 河套IT TALK90:(原創)智能算力新篇章:智算中心構建智能算力的大腦和神經中樞
河套IT TALK90:(原創)智能算力新篇章:智算中心構建智能算力的大腦和神經中樞

上篇我們聊到了人工智能算力(Computing Power),以及對應的那些算力芯片。如果我們把算力芯片理解為神經元的話,智算中心就是智慧大腦和神經中樞。今天智愿君就來聊聊智算中心。
1. 戰略性的選擇
智能算力水平是國家智能化、數字化發展水平的集中體現,是數字化應用建設及發展的底層基礎。《2021-2022全球計算力指數評估報告》數據顯示,美國、日本、德國、英國等15個國家在AI算力上的支出占總算力支出比重從2016年的9%增加到了12%,預計到2025年AI算力占比將達到25%。按照當前發展趨勢,在人均算力中智能算力所占的比重將會逐年增長,人均智能算力水平的高低與國家經濟社會發展將會是緊耦合的綁定關系,成為綜合國力發展的重要表現。
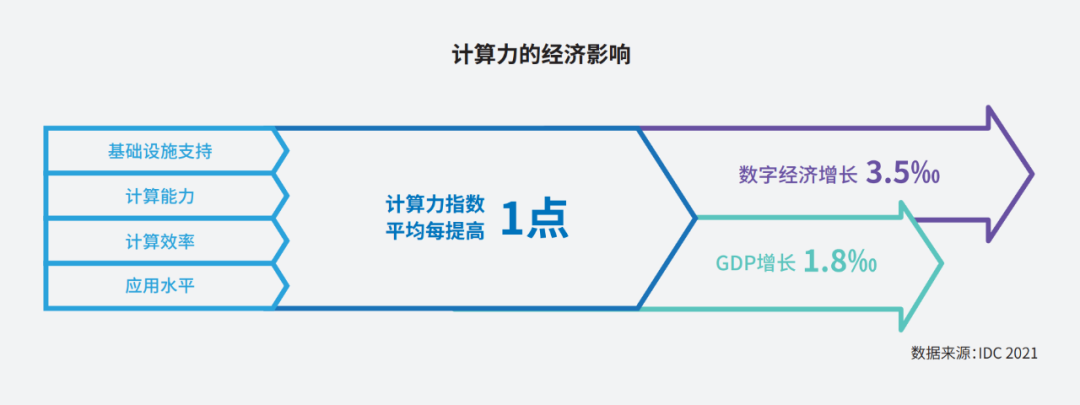
根據IDC聯合浪潮信息發布的《2022-2023中國人工智能計算力發展評估報告》,中國人工智能計算力保持快速增長,2022年智能算力規模達到268百億億次/秒(EFLOPS),超過通用算力規模。預計未來5年中國智能算力規模的年復合增長率將達52.3%。算力指數平均每提高1點,數字經濟和GDP將分別增長3.5‰和1.8‰。
毫無疑問,算力已成為挖掘數據要素價值,推動數字經濟發展的重要驅動力,智算中心的戰略性地位愈發凸顯。規模部署智算中心是迎接未來技術挑戰、加速城市智能化建設的必然選擇。
2. 智算中心的系統架構
上篇,我們其實已經談過了智算中心和超算中心、云計算中心的差異性,本篇不再贅述。
在國家信息中心發布的《智能計算中心創新發展指南》中,明確給出了智算中心的定義:“智算中心是基于最新人工智能理論,采用領先的人工智能計算架構,提供人工智能應用所需算力服務、數據服務和算法服務的公共算力新型基礎設施,通過算力的生產、聚合、調度和釋放,高效支撐數據開放共享、智能生態建設、產業創新聚集,有力促進AI產業化、產業AI化及政府治理智能化。智智算中心以多種異構方式共同發展的AI服務器算力機組為算力底座,不斷提升智能計算能力和速度,滿足人工智能應用場景下大規模、多線并行的計算需求。智算中心圍繞“算力生產、算力聚合、算力調度、算力釋放”四個核心業務功能,為各行業各領域人工智能應用提供穩定的技術支撐,打造可持續發展的算力生態。”
智算中心,如果要充分發揮智算的能量,從整體架構上要分為四層:
-
算力應用層:作為智算中心的最上層,負責接收用戶的計算任務和應用需求。當然為了更好做好算力運營,這一層還需要有算力封裝、算力統計、監控和交易計費、算力并網等管理功能。
-
算力調度層:負責智能資源調度和任務分配。包括算力感知和度量、算力解構、算力編排和分配,算力路由和調度等。
-
算力資源層:這是智算中心的核心,包括多個算力資源中心和計算節點,這些節點可以是具體的物理服務器,也可以是虛擬機部署,還要考慮分布式和分層架構,以實現立體計算的效果。資源層會直接接受來自調度層的任務分配并執行計算任務。算力資源層也需要監控和管理本地算力資源的狀態,負載和性能,并將這些信息實時回饋到調度層。
-
算力網絡通信層:負責智算中心內部和智算中心間的數據傳輸與通信。提供高速可靠的數據傳輸保障。包括互聯互通,云邊互聯,邊邊互聯。數據的安全性和完整性的保障,一般也在這一層。
接下來,我們就會針對上述的分層,分別來展開說明。先談最下面的網絡層,再逐級向上,最后來說應用層。
3. 算力網絡通信層
算力網絡通信層是智算網絡的底座。算力網絡對網絡傳輸提出更為苛刻的要求,所以提出確定性網絡(Deterministic Networking)的概念,也就是說:具有嚴格時間保證和低延遲的網絡通信,以確保任務的及時響應和數據的準確傳輸。
