 從雙目標定到立體匹配:Python實踐指南
從雙目標定到立體匹配:Python實踐指南
立體匹配是計算機視覺中的一個重要領域,旨在將從不同角度拍攝的圖像匹配起來,以創建類似人類視覺的3D效果。實現立體匹配的過程需要涉及許多步驟,包括雙目標定、立體校正、視差計算等。在這篇文章中,將介紹如何使用Python實現立體匹配的基本步驟和技巧。
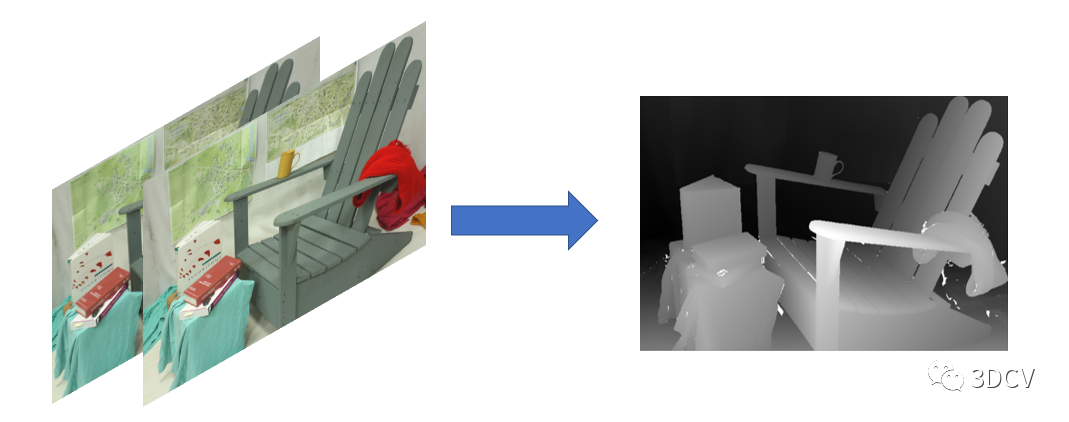
下面的代碼實現了從相機標定到立體匹配的完整流程,下面將分別介紹各個函數的參數和輸出。
標定
首先,該程序需要用到以下庫:
numpy
cv2(OpenCV)
os
在程序開頭,需要定義一些變量來存儲標定圖片的路徑、棋盤格參數、角點坐標等等。具體介紹如下:
path_left="./data/left/"
path_right="./data/right/"
path_left和path_right是左右相機標定圖片文件夾的路徑。
CHESSBOARD_SIZE=(8,11)
CHESSBOARD_SQUARE_SIZE=15#mm
CHESSBOARD_SIZE是棋盤格內部角點的行列數,CHESSBOARD_SQUARE_SIZE是棋盤格內部每個小正方形的大小(單位為毫米)。
objp=np.zeros((CHESSBOARD_SIZE[0]*CHESSBOARD_SIZE[1],3),np.float32)
objp[:,:2]=np.mgrid[0:CHESSBOARD_SIZE[0],0:CHESSBOARD_SIZE[1]].T.reshape(-1,2)*CHESSBOARD_SQUARE_SIZE
objp是物理坐標系下每個角點的三維坐標,即棋盤格的位置。該變量在后續的相機標定以及立體匹配中都會被用到。
criteria=(cv2.TERM_CRITERIA_EPS+cv2.TERM_CRITERIA_MAX_ITER,30,0.001)
criteria是角點檢測的終止準則,一般都使用這個默認值。
img_list_left=sorted(os.listdir(path_left))
img_list_right=sorted(os.listdir(path_right))
img_list_left和img_list_right分別是左、右圖像的文件名列表,使用os.listdir()函數獲取。
obj_points=[]
img_points_left=[]
img_points_right=[]
obj_points、img_points_left和img_points_right分別是存儲每個標定圖片對應的物理坐標系下的角點坐標、左相機的像素坐標和右相機的像素坐標。這些變量同樣在后續的相機標定和立體匹配中用到。
接下來,程序讀取標定圖片并檢測角點。對于每幅圖片,程序執行以下操作:
img_l=cv2.imread(path_left+img_list_left[i])
img_r=cv2.imread(path_right+img_list_right[i])
gray_l=cv2.cvtColor(img_l,cv2.COLOR_BGR2GRAY)
gray_r=cv2.cvtColor(img_r,cv2.COLOR_BGR2GRAY)
首先讀取左右圖像,然后將它們轉換為灰度圖像。
ret_l,corners_l=cv2.findChessboardCorners(gray_l,CHESSBOARD_SIZE,None)
ret_r,corners_r=cv2.findChessboardCorners(gray_r,CHESSBOARD_SIZE,None)
