 芯片性能小談—時間并行
芯片性能小談—時間并行
1
性能的評估——帶寬、吞吐量、時延
在討論如何提高性能之前,得先看看如何評估性能。
從直觀上來說,性能好代表著快。那么如何評估”快”呢?首先芯片根據應用場景分為很多不同的種類,通信類的5G,藍牙,wifi;接口類的USB,以太網,HDMI;計算類的通用CPU,GPU,AI等。在不同的場景下其實都能通過一些統一的指標來衡量:帶寬(bandwidth),吞吐量(throughput)和時延(latency)。我們所熟悉的CPU性能跑分,從微觀層面來說,實際上評估的無非也是同一段時間內系統能正確處理多少段標準的代碼,蘊藏有吞吐量的概念在里面。在計算機網絡中,這三者的大致概念如下:
● 帶寬: 信道上單位時間內能傳輸的最大數據量。
****● 吞吐量: 某段時間里,信道上單位時間內的有效傳輸的數據量。
****● 時延: 每一次有效傳輸所需要的時間。
這三個概念既可以作為宏觀的計算機網絡傳輸性能指標,從微觀上來說,也可以作為芯片內部數據計算,傳輸的性能指標。比如AXI總線的數據傳輸,比如內存訪問的數據傳輸,甚至是模塊與模塊間的數據傳輸。
以AXI總線為例,我們都知道這是一種高帶寬,高性能,低時延的總線,其與同為AMBA總線的AHB和APB的對比如下:
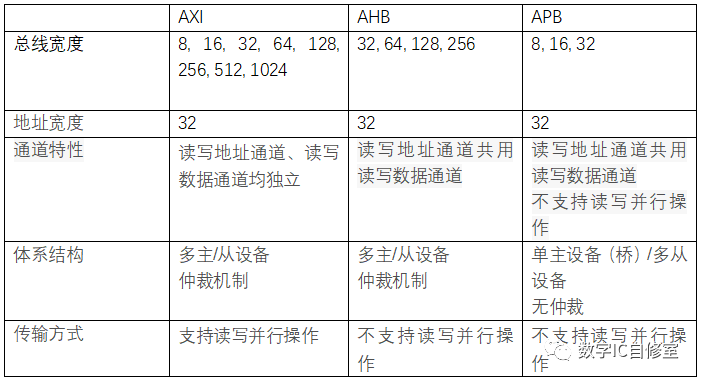
AXI的快,從帶寬,吞吐量以及時延的角度來說,主要得益于以下特性:
● 帶寬:
AXI支持更寬的總線寬度。更寬的總線寬度帶來的好處毋庸置疑,一個周期傳輸的最大數據量更大。形象點說就是公路更寬了。
● 吞吐量:
- 讀寫通道獨立帶來的讀寫并行操作。讀寫通道獨立意味著讀操作和寫操作可以并行。并行的好處自然是同一段時間內可以同時進行的讀和寫更多,完成的也更多,從而增加了一段時間內的有效數據傳輸量,也就是吞吐量。
- 流水/分裂傳輸。這里的流水/分裂傳輸用AXI文檔里的說法叫outstanding。這是一種時間上的并行。在每筆讀/寫操作還未結束的時候就發送下一筆,這樣一來同樣一段時間內并行的讀寫操作更多,傳輸數據更多,增加了吞吐量。
- 猝發傳輸。用于連續地址的讀寫訪問,一次地址發送在slave端可以同時訪問多個連續地址,同一段時間內能訪問更多的地址,傳輸更多的數據,增加了吞吐量。
- 亂序訪問。相比于順序訪問,總線上自由度更大。順序是一種約束,放寬了約束自然可以更肆無忌憚的傳輸數據。假設一種場景,傳輸1訪問地址空間A,三個周期讀回數據。傳輸2訪問地址空間B,一個周期讀回數據。因為順序的約束,先得到數據的傳輸2無法返回數據,必須等到傳輸1完成,這樣效率就很低。有了亂序的支持,后發出的操作如果先完成,可以先返回數據,這樣一來吞吐量自然就更高。
● 時延:
