 【核芯觀察】ChatGPT背后的算力芯片(三)
【核芯觀察】ChatGPT背后的算力芯片(三)
【核芯觀察】是電子發燒友編輯部出品的深度系列專欄,目的是用最直觀的方式令讀者盡快理解電子產業架構,理清上、中、下游的各個環節,同時迅速了解各大細分環節中的行業現狀。以ChatGPT為首的AI大模型在今年以來可以說是最熱的賽道,而AI大模型對算力的需求爆發,也帶動了AI服務器中各種類型的芯片需求,所以本期核芯觀察將關注ChatGPT背后所用到的算力芯片產業鏈,梳理目前主流類型的AI算力芯片產業上下游企業以及運作模式。
接上期ChatGPT背后的算力芯片(二)
AI服務器中的主要算力芯片之FPGA
市場現狀
FPGA的最大特點就是,在芯片被設計、制造完成之后,用戶依然可以通過修改其邏輯單元和開關陣列編程,來進行功能配置,實現所需要的功能。在AI算法快速迭代的過程中,用戶可以通過持續優化FPGA的功能配置,來提高運算效率。這也是FPGA與CPU、GPU、ASIC等芯片最大的不同。
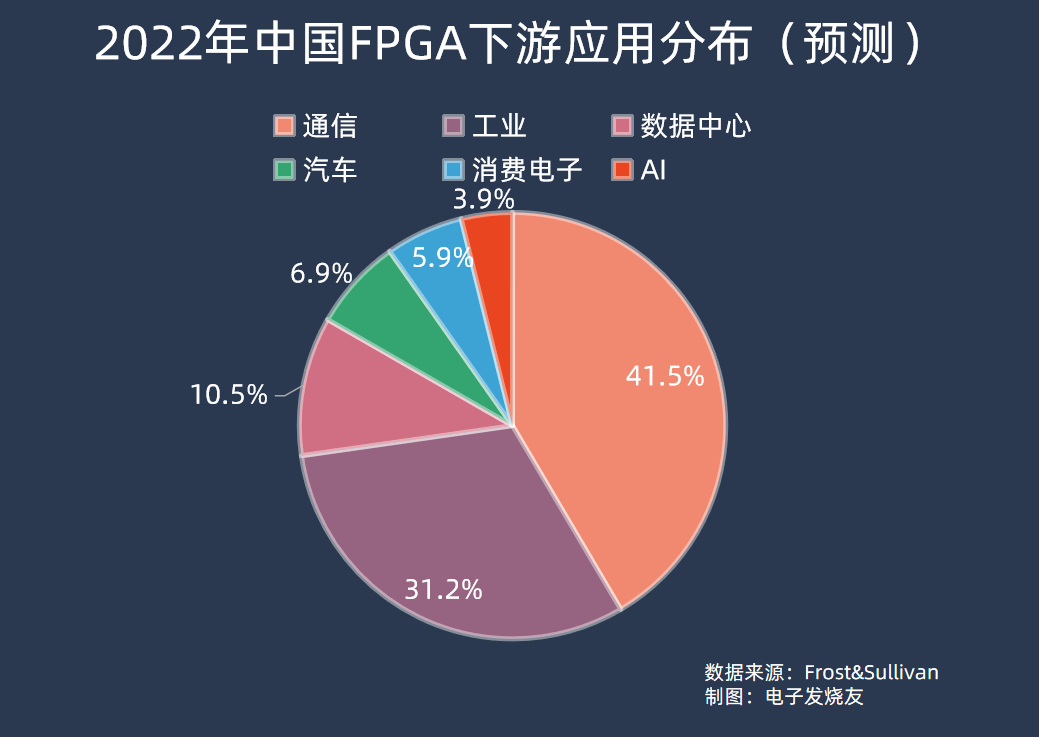
所以最初FPGA被大量用于通信領域,可以靈活更改高速通信協議的處理方式,適配不同場景。根據Frost&Sullivan的預測數據,2022年中國FPGA下游應用中,通信占比最高為41.52%,工業應用其次,占比31.23%。數據中心、汽車、消費電子、AI分別占比10.54%、6.94%、5.89%、3.88%。
從全球市場來看,根據Frost&Sullivan數據,估算2021年全球FPGA市場規模為68.6億美元,2022年預計為79.4億美元,同比增長15.7%;到2025年市場規模將增長至125.8億美元,2021年到2025年年均復合增長率約16.4%。
中國市場上,2021年FPGA市場規模為176.8億元,到2025年 FPGA芯片銷售額將達到332.2億元,2021至2025年年均復合增長率將達到17.1%。出貨量方面,中國市場FPGA芯片出貨量在2020年約為1.6億顆,預計到2025年將達到3.3億顆,2021至2025年年均復合增長率將達到15.0%。
其中數據中心、AI領域市場增長迅速,FPGA能夠使數據中心的不同器件更加有效地協同,最大程度發揮每個器件的硬件優勢避免數據轉換導致的算力空耗;在運算加速領域,FPGA 在矩陣運算、圖像處理、機器學習、非對稱加密、搜索排序等領域有著很廣闊的應用前景。
在中國數據中心細分市場,Frost&Sullivan預計該市場規模在2021年為18.7億元,到2025年會達到34.6億元,其間年均復合增長率將為16.6%。
不過自去年年底以來,由OpenAI掀起的AI熱潮,有望推動FPGA市場以遠超出此前預期的速度增長。
