 將Paxos和Raft統一為一個協議:Abstract-paxos
將Paxos和Raft統一為一個協議:Abstract-paxos
前言
前言
之前寫了一篇 Paxos 的直觀解釋,用簡單的語言描述了 paxos 的工作原理,看過的朋友說是看過的最易懂的 paxos 介紹,同時也問我是否也寫一篇 raft 的。但 raft 介紹文章已經很多很優質了,感覺沒什么可寫的,就一直拖著。
后來想起來,在分布式崗的面試中,會經常被問到 raft 和 paxos 有什么區別, 雖然可能會惹惱面試官,但我會說:沒區別。今天介紹一個把 paxos 和 raft 等統一到一起的分布式一致性算法 abstract-paxos,解釋各種分布式一致性算法從 0 到 1 的推導過程。算是填了 raft 的坑,同時在更抽象的視角看 raft,也可以很容易看出它設計上的不足和幾個優化的方法。
為了清楚的展現分布式一致性協議要解決的問題,我們將從 0 開始,即從 2 個基本需求:技術爆炸和猜疑鏈信息確定和分布式開始。推導出所有的分布式強一致協議的統一形式,然后再把它特例化為 raft 或 paxos。
本文的整個推導過程順著以下過程,從 assumption 開始,最終達到 protocol:
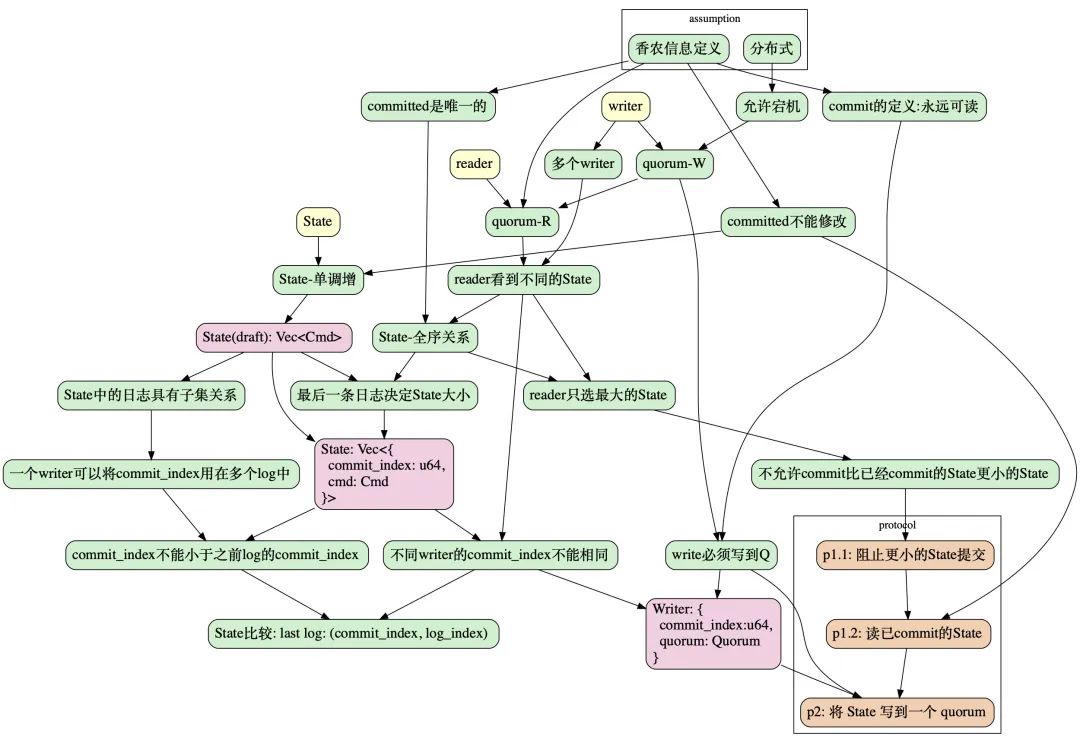
本文結構
本文結構
提出問題
協議推導
定義 commit
定義 系統狀態(State)
協議描述
工程實踐
成員變更
使用 abstract-paxos 描述 paxos
使用 abstract-paxos 描述 raft
問題
問題
從我們要解決的問題出發:實現一個分布式的、強一致的存儲系統。存儲系統是存儲信息的,我們首先給出信息和分布式存儲的定義:
香農信息定義
香農信息理論定義:信息是用來消除隨機不定性的東西。
具體來說,對某個信息的讀操作,每次得到的內容應該都是唯一的,確定的。這個定義將貫穿本文,作為我們設計一致性協議的最根本的公理。
分布式存儲
存儲系統可以看做一個可以根據外部命令(Cmd)改變系統狀態(State)的東西。例如一個 key-value 存儲,set x=1 或 set x=y+1 都可以看做一個 Cmd。
而分布式則表示存儲系統由多個節點(node)組成(一個 node 可以簡單的認為是一個進程),存儲系統的操作者是多個并發的寫入者(write)和讀取者(reader)。
而一個可靠的分布式也意味著它必須允許宕機:它必須能容忍部分節點宕機還能正常工作。
所以它必須有冗余,即:每個節點存儲一個 State 的副本,而我們需要的分布式一致性協議的目的,就是保證對外界觀察者(reader)能夠提供保證香農信息定義的 State 的信息。
系統要提供在 writer 或 reader 只能訪問到部分節點時系統也能工作,這里的部分節點在分布式領域一般定義為一個quorum:
Quorum
Quorum
一個 quorum 定義為一個節點(node)集合。e.g. HashSet。
在這個系統中,分布式的特性要求 writer 只需能聯系到一個 quorum 就可以完成一個信息的寫入,即:實現quorum-write。而 reader 只需要聯系到一個 quorum 就可以確定的讀取到信息,即實現quorum-read。
因為 writer 寫入的信息 reader 必須能讀到,所以任意 2 個 quorum 必須有交集:
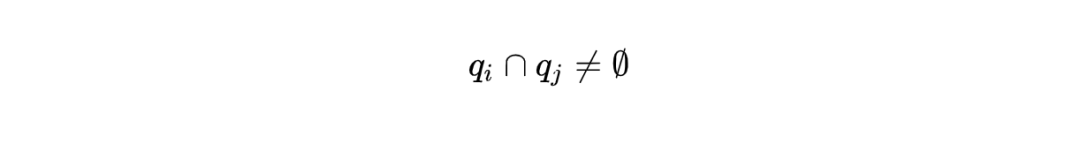
大部分時候, 一個 quorum 都是指 majority,也就是多于半數個 node 的集合。例如【a,b】,【b,c】,【c,a】是集合【a,b,c】的 3 個 quorum。
如果 任何一個 reader 都能通過訪問一個 quorum 來讀到某個數據,那么這條數據就滿足了香農信息定義,我們稱這條數據為 commit 的。
Commit
Commit
根據香農信息定義,如果寫入的數據一定能通過某種方法讀取到,則認為它是 committed。
如果某個數據有時能讀到有時不能,它就不是一個信息。
不確定讀的例子
例子1: 讀到不確定的結果
例如下面 3 個 node N1,N2,N3 的 例子1,
N1 存儲了[x,y],
N3 存儲了 [z],
使用 quorum-read 去讀的時候,有時能得到【x,y】(訪問 N1,N2),有時能得到【z】(訪問 N2,N3)
所以【x,y】和【z】在這個系統中都不是信息,都不是 commit 完成的狀態。

