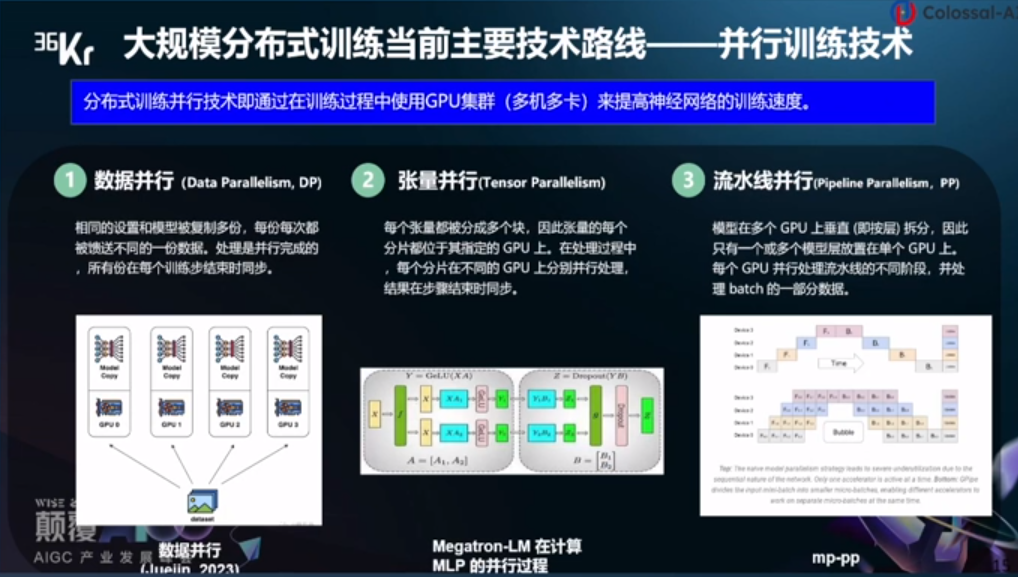
大規(guī)模分布式訓(xùn)練當(dāng)前主要技術(shù)路線——并行訓(xùn)練技術(shù)。分布式訓(xùn)練并行技術(shù)即通過(guò)在訓(xùn)練過(guò)程中使用GPU集群(多機(jī)多卡)來(lái)提高神經(jīng)網(wǎng)絡(luò)的訓(xùn)練速度。
數(shù)據(jù)并行:相同的設(shè)置和模型被復(fù)制多份,每份每次都被饋送不同的一份數(shù)據(jù),處理是并行完成的,所有份在每個(gè)訓(xùn)練步結(jié)束時(shí)同步。
張量并行:每個(gè)張量都被分成多個(gè)塊,因此張量的每個(gè)分片都位于其指定的GPU上,在處理過(guò)程中,每個(gè)分片在不同的GPU上分別并行處理,結(jié)果在步驟結(jié)束時(shí)同步。
流水線并行:模型在多個(gè)GPU上垂直(即按量)拆分,因此只有一個(gè)或多個(gè)模型層放置在單個(gè)GPU上,每個(gè)GPU并行處理流水線的不同階段,并處理batch的一部分?jǐn)?shù)據(jù)。
潞晨科技成立于2021年,是一家致力于“解放AI生產(chǎn)力”的全球性公司。主要業(yè)務(wù)是通過(guò)打造分布式AI開(kāi)發(fā)和部署平臺(tái),幫助企業(yè)降低大模型的落地成本,提升訓(xùn)練、推理效率。
潞晨開(kāi)源的智能系統(tǒng)架構(gòu)Colossal-AI技術(shù),有兩大特性:一是最小化部署成本,Colossal-AI 可以顯著提高大規(guī)模AI模型訓(xùn)練和部署的效率。僅需在筆記本電腦上寫(xiě)一個(gè)簡(jiǎn)單的源代碼,Colossal-AI 便可自動(dòng)部署到云端和超級(jí)計(jì)算機(jī)上。
通常訓(xùn)練大模型 (如GPT-3) 需要 100 多個(gè)GPU,而使用Colossal-AI僅需一半的計(jì)算資源。即使在低端硬件條件下,Colossal-AI也可以訓(xùn)練2-3倍的大模型。
二是最大化計(jì)算效率,在并行計(jì)算技術(shù)支持下,Colossal-AI在硬件上訓(xùn)練AI模型,性能顯著提高。潞晨開(kāi)源的目標(biāo)是提升訓(xùn)練AI大模型速度10倍以上。
小結(jié)
如今,全球眾多科技企業(yè)都在研究大模型,然而大模型的訓(xùn)練和部署對(duì)硬件也有極高的要求,高昂的硬件需求和訓(xùn)練成本是當(dāng)前亟待解決的問(wèn)題。可見(jiàn),除了OpenAI、谷歌、百度、阿里等致力于大模型研究企業(yè),以及英偉達(dá)等提供硬件的企業(yè)之外,潞晨科技這類(lèi)提供微調(diào),致力于提升大模型訓(xùn)練和部署效率、降低成本的企業(yè),也值得關(guān)注。
-
大模型
+關(guān)注
關(guān)注
2文章
2322瀏覽量
2479
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何訓(xùn)練自己的LLM模型
如何訓(xùn)練自己的AI大模型
基于Pytorch訓(xùn)練并部署ONNX模型在TDA4應(yīng)用筆記

LLM大模型推理加速的關(guān)鍵技術(shù)
大語(yǔ)言模型的預(yù)訓(xùn)練
人臉識(shí)別模型訓(xùn)練流程
人臉識(shí)別模型訓(xùn)練是什么意思
深度學(xué)習(xí)模型訓(xùn)練過(guò)程詳解
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的預(yù)訓(xùn)練
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
【大語(yǔ)言模型:原理與工程實(shí)踐】核心技術(shù)綜述
百度首席技術(shù)官王海峰解讀文心大模型的關(guān)鍵技術(shù)和最新進(jìn)展

【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】人體姿態(tài)估計(jì)模型部署前期準(zhǔn)備
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】模型部署(以mobilenetV2為例)
物聯(lián)網(wǎng)關(guān)鍵技術(shù)和應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論