") PyTorch教程-9.2. 將原始文本轉(zhuǎn)換為序列數(shù)據(jù)
PyTorch教程-9.2. 將原始文本轉(zhuǎn)換為序列數(shù)據(jù)
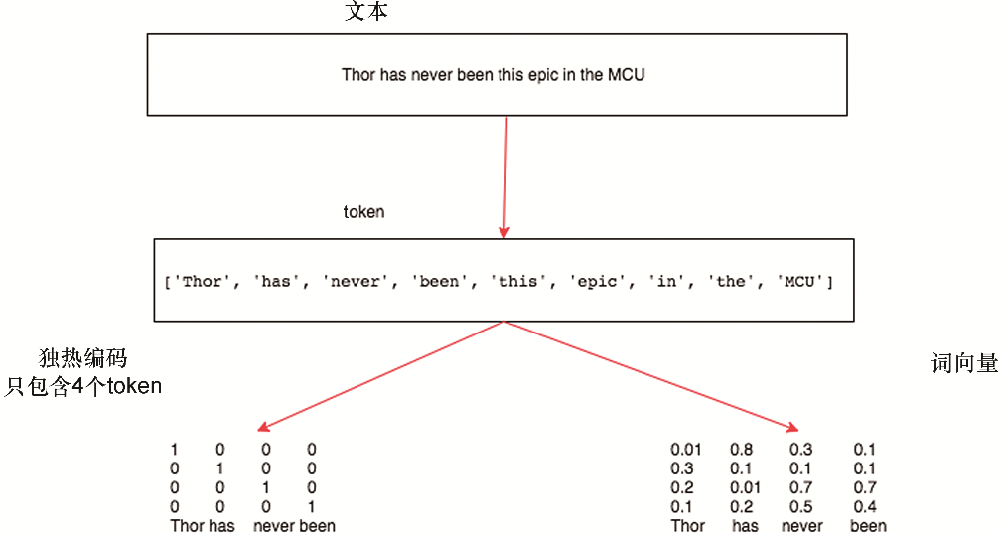
在本書中,我們經(jīng)常會使用表示為單詞、字符或單詞序列的文本數(shù)據(jù)。首先,我們需要一些基本工具來將原始文本轉(zhuǎn)換為適當形式的序列。典型的預處理流水線執(zhí)行以下步驟:
將文本作為字符串加載到內(nèi)存中。
將字符串拆分為標記(例如,單詞或字符)。
構(gòu)建一個詞匯詞典,將每個詞匯元素與一個數(shù)字索引相關聯(lián)。
將文本轉(zhuǎn)換為數(shù)字索引序列。
import collections import random import re import torch from d2l import torch as d2l
import collections import random import re from mxnet import np, npx from d2l import mxnet as d2l npx.set_np()
import collections import random import re import jax from jax import numpy as jnp from d2l import jax as d2l
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
import collections import random import re import tensorflow as tf from d2l import tensorflow as d2l
9.2.1. 讀取數(shù)據(jù)集
在這里,我們將使用 HG Wells 的The Time Machine,這是一本 30000 多字的書。雖然實際應用程序通常會涉及大得多的數(shù)據(jù)集,但這足以演示預處理管道。以下_download方法將原始文本讀入字符串。
class TimeMachine(d2l.DataModule): #@save
"""The Time Machine dataset."""
def _download(self):
fname = d2l.download(d2l.DATA_URL + 'timemachine.txt', self.root,
'090b5e7e70c295757f55df93cb0a180b9691891a')
with open(fname) as f:
return f.read()
data = TimeMachine()
raw_text = data._download()
raw_text[:60]
'時間機器,HG Wells [1898]nnnnnInnnThe Time Tra'
class TimeMachine(d2l.DataModule): #@save
"""The Time Machine dataset."""
def _download(self):
fname = d2l.download(d2l.DATA_URL + 'timemachine.txt', self.root,
'090b5e7e70c295757f55df93cb0a180b9691891a')
with open(fname) as f:
return f.read()
data = TimeMachine()
raw_text = data._download()
raw_text[:60]
Downloading ../data/timemachine.txt from http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt...