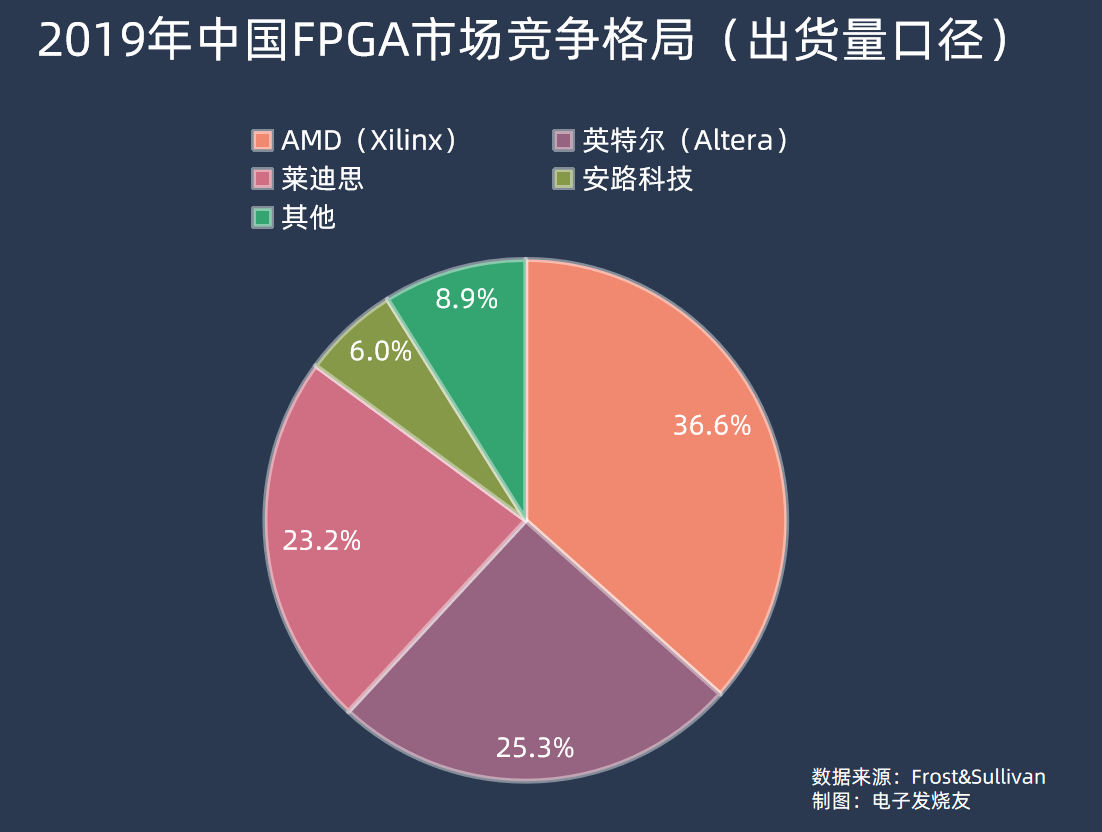
近年沒有新的FPGA市場份額數據,按照Frost&Sullivan 2019年的數據,中國市場上AMD(賽靈思)、英特爾(Altera)兩家占到FPGA市場銷售額的九成以上,分別為55.1%和36%。而按照FPGA出貨量來看,同期AMD占36.6%、英特爾占25.3%、萊迪思占23.2%、安路科技占6%。
FPGA的核心參數是邏輯單元容量,按照邏輯單元容量來分,2019年中國FPGA市場中需求量最大的是100K以下和100K—500K邏輯單元容量的FPGA,份額分別占市場的38.2%和31.7%,更高端的500K-1KK以及1KK以上邏輯單元容量的FPGA則分別占24.4%和5.7%的份額。
全球范圍來看,FPGA市場目前由AMD和英特爾雙寡頭壟斷,占整個市場份額近90%,第二梯隊的海外廠商有萊迪思、Microsemi等,各占5%左右。國內FPGA廠商主要有復旦微電子、紫光國微(紫光同創)、安路科技、高云半導體、華微電子、智多晶、京微齊力等等,不過從邏輯單元容量來看,國內廠商主要集中在500K以下,更多產品線的邏輯單元容量在200K以下,中低端市場布局較為完善,但中高端領域目前國產FPGA仍未有大規模涉足。
復旦微電子在2018年推出了億門級FPGA系列,邏輯單元容量可達700K,據了解,其新一代十億門級的大容量FPGA有望在2023年內推出。而2019年英特爾推出的 Stratix 10 GX 10M FPGA邏輯單元已經高達10KK,相比之下國產FPGA在高端市場目前缺口還是較大的,但目前重要的是在中低端市場站穩,奪得更多的國內市場份額。
AI服務器FPGA的趨勢
衡量FPGA的容量,有兩個階段,在2000年以前,FPGA廠商用門級數量規模來衡量FPGA的容量,因為ASIC的最小功能單元是“門”,而本質上FPGA與ASIC都可以同樣功能,甚至在ASIC設計過程中都會使用到FPGA進行驗證,所以“門”可以間接體現FPGA的容量。
后來2000年后,FPGA廠商逐漸開始轉用統一的邏輯單元來表示FPGA容量,這主要是由于FPGA性能需求的升級,芯片內部的LUT結構和集成度不斷改變,用門級數來表示FPGA容量越來越難。
在AI服務器中,FPGA往往起到加速計算的作用,FPGA的特性可以令其在深度學習中異構計算、并行計算方面有一定優勢,且其具備低延時的特性,在AI服務器中FPGA還可以實現數據高速收發、交換等功能。同時,相比于CPU和GPU,FPGA單位能耗比還更低,特別在深度學習領域,近年來微軟、百度、亞馬遜等已經在數據中心大規模部署FPGA。