例子2: 總能讀到的結果
而像以下這個 例子2, 一次 quorum-read 不論落到哪 2 個 node 上,都能看到【z】
所以【z】在這個系統中有機會成為一個信息。
這時還不能確定【z】是一個信息,因為這里如果 reader 訪問 N1,N2,還涉及到是選 【x,y】還是選 【z】作為系統當前的狀態的問題,也就是說讀取的結果還不能保證唯一。后面繼續討論。

因此,我們就得到了在一個多副本的存儲系統中 commit 完成的條件:
commit-寫 quorum:以保證任何 reader 都可讀到。
commit-唯一:以保證多個 reader 返回相同的結果。
commit 后不能修改:以保證多次讀返回同樣的結果。
我們先解釋這幾個條件,接著討論如何設計一個 commit 的協議來滿足這幾個條件,從而達到一致性。
commit-寫 quorum
一個數據必須有機會被 reader 見到:即一個數據已經寫到一個quorum中:commit-寫 quorum。
commit-唯一
這里唯一是指,在可見的基礎上,增加一個唯一確定的要求:
例如在上面的例子2 中,如果 reader 一次讀操作訪問到 N1, N2 這 2 個 node,那么它收到的看到的 2 個 State 的副本分別是【x,y】和【z】,這 2 個 State 的副本都是可見的,但作為一個存儲系統,任何一個 reader 都必須選擇同樣的 State 作為當前系統的 State(否則違反香農信息定義的消除不確定性的原則)。
所以我們對讀操作還要求 reader 能有辦法在所有可見的副本中唯一確定的選擇一個 State,作為讀操作的結果。
commit 后不能修改
香農信息定義要求一個 commit 完成的 State 必須永遠可被讀到:即要求 commit 的 State 不能被覆蓋和修改,只能增加。
State 不能被修改有點反直覺,,因為一般的存儲系統,,先存儲了 x=1,還可以修改為 x=2。看起來是允許修改的。
這里可以這樣理解:
經歷了 x=1,再到 x=2 的一個 State (【x=1, x=2】),跟直接到 x=2 的 State(【x=1,】)是不同的。這個不同之處體現在:可能有個時間點,可以從第一個 State 讀出 x=1 的信息,而第二個 State 不行。
常見的 State 定義是:一個 Cmd 為元素的,只允許 append 的 list:Vec.
這也就是一個記錄變更操作(Cmd)的日志(log),或稱為 write-ahead-log(WAL). 而系統的 State 也由 WAL 唯一定義的。在一個典型的 WAL + State Machine 的系統中(例如 leveldb),WAL 決定了系統狀態(State),如這 3 條log:【set x=1, set x=2, set y=3】,而平常人們口中的 State Machine,僅僅是負責最終將整個系統的狀態呈現為一個 application 方便使用的形式,即一般的 HashMap 的形式:【x=2, y=3】。
所以在本文中,WAL 是真實的 State,我們這里說的不能修改,只能追加,就是指 WAL 不能修改,只能追加。本文中我們不討論 State Machine 的實現。
如果把存儲系統的 State 看做是一個集合,那么它必須是一個只增的集合:
State
State
本文的目的僅僅是來統一 paxos 和 raft,不需要太復雜,只需把 State 定義為一個只能追加的操作日志:

log 中的每個 entry 是一個改變系統狀態的命令(Cmd)。
這是 State 的初步設計,為了實現這個一致性協議,后面我們將對 State 增加更多的信息來滿足我們的要求。
根據commit-寫 quorum的要求,最終 State 會寫到一個 quorum 中以完成 commit,我們將這個過程暫時稱作phase-2。它是最后一步,在執行這一步之前,我們需要設計一個協議,讓整個 commit 的過程也遵守:
commit-唯一,
commit 后不能修改
的約束。
首先看如何讓 commit 后的數據唯一,這涉及到 reader 如何從 quorum 中多個 node 返回的不同的 State 副本中選擇一個作為讀操作的最終結果:
reader:找出沒有完成 commit 的 State 副本
reader:找出沒有完成 commit 的 State 副本
根據香農信息定義, 已經 commit 的 State 要求一定能被讀到,但多個 writer 可能會(在互不知曉的情況下)并發的向多個 node 寫入不同的 State。
寫入了不同的 State 指:兩個 State:s?, s?,如果 s? ? s? 和 s? ? s? 都不滿足,那么只有一個是可能被 commit 的。否則就產生了信息的丟失。
而當 reader 在不同的 node 上讀到 2 個不同的 State 時,reader 必須能排除其中一個肯定沒有 commit 的 State,如例子2中描述問題。
即,commit-唯一要求:兩個非包含關系的 State 最多只有一個是可能 commit 狀態的。并要求 2 個 State 可以通過互相對比,來排除掉其中一個肯定不是 commit 的 State,這表示 State 之間存在一個全序關系:即任意 2 個 State 是可以比較大小的,在這個大小關系中:
較大的是可能 commit 的,
較小的一定不是 commit 的。
State 的全序關系
State 的全序關系
State 的全序關系來表示 commit 的有效性,但到目前為止,State 本身是一個操作日志,也就是一個 list,list 之間只有一個偏序關系,即包含關系。互不包含的 2 個 list 無法確定大小關系。
例如, 如果在 2 個節點上分別讀到 2 個 log:【x, y, z】和【x, y, w]】,無法確認哪個是可能 commit 的,哪個是一定沒有 commit 的:

所以 State 必須具備更多的信息讓它能形成全序關系。
并且這個全序關系是可控的:即,對任意一個 State,可以使它變得比任何已知 State 大。否則,writer 在試圖 commit 新的數據到系統里時將無法產生一個足夠大的 State 讓 reader 去選它,導致 writer 無法完成 commit。
給 State 添加用于排序的信息
例如下面 例子3 中,如果每個 node 都為其 State 增加一個序號(在例子中的角標位置),那么 reader 不論聯系到哪 2 個節點,都可以確定選擇序號更大的【y】作為讀取結果,這時就可以認為【y】是一個信息了。

而 commit 后不能修改 的原則要求系統所有的修改,都要基于已 commit 的 State,所以當系統中再次 commit 一個數據后可能是在【y】s 之上追加【z,w】:

為了實現上述邏輯, 一個簡單的實現是讓最后一個 log 節點決定 2 個 State 之間的大小關系。
于是我們可以對 State 的每個 log 節點都需要加入一個偏序關系的屬性 commit_index(本文為了簡化描述, 使用一個整數)來確定 State 的全序關系:

在后面的例子中,我們將 commit_index 寫成每條 log 的下標的形式,例如
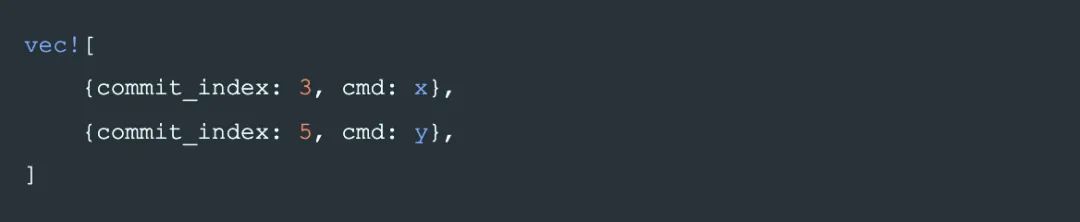
將表示為:

同時定義一個 method 用來取得一個 State 用于比較大小的 commit_index:
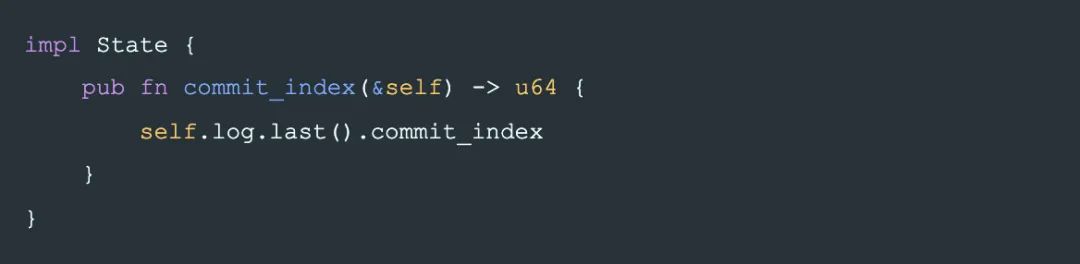
commit_index 的值是由 writer 寫入 State 時決定。即 writer 決定它寫入的 State 的大小。
如果兩個 State 不是包含關系,那么大小關系由 commit_index 決定。writer 通過 quorum-write 寫入一個足夠大的 State,就能保證一定被 reader 選擇,就完成了 commit。
這也暗示了:
非包含關系的 2 個 State 的 commit_index 不能相同。否則 State 之間無法確定全序關系。即,任意 2 個 writer 不允許產生相同的 commit_index。
同一個 writer 產生的 State 一定是包含關系,不需要使用 commit_index 去決定大小:
對于 2 個包含關系的 State:s? ? s?,顯然對于 reader 來說,應該選擇更大的 s?,無需 commit_index 來確定 State 的大小。因此一個 writer 產生的 State,允許多個 log 的 commit_index 相同。并用 log 的長度確定大小關系。
這樣我們就得到了 State 的大小關系的定義:
State-全序定義
兩個 State 的順序關系:通過 commit_index 和 log 長度確定,即比較 2 個 State 的:(s.commit_index(), s.log.len())。
上面提到,commit_index 是一個具有偏序關系的值,不同類型的 commit_index 會將 abstract-paxos 具體化為某種協議或協議族,例如:
如果 commit_index 是一個整數,那就是類似 paxos 的 rnd。
而 raft 中,與 commit_index 對應的概念是【term, Option】,它是一個偏序關系的值,也是它造成了 raft 中選舉容易出現沖突。
關于 abstract-paxos 如何映射為 paxos 或 raft,在本文的最后討論。
另一方面,從 writer 的角度來說:
如果一個 writer 可以生成一個 commit_index 使之大于任何一個已知的 commit_index,那么這時 abstract-paxos 就是一個活鎖的系統:它永遠不會阻塞,但有可能永遠都不會成功提交。例如 paxos 或 raft
如果一個 writer 無法生成任意大的 commit_index,那么它就是一個死鎖的系統,例如 2pc
當然也可以構造 commit_index 使 abstract-paxos 既活鎖又死鎖,那么可以認為它是一個結合了 paxos 和 2pc 的協議。
有了 State 之間的全序關系,然后再讓 writer 保證phase-2寫到 quorum 里的 State 一定是最大的,進而讓 reader 讀取時都可以選擇這個 State,達到香農信息定義要求的信息確定性要求,即commit-唯一的要求,完成 commit:
下面來設計協議,完成這一保證:
協議設計
協議設計
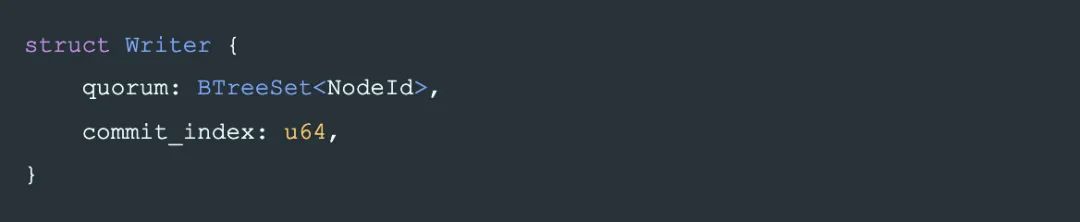
現在我們來設計整個協議,首先,有一個 writer w,w 最終 commit 的操作是在 phase-2 將 State 寫到一個quorum。writer 的數據結構定義為一個它選擇的 quorum,以及它決定使用的 commit_index:
因為 reader 讀取時,只選它看到的最大的 State 而忽略較小的。所以如果一個較大的 State 已經 commit,那么整個系統就不能再允許 commit 一個較小的 State,否則會造成較小的 State 認為自己 commit 完成,但永遠不會被讀到,這就造成了信息丟失。
例如下面 例子5 中描述的場景,如果最終寫入 State 前不做防御,那么是無法完成 commit 的:假設有 2 個 writer w?, w? 同時在寫它們自己的 State 到自己的 quorum:
t1 時間 w? 將 【y?】寫到 N2, N3,
t2 時間 w? 將 【x?,y?】寫到了 N1。
那么當一個 reader 聯系到 N1, N2 進行讀操作時,它會認為【x?,y?】是 commit 完成的, 而真正由 w? commit 的數據就丟失了,違背了香農信息定義。