'The Time Machine, by H. G. Wells [1898]nnnnnInnnThe Time Tra'
class TimeMachine(d2l.DataModule): #@save
"""The Time Machine dataset."""
def _download(self):
fname = d2l.download(d2l.DATA_URL + 'timemachine.txt', self.root,
'090b5e7e70c295757f55df93cb0a180b9691891a')
with open(fname) as f:
return f.read()
data = TimeMachine()
raw_text = data._download()
raw_text[:60]
'The Time Machine, by H. G. Wells [1898]nnnnnInnnThe Time Tra'
class TimeMachine(d2l.DataModule): #@save
"""The Time Machine dataset."""
def _download(self):
fname = d2l.download(d2l.DATA_URL + 'timemachine.txt', self.root,
'090b5e7e70c295757f55df93cb0a180b9691891a')
with open(fname) as f:
return f.read()
data = TimeMachine()
raw_text = data._download()
raw_text[:60]
'The Time Machine, by H. G. Wells [1898]nnnnnInnnThe Time Tra'
為簡單起見,我們在預處理原始文本時忽略標點符號和大寫字母。
@d2l.add_to_class(TimeMachine) #@save def _preprocess(self, text): return re.sub('[^A-Za-z]+', ' ', text).lower() text = data._preprocess(raw_text) text[:60]
'the time machine by h g wells i the time traveller for so it'
@d2l.add_to_class(TimeMachine) #@save
def _preprocess(self, text):
return re.sub('[^A-Za-z]+', ' ', text).lower()
text = data._preprocess(raw_text)
text[:60]
'the time machine by h g wells i the time traveller for so it'
@d2l.add_to_class(TimeMachine) #@save
def _preprocess(self, text):
return re.sub('[^A-Za-z]+', ' ', text).lower()
text = data._preprocess(raw_text)
text[:60]
'the time machine by h g wells i the time traveller for so it'
@d2l.add_to_class(TimeMachine) #@save
def _preprocess(self, text):
return re.sub('[^A-Za-z]+', ' ', text).lower()
text = data._preprocess(raw_text)
text[:60]
'the time machine by h g wells i the time traveller for so it'
9.2.2. 代幣化
標記是文本的原子(不可分割)單元。每個時間步對應 1 個 token,但究竟什么是 token 是一種設計選擇。例如,我們可以將句子“Baby needs a new pair of shoes”表示為一個包含 7 個單詞的序列,其中所有單詞的集合包含一個很大的詞匯表(通常是數(shù)萬或數(shù)十萬個單詞)。或者我們將同一個句子表示為更長的 30 個字符序列,使用更小的詞匯表(只有 256 個不同的 ASCII 字符)。下面,我們將預處理后的文本標記為一系列字符。
@d2l.add_to_class(TimeMachine) #@save def _tokenize(self, text): return list(text) tokens = data._tokenize(text) ','.join(tokens[:30])
't,h,e, ,t,i,m,e, ,m,a,c,h,i,n,e, ,b,y, ,h, ,g, ,w,e,l,l,s, '
@d2l.add_to_class(TimeMachine) #@save def _tokenize(self, text): return list(text) tokens = data._tokenize(text) ','.join(tokens[:30])
't,h,e, ,t,i,m,e, ,m,a,c,h,i,n,e, ,b,y, ,h, ,g, ,w,e,l,l,s, '
@d2l.add_to_class(TimeMachine) #@save def _tokenize(self, text): return list(text) tokens = data._tokenize(text) ','.join(tokens[:30])
't,h,e, ,t,i,m,e, ,m,a,c,h,i,n,e, ,b,y, ,h, ,g, ,w,e,l,l,s, '
@d2l.add_to_class(TimeMachine) #@save def _tokenize(self, text): return list(text) tokens = data._tokenize(text) ','.join(tokens[:30])
't,h,e, ,t,i,m,e, ,m,a,c,h,i,n,e, ,b,y, ,h, ,g, ,w,e,l,l,s, '
9.2.3. 詞匯
這些標記仍然是字符串。然而,我們模型的輸入最終必須由數(shù)值輸入組成。接下來,我們介紹一個用于構(gòu)建詞匯表的類,即,將每個不同的標記值與唯一索引相關聯(lián)的對象。首先,我們確定訓練語料庫中的唯一標記集。然后我們?yōu)槊總€唯一標記分配一個數(shù)字索引。為方便起見,通常會刪除不常用的詞匯元素。Whenever we encounter a token at training or test time that had not been previously seen or was dropped from the vocabulary, we represent it by a special “” token, signifying that this is an unknown value.
class Vocab: #@save
"""Vocabulary for text."""
