") State of GPT:大神Andrej揭秘OpenAI大模型原理和訓(xùn)練過程
State of GPT:大神Andrej揭秘OpenAI大模型原理和訓(xùn)練過程
前言
OpenAI的創(chuàng)始人之一,大神Andrej Karpthy剛在微軟Build 2023開發(fā)者大會(huì)上做了專題演講:State of GPT(GPT的現(xiàn)狀)。
在這個(gè)樸實(shí)無華的題目之下,Andrej帶來的是一場(chǎng)超級(jí)精彩的分享。
他詳細(xì)介紹了如何從GPT基礎(chǔ)模型一直訓(xùn)練出ChatGPT這樣的助手模型(assistant model)。作者不曾在其他公開視頻里看過類似的內(nèi)容,這或許是OpenAI官方第一次詳細(xì)闡述其大模型內(nèi)部原理和RLHF訓(xùn)練細(xì)節(jié)。
難能可貴的是,Andrej不僅深入了細(xì)節(jié), 還高屋建瓴的抽象了大模型實(shí)現(xiàn)中的諸多概念,牛人的洞察就是不一樣。
比如,Andrej非常形象的把當(dāng)前LLM大語言模型比喻為人類思考模式的系統(tǒng)一(快系統(tǒng)),這是相對(duì)于反應(yīng)慢但具有更長(zhǎng)線推理的系統(tǒng)二(慢系統(tǒng))而言。這只是演講里諸多閃光點(diǎn)的其中一個(gè)。
并且,Andrej真的有當(dāng)導(dǎo)師的潛力,把非常技術(shù)的內(nèi)容講得深入淺出,而又異常透徹。這個(gè)演講完全可以讓非專業(yè)人士也能理解,并且,認(rèn)真看完演講后會(huì)有一種醍醐灌頂?shù)母杏X。
這場(chǎng)主題演講是如此精彩,以至于作者認(rèn)為,所有關(guān)心LLM大語言模型的人都不容錯(cuò)過。所以,在制作視頻之余,特以此文整理,和大家分享。
此外,在本文最后還有一些拓展閱讀,同樣非常推薦,有興趣的讀者可以自取。
本次演講的精校完整中文版視頻的B站傳送門:
https://www.bilibili.com/video/BV1ts4y1T7UH
(視頻號(hào)莫名不讓分享這個(gè)視頻,大家移步b站吧)
(演講全文)
大家好。
我很高興在這里向您介紹 GPT 的狀態(tài),更廣泛地介紹大型語言模型快速發(fā)展的生態(tài)系統(tǒng)。
我想把演講分成兩部分:
在第一部分我想告訴你我們是如何訓(xùn)練 GPT 助手的;
然后在第二部分中,我們將了解如何將這些助手有效地用于您的應(yīng)用程序。

首先讓我們看一下如何訓(xùn)練這些助手的新興秘訣,并記住這一切都是非常新的,并且仍在迅速發(fā)展。
但到目前為止,食譜看起來像這樣。這是一張有點(diǎn)復(fù)雜的幻燈片,我將逐一介紹它。

粗略地說,我們有四個(gè)主要階段:預(yù)訓(xùn)練、有監(jiān)督微調(diào)、獎(jiǎng)勵(lì)建模、強(qiáng)化學(xué)習(xí),依次類推。
現(xiàn)在在每個(gè)階段我們都有一個(gè)數(shù)據(jù)集來支持。我們有一個(gè)算法,我們?cè)诓煌A段的目的,將成為訓(xùn)練神經(jīng)網(wǎng)絡(luò)的目標(biāo)。然后我們有一個(gè)結(jié)果模型,然后在上圖底部有一些注釋。
Pretraining 預(yù)訓(xùn)練
我們要開始的第一個(gè)階段是預(yù)訓(xùn)練階段。

這個(gè)階段在這個(gè)圖中有點(diǎn)特殊:這個(gè)圖沒有按比例縮放,這個(gè)階段實(shí)際上是所有計(jì)算工作基本上發(fā)生的地方,相當(dāng)于訓(xùn)練計(jì)算時(shí)間的 99%。
因此,這就是我們?cè)诔?jí)計(jì)算機(jī)中使用數(shù)千個(gè) GPU 以及可能進(jìn)行數(shù)月的訓(xùn)練來處理互聯(lián)網(wǎng)規(guī)模數(shù)據(jù)集的地方。
其他三個(gè)階段是微調(diào)階段,更多地遵循少量 GPU 和數(shù)小時(shí)或數(shù)天的路線。
那么讓我們來看看實(shí)現(xiàn)基礎(chǔ)模型的預(yù)訓(xùn)練階段。
首先,我們要收集大量數(shù)據(jù)。這是我們稱之為數(shù)據(jù)混合的示例,該示例來自 Meta 發(fā)布的這篇論文,他們發(fā)布了這個(gè) Llama 基礎(chǔ)模型。

可以大致看到進(jìn)入這些集合的數(shù)據(jù)集的種類,我們有common crawl這只是一個(gè)網(wǎng)絡(luò)爬取,C4也是common crawl,然后還有一些高質(zhì)量的數(shù)據(jù)集。例如,GitHub、維基百科、書籍、ArXiv論文存檔、StackExchange問答網(wǎng)站等。這些都混合在一起,然后根據(jù)給定的比例進(jìn)行采樣,形成 GPT 神經(jīng)網(wǎng)絡(luò)的訓(xùn)練集。
現(xiàn)在,在我們實(shí)際訓(xùn)練這些數(shù)據(jù)之前,我們需要再經(jīng)過一個(gè)預(yù)處理步驟,即標(biāo)記化(tokenization)。

這基本上是將我們從互聯(lián)網(wǎng)上抓取的原始文本翻譯成整數(shù)序列,因?yàn)檫@是 GPT 運(yùn)行的原生表示。
標(biāo)記化是文本片段和標(biāo)記與整數(shù)之間的一種無損轉(zhuǎn)換,這個(gè)階段有許多算法。通常您可以使用諸如字節(jié)編碼之類的東西,它迭代地合并小文本塊并將它們分組為標(biāo)記。
在這里我展示了這些標(biāo)記的一些示例塊,然后這是將實(shí)際饋入Transformer的原始整數(shù)序列。
現(xiàn)在我在這里展示了兩個(gè)類似的例子,用于控制這個(gè)階段的超參數(shù)。
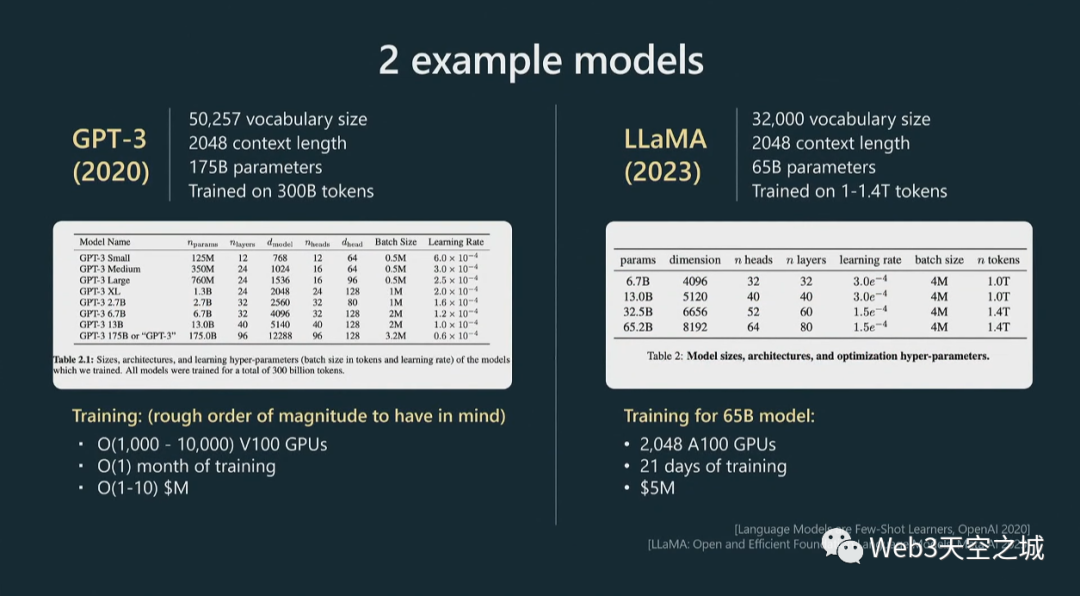
GPT4,我們沒有發(fā)布太多關(guān)于它是如何訓(xùn)練的信息,所以我使用 GPT3 的數(shù)字;GPT3 現(xiàn)在有點(diǎn)老了,大約三年前。但是Llama是 Meta 的一個(gè)相當(dāng)新的模型。
這些大致是我們?cè)谶M(jìn)行預(yù)訓(xùn)練時(shí)要處理的數(shù)量級(jí):詞匯量通常是幾萬個(gè)標(biāo)記。上下文長(zhǎng)度通常是 2,000、4,000,現(xiàn)在甚至是 100,000,這決定了 GPT 在嘗試預(yù)測(cè)序列中的下一個(gè)整數(shù)時(shí)將查看的最大整數(shù)數(shù)。
你可以看到,Llama 的參數(shù)數(shù)量大概是 650 億。現(xiàn)在,盡管與 GPT3 的 1750 億個(gè)參數(shù)相比,Llama 只有 65 個(gè) B 參數(shù),但 Llama 是一個(gè)明顯更強(qiáng)大的模型,直觀地說,這是因?yàn)樵撃P偷挠?xùn)練時(shí)間明顯更長(zhǎng),訓(xùn)練了1.4 萬億標(biāo)記而不是 3000 億標(biāo)記。所以你不應(yīng)該僅僅通過模型包含的參數(shù)數(shù)量來判斷模型的能力。
這里我展示了一些粗略的超參數(shù)表,這些超參數(shù)通常用于指定 Transformer 神經(jīng)網(wǎng)絡(luò)。比如頭的數(shù)量,尺寸大小,層數(shù)等等。
在底部,我展示了一些訓(xùn)練超參數(shù)。例如,為了訓(xùn)練 65 B 模型,Meta 使用了 2,000 個(gè) GPU,大約訓(xùn)練了 21 天,大約花費(fèi)了數(shù)百萬美元。
這是您在預(yù)訓(xùn)練階段應(yīng)該記住的粗略數(shù)量級(jí)。
現(xiàn)在,當(dāng)我們實(shí)際進(jìn)行預(yù)訓(xùn)練時(shí),會(huì)發(fā)生什么?
一般來說,我們將獲取我們的標(biāo)記并將它們放入數(shù)據(jù)批次中。