- 地址數據通道獨立。在AHB協議中,因為地址數據通道共用,一次寫操作需要經歷發送地址->發送寫數據這樣的步驟。而在AXI中,寫數據和寫地址可以同時發送,減小了一次寫操作所需要的時延。
- 多主從設備/仲裁機制。與APB只有一個apb master從而導致需要2個cycle才能完成傳輸不同,AXI與AHB都是多主從設備,可以直接點對點完成傳輸,1個cycle就可以完成傳輸,減小了時延。雖然仲裁機制的引入一定程度上又增加了時延,但基于流水分裂傳輸,性能還是可以得到保證。
從上述AXI的特性以及其對性能帶來的增益我們可以明顯看到,性能的提升手段有很多,但這里面蘊藏的主要思想是類似的:提速與并行。道理很簡單,想要更快,那么在一段時間里就需要做更多的事。
2
性能的提升——提速與并行
提速指的是減小時延(latency),即減小每次有效輸出的時間。提速的方式可以來自于計算傳輸自身的算法優化,硬件升級。比如我們在設計的時候經常會做的去除冗余邏輯,本來1拍能做的事沒必要2拍,這就是一種自身算法優化。而更先進的工藝,更小的門電路延遲,也可以減小硬件時延,算作是一種硬件升級。
提速也可以來自于并行。并行又分為空間并行和時間并行。其主要區別在于空間并行需要更多的物理資源,通過更多的資源同時運作來實現并行。而時間并行則是充分調度有限的資源,使其在一段時間內盡可能少的處于閑置等待狀態。
舉一個最簡單的例子就是,你開了一個工廠,原計劃在1個禮拜內完成一個項目交付,老板突然把要求提高了,讓你三天完成,怎么辦呢?可以有以下幾種處理方式。
- 請更多的工人,同樣一堆活丟給更多的人去做,這就是空間并行。
- 減少工人偷懶或者無所事事的時間,充分利用閑暇時間用來干活,同一時刻讓更多的工人處于干活狀態,這就是時間并行。
- 每個工人提升工作效率,做一項工作的時間縮短,這樣相同時間就可以做更多工作,這可以類比于硬件上的算法優化和先進工藝。
在AXI的例子中,更寬的總線寬度,讀寫通道獨立,地址數據獨立屬于空間并行,用更多的總線資源換來速度。流水/分割,猝發,亂序都是屬于時間并行。而多主從的連接方式則幫助到了傳輸本身的提速。
3
時間并行——隱藏latency
這里主要討論一下時間并行。還是基于AXI,從流水/分裂傳輸開始,也就是耳熟能詳的Outstanding。
Outstanding的英文含義是未完成的。在AXI協議中,Outstanding的意思是在一個讀寫操作還沒完成的時候就開始另外一個。
如下圖所示,水平方向表示時間,如果沒有Outstanding,那么總線在同一時刻只會有一個傳輸正在執行。兩個傳輸必須要串行完成。這樣完成兩個讀操作總共需要100ns。