def __init__(self, tokens=[], min_freq=0, reserved_tokens=[]):
# Flatten a 2D list if needed
if tokens and isinstance(tokens[0], list):
tokens = [token for line in tokens for token in line]
# Count token frequencies
counter = collections.Counter(tokens)
self.token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# The list of unique tokens
self.idx_to_token = list(sorted(set([''] + reserved_tokens + [
token for token, freq in self.token_freqs if freq >= min_freq])))
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if hasattr(indices, '__len__') and len(indices) > 1:
return [self.idx_to_token[int(index)] for index in indices]
return self.idx_to_token[indices]
@property
def unk(self): # Index for the unknown token
return self.token_to_idx['']
我們現(xiàn)在為我們的數(shù)據(jù)集構(gòu)建一個詞匯表,將字符串序列轉(zhuǎn)換為數(shù)字索引列表。請注意,我們沒有丟失任何信息,并且可以輕松地將我們的數(shù)據(jù)集轉(zhuǎn)換回其原始(字符串)表示形式。
vocab = Vocab(tokens)
indices = vocab[tokens[:10]]
print('indices:', indices)
print('words:', vocab.to_tokens(indices))
indices: [21, 9, 6, 0, 21, 10, 14, 6, 0, 14] words: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm']
vocab = Vocab(tokens)
indices = vocab[tokens[:10]]
print('indices:', indices)
print('words:', vocab.to_tokens(indices))
indices: [21, 9, 6, 0, 21, 10, 14, 6, 0, 14] words: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm']
vocab = Vocab(tokens)
indices = vocab[tokens[:10]]
print('indices:', indices)
print('words:', vocab.to_tokens(indices))
indices: [21, 9, 6, 0, 21, 10, 14, 6, 0, 14] words: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm']
vocab = Vocab(tokens)
indices = vocab[tokens[:10]]
print('indices:', indices)
print('words:', vocab.to_tokens(indices))
indices: [21, 9, 6, 0, 21, 10, 14, 6, 0, 14] words: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm']
9.2.4. 把它們放在一起
使用上述類和方法,我們將所有內(nèi)容打包到build該類的以下方法中TimeMachine,該方法返回 corpus,一個標記索引列表,以及, The Time Machinevocab語料庫的詞匯表 。我們在這里所做的修改是:(i)我們將文本標記為字符,而不是單詞,以簡化后面部分的訓練;(ii)是單個列表,而不是標記列表的列表,因為時間機器數(shù)據(jù)集中的每個文本行不一定是句子或段落。corpus
@d2l.add_to_class(TimeMachine) #@save def build(self, raw_text, vocab=None): tokens = self._tokenize(self._preprocess(raw_text)) if vocab is None: vocab = Vocab(tokens) corpus = [vocab[token] for token in tokens] return corpus, vocab corpus, vocab = data.build(raw_text) len(corpus), len(vocab)
(173428, 28)
@d2l.add_to_class(TimeMachine) #@save def build(self, raw_text, vocab=None): tokens = self._tokenize(self._preprocess(raw_text)) if vocab is None: vocab = Vocab(tokens) corpus = [vocab[token] for token in tokens] return corpus, vocab corpus, vocab = data.build(raw_text) len(corpus), len(vocab)
(173428, 28)
@d2l.add_to_class(TimeMachine) #@save def build(self, raw_text, vocab=None): tokens = self._tokenize(self._preprocess(raw_text)) if vocab is None: vocab = Vocab(tokens) corpus = [vocab[token] for token in tokens] return corpus, vocab corpus, vocab = data.build(raw_text) len(corpus), len(vocab)
(173428, 28)