所以:writer 在 commit 一個 State 前,必須阻止更小的 State 被 commit。這就是phase-1要做的第一件事:
Phase-1.1 阻止更小的 State 被 commit
假設 writer w?要寫入的 State 是 s?,在 w?將 s? 寫到一個 quorum 前,整個系統必須阻止小于 s? 的 State 被 commit。
因為不同的 writer 不會產生同樣的 commit_index。所以整個系統只需阻止更小的 commit_index 的 State 被 commit:
為達到這個目的,在這一步,首先通知 w? quorum 中的每個節點:拒絕所有其他 commit_index 小于 w?。commit_index 的 phase-2 請求。
于是我們基本上可以確定 node 的數據結構,它需要存儲phase-2中真正寫入的 State,以及phase-1.1中要拒絕的 commit_index:

在后面的例子中,我們將用一個數字前綴表示 node 中的 commit_index,例如:

將表示為:

一個直接的推論是, 一個 node 如果記錄了一個 commit_index , 就不能接受更小的 commit_index , 否則意味著它的防御失效了: Node.commit_index 單調增。
如果 writer 的phase-1.1請求沒有被 quorum 中全部成員認可,那么它無法安全的進行phase-2,這時只能終止。
最后我們整理下phase-1.1的流程:

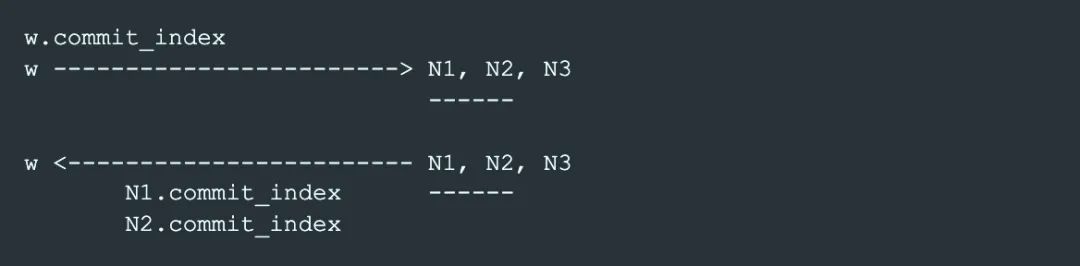
每個 node 在 P1Reply 中返回自己之前保存的 commit_index,writer 拿到 reply 后跟自己的commit_index 對比,如果 w.commit_index >= P1Reply.commit_index,表示 phase-1.1 成功。
完成phase-1.1后,可以保證沒有更小的 State 可以被 commit 了。
然后,為了滿足 commit 后不能修改 的原則,還要求 s? 必須包含所有已提交的,commit_index 小于 s?.commit_index() 的所有 State:
Phase-1.2 讀已完成 commit 的 State
因為 commit 的條件之一是將 State 寫入一個 quorum,所以 w? 詢問 w?.quorum,就一定能看到小于 w?.commit_index 的,已 commit 的其他 State。這時 writer 是一個 reader 的角色(如果遇到大于 w?.commit_index 的 State,則當前 writer 是可能無法完成提交的,應終止)。
且讀過某個 node 之后,就不允許這個 node 再接受來自其他 writer 的,小于 w?.commit_index 的 phase-2 的寫入。以避免讀后又有新的 State 被 commit,這樣就無法保證 w? 寫入的 State 能包含所有已 commit 的 State。
w? 在不同的節點上會讀到不同的 State,根據 State 的全序的定義,只有最大的 State 才可能是已 commit 的(也可能不是, 但更小的一定不是),所以 w? 只要選最大的 State 就能保證它包含了所有已 commit 的 State。
在最大 State 的基礎上,增加 w? 自己要寫的內容。最后進行 phase-2 完成 commit 。
phase-1.1 跟 phase-1.2 一般在實現上會合并成一個 RPC,即 phase-1。
Phase-1
Phase-1: Data