但我們通過觀察可以發現,一個完整的讀操作由Master和Slave共同完成。Master處理地址發出讀請求,Slave處理請求返回數據。如果把Master和Slave看成兩個工人,工人M處理完讀請求操作之后,在等待工人S返回數據的20ns里其實是啥事都不做的偷懶狀態。為了提高效率,讓工人M不偷懶,可以讓他處理完第一筆讀請求操作之后馬上開始準備發出第二個請求。如下圖所示:
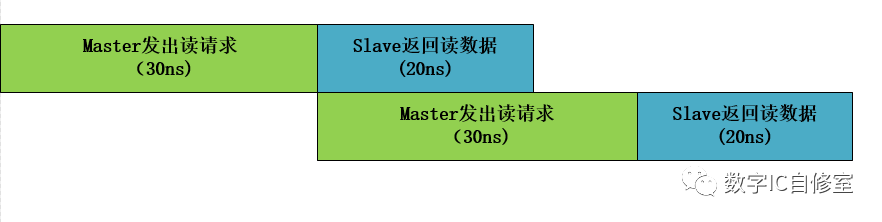
在鞭策了M之后,他發出第一個讀請求之后,馬上馬不停蹄地開始處理第二個讀請求。于此同時,S并行地處理著之前的第一個讀請求。當M完成了第二個讀請求發出時,因為S已經完成了第一個讀請求的數據返回,M可以立馬交付出自己的第二個讀請求,開始第3個讀請求的準備。這樣一來完成兩次讀操作的總時間為80ns,相比第一種情況縮短了20ns。這20ns是S處理第一筆數據的時間,也就是latency,它被“隱藏”在M的第二次操作里。
上述的情況中,有一個前提條件是,S端返回讀數據的latency要小于M發出讀請求處理的latency。這樣才能保證M發出讀請求的時候S能馬上收走。因為在AXI中是握手傳輸,即需要M端valid與S端ready信號同時有效才能進行傳輸。如果S某一次返回讀數據的latency大于M端,M在完成了一次讀請求之后需要等待S端的ready信號,從而還是會有閑置狀態,如下圖所示:
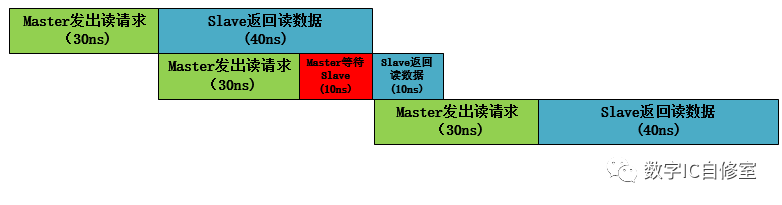
在上圖中,由于在第二次傳輸的時候Master等待了10ns,三次讀操作總共用了140ns。
一個解決此問題的辦法是改變M和S的交互方式。假想M發出請求之后,如果有個地方可以緩存這個請求,M就可以騰出手去做別的事了。這個緩存可以用BUF來做到。如果S特別慢,M發出好幾個請求S都來不及收,就緩存更多,并滿足先發的請求先被處理,則可以使用FIFO進行銜接。如下圖所示:
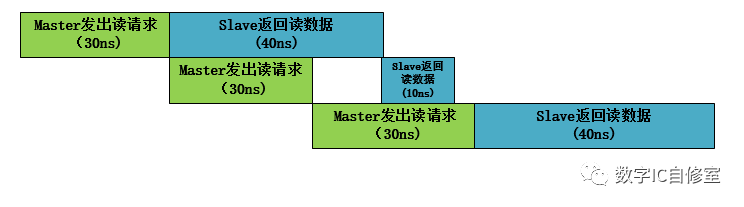
在有了BUF緩存之后,M的第二次操作完成時可以直接進行第三次操作,以此節省了10ns的等待時間,三次讀操作總共只需要130ns。在AXI里,如果有outstanding設置,M與S之間都會有buffer來進行此類緩存,保證同時可以有多個數據傳輸并行。此時的slave ready信號其實是這些緩存FIFO的非滿信號。
從上面的例子中,我們看到了outstanding的魔力,成功地將latency隱藏起來,從而提升了系統的性能。這里的性能提升點為吞吐量,因為單位時間的有效輸出數據增加了。并行之所以重要,是因為在這些例子里的時延latency,即master發出讀請求和slave返回讀數據本身需要的時間,一般來說是比較難降低的。Master發出讀請求前需要處理計算地址,以及slave返回數據時可能有的Memory讀取時間,在設計沒太大毛病的基礎上,要縮短只能靠工藝的升級,內存結構的改變。而要提高系統的吞吐量,只能想辦法將一部分latency隱藏起來。