我們有這些數(shù)組將饋入Transformer,這些數(shù)組是 B,批量大小,這些都是按行堆疊的獨(dú)立示例,B 乘以 T,T 是最大上下文長(zhǎng)度。在我的這個(gè)圖里,長(zhǎng)度只有十個(gè),實(shí)際工作里這可能是 2,000、4,000 等等。這些是非常長(zhǎng)的行。
我們所做的是獲取這些文檔并將它們打包成行,然后用這些特殊的文本結(jié)束標(biāo)記將它們分隔開,基本上是為了告訴Transformer新文檔從哪里開始。
這里我有幾個(gè)文檔示例,然后將它們擴(kuò)展到這個(gè)輸入中。現(xiàn)在,將把所有這些數(shù)字輸入到 Transformer 中。
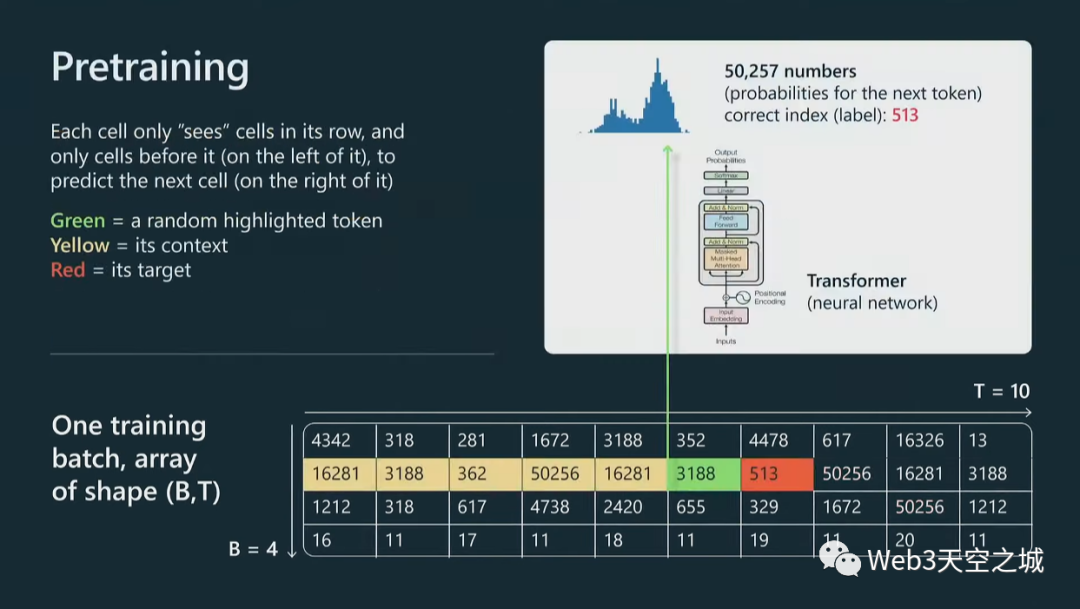
我們只關(guān)注一個(gè)特定的單元格,但同樣的事情會(huì)發(fā)生在這個(gè)圖中的每個(gè)單元格上。
讓我們看看綠色單元格。綠色單元會(huì)查看它之前的所有標(biāo)記,所有標(biāo)記都是黃色的,我們將把整個(gè)上下文輸入到 Transformer 神經(jīng)網(wǎng)絡(luò)中,Transformer 將嘗試預(yù)測(cè) 序列中的下一個(gè)標(biāo)記,在本例中為紅色。
不幸的是,我現(xiàn)在沒有太多時(shí)間來詳細(xì)介紹Transformer這個(gè)神經(jīng)網(wǎng)絡(luò)架構(gòu)。(注:特別棒和巧的,Andrej做過一次斯坦福課程,專門深入講解了Transformer神經(jīng)網(wǎng)絡(luò)架構(gòu),同樣非常推薦,中文版視頻附在本文結(jié)尾)
對(duì)于我們的目的來說,Transformer只是一大堆神經(jīng)網(wǎng)絡(luò)的東西,通常有幾百億個(gè)參數(shù),或者類似的東西。當(dāng)然,當(dāng)您調(diào)整這些參數(shù)時(shí),您會(huì)得到這些單元格中的每一個(gè)單元格的預(yù)測(cè)分布略有不同。
例如,如果我們的詞匯表大小是 50,257 個(gè)標(biāo)記,那么我們將擁有那么多數(shù)字,因?yàn)槲覀冃枰獮榻酉聛戆l(fā)生的事情指定概率分布。基本上,我們有可能發(fā)生任何事情。
現(xiàn)在,在這個(gè)特定的例子中,對(duì)于這個(gè)特定的單元格,513 將是下一個(gè)標(biāo)記,因此我們可以將其用作監(jiān)督源來更新Transformer的權(quán)重。將同樣的做法應(yīng)用于并行中的每個(gè)單元格,并且不斷交換批次,并且試圖讓Transformer對(duì)序列中接下來出現(xiàn)的標(biāo)記做出正確的預(yù)測(cè)。
讓我更具體地向您展示當(dāng)您訓(xùn)練其中一個(gè)模型時(shí)的情況。
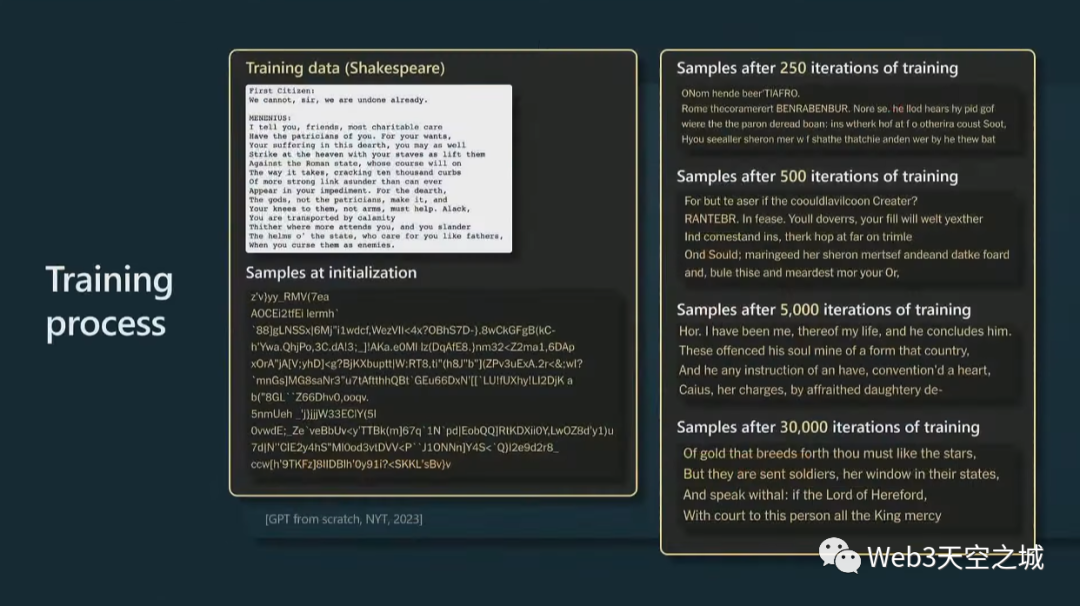
這實(shí)際上來自紐約時(shí)報(bào),他們?cè)谏勘葋喩嫌?xùn)練了一個(gè)小的 GPT,這是莎士比亞的一小段,他們?cè)谏厦嬗?xùn)練了一個(gè) GPT。
一開始,在初始化時(shí),GPT 以完全隨機(jī)的權(quán)重開始,因此也將獲得完全隨機(jī)的輸出。但是,隨著時(shí)間的推移,當(dāng)訓(xùn)練 GPT 的時(shí)間越來越長(zhǎng)時(shí),我們會(huì)從模型中獲得越來越連貫和一致的樣本。
當(dāng)然,你從中抽樣的方式是預(yù)測(cè)接下來會(huì)發(fā)生什么,你從那個(gè)分布中抽樣,然后不斷將其反饋到過程中,基本上就是對(duì)大序列進(jìn)行抽樣。到最后,你會(huì)看到 Transformer 已經(jīng)學(xué)會(huì)了單詞,以及在哪里放置空格,在哪里放置逗號(hào)等等。
隨著時(shí)間的推移,模型正在做出越來越一致的預(yù)測(cè)。
然后以下這些,是您在進(jìn)行模型預(yù)訓(xùn)練時(shí)會(huì)查看的圖類型。
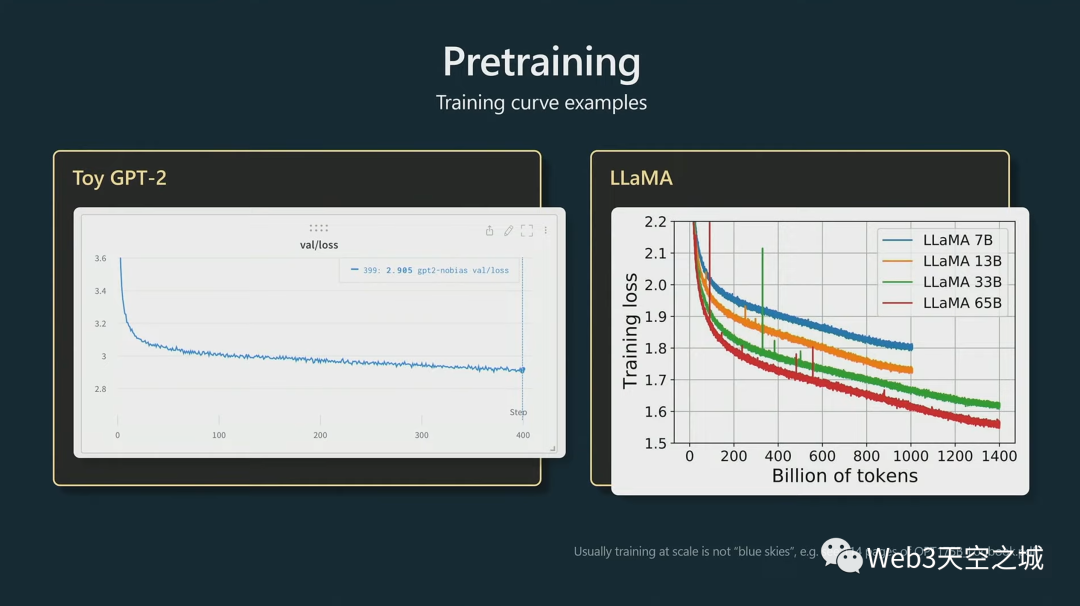
實(shí)際上,我們?cè)谟?xùn)練時(shí)查看隨時(shí)間變化的損失函數(shù),低損失意味著我們的Transformer正在預(yù)測(cè)正確 - 為序列中正確的下一個(gè)整數(shù)提供更高的概率。
訓(xùn)練一個(gè)月后,我們將如何處理這個(gè)模型?
我們注意到的第一件事,在這個(gè)領(lǐng)域,這些模型基本上在語言建模過程中學(xué)習(xí)了非常強(qiáng)大的通用表示,并且可以非常有效地微調(diào)它們以用于您可能感興趣的任何下游任務(wù) 。
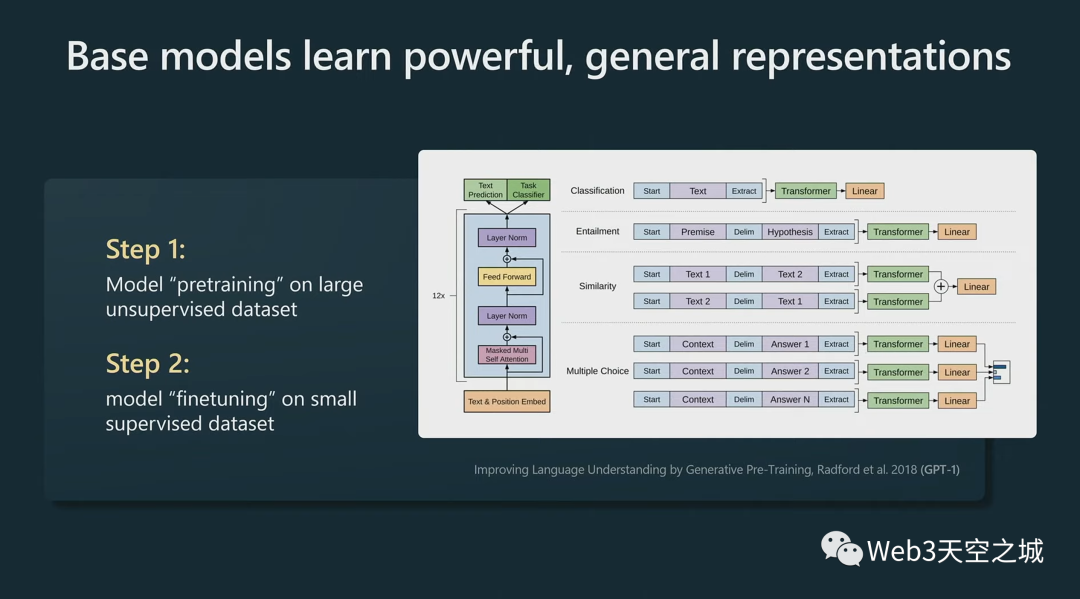
舉個(gè)例子,如果對(duì)情感分類感興趣,過去的方法是收集一堆正面和負(fù)面的信息,然后為此訓(xùn)練某種 NLP 模型,
但新方法是忽略情感分類,直接去進(jìn)行大型語言模型預(yù)訓(xùn)練,訓(xùn)練大型Transformer,然后你可能只有幾個(gè)例子,已經(jīng)可以非常有效地為該任務(wù)微調(diào)你的模型。
這在實(shí)踐中非常有效。
這樣做的原因基本上是 Transformer 被迫在語言建模任務(wù)中同時(shí)處理大量任務(wù),因?yàn)榫皖A(yù)測(cè)下一個(gè)標(biāo)記而言,它被迫了解很多關(guān)于文本的結(jié)構(gòu)和其中所有不同的概念。這就是 GPT-1。
在 GPT-2 前后,人們注意到比微調(diào)更好的是,你可以非常有效地提示(prompt)這些模型。
這些是語言模型,它們想要完成文檔,所以你可以通過排列這些假文檔來欺騙它們執(zhí)行任務(wù)。