確定性網絡要求網絡中的數據包傳輸要具有可預測性、穩定的傳輸速度,不會受到隨機波動或者擁塞的影響,做到最小化阻塞和抖動性。要達到至少微秒級(Microsecond Level),甚至是納秒級(Nanosecond Level)的硬實時要求。要想達到確定性網絡,硬件上就必須采用高速的交換機、路由器、全光網絡(All-Optical Network)的傳輸設備。同時,還需要在高精度原子鐘的支持下,做到精準的任務調度和協調,并采用硬實時調度算法來避免資源競爭,達到實時性保障。同時在路由算法上,要采用低延遲路由技術,以減少數據包的傳輸時間和網絡中的排隊延遲。
除了時延之外,確定性網絡還要求數據傳輸過程中絕對不能出現丟失。這就需要無損路由(Lossless Routing)技術的運用。在傳統的網絡中,當網絡擁塞或緩沖區溢出時,可能會發生數據包的丟失。而在無損路由中,采用一系列擁塞控制和緩沖管理機制,確保所有的數據包都能夠被成功傳輸,避免數據丟失。
網絡層除了滿足確定性網絡要求外,還需要配合上層的資源調度提供信息保證,這就需要遵守資源感知路由協議(Resource-Aware Routing Protocol)。根據網絡中的資源狀態和拓撲、算力資源的負載、性能指標和能耗等信息,智能地動態選擇最佳的網絡路徑和節點,以實現資源的高效利用和任務的優化調度。
4. 算力資源層
傳統的云計算、和超算中心,由于業務的特殊屬性,更傾向于集中計算。但是智算中心會更加強調立體計算的模式。立體計算將云、邊不同位置的設備橫向和縱向進行協同拉通,實現優勢互補。解決業務體驗不好、算力分布不均、算力利用率低、信息孤島等一系列的問題與挑戰。
邊緣計算(Edge Computing)這個話題,之前我們專門出過一期聊過。詳細參見:《河套IT TALK 82: (原創) 解鎖邊緣的力量:邊緣計算的崛起和未來(萬字長文)》。邊緣計算就是將計算和數據處理功能移動到離數據產生源頭更近的邊緣設備、邊緣節點或邊緣服務器上進行處理。邊緣計算的目標是減少數據的傳輸延遲、提高應用的實時性和響應性,并減輕云計算中心的負載。智算中心也同樣可以分為集中部署節點和分布式的邊緣部署節點。這就會牽扯到什么時候采用集中部署節點的算力來計算,什么時候用邊緣計算的問題。
一般而言,邊緣計算將計算和數據處理推向離數據源頭更近的邊緣,可以在接近數據產生的地方進行實時處理,減少數據傳輸的延遲。這對于需要即時響應的應用非常重要。制造、電力、城市、交通、金融等垂直行業的智能化升級與改造,是邊緣計算在這些行業規模應用的重要驅動因素,將帶來爆發式的增長。例如,物聯網設備產生的傳感器數據、智能城市的實時監測數據、虛擬現實、增強現實應用、在線游戲等。邊緣算力的設備因未來業務發展多樣化的訴求,逐漸向小型化、移動化、低功耗的方向發展。
在某些極端情況下,在沒有持續互聯網連接或有網絡限制的環境下,邊緣計算可以在本地進行計算和數據處理,降低對云端資源的依賴,提供離線環境下的支持。例如,邊緣設備在偏遠地區、海上平臺或工廠車間等環境中的計算需求。而云端算力更適合于處理大規模數據集合、進行復雜的數據分析和機器學習算法訓練。當業務需要根據需求進行彈性擴展和高可靠性部署時,云端算力的虛擬化和自動化特性能夠快速分配和調整計算資源,提供高可用性和可伸縮性。
當然不能簡單的二分法,從安全角度來看,算力集中云端部署會充分發揮數據潛能價值,但是數據容易受到云端的黑客攻擊。而算力邊緣層盡管相對可以保護核心資產的安全與隱私,但是也容易形成數據孤島,同時也更容易遭受來自南向的物理硬件接口的安全攻擊。在智算領域,從負載均衡、資源優化、彈性擴展、靈活性和安全性考慮,往往是邊云協同,邊邊協同的方式來實現的。