Phase-1: Req

Phase-1: Reply

Phase-1: Handler
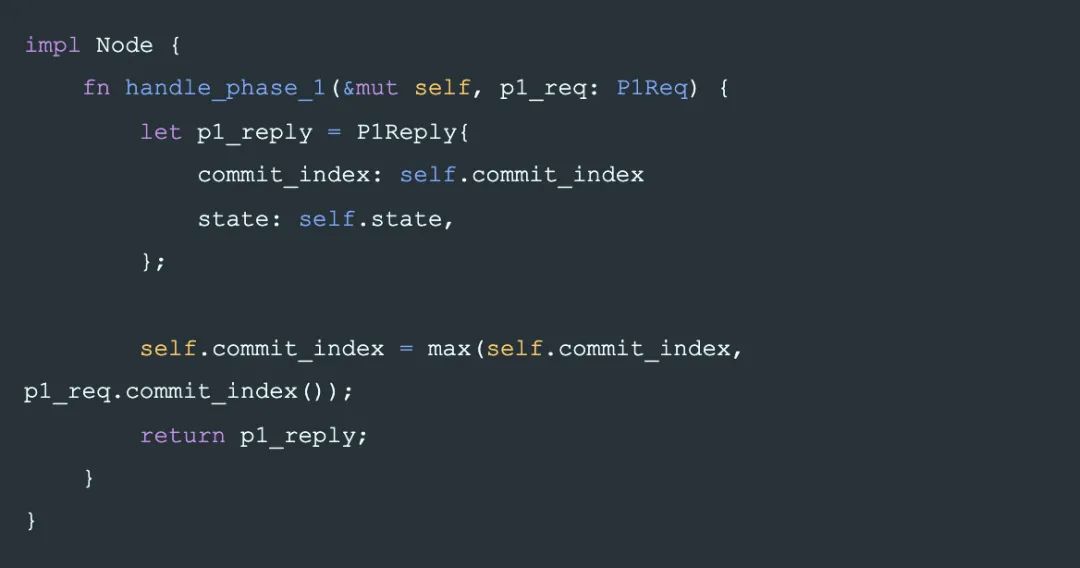
Phase-2
最后,保證了 s? 當前最大,和 commit 后不能修改這兩個條件后,第 2 階段,writer 就可以安全的寫入一個 s? 完成 commit。
如果 phase-2 完成了,則表示 commit 一定成功了,任何一個 reader 都能讀到唯一確定的 State s?(除非有更大的 State 被寫入了)。
反之,如果有其他 writer 通過 phase-1 阻止了 w?.commit_index 的寫入,那么 w? 的 phase-2 就可能失敗,這時就退出 commit 過程并終止。
這里有一個學習分布式系統時經常提出的問題:
Q:
因為在 phase-1 中 w 已經阻止了所有小于 w.commit_index 的 State 的提交,phase-2 是否可以寫入一個小于 w.commit_index 的 State?
A:
不可以,phase-2 寫入的 State 的commit_index() 跟 w.commit_index 相等時才能保證安全,簡單分析下:
顯然要寫的 s?.commit_index() 不能大于 w?.commit_index,因為 phase-1.1 沒有保護大于 w?.commit_index 的 State 的寫入。
雖然在 phase-1 階段,系統已經阻止了所有小于 s?.commit_index() 的其他 State 的 phase-2 寫入,如果 w? 寫的 State 的 s_1.commit_index() 小于w.commit_index,那么系統中可能存在另一個稍大一點的 State (但沒有 commit,導致 reader 不認為 s? 是 commit 的。
例如:
一個 writer w? 在 t1 時間完成了 phase-1,在 t2 時間 phase-2 只寫入了 N1;
然后另一個 writer w? 在 t3 時間完成了 phase-1,phase-2 只寫入了一個較小的 commit_index=4 的 State。
那么某個 reader 如果通過訪問 N1,N2 讀取數據,會認為 N1 上的【x?】是 commit 的,破壞了 香農信息定義。

所以必須滿足:s?.commit_index() == w?.commit_index
這時,只要將 State 寫入到 w?.quorum,就可以認為提交。
對應每個 node 的行為是:在每個收到 phase-2 請求的節點上,如果 node 上沒有記錄拒絕 commit_index 以下的 phase-2 請求,就可以接受這筆寫入。
一個推論:一個節點如果接受了 commit_index 的寫入,那么同時它應該拒絕小于 commit_index 的寫入了。因為較小的 State 一定不是 commit 的,如果接受,會造成信息丟失。
Phase-2: data

和 phase-1 類似,一個 node 返回它自己的 commit_index 來表示它是否接受了 writer 的 phase-2 請求。
在 P2Req 中,如果 state 是完整的,commit_index 總是與 state.commit_index() 一樣,可以去掉;這里保留是因為之后將會討論到的分段傳輸:每個請求只傳輸 State 的一部分,這時就需要額外的 P2Req.commit_index。
Phase-2: Req