@d2l.add_to_class(TimeMachine) #@save def build(self, raw_text, vocab=None): tokens = self._tokenize(self._preprocess(raw_text)) if vocab is None: vocab = Vocab(tokens) corpus = [vocab[token] for token in tokens] return corpus, vocab corpus, vocab = data.build(raw_text) len(corpus), len(vocab)
(173428, 28)
9.2.5. 探索性語言統(tǒng)計
使用真實的語料庫和Vocab在單詞上定義的類,我們可以檢查有關語料庫中單詞使用的基本統(tǒng)計數(shù)據(jù)。下面,我們根據(jù)時間機器中使用的單詞構(gòu)建一個詞匯表,并打印出 10 個最常出現(xiàn)的單詞。
words = text.split() vocab = Vocab(words) vocab.token_freqs[:10]
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
words = text.split() vocab = Vocab(words) vocab.token_freqs[:10]
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
words = text.split() vocab = Vocab(words) vocab.token_freqs[:10]
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
words = text.split() vocab = Vocab(words) vocab.token_freqs[:10]
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
請注意,十個最常用的詞并沒有那么具有描述性。你甚至可以想象,如果我們隨機選擇任何一本書,我們可能會看到一個非常相似的列表。諸如“the”和“a”之類的冠詞,“i”和“my”之類的代詞,以及“of”、“to”和“in”之類的介詞經(jīng)常出現(xiàn),因為它們具有共同的句法作用。這些既常見又特別具有描述性的詞通常稱為停用詞,在前幾代基于詞袋表示的文本分類器中,它們最常被過濾掉。然而,它們具有意義,在使用現(xiàn)代基于 RNN 和 Transformer 的神經(jīng)模型時,沒有必要過濾掉它們。如果您進一步查看列表,您會注意到詞頻衰減很快。這 10th最常見的詞小于1/5和最受歡迎一樣普遍。當我們沿著排名下降時,詞頻傾向于遵循冪律分布(特別是 Zipfian)。為了更好地理解,我們繪制了詞頻圖。
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')

freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
在將前幾個詞作為例外處理后,所有剩余的詞在對數(shù)-對數(shù)圖上大致沿著一條直線。Zipf 定律捕捉到了這種現(xiàn)象,該定律指出頻率ni 的ith出現(xiàn)頻率最高的詞是:
(9.2.1)ni∝1iα,
這相當于
(9.2.2)log?ni=?αlog?i+c,
在哪里α是表征分布的指數(shù),并且c是一個常數(shù)。如果我們想通過計算統(tǒng)計數(shù)據(jù)來建模單詞,這應該已經(jīng)讓我們停下來了。畢竟,我們會顯著高估尾部的頻率,也稱為不常見詞。但是其他單詞組合呢,比如兩個連續(xù)的單詞(bigrams)、三個連續(xù)的單詞(trigrams)等等?讓我們看看二元組頻率的行為方式是否與單個單詞(一元組)頻率的行為方式相同。
bigram_tokens = ['--'.join(pair) for pair in zip(words[:-1], words[1:])] bigram_vocab = Vocab(bigram_tokens) bigram_vocab.token_freqs[:10]
[('of--the', 309),
('in--the', 169),
('i--had', 130),
('i--was', 112),
('and--the', 109),
('the--time', 102),
('it--was', 99),
('to--the', 85),
('as--i', 78),
('of--a', 73)]
bigram_tokens = ['--'.join(pair) for pair in zip(words[:-1], words[1:])] bigram_vocab = Vocab(bigram_tokens) bigram_vocab.token_freqs[:10]
[('of--the', 309),
('in--the', 169),
('i--had', 130),
('i--was', 112),
('and--the', 109),
('the--time', 102),
('it--was', 99),
('to--the', 85),
('as--i', 78),
('of--a', 73)]
bigram_tokens = ['--'.join(pair) for pair in zip(words[:-1], words[1:])] bigram_vocab = Vocab(bigram_tokens) bigram_vocab.token_freqs[:10]
[('of--the', 309),
('in--the', 169),
('i--had', 130),
('i--was', 112),
('and--the', 109),
('the--time', 102),
('it--was', 99),
('to--the', 85),
('as--i', 78),
('of--a', 73)]
bigram_tokens = ['--'.join(pair) for pair in zip(words[:-1], words[1:])] bigram_vocab = Vocab(bigram_tokens) bigram_vocab.token_freqs[:10]
[('of--the', 309),
('in--the', 169),
('i--had', 130),
('i--was', 112),
('and--the', 109),
('the--time', 102),
('it--was', 99),
('to--the', 85),
('as--i', 78),
('of--a', 73)]
這里值得注意的一件事。在十個最常見的詞對中,有九個由停用詞組成,只有一個與實際書籍相關——“時間”。此外,讓我們看看三元組頻率是否以相同的方式表現(xiàn)。
trigram_tokens = ['--'.join(triple) for triple in zip( words[:-2], words[1:-1], words[2:])] trigram_vocab = Vocab(trigram_tokens) trigram_vocab.token_freqs[:10]