在這個(gè)例子中,例如,我們有一些段落,然后我們做 QA(問和答),QA,QA,幾次提示,然后我們做 Q,然后,當(dāng) Transformer 試圖完成文檔時(shí),它實(shí)際上是在回答我們的問題。
這就是一個(gè)提示工程(prompt engineering)基礎(chǔ)模型的示例,通過提示工程讓模型相信它正在模仿文檔并讓它執(zhí)行特定的任務(wù)。
這開啟了提示高于微調(diào)(prompt over finetuning)的時(shí)代。我們看到,即使沒有對(duì)任何神經(jīng)網(wǎng)絡(luò)進(jìn)行微調(diào),它也可以在很多問題上非常有效。
從那時(shí)起,我們就看到了每個(gè)人都知道的,基礎(chǔ)模型的完整進(jìn)化樹:
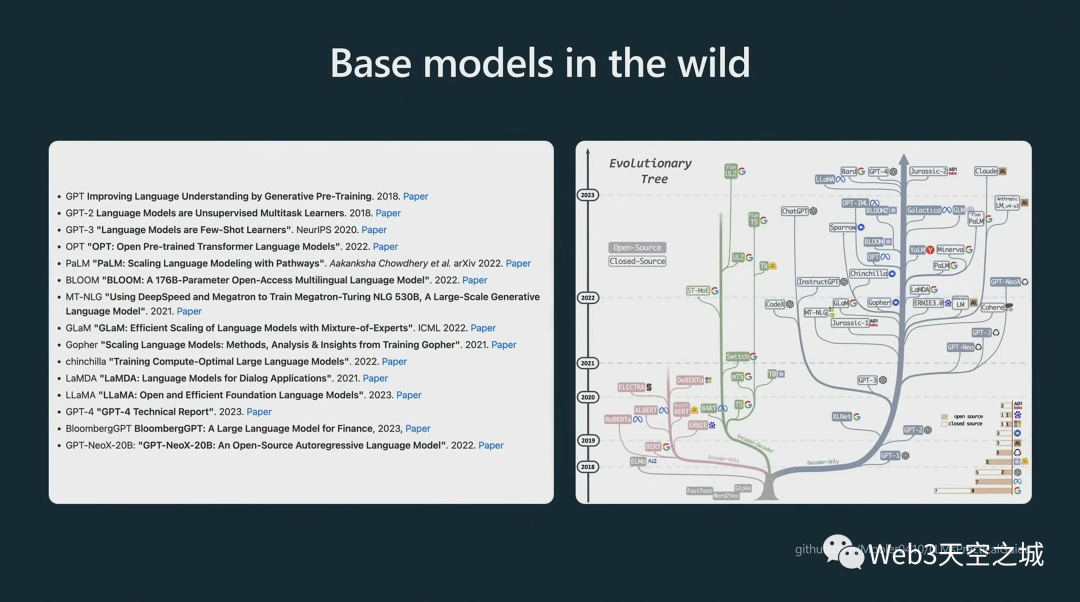
并非所有這些模型型號(hào)都可用。
例如,GPT-4 基礎(chǔ)模型從未發(fā)布。您可能通過 API 與之交互的 GPT-4 模型不是基礎(chǔ)模型,而是輔助模型,我們稍后將介紹如何獲取這些模型;
GPT-3 基礎(chǔ)模型可通過名為 DaVinci 的 API 獲得;
GPT-2 基礎(chǔ)模型可在我們的 GitHub 存儲(chǔ)庫(kù)上作為權(quán)重獲得;
目前最好的(可以公開獲得的)基礎(chǔ)模型是 Meta 的 Llama 系列,盡管它沒有商業(yè)許可。
需要指出的一件事是,基礎(chǔ)模型不是助手(assistant,即類似ChatGPT的問答助手),它們不想回答你的問題,它們只是想完成文件(笑)。

所以如果你告訴基礎(chǔ)模型:“寫一首關(guān)于面包和奶酪的詩(shī)”,它會(huì)用更多的問題來回答問題。它只是在完成它認(rèn)為是文檔的內(nèi)容。
但是,您可以在基礎(chǔ)模型里以特定方式提示以更可能得到結(jié)果。例如,“這是一首關(guān)于面包和奶酪的詩(shī)“。在這種情況下,它將正確地自動(dòng)完成。
你甚至可以欺騙基礎(chǔ)模型成為助手,你這樣做的方法是創(chuàng)建一個(gè)特定的小提示,讓它看起來像是人和助手之間有一份文件,他們正在交換信息。
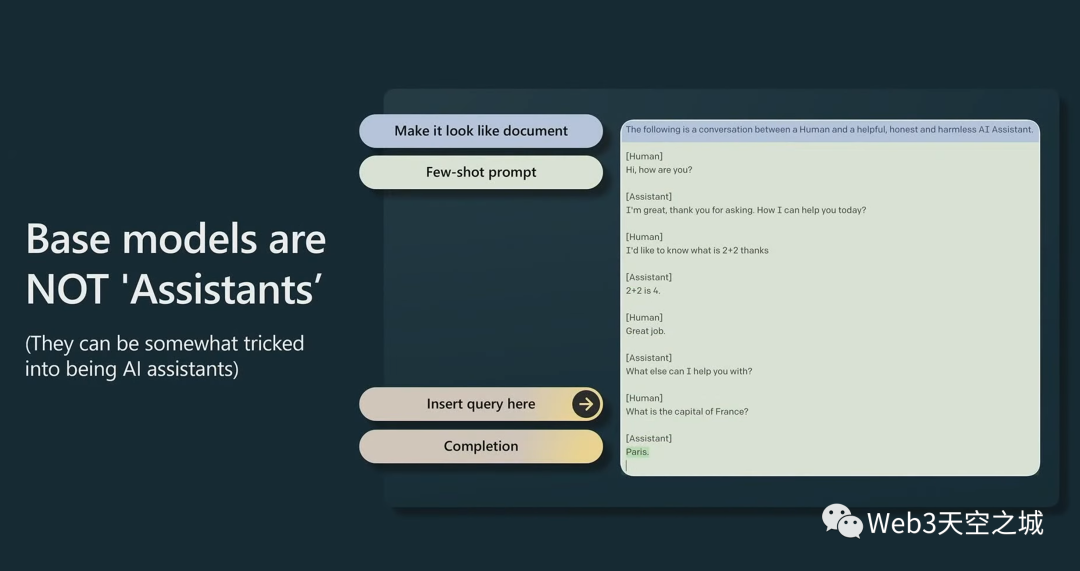
然后,在底部,您將查詢放在最后,基礎(chǔ)模型將自我調(diào)整為有用的助手和某種答案(生成這種形式的文檔)。
這不是很可靠,在實(shí)踐中也不是很好,盡管它可以做到。
Supervised Finetuning 監(jiān)督微調(diào)
相反,我們有不同的途徑來制作實(shí)際的 GPT 助手(GPT Assistant),而不僅僅是基礎(chǔ)模型文檔完成器。
這將我們帶入有監(jiān)督的微調(diào)。

在有監(jiān)督的微調(diào)階段,我們將收集少量但高質(zhì)量的數(shù)據(jù)集。在這種情況下,我們要求人工承包商收集及時(shí)和理想響應(yīng)形式的數(shù)據(jù)。
我們收集很多這樣的東西,通常是類似數(shù)萬個(gè)這種數(shù)量。然后我們?nèi)詫?duì)這些數(shù)據(jù)進(jìn)行語言建模,因此算法上沒有任何改變。
我們只是換出一個(gè)訓(xùn)練集。它曾經(jīng)是互聯(lián)網(wǎng)文檔,那是一種量很大但質(zhì)量不高的數(shù)據(jù),我們換成用QA即時(shí)響應(yīng)的數(shù)據(jù)。那是低數(shù)量但高質(zhì)量的。
我們還是做語言建模,然后,訓(xùn)練之后,我們得到一個(gè)SFT(Supervised Finetuning 監(jiān)督微調(diào))模型。
你可以實(shí)際部署這些模型,它們是實(shí)際的助手,它們?cè)谝欢ǔ潭壬掀鹱饔谩?/p>
讓我向您展示示例演示的樣子。這里有一個(gè)人類承包商可能會(huì)想出的東西,這是一個(gè)隨機(jī)的演示:

你寫了一篇關(guān)于壟斷一詞的相關(guān)性的簡(jiǎn)短介紹,或者類似的東西,然后承包商也寫下了一個(gè)理想的回應(yīng)。當(dāng)他們寫下這些回復(fù)時(shí),他們遵循大量的標(biāo)簽文檔,并且要求他們生成提供幫助、真實(shí)且無害的回答。
這是這里的標(biāo)簽說明。
你可能看不懂,我也看不懂,它們很長(zhǎng),人們按照說明并試圖完成這些提示。
這就是數(shù)據(jù)集的樣子,你可以訓(xùn)練這些模型,這在一定程度上是有效的。
Reward Modeling 獎(jiǎng)勵(lì)建模
現(xiàn)在,我們可以從這里繼續(xù)流程,進(jìn)入 RLHF,即“從人類反饋中強(qiáng)化學(xué)習(xí)”,它包括獎(jiǎng)勵(lì)建模和強(qiáng)化學(xué)習(xí)。

讓我介紹一下,然后我將回過頭來討論為什么您可能想要完成額外的步驟,以及這與 僅有SFT 模型相比如何。
在獎(jiǎng)勵(lì)建模步驟中,我們現(xiàn)在要做的是將數(shù)據(jù)收集轉(zhuǎn)變?yōu)楸容^形式。
下面是我們的數(shù)據(jù)集的示例。
頂部是相同的提示,它要求助手編寫一個(gè)程序或一個(gè)函數(shù)來檢查給定的字符串是否為回文。
然后我們做的是采用已經(jīng)訓(xùn)練過的 SFT 模型,并創(chuàng)建多個(gè)補(bǔ)全。在這種情況下,我們有模型創(chuàng)建的三個(gè)補(bǔ)全。然后我們要求人們對(duì)這些補(bǔ)全進(jìn)行排名。
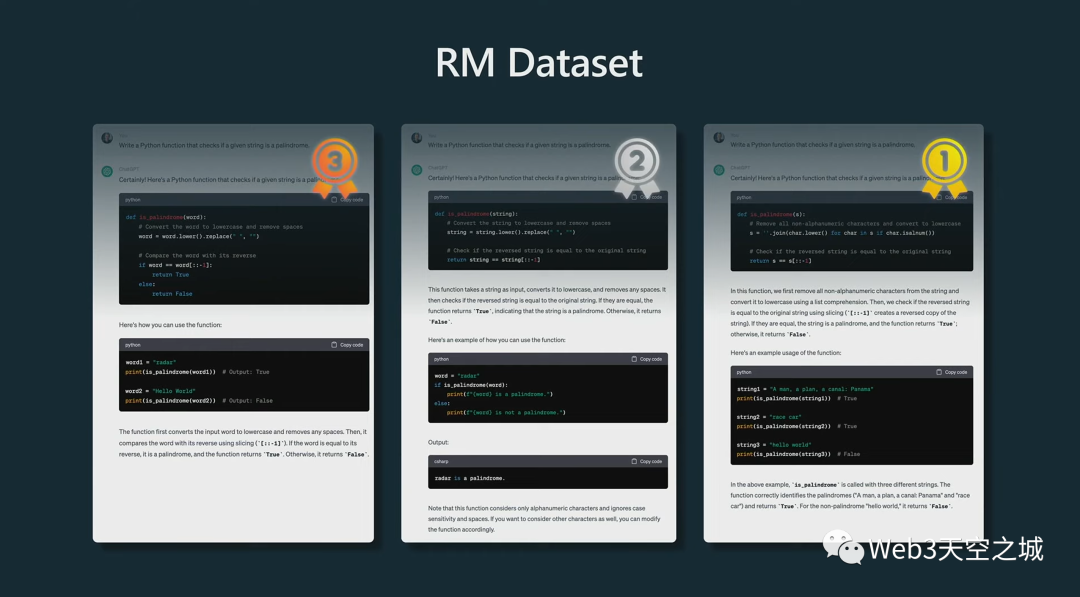
如果你盯著它看一會(huì)兒——順便說一下,要比較其中的一些預(yù)測(cè)是非常困難的事情,而且這可能需要人們甚至幾個(gè)小時(shí)來完成一個(gè)提示補(bǔ)全的比較。但假設(shè)我們決定,其中一個(gè)比其他的好得多,依此類推,我們對(duì)它們進(jìn)行排名。
然后,我們可以對(duì)這些補(bǔ)全之間的所有可能對(duì),進(jìn)行看起來非常像二元分類的東西(以進(jìn)行排序)。