有數據顯示,在保持相同神經網絡模型計算結果的同時,FPGA平臺的16位定點計算性能普遍是CPU的2到3倍,計算資源利用率更是CPU的接近20倍;與GPU相比,盡管計算性能沒有明顯領先,但功耗顯著降低,所以FPGA在AI服務器中用于計算加速是有明顯優勢的。
在AI服務器中,FPGA的一些重要指標包括邏輯單元數、DSP的數量、收發器的傳輸速率等。另一方面,FPGA的制程工藝也是考量FPGA的一個重要標準,目前高端FPGA的制程基本是20nm以下,AMD目前最高端的產品線就采用臺積電16nm制程。
同時邏輯單元數大于700K,基本在1KK以上的水平;DSP的數量較多,比如超過10000的DSP;較高的Bloch RAM容量,比如1000Mb以上;收發器速率高于50GB/s,還集成CPU等的處理單元和PCIe 5等先進接口。
總而言之,高端的FPGA往往以SoC的形式呈現。而為了更加便于數據中心、AI服務器等應用的導入,FPGA廠商也提供了比如數據中心加速卡的解決方案,比如AMD Alveo系列。
AI服務器中的主要算力芯片之ASIC
市場現狀
近年來,TPU、NPU、VPU、DPU、BPU等各種名詞層出不窮,其實這些從廣義的概念看都屬于ASIC。
ASIC其實與前面提到的FPGA有密切的關系,在ASIC開發的過程中,往往要用到FPGA驗證。理論上一些芯片功能如果能用FPGA做出來,那么ASIC就同樣可以做到,本質上是用兩種不同的設計理念來讓芯片實現部分相同的功能。
當然,FPGA的靈活程度是ASIC不可比擬的,ASIC自設計之初就被限定了功能,無法像FPGA一樣在實際使用中還可以隨時重新配置芯片功能。
雖然ASIC的設計流程漫長,但ASIC相比FPGA由于進行了完整的定制,專為特定程序優化電路,在進行特定任務時性能會更加穩定,并且運行效率、能效比都會優于FPGA。
根據Bob Broderson數據,FPGA的能效比集中在1-10MOPS/mW之間。ASIC的能效比處于專用硬件水平,超過100MOPS/mW,是FPGA的10倍以上。
目前來看,在AI服務器場景中,ASIC主要用于推理服務器,針對已經訓練完成的模型來設計高效的運算硬件。但當前AI大模型領域正處于爆發初期,ASIC在AI服務器上的份額或許會呈現后發趨勢,在相關應用的AI模型成熟后,未來在云端推理方面將有較大的市場空間。正如地平線CEO余凱曾說的,“一旦軟件算法固定下來,專用集成電路ASIC一定是未來的方向”。
KBVResearch報告數據顯示,到2025年,全球ASIC芯片市場規模預計將達到247億美元,在2019到2025年間的復合年增長率為8.2%。
也正因為目前應用方面的一些難點,暫時來看,全球ASIC市場還未出現明顯的領先者,海內外廠商都在高速發展的過程中。