在協同計算中,需要先將任務進行拆解,分割為多個子任務,可以根據任務的緊急程度和計算資源的可用性,將推理任務靈活地分配到邊緣設備和云端進行處理。然后再通過上層的編排調度實現部分子任務在邊,部分在云的方式執行。同時,優化模型的大小和復雜度,采用模型剪枝、輕量化等技術,減少推理時延,并針對不同設備和網絡環境進行優化。將復雜的深度學習模型壓縮為適合邊緣設備的小型模型,以減少計算和存儲需求。同時,可以利用分布式計算和任務卸載的方式,將部分計算任務卸載到云端進行處理,減輕邊緣設備的負擔。
在智能協同中,常見的模式是:“云端訓練、邊緣推理”。要通過聯合學習(Federated Learning)等技術,將模型訓練分散到邊緣設備和云端進行,通過模型參數的交換和聚合來實現全局模型的訓練。同時,還可以引入增量學習和遷移學習等技術,利用已有模型的知識和經驗來加速協同訓練精度和提高收斂速度。這種方式也能將邊緣設備上的局部數據進行共享和融合,形成更豐富的數據集進行模型訓練。同時,還可以利用生成對抗網絡(GAN)等技術生成合成數據來擴充樣本集。最終可以解決邊緣計算數據孤島和小樣本問題。
在邊云協同中,不同設備和節點可能具有不同的數據格式和特征表示。可以通過數據轉換和標準化的方法,將異構數據轉換為統一的表示形式,以便于模型的訓練和推理。進而更好應對數據異構問題。
在算力資源層,如何節能也是一個重要的考慮因素。節能通過能源使用效率PUE(Power Usage Effectiveness)來衡量。PUE是將數據中心的總能源消耗除以用于支撐計算設備的能源消耗的值。由于數據中心的冷卻設備、電源轉換損耗和其他輔助設備的能耗,使得PUE值通常大于1.0。PUE的值越低,表示數據中心在提供計算服務時的能源利用效率越高。理想的PUE值是1.0,這意味著所有的能源都被用于計算設備,沒有能源浪費。但隨著可再生能源或能源回收系統的運用,數據中心的PUE可能會成為小于1的情況,這就是負PUE(Negative PUE)或者Net-Zero能耗的概念。負PUE是指數據中心的能源消耗低于用于支撐計算設備的能源消耗,也就是說,數據中心產生的能源超過了用于運行設備的能源需求。Net-Zero能耗,它表示數據中心在一定的時間范圍內的總能源消耗與可再生能源的產生量相等,即數據中心的凈能耗為零。
5. 算力調度層
算力調度層算是智算中心和網絡的調度中樞系統,向下實現算力資源的統一管理、統一編排、智能調度和全局優化,以實現高效的資源利用和任務執行,提升算力網絡效能。
要實現智能調度,先要有算力感知能力。算力調度層先要進行整個智算中心的算力資源進行解構和分類。這可能包括將算力資源劃分為不同類型(例如CPU、GPU、FPGA等),不同規格和性能等級。這樣可以更好地匹配任務需求和資源特性,提高資源利用效率。在建立智算中心時,可以通過手工配置的方式對算力資源進行解構和分類。這包括人工對每個算力資源進行分類、規格化和標記,將其劃分為不同類型、不同規格和性能等級。這種方法需要依靠運維人員對算力資源的了解和判斷,手動指定其所屬的類別和特性。但這還遠遠不夠,在現實運作中,需要借助傳感器、監控系統和數據分析算法來實現。通過收集算力資源的運行數據,如CPU使用率、內存占用、能耗等指標,以及性能測試結果,可以利用機器學習、數據挖掘和模式識別等技術來自動分析和劃分算力資源的類型和特性。在實際應用中,通常會采用一些自動化工具和系統來輔助算力解構的過程,提高效率和準確性。
具體運作過程中,算力調度層需要實時感知和監測算力資源的狀態和可用性。這可以通過監測計算節點的負載、性能指標、能源消耗等來實現。傳感器、監控系統和監測算法可以用于收集和分析這些數據,并提供準確的算力度量。這樣結合任務需求和資源可用性,對算力資源進行編排和分配。這可能涉及到任務調度算法、負載均衡策略、資源分配策略等。通過綜合考慮任務的優先級、資源的可用性和性能指標,算力調度層可以決定如何最優地分配算力資源,以實現任務的高效執行。以上也稱為:彈性伸縮和自動化管理(Elastic Scaling and Automation),根據用戶需求和負載情況動態調整算力資源的規模和配置。彈性伸縮可以根據負載變化自動增加或減少計算資源,以滿足任務需求,并避免資源浪費。自動化管理可以自動監測和調整資源配置、執行任務調度和優化,從而提高系統的自動化程度和效率。