接著,要做的是將提示按行排列,這里所有三行的提示都是相同的,但補(bǔ)全方式不同,黃色標(biāo)記來自 SFT 模型,我們?cè)谧詈蟾郊恿硪粋€(gè)特殊的獎(jiǎng)勵(lì)讀出標(biāo)記,基本上只在這個(gè)單一的綠色標(biāo)記上監(jiān)督Transformer。Transformer會(huì)根據(jù)提示的完成程度預(yù)測(cè)一些獎(jiǎng)勵(lì)。
Transformer對(duì)每個(gè)補(bǔ)全的質(zhì)量進(jìn)行了猜測(cè),然后,一旦對(duì)每個(gè)補(bǔ)全進(jìn)行了猜測(cè),我們就有了模型對(duì)它們排名的基本事實(shí),而我們實(shí)際上可以強(qiáng)制其中一些數(shù)字應(yīng)該比其他數(shù)字高得多,我們將其制定為損失函數(shù),并訓(xùn)練我們的模型,使得模型做出與來自人類承包商的比較事實(shí)數(shù)據(jù)相一致的獎(jiǎng)勵(lì)預(yù)測(cè)。 這就是我們訓(xùn)練獎(jiǎng)勵(lì)模型的方式。這使我們能夠?qū)μ崾镜耐瓿沙潭冗M(jìn)行評(píng)分。
Reinforcement Learning 強(qiáng)化學(xué)習(xí)
現(xiàn)在我們有了獎(jiǎng)勵(lì)模型,但我們還不能部署它。
因?yàn)樗旧碜鳛橹植皇呛苡杏茫撬鼘?duì)于現(xiàn)在接下來的強(qiáng)化學(xué)習(xí)階段非常有用。

因?yàn)槲覀冇幸粋€(gè)獎(jiǎng)勵(lì)模型,所以我們可以對(duì)任何給定提示(prompt)的任意完成/補(bǔ)全(completion)質(zhì)量進(jìn)行評(píng)分。
我們?cè)趶?qiáng)化學(xué)習(xí)期間所做的基本上是再次獲得大量提示,然后針對(duì)獎(jiǎng)勵(lì)模型進(jìn)行強(qiáng)化學(xué)習(xí)。
這就是它的樣子:
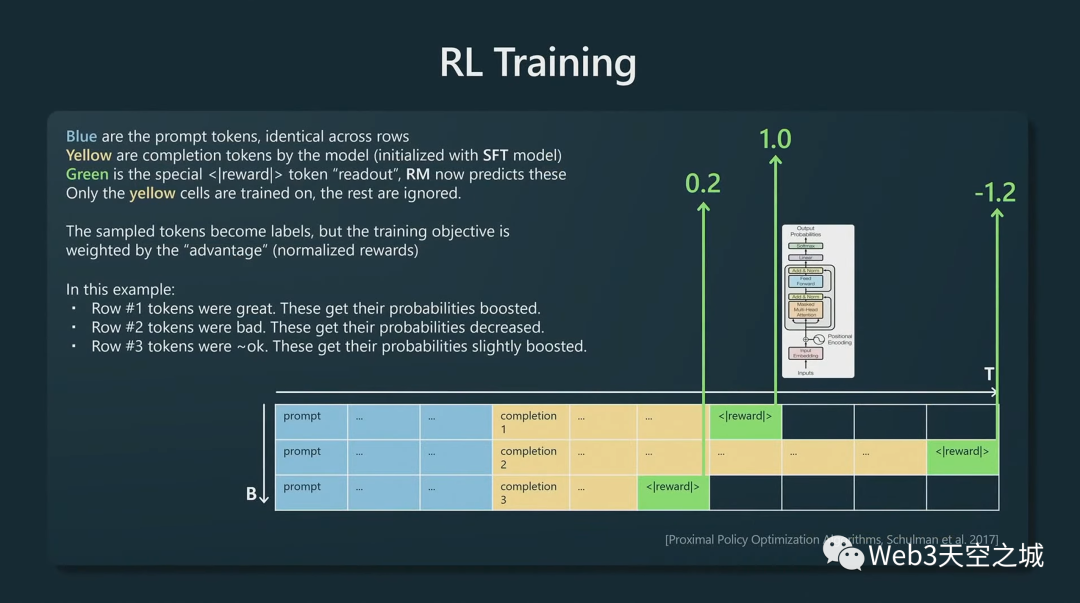
我們接受一個(gè)提示,將其排成行,現(xiàn)在我們使用想要訓(xùn)練的模型,將該模型初始化為 SFT 模型,以創(chuàng)建一些黃色的補(bǔ)全。
然后,再追加獎(jiǎng)勵(lì)標(biāo)記,按照已經(jīng)固定不變的獎(jiǎng)勵(lì)模型讀出獎(jiǎng)勵(lì)分?jǐn)?shù),現(xiàn)在這個(gè)獎(jiǎng)勵(lì)模型的評(píng)分不再變化。獎(jiǎng)勵(lì)模型告訴我們這些提示的每一次完成的質(zhì)量。
我們現(xiàn)在基本上可以用(和前面)相同的語言建模損失函數(shù),但我們目前正在對(duì)黃色標(biāo)記進(jìn)行訓(xùn)練,并且我們正在通過獎(jiǎng)勵(lì)模型指示的獎(jiǎng)勵(lì)來權(quán)衡語言建模目標(biāo)。
例如,在第一行中,獎(jiǎng)勵(lì)模型表示這是一個(gè)相當(dāng)高的完成度,因此我們碰巧在第一行采樣的所有標(biāo)記都將得到強(qiáng)化,它們將 獲得更高的未來概率。相反,在第二行,獎(jiǎng)勵(lì)模型真的不喜歡這個(gè)完成,負(fù) 1.2,因此我們?cè)诘诙胁蓸拥拿總€(gè)標(biāo)記在未來都會(huì)有更低的概率。
我們?cè)诤芏嗵崾尽⒑芏嗯紊弦槐橛忠槐榈剡@樣做,基本上,我們得到一個(gè)在這里創(chuàng)建黃色標(biāo)記的策略,讓所有完成標(biāo)記都會(huì)根據(jù)我們?cè)谇耙浑A段訓(xùn)練的獎(jiǎng)勵(lì)模型獲得高分。
這就是我們訓(xùn)練的方式——這就是 RLHF 流程。
最后,您得到了一個(gè)可以部署的模型。例如,ChatGPT 是 RLHF 模型。您可能會(huì)遇到其他一些模型,例如 Kuna 13B 等,這些都是 SFT 模型。
我們有基礎(chǔ)模型、SFT 模型和 RLHF 模型,這基本上是可用模型列表的事物狀態(tài)。
你為什么想要做 RLHF?一個(gè)不太令人興奮的答案是它的效果更好。
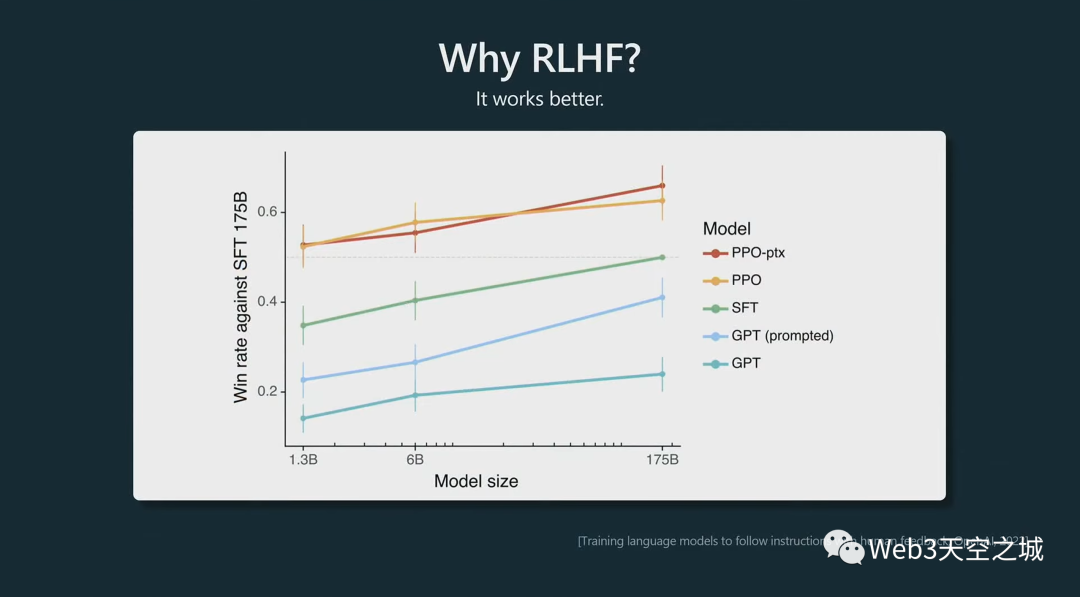
以上這個(gè)圖來自instructGPT論文。
這些 PPO 模型是 RLHF,根據(jù)前一段時(shí)間的這些實(shí)驗(yàn),我們看到把它們提供給人類時(shí),它們?cè)诤芏啾容^中更受歡迎。與提示為助手的基礎(chǔ)模型相比,與 SFT 模型相比,人類基本上更喜歡來自 RLHF 模型的標(biāo)記(輸出文字)。
它就是工作得更好。
但你可能會(huì)問為什么?為什么效果更好?
我不認(rèn)為社區(qū)有一個(gè)一致的令人驚奇的答案,但我可能提供一個(gè)原因:它與計(jì)算比較容易程度與生成容易程度之間的不對(duì)稱有關(guān)。
讓我們以生成俳句為例。假設(shè)我請(qǐng)模特寫一首關(guān)于回形針的俳句。
如果你是一個(gè)試圖提供訓(xùn)練數(shù)據(jù)的承包商,那么想象一下,作為一個(gè)為 SFT 階段收集基本數(shù)據(jù)的承包商,你應(yīng)該如何為一個(gè)回形針創(chuàng)建一個(gè)漂亮的俳句?
你可能不太擅長(zhǎng)這個(gè)。
但是,如果我給你舉幾個(gè)俳句的例子,你可能會(huì)比其他人更能欣賞其中的一些俳句。
因此,判斷其中哪一個(gè)是好的是一項(xiàng)容易得多的任務(wù)。
基本上,這種不對(duì)稱性使得比較成為一種更好的方式,可以潛在地利用你作為一個(gè)人和你的判斷力來創(chuàng)建一個(gè)稍微更好的模型。
但是,RLHF 模型在某些情況下并不是對(duì)基礎(chǔ)模型的嚴(yán)格改進(jìn)。
特別是,我們注意到,例如,RLHF模型失去了一些熵,這意味著它們給出了更多的峰值結(jié)果。

它們可以輸出更低的變化,可以輸出比基礎(chǔ)模型變化更少的樣本。
基礎(chǔ)模型有更多熵,會(huì)給出很多不同的輸出。我仍然更喜歡使用基礎(chǔ)模型的一種地方是。。。比如有 n 個(gè)東西并且想要生成更多類似東西的場(chǎng)景中。
這是我剛剛編造的一個(gè)例子。
我想生成很酷的口袋妖怪名字。我給了它七個(gè)口袋妖怪的名字,讓基礎(chǔ)模型完成了文檔。它給了我更多的口袋妖怪名字。
這些都是虛構(gòu)的,我還試圖查找它們,確定它們不是真正的口袋妖怪。
這是我認(rèn)為基礎(chǔ)模型擅長(zhǎng)的任務(wù),因?yàn)樗匀挥泻芏囔兀⑶視?huì)給你很多不同的、很酷的、更多的東西,看起來像你以前給它的任何東西。
說了這么多,這些是你現(xiàn)在可以使用的輔助模型,有一些數(shù)字:

伯克利有一個(gè)團(tuán)隊(duì)對(duì)許多可用的助手模型進(jìn)行排名,并基本上給了它們 ELO 評(píng)級(jí)。
目前最好的模型毫無疑問是 GPT-4,其次是 Claude,GPT-3.5,然后是一些模型,其中一些可能作為權(quán)重提供,比如 Kuna、Koala 等。
這里排名前三的是 RLHF 模型,據(jù)我所知,我相信所有其他模型都是 SFT 模型。
將GPT助手模型應(yīng)用于問題
以上是我們?cè)诟邔哟紊嫌?xùn)練這些模型的方式。
現(xiàn)在我要換個(gè)方向,讓我們看看如何最好地將 GPT 助手模型應(yīng)用于您的問題。
現(xiàn)在我想在一個(gè)具體示例的場(chǎng)景里展示。讓我們?cè)谶@里使用一個(gè)具體示例。
假設(shè)你正在寫一篇文章或一篇博客文章,你打算在最后寫這句話。

加州的人口是阿拉斯加的 53 倍。因此出于某種原因,您想比較這兩個(gè)州的人口。
想想我們自己豐富的內(nèi)心獨(dú)白和工具的使用,以及在你的大腦中實(shí)際進(jìn)行了多少計(jì)算工作來生成這最后一句話。
這可能是你大腦中的樣子:
好的。對(duì)于下一步,讓我寫博客——在我的博客中,讓我比較這兩個(gè)人群。
好的。首先,我顯然需要得到這兩個(gè)人群。
現(xiàn)在我知道我可能根本不了解這些人群。
我有點(diǎn),比如,意識(shí)到我知道或不知道我的自我知識(shí);正確的?
我去了——我做了一些工具的使用,然后我去了維基百科,我查找了加利福尼亞的人口和阿拉斯加的人口。
現(xiàn)在我知道我應(yīng)該把兩者分開。
同樣,我知道用 39.2 除以 0.74 不太可能成功。
那不是我腦子里能做的事情。
因此,我將依靠計(jì)算器。
我打算用一個(gè)計(jì)算器,把它打進(jìn)去,看看輸出大約是 53。
然后也許我會(huì)在我的大腦中做一些反思和理智檢查。
那么53有意義嗎?
好吧,這是相當(dāng)大的一部分,但是加利福尼亞是人口最多的州,也許這看起來還可以。
這樣我就有了我可能需要的所有信息,現(xiàn)在我開始寫作的創(chuàng)造性部分了。
我可能會(huì)開始寫類似,加利福尼亞有 53 倍之類的東西,然后我對(duì)自己說,這實(shí)際上是非常尷尬的措辭,讓我刪除它,然后再試一次。
在我寫作的時(shí)候,我有一個(gè)獨(dú)立的過程,幾乎是在檢查我正在寫的東西,并判斷它是否好看。
然后也許我刪除了,也許我重新構(gòu)造了它,然后也許我對(duì)結(jié)果感到滿意。
基本上,長(zhǎng)話短說,當(dāng)你創(chuàng)造這樣的句子時(shí),你的內(nèi)心獨(dú)白會(huì)發(fā)生很多事情。
但是,當(dāng)我們?cè)谄渖嫌?xùn)練 GPT 時(shí),這樣的句子是什么樣的?
從 GPT 的角度來看,這只是一個(gè)標(biāo)記序列。
因此,當(dāng) GPT 讀取或生成這些標(biāo)記時(shí),它只會(huì)進(jìn)行分塊、分塊、分塊,每個(gè)塊對(duì)每個(gè)標(biāo)記的計(jì)算工作量大致相同。
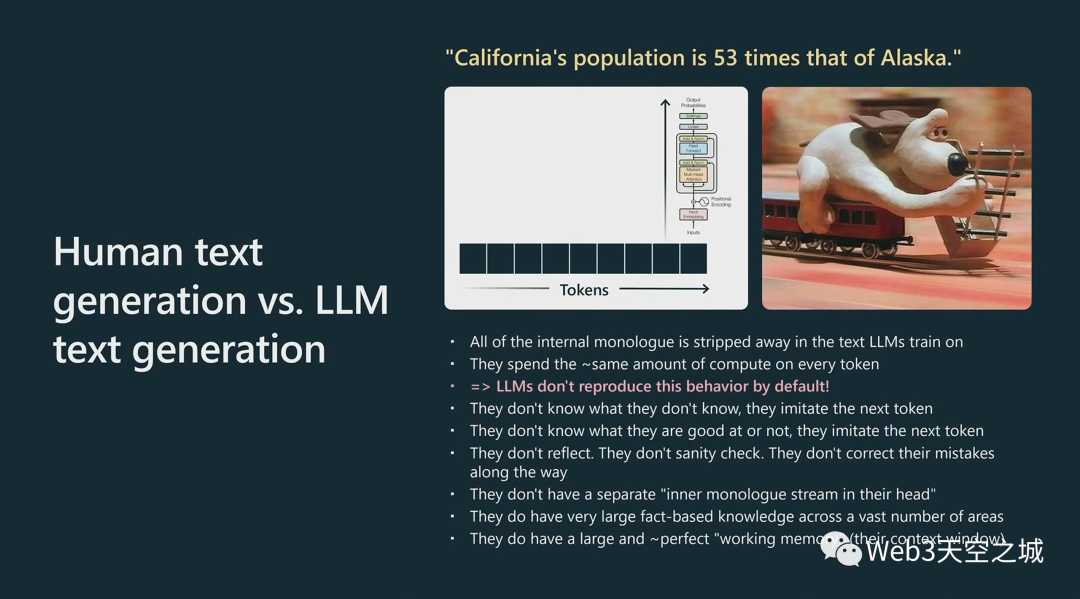
這些 Transformer 都不是很淺的網(wǎng)絡(luò),它們有大約 80 層的推理,但 80 仍然不算太多。
這個(gè)Transformer將盡最大努力模仿。..但是,當(dāng)然,這里的過程看起來與你采用的過程非常非常不同。
特別是,在我們最終的人工制品中,在創(chuàng)建并最終提供給 LLM 的數(shù)據(jù)集中,所有內(nèi)部對(duì)話都被完全剝離(只給出最后結(jié)果作為訓(xùn)練數(shù)據(jù))。
并且與您不同的是,GPT 將查看每個(gè)標(biāo)記并花費(fèi)相同的算力去計(jì)算它們中的每一個(gè),實(shí)際上,你不能指望它對(duì)每個(gè)標(biāo)記做太多的工作。
基本上,這些Transformer就像標(biāo)記模擬器。它們不知道自己不知道什么,它們只是模仿(預(yù)測(cè))下一個(gè)標(biāo)記;它們不知道自己擅長(zhǎng)什么,不擅長(zhǎng)什么,只是盡力模仿(預(yù)測(cè))下一個(gè)標(biāo)記。
它們不反映在循環(huán)中,它們不檢查任何東西,它們?cè)谀J(rèn)情況下不糾正它們的錯(cuò)誤,它們只是對(duì)標(biāo)記序列進(jìn)行采樣。
它們的頭腦中沒有單獨(dú)的內(nèi)心獨(dú)白流,它們正在評(píng)估正在發(fā)生的事情。
現(xiàn)在它們確實(shí)有某種認(rèn)知優(yōu)勢(shì),我想說,那就是它們實(shí)際上擁有大量基于事實(shí)的知識(shí),涵蓋大量領(lǐng)域,因?yàn)樗鼈冇袔装賰|個(gè)參數(shù),這是大量存儲(chǔ)和大量事實(shí)。
而且我認(rèn)為,它們也有相對(duì)大而完美的工作記憶。
因此,任何適合上下文窗口的內(nèi)容都可以通過其內(nèi)部自注意機(jī)制立即供Transformer使用,它有點(diǎn)像完美的記憶。它的大小是有限的,但Transformer可以非常直接地訪問它,它可以無損地記住其上下文窗口內(nèi)的任何內(nèi)容。
這就是我比較這兩者的方式。
我之提出所有這些,是因?yàn)槲艺J(rèn)為在很大程度上,提示只是彌補(bǔ)了這兩種架構(gòu)之間的這種認(rèn)知差異。就像我們?nèi)祟惔竽X和 LLM 大腦(的比較),你可以這么看。
人們發(fā)現(xiàn)有一件事,在實(shí)踐中效果很好。