海外的主要玩家有谷歌、Habana(英特爾收購)等,谷歌目前已經推出了四代 TPU產品,TPU v5據稱即將在今年內面世;英特爾在2019年收購了Habana,隨后在2022年推出了Gaudi 2;云服務器巨頭亞馬遜也在持續布局開發ASIC,此前亞馬遜計劃在Alexa語音助手運算上采用ASIC,以降低對英偉達的依賴;微軟近幾年都有消息傳出,正在開發一款名為Athena的AI訓練專用ASIC,據稱還將采用臺積電5nm制程,不過還未有這款芯片的具體消息。
國內玩家有海思、寒武紀、燧原科技、百度、阿里等,其中海思、百度、阿里由于其公司業務場景對ASIC存在天然需求,因此選擇ASIC能降低其服務器建設成本。海思在2019年推出了昇騰910,百度也在同年推出了昆侖芯片、阿里也在2019年推出了含光800。
其中華為通過ASIC部署了端到端的完整生態,比如使用昇騰910時,需要搭配華為的大模型支持框架MindSpore和盤古大模型等;阿里則將含光800用于自家業務平臺的加速,比如為淘寶等平臺提供算力支持;百度的昆侖芯則主要在自身服務器、算力集群等應用,對政企客戶等提供算力。
以公開的算力數據來算,海思的昇騰910在BF16浮點算力為320Tflops,已經超越谷歌最新一代產品TPUv4的275Tflops,在INT8定點算力上同樣大幅領先。同時遂原科技和寒武紀的產品在整體性能上也與谷歌的TPUv4相差不遠,當然,由于應用上的區別,可能是設計上有不同傾向,比如TPUv4互聯帶寬較高,1000GB/s遠遠領先于遂原科技和寒武紀的產品。
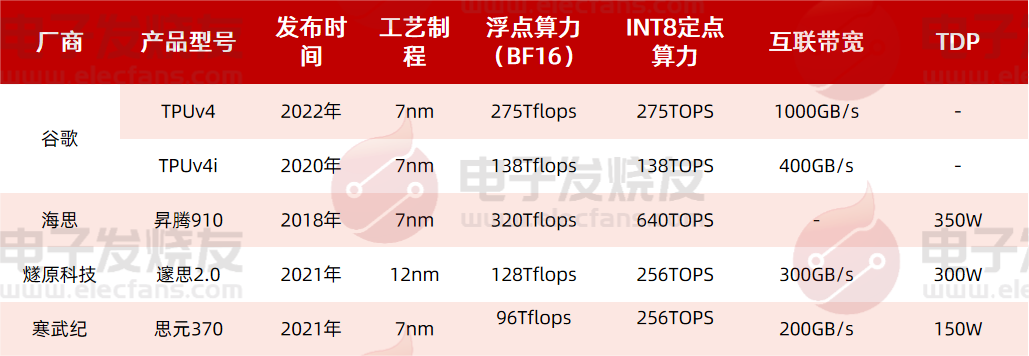
燧原科技在2021年推出了邃思2.0,采用12nm制程,單精度 FP32 算力為 40TFLOPS,單精度張量 TF32 算力為 160TFLOPS,整數精度 INT8 算力為 320TOPS,可用于云端AI訓練;同期寒武紀也推出了思元370芯片,采用7nm先進制程,算力最高可達 256TOPS (INT8),可靈活應用于云端推理、訓練等領域。
AI服務器上ASIC的發展趨勢
ASIC作為一種專用的集成電路,它的發展永遠是跟隨算法需求而定,這種表現在谷歌、百度、阿里、華為等云服務廠商中可能尤為明顯。
不過在2020年,英特爾發布了全新可定制解決方案,同時也將“結構化ASIC”的概念帶火。從上文我們也了解到,FPGA與ASIC關系密切,同時又各有優勢,英特爾提出的“結構化ASIC”,就是一種各項特性上介于FPGA和ASIC之間的芯片。
這種結構化ASIC在量產成本、邏輯門利用率、能耗、效能速度等表現上優于FPGA,但又不如純ASIC表現得優異,同時也具有FPGA的可編程化邏輯功效,以及加速芯片的研發設計速度與修改彈性,使芯片能更快完成并投入市場。