同時也結合前面算力網絡通信層的算力路由上報信息,通過算力路由算法、網絡拓撲優化、數據傳輸調度算法等,優化傳輸路徑、降低通信延遲、提高數據傳輸速率,從而優化算力資源的利用效率。
智能算力調度和動態算力解構是一個不斷試錯和修正的過程。在任務分配過程中,可能會采用一些啟發式算法、機器學習或優化算法來進行決策。這些算法會根據任務的特性、算力資源的性能指標、歷史數據和反饋等信息,進行評估和預測,以確定最優的算力資源類型。然而,由于任務的特性和需求可能存在不確定性和變化,所以選擇的算力資源類型可能不總是完全準確的。因此,智能算力調度和動態算力解構是一個迭代的過程。在實際應用中,可能會根據任務的執行情況和算力資源的反饋信息,對算力資源的選擇和分配進行修正和優化。這可以包括動態調整任務分配策略、實時監控任務的執行情況,以及根據反饋信息對算力資源的選擇進行修正。通過不斷的試錯和修正,智能算力調度和動態算力解構可以逐漸優化算力資源的利用效率和任務執行的性能。這種迭代的過程可以提高智算中心的整體效能,并適應任務需求和算力資源變化的動態性。
另外,智算中心的調度是一定會采用并行計算和分布式計算的方式來提升計算效率的。并行計算是將一個大型計算問題分解為多個子問題,并將這些子問題同時分配給多個計算資源進行獨立計算,最終將它們的結果合并得到最終的計算結果。通過并行計算,可以加快計算速度,提高計算效率,并處理更大規模和復雜度的計算任務。分布式計算是將一個計算任務分發給多個計算節點進行并行計算,這些計算節點可以分布在不同的物理位置上,相互之間通過網絡進行通信和協同工作。分布式計算利用了智算中心中的多個計算資源,使得計算任務可以在多個節點上同時進行,從而提高計算能力和資源利用率。
6. 算力應用層
作為智算中心的最上層,算力應用層直接與用戶和應用程序進行交互,負責接收用戶的計算任務和應用需求,并將其轉化為具體的計算操作。這一層通過算力封裝和算力統計等管理功能,確保任務的準確執行和高效運營。所以應用層也可以叫做運營層。
為了更好地運營,需要做好算力封裝(Compute Packaging),將底層的算力資源進行抽象和封裝,提供統一的接口和規范給上層的應用程序使用。這樣,應用程序可以通過標準化的接口調用和管理算力資源,而無需關注具體的硬件和底層細節,做好隔離。算力封裝可以通過容器化技術(如Docker)或虛擬化技術(如虛擬機)來實現。
有的時候,算力交易還存在算力并網(Compute Federation)的情況,也就是多個智算中心的算力資源進行聯合和整合,形成一個統一的算力網絡。這可以通過跨地域、跨機構的協同合作來實現,以共享和交換算力資源。算力并網可以提高算力資源的利用率和可用性,使得用戶可以更加靈活地訪問和利用分布在不同地方的算力資源。
為了繁榮生態,算力應用層還需要提供應用程序開發和部署(Application Development and Deployment)。以支持用戶開發和部署自己的應用程序。這可能涉及編程框架、軟件開發工具包、API接口等,使得用戶可以方便地構建和部署各種計算任務和應用。此外,應用程序開發和部署也需要與算力封裝和調度層進行協同,以實現應用程序的高效運行和資源利用。
當然,運營一定少不了算力統計與監控(Compute Monitoring)。對算力資源進行實時的監測、度量和統計,以獲取關于算力資源的各種性能指標和使用情況。這可以幫助算力管理者了解算力資源的利用率、負載情況、性能狀況等,從而進行合理的調度和管理。常見的算力統計與監控技術包括指標收集、日志記錄、事件報警、性能分析等。