特別是如果您的任務(wù)需要推理,您不能指望Transformer對(duì)每個(gè)標(biāo)記進(jìn)行太多推理,因此您必須真正將推理分散到越來越多的標(biāo)記上。
例如,您不能向Transformer提出一個(gè)非常復(fù)雜的問題并期望它在一個(gè)標(biāo)記中得到答案。(用于計(jì)算的)時(shí)間不夠。
這些Transformer需要標(biāo)記來思考,我有時(shí)喜歡這樣說。
這是一些實(shí)踐中運(yùn)作良好的事情:
例如,您可能有一個(gè)few-shot prompt提示,向Transformer顯示它在回答問題時(shí)應(yīng)該展示其工作,如果您給出幾個(gè)示例,Transformer將模仿該模板,然后它就會(huì)在評(píng)估方面做得更好。
此外,您可以通過說“l(fā)et‘s think step by step”從Transformer中引發(fā)這種行為,因?yàn)檫@使Transformer變得有點(diǎn)像展示它的工作。
而且,因?yàn)樗悬c(diǎn)進(jìn)入一種顯示其工作的模式,它會(huì)為每個(gè)標(biāo)記做更少的計(jì)算工作,因此它更有可能成功,因?yàn)殡S著時(shí)間的推移,它的推理速度會(huì)變慢。
這是另一個(gè)例子。這稱為自我一致性。
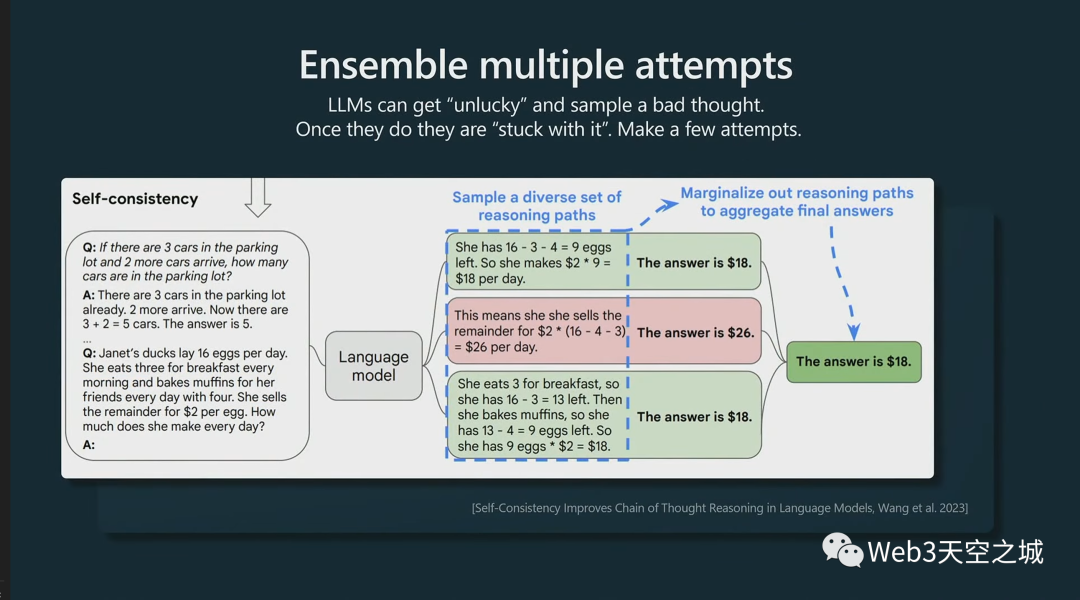
我們看到我們有能力開始寫,然后如果沒有成功,我可以再試一次,我可以多次嘗試,也許會(huì)選擇一個(gè)最好的。
因此,在這些類型的實(shí)踐中,您可能不僅會(huì)抽樣一次,還會(huì)抽樣多次,然后有一些過程來找到好的樣本,只保留這些樣本或者進(jìn)行多數(shù)表決,類似這樣的事情。
而在這個(gè)過程中,這些 Transformer 在預(yù)測(cè)下一個(gè)標(biāo)記時(shí),就像你一樣,它們可能會(huì)倒霉,它們可能會(huì)采樣到一個(gè)不太好的標(biāo)記,它們可能會(huì)在推理方面像死胡同一樣走下坡路。
因此,與您不同,它們無法從中恢復(fù)過來。
它們被它們采樣的每一個(gè)標(biāo)記所困,所以它們會(huì)繼續(xù)這個(gè)序列,即使它們知道這個(gè)序列不會(huì)成功。
讓它們有某種能力能夠回顧、檢查或嘗試。。基本上圍繞它進(jìn)行抽樣,這也是一種技術(shù)。
事實(shí)證明,實(shí)際上LLM像是知道什么時(shí)候搞砸了一樣。
例如,假設(shè)您要求模型生成一首不押韻的詩(shī):
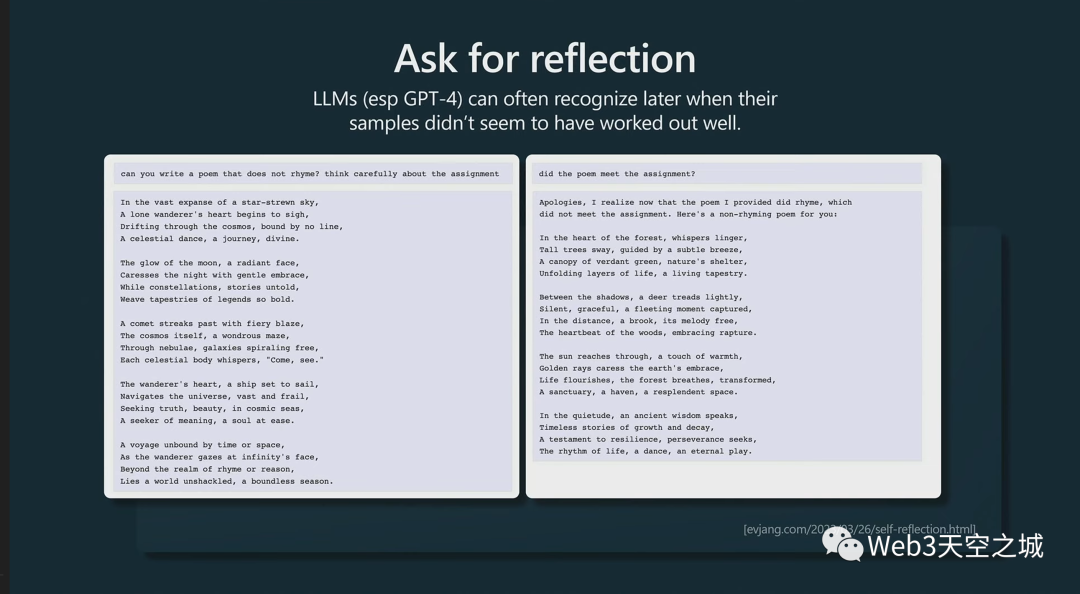
它可能會(huì)給你一首詩(shī),但它實(shí)際上是押韻的。
事實(shí)證明,特別是對(duì)于更大的模型,比如 GPT-4,你可以問它,“你完成任務(wù)了嗎?”
實(shí)際上,GPT-4 很清楚自己沒有完成任務(wù)。它只是在采樣方面有點(diǎn)不走運(yùn)。它會(huì)告訴你,“不,我沒有完成任務(wù)。讓我再嘗試一次。”
但是如果你不提示它,它甚至不會(huì)——就像它不知道要重新訪問等等,你必須在你的提示中彌補(bǔ)這一點(diǎn)。
你必須推動(dòng)它來檢查。如果你不要求它檢查,它不會(huì)自己檢查。它只是一個(gè)標(biāo)記模擬器。
我認(rèn)為更一般地說,很多這些技術(shù)都屬于我所說的重建我們?nèi)祟惖南到y(tǒng)二的范圍。
你可能熟悉人類思考的系統(tǒng)一和系統(tǒng)二模式。
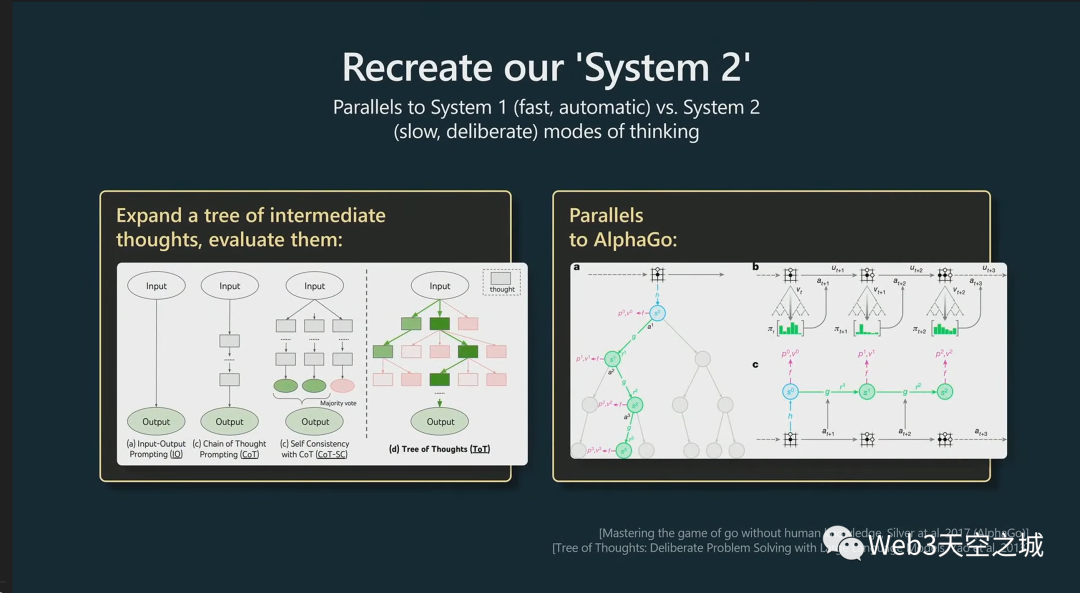
系統(tǒng)一是一個(gè)快速的自動(dòng)過程,我認(rèn)為有點(diǎn)對(duì)應(yīng)于 LLM,只是對(duì)標(biāo)記進(jìn)行抽樣。
系統(tǒng)二是大腦中較慢的、經(jīng)過深思熟慮的計(jì)劃部分。
這實(shí)際上是上周的一篇論文,這個(gè)領(lǐng)域正在迅速發(fā)展。它被稱為思想樹(Tree of Thought)。
在思想樹中,這篇論文的作者建議為任何給定的提示維護(hù)多個(gè)完成,然后也會(huì)在整個(gè)過程中對(duì)它們進(jìn)行評(píng)分,并保留那些進(jìn)展順利的。大家看看這是否有意義。
很多人真的在把玩一些prompt工程,基本上是希望讓LLM恢復(fù)一些我們大腦中具有的能力。
我想在這里指出的一件事是,這不僅僅是一個(gè)提示。這實(shí)際上是與一些 Python 膠水代碼一起使用的提示,因?yàn)槟銓?shí)際上要維護(hù)多個(gè)提示,你還必須在這里做一些樹搜索算法來找出擴(kuò)展哪個(gè)提示等等。
因此,它是 Python 膠水代碼和在 while 循環(huán)或更大算法中調(diào)用的各個(gè)提示的共生體。
我還認(rèn)為這里與 AlphaGo 有一個(gè)非常酷的相似之處。
AlphaGo下圍棋有一個(gè)放下一塊棋子的策略,這個(gè)策略本來就是模仿人訓(xùn)練出來的。
但是除了這個(gè)策略之外,它還會(huì)做蒙特卡洛搜索,它會(huì)在圍棋中打出多種可能性并評(píng)估所有這些,只保留那些運(yùn)作良好的。
我認(rèn)為這有點(diǎn)類似于AlphaGo,但是針對(duì)于文本。
就像思想樹一樣,我認(rèn)為更普遍的是,人們開始真正探索更通用的技術(shù),不僅僅是簡(jiǎn)單的問答提示,而是看起來更像是將許多提示串在一起的 Python 膠水代碼。

在右邊,我有一個(gè)來自這篇論文的例子,叫做 React,他們將提示的答案構(gòu)造為一系列思考、行動(dòng)、觀察、思考、行動(dòng)、觀察,這是一個(gè)完整的展開,一種思考 回答查詢的過程。在這些動(dòng)作中,模型也被允許使用工具。
在左邊,我有一個(gè)AutoGPT 的例子。
順便說一句,AutoGPT 是一個(gè)我認(rèn)為最近炒得沸沸揚(yáng)揚(yáng)的項(xiàng)目,但我仍然覺得它有點(diǎn)鼓舞人心。它是一個(gè)允許 LLM 保留任務(wù)列表并繼續(xù)遞歸分解任務(wù)的項(xiàng)目,我認(rèn)為目前效果不是很好,不建議人們?cè)趯?shí)際應(yīng)用中使用它。
但我認(rèn)為,隨著時(shí)間的推移,這是可以從中汲取靈感的東西。AutoGPT有點(diǎn)像讓我們的模型系統(tǒng)思考。
接下來一件事,我覺得有點(diǎn)意思的是 ,LLM 有種不想成功的心理怪癖。
它們只是想模仿。如果你想成功,你應(yīng)該要求它。