簡單來說,結構化ASIC是一種“半成品”的ASIC,它的性能和功耗接近標準單元ASIC,同時能夠節省一半的一次性工程費用和設計時間。但也有所損失,因為密度只有標準單元ASIC的50%到75%,所以結構化ASIC的成本會是標準單元ASIC的1.5-2倍。
按照英特爾的說法,采用結構化ASIC后,芯片編程不能像FPGA一樣可以在現場修改,而是需要在芯片工廠完成對芯片的編程。盡管成本仍然高達數十萬美元,但只需要幾個月時間就可以完成,傳統ASIC則至少需要兩年。
所以目前ASIC的一個最大痛點是,設計時間和資源消耗,這在如今快速迭代的AI大模型和AI算法中,是難以成為主流的。而從結構化ASIC的發展來看,事實上這個概念并非英特爾首創,但過去由于半導體工藝制程的高速發展,使得制程帶來的性能紅利要遠遠大于ASIC的帶來的能效提升,因此結構化ASIC沒有受到市場重視。
而近年來摩爾定律逐漸放緩,芯片制程工藝也已經邁入一個較為穩定的階段,因此現階段ASIC應用的主要限制就在于設計周期和流片等工程費用投入。或許結構化ASIC能夠成為下一階段ASIC的一個重要發展方向,加速ASIC在AI服務器上的部署。
值得一提的是,電子發燒友網主辦的第七屆人工智能大會將在2023年8月23日正式召開,
在過去的三屆大會中,我們舉辦的“中國人工智能卓越創新獎”評選活動得到了業界的普遍認可和廣泛好評。2023年我們將繼續這一殊榮的評選,舉辦“2023第四屆中國人工智能卓越創新獎”評選活動,旨在發掘和表彰人工智能領域優秀人才、企業、技術以及產品。
“2023第四屆中國人工智能卓越創新獎”獎項提名于即日起到6月30日截至,提名詳情可掃描下方二維碼了解。

聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
FPGA
+關注
關注
1626文章
21678瀏覽量
602004 -
asic
+關注
關注
34文章
1195瀏覽量
120346 -
gpu
+關注
關注
28文章
4703瀏覽量
128723 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507
發布評論請先 登錄
相關推薦
AI算力芯片供電電源測試利器:費思低壓大電流系列電子負載
AI算力芯片作為驅動復雜計算任務的核心引擎,其性能與穩定性成為了決定應用成敗的關鍵因素。而在這背后,供電電源的穩定性和高效性則是保障AI算

名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