Phase-2: Reply

Phase-2: Handler
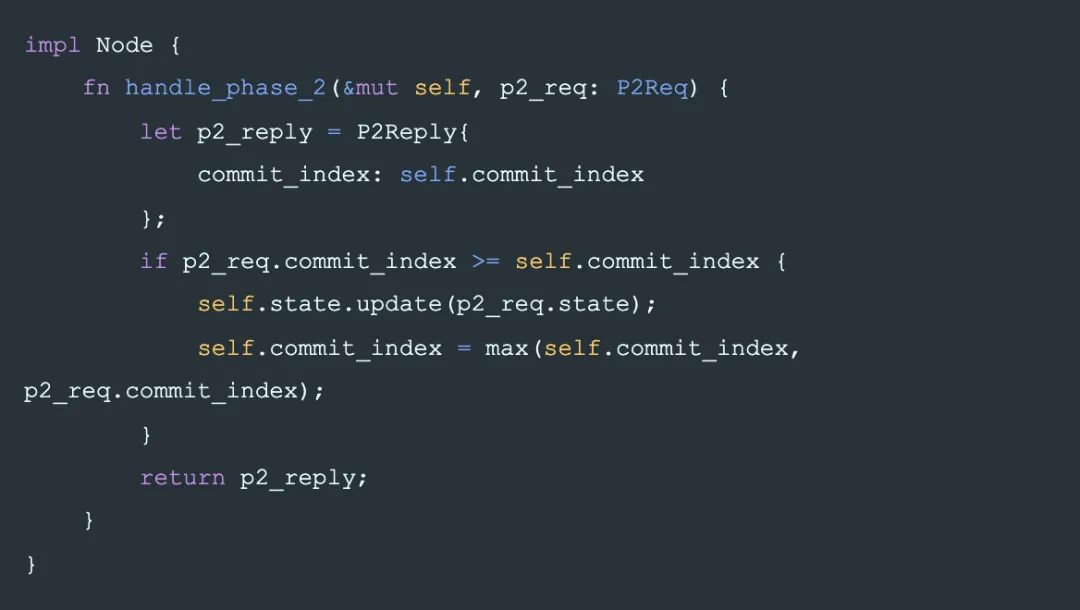
也就是說 phase-2 不止可能修改 Node.state,同時也會修改 Node.commit_index。
這里也是一個學習分布式容易產生誤解的地方,例如很多人曾經以為的一個 paxos 的bug: paxos-bug。
這里也很容易看出為何在 raft 中必須當前 term 復制到 quorum 才認為是 commit 了。
可重復的 phase-2
要保證寫入的數據是 commit 的,只需保證寫入一個 quorum 的 State 是最大的即可。所以 writer 可以不斷追加新的日志,不停的重復phase-2。
Writer 協議描述
Writer 協議描述
最后將整個協議組裝起來的是 writer 的邏輯,如前所講,它需要先在一個 quorum 上完成 phase-1 來阻止更小的 State 被 commit,然后在 quorum 上完成 phase-2 完成一條日志的提交。
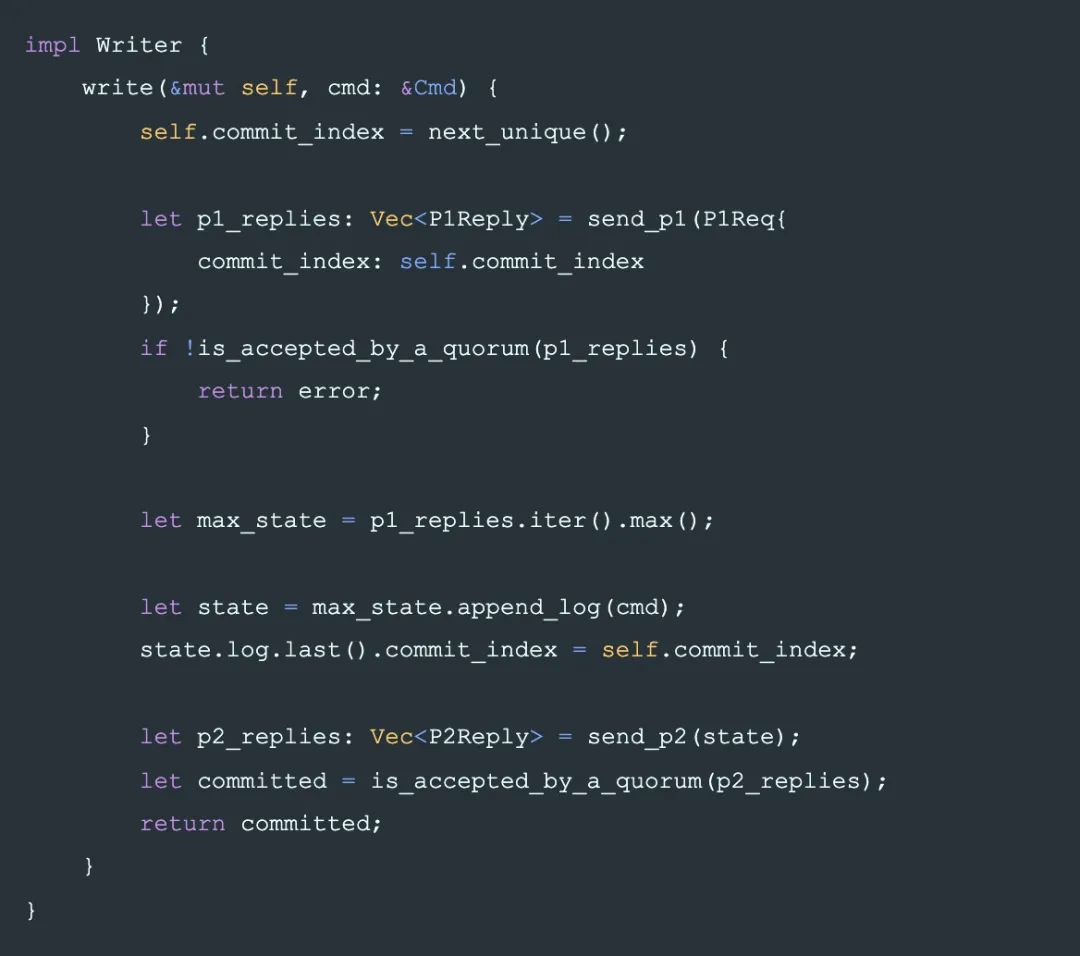
工程實現
工程實現
Phase-2: 增量復制
這個算法的正確性 還需考慮工程上的方便,
到目前為止,算法中對 State 的寫都假設是原子的。但在工程實現上, State 是一個很大的數據結構,很多條 log
所以在phase-2傳輸 State 的過程中,我們還需要一個正確的分段寫的機制:
原則還是保證香農信息定義,即:commit 的數據不丟失。
State 不能留空洞:有空洞的 State 跟沒空洞的 State 不同,不能通過最后一條日志來確定其所在的 State 大小。
writer 在phase-1完成后可以保證一定包含所有已經 commit 的 State。
所以在一個接受phase-2的 node 上,它 Node.state 中任何跟 Writer.State 不同的部分都可以刪除,因為不一致的部分一定沒有被 commit。
以下是 phase-2 過程中刪除 N3 上不一致數據的過程:

t1 時刻,writer W 聯系到 N1,N2 完成 phase-1,讀到最大的State【x?,z?】,添加自己的日志到最大 State 上:【x?,z?,w?】,這時系統中沒有任何一個 node 的 State 是 commit 完成狀態的,一個 reader 可能選擇【x?,z?】作為讀取結果(訪問N1,N2),可能選擇【x?,y?】作為讀取結果(訪問N2,N3)。
但這時一個 State 的子集:【x?】是commit完成的狀態。
t2 時刻,W 向 N3 復制了一段 State:【x?】,它是 N3 本地日志的子集,不做變化。
這時 reader 還是可能讀到不同的結果,同樣【x?】是 commit 完成的狀態。
t3 時刻,W 向 N3 復制了另一段 State z?,它跟 N3 本地 State 沖突,于是 N3 放棄本地的一段與 writer 不一致的 Statey?,將本地 State 更新為:【x?,z?】
這時【x?,z?】是 commit 完成狀態。
t4 時刻,W繼續復制 w_6 到 N3,這是【x?,z?,w_4】是 commit 完成狀態。
Snapshot 復制
snapshot 復制跟 State 分段復制沒有本質區別,將 State 中的 log 從 0 到某一范圍以壓縮后的形式傳輸的到其他 node。
成員變更
成員變更
為支持成員變更,我們先加入下面這幾個行為來支持成員變更操作:
State 中某些日志(config日志)表示集群中的成員配置。
State 中最后一個成員配置(config)日志出現就開始生效。
config 日志與普通的日志寫入沒有區別。
config 定義一個集群的 node 有哪些,以及定義了哪些 node 集合是一個 quorum。
例如一個普通的3成員集群的 config 【{a,b,c}】,它定義的 quorum 有