我的意思是,當(dāng) Transformer 被訓(xùn)練時(shí),它們有訓(xùn)練集,并且它們的訓(xùn)練數(shù)據(jù)中可以有一個(gè)完整的性能質(zhì)量范圍。
例如,可能有一些物理問題或類似問題的提示,可能有一個(gè)學(xué)生的解決方案完全錯(cuò)誤,但也可能有一個(gè)非常正確的專家答案。
Transformer無法區(qū)分它們之間的區(qū)別——它們知道低質(zhì)量解決方案和高質(zhì)量解決方案,但默認(rèn)情況下,它們想要模仿所有這些,因?yàn)樗鼈冎皇墙邮苓^語言建模方面的訓(xùn)練。
在測(cè)試的時(shí)候,你必須要求一個(gè)好的表現(xiàn)。
上面論文中的這個(gè)例子,他們嘗試了各種提示,“l(fā)et’s think step by step”非常強(qiáng)大,因?yàn)樗淹评矸稚⒌皆S多標(biāo)記上
但更好的提示方法是:“讓我們一步一步地解決這個(gè)問題 確定我們有正確的答案”。
這就像獲得正確答案的條件一樣,這實(shí)際上使Transformer工作得更好,因?yàn)門ransformer現(xiàn)在不必在低質(zhì)量解決方案上對(duì)沖其概率質(zhì)量,盡管這聽起來很荒謬。。。
基本上,請(qǐng)隨意尋求一個(gè)強(qiáng)有力的解決方案,說出您是該主題的領(lǐng)先專家之類的話,假裝你有 IQ 120,等等。
不要試圖要求太多的智商,因?yàn)槿绻阋?400 的智商,你可能會(huì)在數(shù)據(jù)分布之外;或者更糟糕的是,你可能會(huì)在一些科幻的數(shù)據(jù)分布中,它會(huì)開始 進(jìn)行一些科幻角色扮演,或類似的事情。
我認(rèn)為你必須找到合適的智商設(shè)定。那里有一些U形曲線。
接下來,正如我們所看到的,當(dāng)我們?cè)噲D解決問題時(shí),我們知道自己擅長(zhǎng)什么,不擅長(zhǎng)什么,并且我們?cè)谟?jì)算上依賴工具。
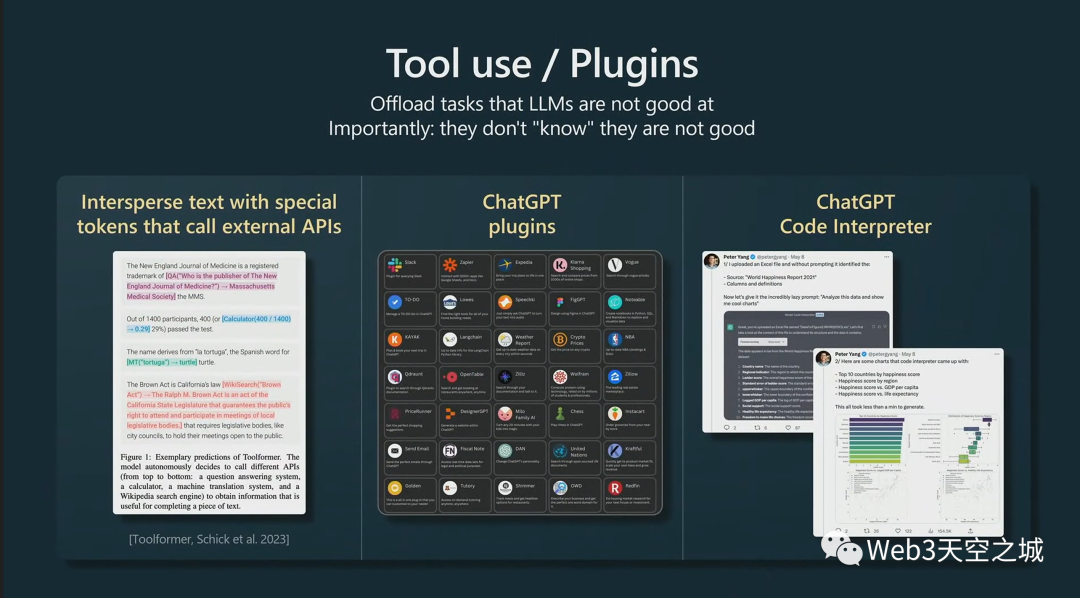
你想對(duì)你的LLM做同樣的事情。特別是,我們可能希望為它們提供計(jì)算器、代碼解釋器等,以及進(jìn)行搜索的能力,并且有很多技術(shù)可以做到這一點(diǎn)。
再次要記住的一件事是,默認(rèn)情況下這些Transformer可能不知道它們不知道的事情,你甚至可能想在提示中告訴Transformer,“你的心算不太好。每當(dāng)您需要進(jìn)行大數(shù)加法、乘法或其他操作時(shí),請(qǐng)使用此計(jì)算器。以下是您如何使用計(jì)算器。使用這個(gè)標(biāo)記組合,等等,等等。”
你必須把它拼出來,因?yàn)槟J(rèn)情況下模型不知道它擅長(zhǎng)什么或不擅長(zhǎng)什么,就像你和我一樣。
接下來,我認(rèn)為一件非常有趣的事情是,我們從一個(gè)只有檢索的世界走到鐘擺擺動(dòng)的另一個(gè)極端,那里只有LLM的記憶
但實(shí)際上,在這兩者之間有檢索增強(qiáng)模型的整個(gè)空間,這在實(shí)踐中非常有效。
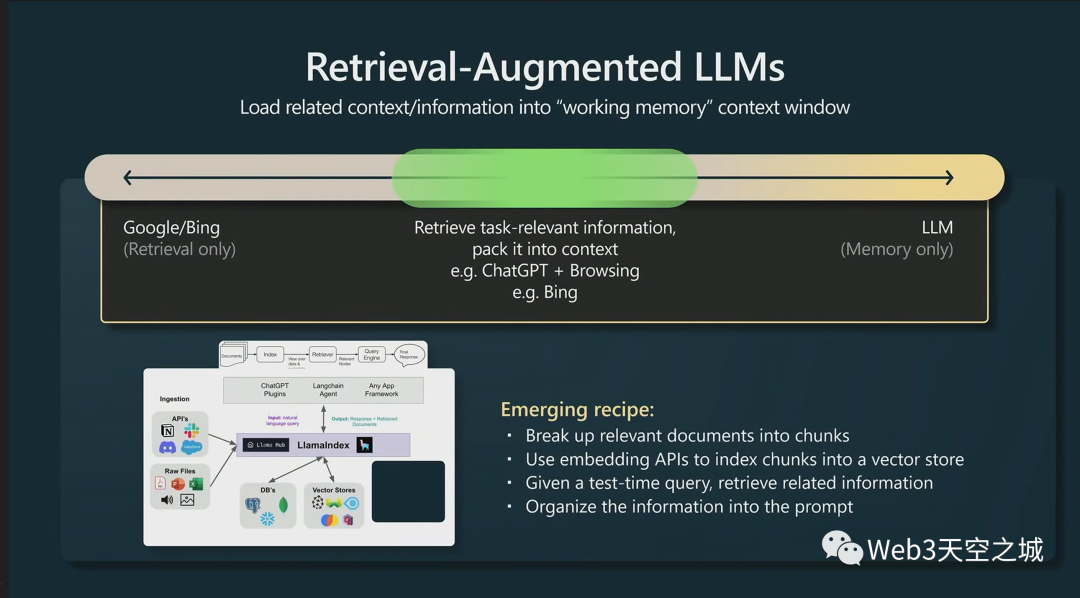
正如我所提到的,Transformer的上下文窗口是它的工作內(nèi)存。如果您可以將與任務(wù)相關(guān)的任何信息加載到工作內(nèi)存中,那么該模型將運(yùn)行得非常好,因?yàn)樗梢粤⒓丛L問所有內(nèi)存。
我認(rèn)為很多人對(duì)基本上檢索增強(qiáng)生成非常感興趣,在上圖底部,我有一個(gè)Llama索引的例子,它是許多不同類型數(shù)據(jù)的一個(gè)數(shù)據(jù)連接器,你可以索引所有這些數(shù)據(jù),讓 LLM 訪問它。
新興的秘訣是獲取相關(guān)文檔,將它們分成塊,將它們?nèi)壳度耄玫奖硎驹摂?shù)據(jù)的嵌入向量,將其存儲(chǔ)在向量存儲(chǔ)中;然后在測(cè)試時(shí),對(duì)矢量存儲(chǔ)進(jìn)行某種查詢,獲取可能與您的任務(wù)相關(guān)的塊,然后將它們填充到提示中,然后生成。這在實(shí)踐中可以很好地工作。
這類似于你我解決問題的時(shí)候,你可以憑記憶做任何事情,Transformer的記憶力非常大,但它有助于參考一些主要文件。
無論何時(shí),您發(fā)現(xiàn)自己要回到教科書上找東西,或者每當(dāng)您發(fā)現(xiàn)自己要回到圖書館的文檔中查找東西時(shí),Transformer肯定也想這樣做。您對(duì)庫(kù)的某些文檔如何工作有一定的記憶,但最好查找一下。同樣的事情也適用于LLM。
接下來,我想簡(jiǎn)單說一下約束提示。我也覺得這很有趣。
這是在 LLM 的輸出中強(qiáng)制使用特定模板的技術(shù),實(shí)際上這是 Microsoft 的一個(gè)示例。
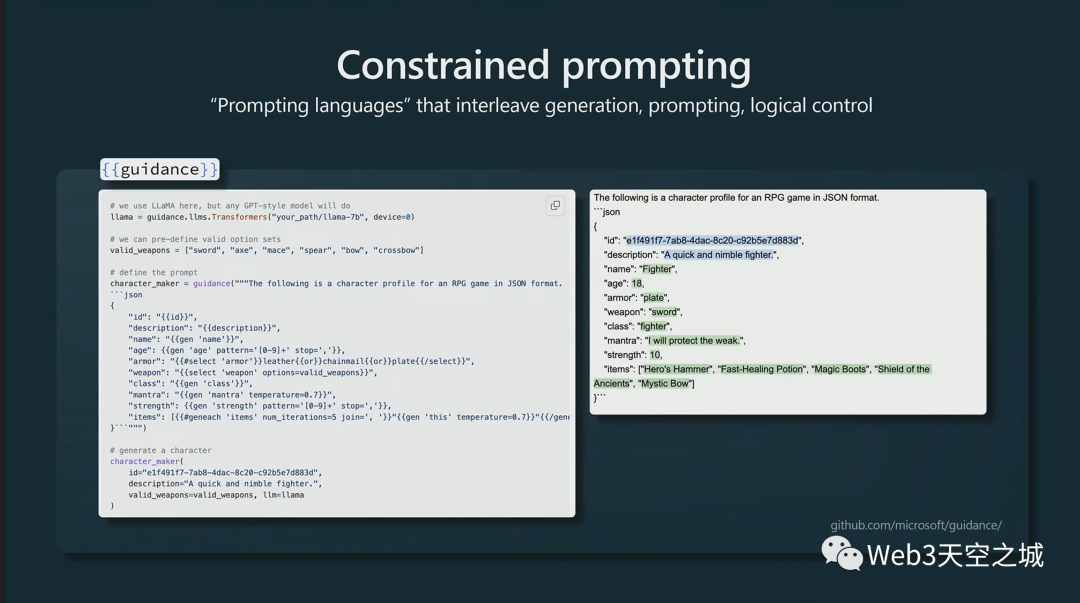
在這里,我們強(qiáng)制 LLM 的輸出將是 JSON,這實(shí)際上將保證輸出將采用這種形式,因?yàn)樗鼈冞M(jìn)入并擾亂了來自Transformer的所有不同標(biāo)記的概率,并且固定住這些標(biāo)記。
然后Transformer只填充此處的空白,然后可以對(duì)可能進(jìn)入這些空白的內(nèi)容實(shí)施額外的限制。這可能真的很有幫助,我認(rèn)為這種約束抽樣也非常有趣。
我還想說幾句微調(diào)。
您可以通過快速prompt工程取得很大進(jìn)展,但也可以考慮微調(diào)您的模型。
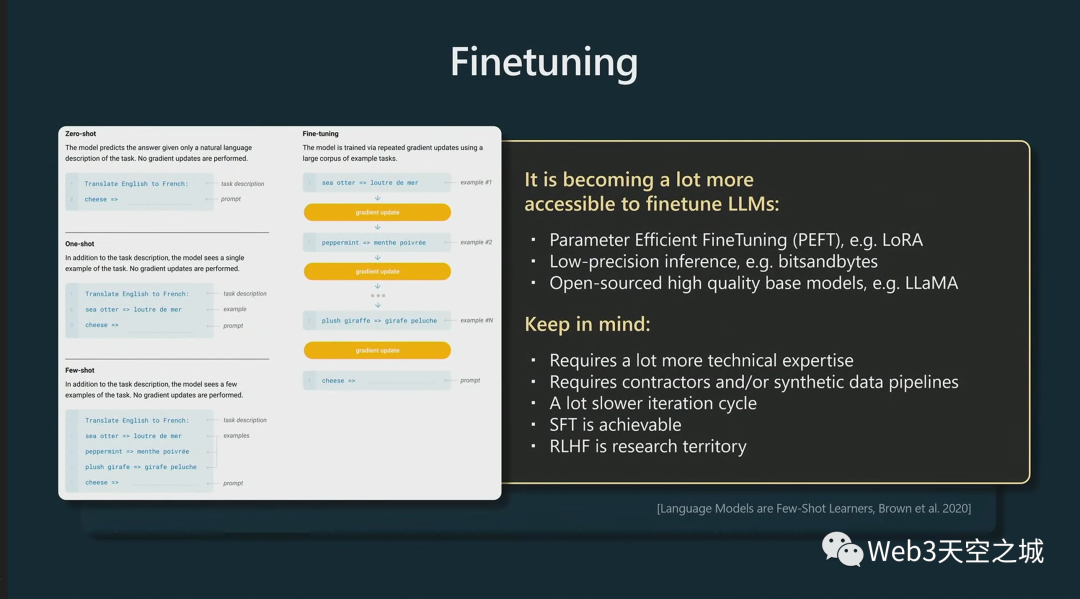
微調(diào)模型意味著你實(shí)際上要改變模型的權(quán)重。現(xiàn)在在實(shí)踐中做到這一點(diǎn)變得越來越容易,這是因?yàn)樽罱_發(fā)了許多技術(shù)并擁有庫(kù)調(diào)用。
例如,像 Lora 這樣的參數(shù)高效微調(diào)技術(shù)可確保您只訓(xùn)練模型的小而稀疏的部分。因此大部分模型都保持在基礎(chǔ)模型上,并且允許更改其中的一些部分, 這在經(jīng)驗(yàn)上仍然很有效,并且使得僅調(diào)整模型的一小部分成本更低。
這也意味著,因?yàn)槟愕拇蟛糠帜P投际枪潭ǖ模憧梢允褂梅浅5偷木韧评韥碛?jì)算這些部分,因?yàn)樗鼈儾粫?huì)被梯度下降更新,這也使得一切都更加高效。
此外,我們還有許多開源的高質(zhì)量基礎(chǔ)模型。目前,正如我提到的,我認(rèn)為 Llama 相當(dāng)不錯(cuò),盡管我認(rèn)為它現(xiàn)在還沒有獲得商業(yè)許可。
需要記住的是,微調(diào)在技術(shù)上涉及更多,它需要更多的技術(shù)專長(zhǎng)才能做對(duì)。它需要數(shù)據(jù)集和/或可能非常復(fù)雜的合成數(shù)據(jù)流程的人工數(shù)據(jù)承包商。這肯定會(huì)大大減慢你的迭代周期。
我想在較高的層次上說,SFT 是可以實(shí)現(xiàn)的,因?yàn)槟阒皇窃诶^續(xù)語言建模任務(wù)。它相對(duì)簡(jiǎn)單;但 RLHF 是一個(gè)非常多的研究領(lǐng)域,而且它更難開始工作。
我可能不建議有人嘗試推出他們自己的 RLHF 實(shí)現(xiàn)。這些東西非常不穩(wěn)定,很難訓(xùn)練,現(xiàn)在對(duì)初學(xué)者來說不是很友好,而且它也有可能變化得非常快。
我認(rèn)為以下這些是我現(xiàn)在的默認(rèn)建議。