紙質媒體的高質量和專業網絡媒體的信息更新速度。
算力芯片在最近15年有著巨大性能突破,這些年Intel的CPU芯片從雙核128位SIMD到眾
發表于 09-02 10:09
淺析三大算力之異同
隨著一年多前ChatGPT的出現引爆人工智能(AI)浪潮,支撐大模型背后的“算力”概念突然闖進我們的視野,成為科技圈炙手可熱的新詞,引領著最新潮流。作為數字經濟時代新生產

從多核到眾核, 賽昉科技RISC-V+NoC IP子系統為算力芯片賦能
全球算力產業已然邁入新一輪的快速發展階段,RISC-V具備開源開放、模塊化等獨特優勢,使我國能夠獨立開發、部署滿足特定安全需求的算力芯片產品

揭秘芯片算力:為何它如此關鍵?
在數字化時代,芯片作為電子設備的核心組件,其性能直接關系到設備的運行速度和處理能力。而芯片的算力,即其計算能力,更是衡量芯片性能的重要指標。
算力系列基礎篇——算力101:從零開始了解算力
相信大家已經感受到,我們正處在一個人工智能時代。如果要問在人工智能時代最重要的是什么?那必須是:算力!算力!算

【核芯觀察】IMU慣性傳感器上下游產業梳理(二)
前言:【核芯觀察】是電子發燒友編輯部出品的深度系列專欄,目的是用最直觀的方式令讀者盡快理解電子產業架構,理清上、中、下游的各個環節,同時迅速了解各大細分環節中的行業現狀。本期【核


是德科技智能算力‘芯’技術研討會回顧
2023年12月20日,是德科技成功舉辦了智能算力‘芯’技術研討會。此次研討會由是德科技的行業市場經理周巍策劃并主持,研討會聚焦算力網絡,
ChatGPT算力芯片如何做算力輸出
算力卡的核心當然還是計算芯片,會搭配大容量高帶寬的內存、緩存,以及搭載CPU用于調度,為了幫助數據傳輸,便會使用高速通道,這便是PCIe(高速串行計算機擴展總線標準)在系統中的作用:提供總線通道。
發表于 01-11 10:01
?464次閱讀
芯科技,解密ChatGPT暢聊之算力芯片
的GPU服務器,尤其是英偉達的A100 GPU,提供了強大而精確的計算能力。ChatGPT的功能遠超日常對話,它能夠學習、理解并生成人類般的文本,是人工智能領域的一個重要突破。但其真正力量的源泉,是背后那些不斷工作的算
大算力芯片里的HBM,你了解多少?
最近,隨著人工智能行業的高速崛起,大算力芯片業成為半導體行業為數不多的熱門領域HBM(高寬帶內存:High-bandwidthmemory)作為大算
【12月20日|杭州】智能算力“芯”技術研討會
會議名稱: 是德科技智能算力“芯”技術研討會——杭州站 會議時間: 2023年12月20日 13:00—17:15 會議地點: 杭州明豪VOCO酒店 (杭州市濱江區江南大道558號) 三






 工商網監
工商網監
評論