再如一個由 2 個配置組成的 joint config【{a,b,c}, {x,y,z}】。它定義的 quorum 集合是【a,b,c】的 quorum 集合跟【x,y,】的 guorum 集合的笛卡爾積:

然后,我們對成員變更增加約束,讓成員變更的過程同樣保證香農信息定的要求:
成員變更約束-1
首先,顯然有2 個相鄰 config 的 quorum 必須有交集。否則新配置啟用后就立即會產生腦裂。即:
在后面的討論中我們將滿足以上約束的 2 個 config 的關系表示為:c? ~ c???。
例如:假設 State 中某條日志定義了一個 joint config:【{a,b,c}, {x,y,z}】那么,
下一個合法的 config 可以是:
uniform config【{a,b,c}】,
或另一個 joint config 【{x,y,z}, {o,p,q}】。
但不能是【{a,x,p}】,因為它的一個 quorum【a,x}】與 上一個 config 的 quorum【{b,c}, {y,z}】沒有交集。
成員變更Lemma-1
對 2 個 config c? ~ c?,以及 2 個 State S? 和 S? 如果 S? 和 S? 互相不是子集關系,S? 在 c? 上 commit 跟 S? 在 c? 上 commit 不能同時發生。
成員變更約束-2
因為 2 個不同 writer 提出(propose)的 config 不一定 有交集,所以為了滿足 commit-唯一 的條件,包含新 config 的日志要提交到一個新,舊配置的 joint config 上。即, c??? 必須在【c?, c???】上 commit. c??? 之后的 State, 只需使用 c??? 進行 commit。
但是,當 writer 中斷,另一個 writer 看到 c??? 時,它不知道 c??? 處于變更中間,也就是說新的 writer 不知道現在的 commit 應該使用【c?, c???】,它只使用【c???】。
所以對 config 日志向 joint config 的 commit 分為兩步:
先在舊配置上拒絕更小的 State 的提交,再 propose 新配置。根據成員變更Lemma-1,即:至少將一個與 w.commit_index 相同的 State commit 到 c? 上。
再 propose c???,從日志 c??? 之后的日志開始,都只需 commit 到 c??? 上。
最后總結:
成員變更的約束條件
上一個 config 在當前 commit_index 上提交后才允許 propose 下一個配置。
下一個配置必須跟最后一個已提交的配置有交集。
成員變更舉例
raft 只支持以下的成員變更方式
c1 → c1c2 → c2 → c2c3 → c3 …
其中 c1c2 指 c1 跟 c2 的 joint config,例如:
c? :【a, b, c】;
c?c?:【{a, b, c},{x, y, z}】。
abstract-paxos 可以支持更靈活的變更:
c1 → c1c2c3 → c3c4 → c4
或回退到上一個 config:
c1c2c3 → c1
合法變更狀態轉換圖示
下面的圖示中簡單列出了至多 2 個配置的 joint config 跟 uniform config 之間可轉換的關系:
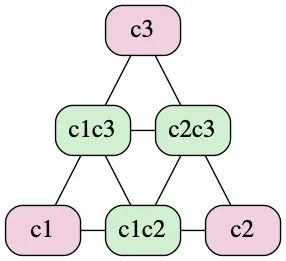
Variants
Variants
以上為 abastract-paxos 的算法描述部分。接下來我們將看它是如何通過增加一些限制條件,absract-paxos 將其變成 classic-paxos 或 raft 的。
秒變 Paxos
限制 State 中的日志只能有一條,那么它就變成 paxos。
不支持成員變更。
其中概念對應關系為:
| abstract-paxos | classic-paxos |
|---|---|
| writer | proposer |
| node | acceptor |
| Writer.commit_index | rnd/ballot |
| State.commit_index() | vrnd/vbal |
秒變 Raft
Raft 為了簡化實現(而不是證明),有一些刻意的閹割:
commit_index 在 raft 里是 一個 偏序關系 的 tuple,包括:
term
和是否投票給了某個 Candidate:
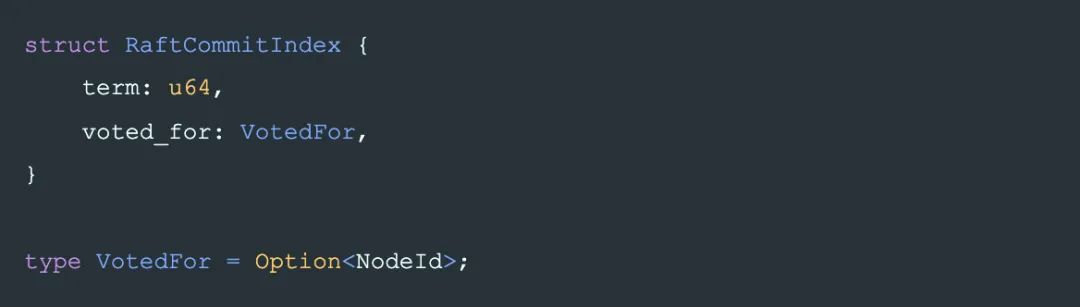
其中 VotedFor 的大小關系(即覆蓋關系:大的可以覆蓋小的)定義是:
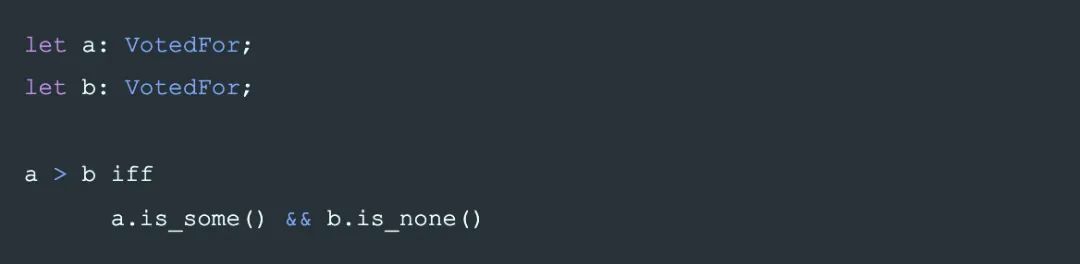
即,VotedFor 只能從 None 變化到 Some,不能修改。或者說,Some(A)和 Some(B)沒有大小關系,這限制了 raft 選主時的成功幾率.。導致了更多的選主失敗沖突。
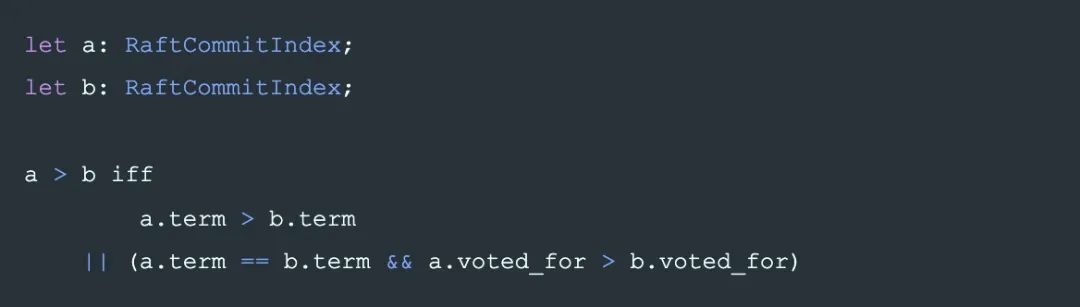
commit_index 在每條日志中的存儲也做了簡化,先看直接嵌入后的結構如下:

raft 中,因為 VotedFor 的特殊的偏序關系的設計,日志中 Term 相同則 voted_for 一定相同,所以最終日志里并不需要記錄 voted_for,也能用來唯一標識日志,State,及用于比較 State 的大小。最終記錄為:

這樣的確讓 raft 少記錄一個字段, 但使得其含義變得更加隱晦,工程上也引入了一些問題, xp 并不欣賞這樣的作法。
但不否認 raft 的設計在出現時是一個非常漂亮的抽象,主要在于它對 multi-paxos 沒有明確定義的問題,即多條日志之間的關系到底應該是怎樣的,給出了一個確定的答案。
概念對應關系:
| abstract-Paxos | raft |
|---|---|
| writer at phase-1 | Candidate |
| writer at phase-2 | Leader |
| node | node |
| Writer.commit_index | (Term,VotedFor) |
| State.commit_index() | Term |
成員變更方面,raft 的 joint 成員變更算法將條件限制為只允許 uniform 和 joint 交替的變更:c0 -> c0c1 -> c1 -> c1c2 -> c2 ....
不難看出,raft 的 單步變更算法也容易看出是本文的成員變更算法的一個特例。
Raft 的優化
abstract-paxos 通過推導的方式,得出的一致性算法可以說是最抽象最通用的。不像 raft 那樣先給出設計再進行證明,現在從上向下看 raft 的設計,就很容易看出 raft 丟棄了哪些東西和給自己設置了哪些限制,也就是 raft 可能的優化的點:
一個 term 允許選出多個 leader:將 commit_index 改為字典序,允許一個 term 中先后選出多個 leader。
提前 commit:raft 中 commit 的標準是復制本 term 的一條日志到 quorum。這樣在新 leader 剛剛選出后可能會延后 commit 的確認,如果有較多的較小 term 的日志需要復制的話。因此一個可以較快 commit 的做法是復制一段 State 時(raft 的 log),也帶上 writer 的 commit_index 信息(即 raft leader 的 term)到每個 node,同時,對 State 的比較(即raft 的 log 的比較)改為比較【writer.commit_index, last_log_commit_index, log.len()】,在 raft 中,對應的是比較【leader_term, last_log_term, log.len()】。
成員變更允許更靈活的變化:例如 c0c1 -> c1c2.
其中 1,3 已經在 openraft 中實現(朋友說它是披著raft皮的paxos/:-))。
Reference
Reference
可靠分布式系統-paxos的直觀解釋 : https://blog.openacid.com/algo/paxos/
abstract-paxos : https://github.com/openacid/abstract-paxos
(Not a) bug in Paxos : https://github.com/drmingdrmer/consensus-bugs#trap-the-bug-in-paxos-made-simple
leveldb : https://github.com/google/leveldb
openraft : https://github.com/datafuselabs/openraft
Two phase commit : https://en.wikipedia.org/wiki/Two-phase_commit_protocol
偏序關系 : https://zh.wikipedia.org/wiki/偏序關系
字典序 : https://zh.wikipedia.org/wiki/字典序
作者介紹:張炎潑(xp)Databend 分布式研發負責人
-
算法
+關注
關注
23文章
4601瀏覽量
92677 -
存儲系統
+關注
關注
2文章
405瀏覽量
40842 -
分布式
+關注
關注
1文章
880瀏覽量
74472 -
abstract
+關注
關注
0文章
4瀏覽量
1663
原文標題:將Paxos和Raft統一為一個協議:Abstract-paxos
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
解決分布式系統“幽靈復現”問題的四大方案
超干的干貨來了!一文了解HTTP協議

傳谷歌將推新設計語言 統一Android界面
2017雙11技術揭秘—X-DB支撐雙11進入分布式數據庫時代
一個協議轉換器需要一個主控制器,但是不知道怎么去選擇?請教大家
串口協議、485協議、MODBUS協議,這三個協議都是怎么定義的?誰能通俗的說下?他們之間有沒有關聯和異同
如何接一個協議為SDI-12的數字型傳感器到Arduino的2560上?
將nodemcu與rc522和rdm6300一起使用,選擇哪個協議?
區塊鏈項目中共識算法的分類,及存在的問題分析
八個協議仿真實驗的詳細資料匯總免費下載





 工商網監
工商網監
評論