我會(huì)把你的任務(wù)分成兩個(gè)主要部分。
第一,實(shí)現(xiàn)你的最佳表現(xiàn),第二,按照這個(gè)順序優(yōu)化你的費(fèi)用。
首先,目前最好的性能來自 GPT4 模型。它是迄今為止功能最強(qiáng)大的模型。
然后, 讓提示里包含詳細(xì)的任務(wù)內(nèi)容、相關(guān)信息和說明。想想如果它們不能給你回郵件你會(huì)告訴它們什么。要記住任務(wù)承包商是人,他們有內(nèi)心獨(dú)白,他們非常聰明;而LLM不具備這些品質(zhì)。因此,請(qǐng)務(wù)必仔細(xì)考慮LLM的心理,并迎合這一點(diǎn)。甚至向這些提示添加任何相關(guān)的上下文和信息。
多參考很多提示工程技術(shù)。我在上面的幻燈片中突出顯示了其中一些,但這是一個(gè)非常大的空間,我只建議您在線尋找快速的Prompt工程技術(shù)。那里有很多內(nèi)容。
嘗試使用少樣本few-shots示例提示。這指的是你不只是想問,你還想盡可能地展示(你想要的),給它舉例子,如果可以的話,幫助它真正理解你的意思。
嘗試使用工具和插件來分擔(dān) LLM 本身難以完成的任務(wù)。
然后不僅要考慮單個(gè)提示和答案,還要考慮潛在的鏈條和反射,以及如何將它們粘合在一起,以及如何制作多個(gè)樣本等。
最后,如果你認(rèn)為你已經(jīng)最大化了提示工程的效果,我認(rèn)為你應(yīng)該堅(jiān)持一段時(shí)間,看看一些可能對(duì)你的應(yīng)用程序的模型微調(diào),但預(yù)計(jì)這會(huì)更慢并且涉及更多。
然后這里有一個(gè)脆弱的專家研究區(qū),我想說的是 RLHF,如果你能讓它工作的話。它目前確實(shí)比 SFT 好一點(diǎn),但是,我想說的是,這非常復(fù)雜。
為了優(yōu)化您的成本,請(qǐng)嘗試探索容量較低的模型或更短的提示等。
我還想談?wù)勎艺J(rèn)為 LLM 目前非常適合的用例。
特別要注意的是,今天的 LLM 有很多限制,我會(huì)在所有應(yīng)用中牢記這一點(diǎn)。

模型,順便說一句,這可能是一個(gè)完整的演講,我沒有時(shí)間詳細(xì)介紹它。
模型可能有偏見,它們可能捏造、產(chǎn)生幻覺信息,它們可能有推理錯(cuò)誤,它們可能在整個(gè)類別的應(yīng)用程序中都掙扎,它們有知識(shí)截止日期,比如說,2021 年 9 月。Twitter 每天都在發(fā)生大量對(duì)LLM的攻擊,包括即時(shí)注入、越獄攻擊、數(shù)據(jù)中毒攻擊等。
我現(xiàn)在的建議是在低風(fēng)險(xiǎn)應(yīng)用程序中使用 LLM,將它們與始終與人工監(jiān)督結(jié)合起來,將它們用作靈感和建議的來源,并考慮副駕駛而不是在某處執(zhí)行任務(wù)的完全自主的代理。目前尚不清楚這些模型是否合適。
最后我想說,GPT-4 是一個(gè)了不起的人工制品,我非常感謝它的存在。
它很漂亮,它在很多領(lǐng)域都有大量的知識(shí),它可以做數(shù)學(xué)、代碼等等。此外,還有一個(gè)蓬勃發(fā)展的生態(tài)系統(tǒng),包括正在構(gòu)建并納入生態(tài)系統(tǒng)的其他所有事物,其中一些我已經(jīng)談到了。
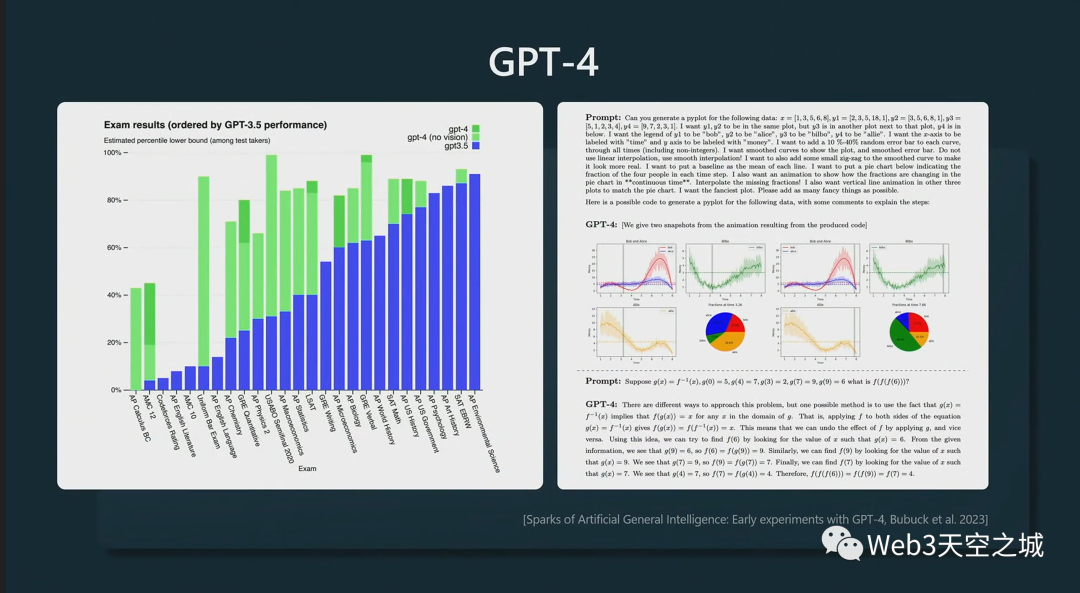
所有這些功能都觸手可及。
我和GPT-4說,“你能說些什么來激勵(lì) Microsoft Build 2023 的觀眾嗎?”
我將其輸入 Python 并逐字記錄,GPT-4 說了以下內(nèi)容。
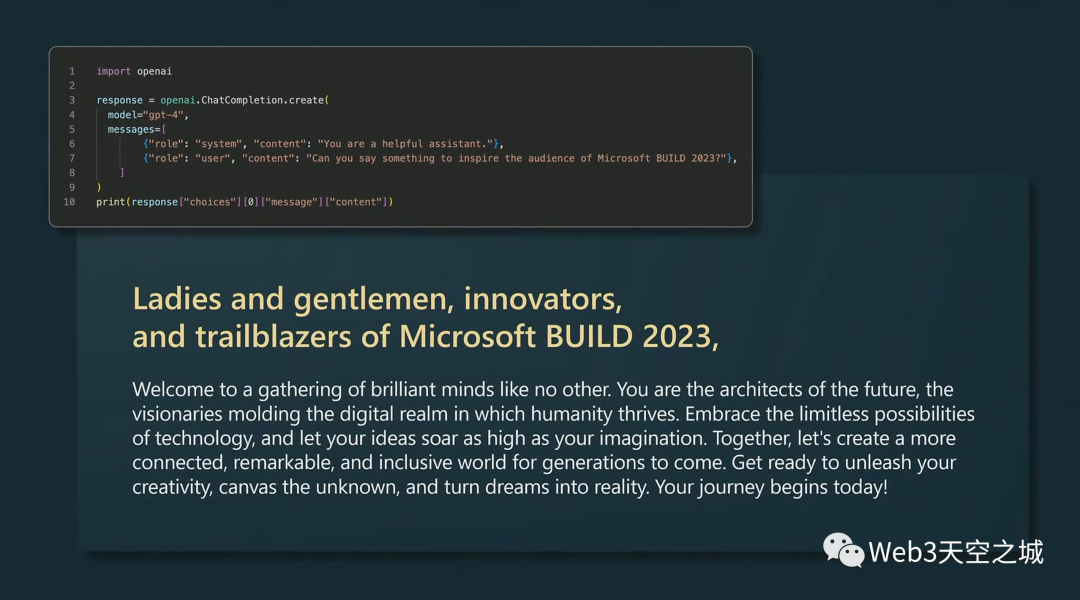
順便說一句,我不知道它們?cè)谥黝}演講中使用了這個(gè)技巧,我以為我很聰明,但它真的很擅長(zhǎng)這個(gè)。
它說:
“女士們,先生們,微軟 Build 2023 的創(chuàng)新者和開拓者,歡迎來到與眾不同的聰明才智的聚會(huì)。
你們是未來的建筑師,是塑造人類蓬勃發(fā)展的數(shù)字領(lǐng)域的遠(yuǎn)見者。
擁抱技術(shù)的無限可能性,讓您的想法像您的想象一樣飛翔。
讓我們一起為子孫后代創(chuàng)造一個(gè)聯(lián)系更緊密、更卓越、更具包容性的世界。
準(zhǔn)備好釋放您的創(chuàng)造力,探索未知,將夢(mèng)想變?yōu)楝F(xiàn)實(shí)。
你的旅程從今天開始。”。
謝謝!
審核編輯 :李倩
-
生態(tài)系統(tǒng)
+關(guān)注
關(guān)注
0文章
701瀏覽量
20709 -
OpenAI
+關(guān)注
關(guān)注
9文章
1043瀏覽量
6407
原文標(biāo)題:State of GPT:大神Andrej揭秘OpenAI大模型原理和訓(xùn)練過程
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
OpenAI宣布啟動(dòng)GPT Next計(jì)劃
BP神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)和訓(xùn)練過程
解讀PyTorch模型訓(xùn)練過程
深度學(xué)習(xí)的典型模型和訓(xùn)練過程
CNN模型的基本原理、結(jié)構(gòu)、訓(xùn)練過程及應(yīng)用領(lǐng)域
使用PyTorch搭建Transformer模型
OpenAI揭秘CriticGPT:GPT自進(jìn)化新篇章,RLHF助力突破人類能力邊界
深度學(xué)習(xí)模型訓(xùn)練過程詳解
OpenAI發(fā)布全新GPT-4o模型
OpenAI推出面向所有用戶的AI模型GPT-4o
OpenAI有望在年中推出全新GPT-5模型
OpenAI預(yù)計(jì)最快今年夏天發(fā)布GPT-5
OpenAI迎戰(zhàn)紐約時(shí)報(bào)指控 非法使用其內(nèi)容訓(xùn)練人工智能模型
OpenAI推出GPT商店
OpenAI GPT 商店即將亮相,SpaceX 新型 Starlink 衛(wèi)星發(fā)射上天






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論