[('the--time--traveller', 59),
('the--time--machine', 30),
('the--medical--man', 24),
('it--seemed--to', 16),
('it--was--a', 15),
('here--and--there', 15),
('seemed--to--me', 14),
('i--did--not', 14),
('i--saw--the', 13),
('i--began--to', 13)]
trigram_tokens = ['--'.join(triple) for triple in zip( words[:-2], words[1:-1], words[2:])] trigram_vocab = Vocab(trigram_tokens) trigram_vocab.token_freqs[:10]
[('the--time--traveller', 59),
('the--time--machine', 30),
('the--medical--man', 24),
('it--seemed--to', 16),
('it--was--a', 15),
('here--and--there', 15),
('seemed--to--me', 14),
('i--did--not', 14),
('i--saw--the', 13),
('i--began--to', 13)]
trigram_tokens = ['--'.join(triple) for triple in zip( words[:-2], words[1:-1], words[2:])] trigram_vocab = Vocab(trigram_tokens) trigram_vocab.token_freqs[:10]
[('the--time--traveller', 59),
('the--time--machine', 30),
('the--medical--man', 24),
('it--seemed--to', 16),
('it--was--a', 15),
('here--and--there', 15),
('seemed--to--me', 14),
('i--did--not', 14),
('i--saw--the', 13),
('i--began--to', 13)]
trigram_tokens = ['--'.join(triple) for triple in zip( words[:-2], words[1:-1], words[2:])] trigram_vocab = Vocab(trigram_tokens) trigram_vocab.token_freqs[:10]
[('the--time--traveller', 59),
('the--time--machine', 30),
('the--medical--man', 24),
('it--seemed--to', 16),
('it--was--a', 15),
('here--and--there', 15),
('seemed--to--me', 14),
('i--did--not', 14),
('i--saw--the', 13),
('i--began--to', 13)]
最后,讓我們可視化這三個模型中的標記頻率:unigrams、bigrams 和 trigrams。
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])

bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
這個數(shù)字相當令人興奮。首先,除了 unigram 單詞之外,單詞序列似乎也遵循 Zipf 定律,盡管指數(shù)較小α在(9.2.1)中,取決于序列長度。二、數(shù)量不同n-克不是那么大。這給了我們希望,語言中有相當多的結(jié)構(gòu)。三、多n-grams 很少出現(xiàn)。這使得某些方法不適用于語言建模,并激發(fā)了深度學習模型的使用。我們將在下一節(jié)討論這個問題。
9.2.6. 概括
文本是深度學習中最常見的序列數(shù)據(jù)形式之一。構(gòu)成標記的常見選擇是字符、單詞和單詞片段。為了預處理文本,我們通常 (i) 將文本拆分為標記;(ii) 構(gòu)建詞匯表以將標記字符串映射到數(shù)字索引;(iii) 將文本數(shù)據(jù)轉(zhuǎn)換為標記索引,供模型操作。在實踐中,單詞的出現(xiàn)頻率往往遵循齊普夫定律。這不僅適用于單個單詞(unigrams),也適用于 n-克。
9.2.7. 練習
在本節(jié)的實驗中,將文本標記為單詞并改變實例min_freq的參數(shù)值Vocab。定性地描述變化如何min_freq影響最終詞匯量的大小。
估計此語料庫中一元字母、二元字母和三元字母的 Zipfian 分布指數(shù)。
查找一些其他數(shù)據(jù)源(下載標準機器學習數(shù)據(jù)集、選擇另一本公共領域書籍、抓取網(wǎng)站等)。對于每個,在單詞和字符級別對數(shù)據(jù)進行標記化。詞匯量大小與Time Machine語料庫的等效值相比如何min_freq。估計與這些語料庫的一元和二元分布相對應的 Zipfian 分布的指數(shù)。他們?nèi)绾闻c您觀察到的時間機器語料庫的值進行比較?
-
pytorch
+關注
關注
2文章
803瀏覽量
13152
發(fā)布評論請先 登錄
相關推薦
如何將算得的數(shù)據(jù)(10進制)轉(zhuǎn)換為16進制通過串口發(fā)送出?
請問怎樣實現(xiàn)labview將ASCII碼文本轉(zhuǎn)換為中文顯示
如何將原始數(shù)據(jù)從LIS2DS12轉(zhuǎn)換為G為2/4/8/16g范圍?
怎么將原始拜耳轉(zhuǎn)換為RGB輸出
是否有辦法用vee pro將文本文件轉(zhuǎn)換為excel文件?
如何在Python中將語音轉(zhuǎn)換為文本
ABPDLNN100MG2A3壓力傳感器如何將原始數(shù)據(jù)轉(zhuǎn)換為毫巴?
將Pytorch模型轉(zhuǎn)換為DeepViewRT模型時出錯怎么解決?
將ONNX模型轉(zhuǎn)換為中間表示(IR)后,精度下降了怎么解決?
如何將ADC采集的原始數(shù)據(jù)的序列轉(zhuǎn)換成VisualAnalog中Pattern Loader可以接受的I Only文件,文件格式是怎樣的?
如何用百度硬盤搜索將PDF轉(zhuǎn)換為文本文件txt

序列數(shù)據(jù)和文本的深度學習
全面的分子生物學和序列分析工具套件有什么新功能
PyTorch教程9.2之將原始文本轉(zhuǎn)換為序列數(shù)據(jù)

PyTorch教程21.7之序列感知推薦系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論