當然,運營的目的是為了營利,所以就需要算力交易和計費系統(Compute Billing)。基于用戶的計算任務和資源使用情況,對其進行計費和結算。這需要實現計費模型、價格策略、賬單生成等功能,并提供用戶界面和API接口進行交互。交易計費的設計應當考慮公平、透明和可擴展性,以滿足不同用戶和應用場景的需求。如果要使得智算算力交易更為靈活,還可以提供算力交易市場(Compute Marketplace)的功能,允許用戶交易和共享算力資源。這可以促進資源的合理利用和共享經濟的發展,使得資源擁有者可以出租閑置資源,而需求方可以獲得靈活的算力資源。算力交易市場需要提供可信的交易機制、支付結算功能和服務質量保證,以確保交易的安全和可靠。
7. 開放計算
我們前面介紹了,智算中心的解決方案會分四層,每層都會有很多的供應商,包括硬件供應商、軟件供應商或者解決方案集成商。這種復雜的狀況,是沒有辦法由一家供應商解決的,更不要說還存在智算中心協同的情況了。所以要構建一個繁榮的智算中心生態系統,必須通過開放的標準和接口,各方才可以更便捷地整合和擴展自己的產品和服務。
開放計算最先要做到的就是各方要遵循既定的標準,智算中心通常涉及大規模的數據中心建設和管理。因此,可以參考數據中心相關的標準和規范,如TIA-942(數據中心設計和建設標準)、ISO/IEC 27001(信息安全管理體系標準)和ISO/IEC 20000(IT服務管理標準)等。為了實現開放計算,可以參考開放計算的標準和規范,如Open Compute Project(OCP)的硬件設計規范。而互聯互通的通信層面需要遵循網絡通信的標準和規范,如IEEE和ITU的標準。
Open Compute Project(OCP)是當前最重要的開放計算社區之一。社區的成員包括各大科技公司、數據中心運營商、硬件供應商和軟件開發者等。他們共同合作,通過共享硬件設計、制定開放標準和規范,推動數據中心、服務器、存儲和網絡等領域的創新。OCP社區的核心目標是降低數據中心成本、提高能源效率、提升計算性能,并推動可持續發展。社區通過開放的硬件設計和規范,促進各方共享最佳實踐和技術創新,加速行業的進步。除此之外,在云層面和開源層面,也有很多和開放計算相關的社區和項目。比如Kubernetes(容器編排平臺)、OpenStack(開源云計算平臺)等。這些社區和項目在不同的領域推動開放計算的發展,吸引了大量的開發者和組織參與共同創新。
8. 展望未來
由于強勁的增長動力,智算中心,相信未來相當長的一段時間內,都會是科技領域的熱點話題。智算中心的未來發展充滿了潛力和機遇。通過不斷探索和應用新技術,智算中心可以實現更高效、智能和可持續的計算能力,為社會和人類的進步做出更大的貢獻。隨著科技的不斷進步和創新的推動,我們可以期待智算中心將在未來展現出更加令人驚嘆的發展和成就。比如,當下,量子計算和量子網絡方興未艾,如果有可能在智算中心引入量子能力,相信一定會引發新的變革和突破,讓我們拭目以待吧。
-
開源技術
+關注
關注
0文章
389瀏覽量
7914 -
OpenHarmony
+關注
關注
25文章
3661瀏覽量
16159
原文標題:河套IT TALK90:(原創)智能算力新篇章:智算中心構建智能算力的大腦和神經中樞
文章出處:【微信號:開源技術服務中心,微信公眾號:共熵服務中心】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
算力基礎篇:從零開始了解算力
共赴2024鄭州算力大會,開啟智慧新篇章


九聯科技攜手智算云網共繪智算產業新篇章
中科曙光入選2024算力服務產業圖譜及算力服務產品名錄
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
中國算力中心市場持續增長,智能算力規模快速崛起
算力系列基礎篇——算力與計算機性能:解鎖超能力的神秘力量!


算力系列基礎篇——算力101:從零開始了解算力






 工商網監
工商網監
評論