4
時間并行的瓶頸
以上的一切看起來很好,但如果這樣的并行技術那么牛逼,照理說我們可以使系統無限快才對。當然這樣的技術還是有一定的局限性的。它使用的前提是Master端是效率的瓶頸。如果Slave端總是比Master端更慢,那么實際上系統的吞吐量并不能得到增加,看以下兩個例子:
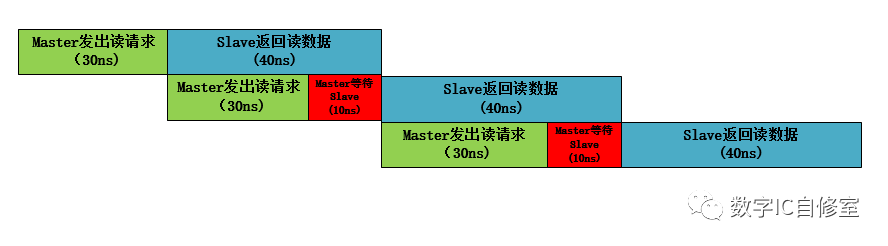
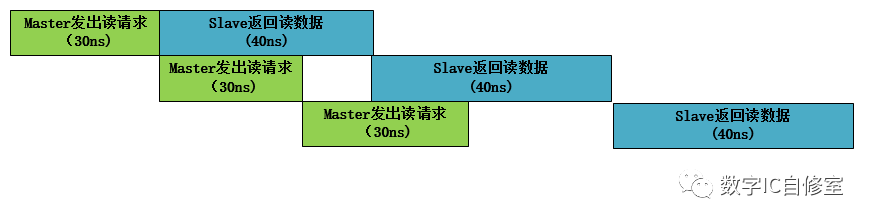
從上面兩圖的對比我們可以看到,雖然Outstanding技術可以幫助Master以最快速度發出三個請求,但這三筆讀數據最后完成的時間和與不使用該技術是完全一樣的。這是因為在此例子中Slave端的處理速度才是瓶頸所在。
那么如何解決這個問題呢?其實這個問題一直是計算機系統效率提升的頭號問題,即著名的”Memory Wall”。可以將上圖中的Master看作是CPU計算單元,Slave看作是系統內存DRAM Memory。因為訪問系統內存的時間本身遠遠大于CPU計算單元本身處理,而 CPU在變得原來越快(多核處理器,superscalar等),DRAM的讀取速度相比之下比較難提高(雖然有DDR,HBM等技術,但還是要寄希望于DRAM本身的提高),這個差距在越拉越大。
目前在計算機體系中使用的是緩存技術,用高速的SRAM作為一個“假”的Memory來進行訪問。只在必要的時候訪問DDR。對應到上圖中實際上是縮短了藍色色塊Slave返回讀數據的時延latency。
5
完美的時間并行——Pipeline
從上面的Outstanding技術中,我們可以發現,Master與Slave端自身的Latency對并行的效果會有很大影響。如果Slave端Latency較大,Outstanding無法很好起到提升吞吐量的效果,并且Master需要很多的BUF來儲存自己的數據。而如果Master的Latency較大,上述的Outstanding是否效率最高呢?
從上圖中我們可以看到,雖然Master端效率達到了最高,工人M一刻不停歇地處理數據,但是Slave在接受處理完Master發出的第一個請求后,有10ns的空閑時間在等待M的第二個讀請求。因為Master是主動方,Slave在收到Master的請求之前沒法做別的事,要避免Slave白等,只能將Master提速。如果Master的latency也是20ns,那么系統中將沒有任何等待,如下圖所示:
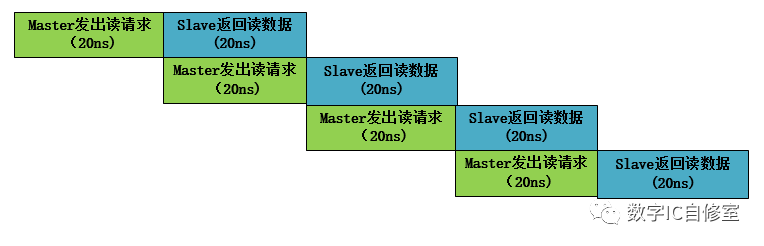
我們知道,如果你遲到了,讓一個人某一次等了一個小時,可能他沒什么感覺,也不會生氣。但如果每天都讓別人等1小時,一個月是30小時,相當于這個人這個月花了一天的時間來等你,他還能沒感覺嗎?
對于系統來說也是一樣的道理。某次傳輸存在等待問題不大,但若每一次傳輸都存在等待,整個系統的效率將大大降低。因此最完美的并行是沒有等待的并行,也就是master發出請求的時候,slave剛剛處理完上一個請求,準備開始下一個。
以上的討論都基于兩個工作者,M和S。但就像大魚吃小魚一個道理一樣,你是一個人的Slave,也會是其他人的Master,生物鏈是一環扣一環的。系統也一樣,有可能是層層往下傳遞的。上述的例子讀操作起始于M,經過S,終止于M。如果加上AXI的網絡(實際情況也不會是直接bypass訪問),Slave1在接收到讀請求之后,只是將其做了預處理,又繼續往下發放到Slave2, Slave3, 直到真正的Memory Slave,如下圖所示:
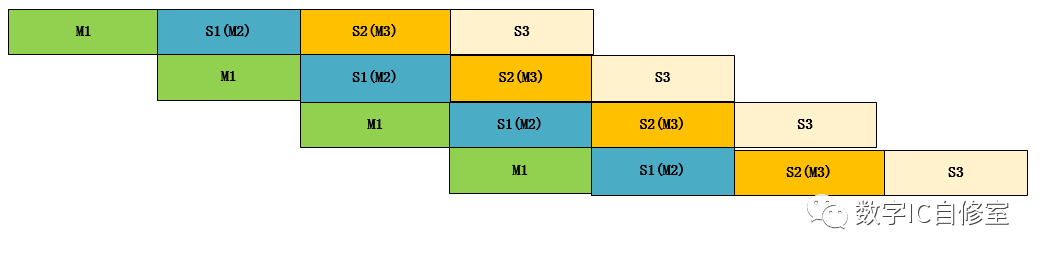
上圖是一種理想狀態,每一對M與S都不存在等待問題,這在現實中很難做到,因為不同的功能塊時延Latency很難做到一致。但還是先來看看這種理想狀態。
因為級數增多了,總的效率提升更為顯著。并且隨著傳遞深度的提升,Latency的隱藏更為顯著。整段時間內最多有4個任務在并行,并且這四個任務的Latency相等,有多達3段latency被完美隱藏!
這么完美的并行技術,無法天然形成,但不利用豈不可惜!我想大家都已經知道了,這就是經典的Pipeline技術。我們會將一些時延較長的電路手動分割成幾個部分,每個部分之間有寄存器鏈接,這樣一來雖然每個部分的時延latency不同,都會在一個時鐘周期的時候同時更新:Master在時鐘上升沿傳遞數據,Slave在時鐘上升沿完成上一數據處理。Pipeline技術大大提高了系統的吞吐量,深度越深,提升越顯著。
理論上來說,任何的電路都可以使用Pipeline技術,但最經典的應用莫過于CPU流水線處理器。下圖是經典的MIPS 5級Pipeline處理器流程:
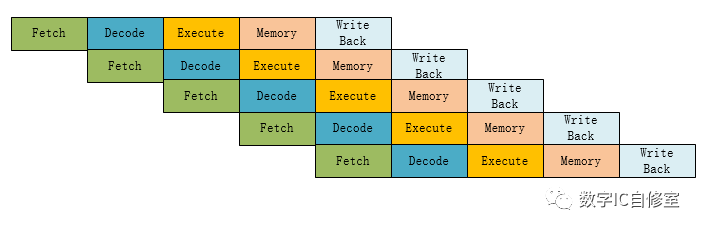
指令的生命周期分別有5個階段: Fetch讀取指令,Decode指令解碼,Execute指令執行,Memory內存訪問,以及Write Back指令回寫寄存器。最后一步結束后一條指令即完成執行。從上圖可以看出,在不考慮數據依賴關系的理想狀態下,有了Pipeline并行技術的加持,在從第5個周期開始,每個周期都可以完成一條指令,大大提高了吞吐量!
6
小結
今天介紹的并行技術其實只是拋磚引玉,也只是設計中并行思想的冰山一角。這種思想可以是outstanding,可以是pipeline,其實還可以是很多很多其他的技術細節。希望大家能應用到平時的設計中,多想想那些地方是存在等待的,那些地方就是效率提升點。
-
HDMI
+關注
關注
32文章
1669瀏覽量
151669 -
以太網
+關注
關注
40文章
5381瀏覽量
171137 -
門電路
+關注
關注
7文章
199瀏覽量
40125 -
AXI總線
+關注
關注
0文章
66瀏覽量
14250 -
FIFO存儲
+關注
關注
0文章
103瀏覽量
5965
發布評論請先 登錄
相關推薦
請問如何使用fx3芯片來對FPGA進行并行配置?
AI芯片談算法不談智能,談實現不談芯片!
并行編程對單芯片多處理性能有什么影響?
可編程并行接口芯片應用
14位并行模數轉換芯片AD9240及其應用
基于Spark的BIRCH算法并行化的設計與實現
并行調度能耗優化算法
基于并行搜索和快速插入的算法
時間數據流的并行檢測算法
怎樣成為一名異構并行計算工程師







 工商網監
工商網監
評論