通過OpenCV的cv2.findChessboardCorners()函數檢測左右圖像上的棋盤格角點。這個函數的參數包括:
image:需要檢測角點的灰度圖像。patternSize:內部角點的行列數,即(CHESSBOARD_SIZE[1]-1, CHESSBOARD_SIZE[0]-1)。corners:用于存儲檢測到的角點坐標的數組。如果檢測失敗,則該參數為空(None)。flags:檢測時使用的可選標志。這個函數的返回值包括:
ret:一個布爾值,用于指示檢測是否成功。如果檢測成功,則為True,否則為False。corners:用于存儲檢測到的角點坐標的數組。接下來是亞像素級別的角點檢測。
cv2.cornerSubPix(gray_l,corners_l,(11,11),(-1,-1),criteria)
cv2.cornerSubPix(gray_r,corners_r,(11,11),(-1,-1),criteria)
這里使用了OpenCV的cv2.cornerSubPix()函數來進行亞像素級別的角點檢測。這個函數的參數包括:
image:輸入的灰度圖像。
corners:用于存儲檢測到的角點坐標的數組。
winSize:每次迭代中搜索窗口的大小,即每個像素周圍的搜索范圍大小。通常為11x11。
zeroZone:死區大小,表示怎樣的對稱性(如果有的話)不考慮。通常為(-1,-1)。
criteria:定義迭代停止的誤差范圍、迭代次數等標準,和以上的criteria一樣。
img_points_left.append(corners_l)
img_points_right.append(corners_r)
如果檢測到了左右圖像上的角點,則將這些角點的坐標存儲到img_points_left和img_points_right中。
cv2.drawChessboardCorners(img_l,CHESSBOARD_SIZE,corners_l,ret_l)
cv2.imshow("ChessboardCorners-Left",cv2.resize(img_l,(img_l.shape[1]//2,img_l.shape[0]//2)))
cv2.waitKey(50)
cv2.drawChessboardCorners(img_r,CHESSBOARD_SIZE,corners_r,ret_r)
cv2.imshow("ChessboardCorners-Right",cv2.resize(img_r,(img_r.shape[1]//2,img_r.shape[0]//2)))
cv2.waitKey(50)
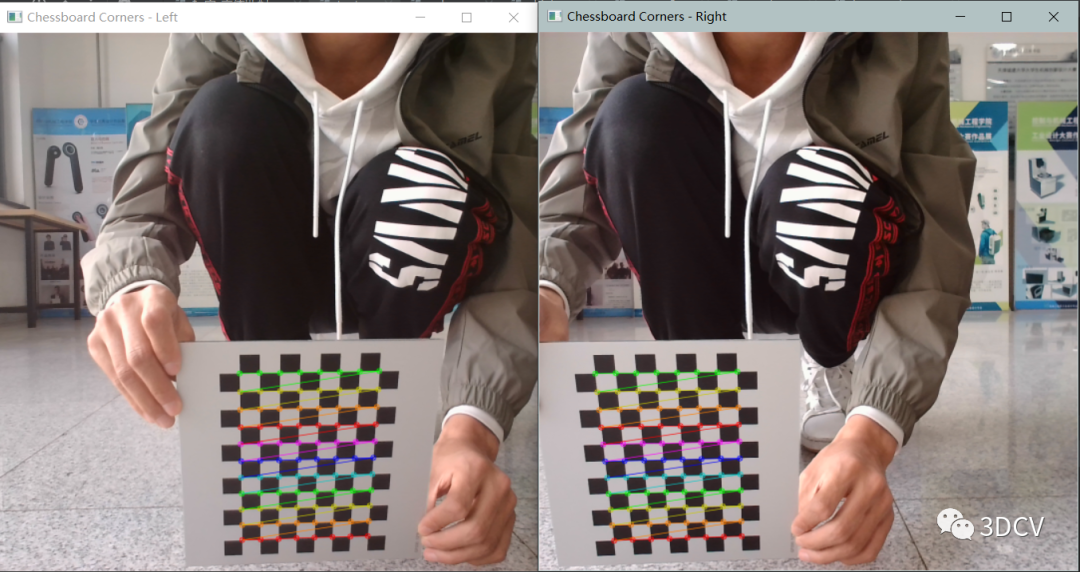 在圖片上標出檢測到的角點,并在窗口中顯示。這里使用了cv2.drawChessboardCorners()函數,該函數的參數包括:
在圖片上標出檢測到的角點,并在窗口中顯示。這里使用了cv2.drawChessboardCorners()函數,該函數的參數包括:
img:需要標定角點的圖像。patternSize:內部角點的行列數,即(CHESSBOARD_SIZE[1]-1, CHESSBOARD_SIZE[0]-1)。
corners:存儲檢測到的角點坐標的數組。patternfound:檢測到角點的標記,即ret。
程序接下來對雙目攝像機進行標定。
ret_l,mtx_l,dist_l,rvecs_l,tvecs_l=cv2.calibrateCamera(obj_points,img_points_left,gray_l.shape[::-1],None,None)
ret_r,mtx_r,dist_r,rvecs_r,tvecs_r=cv2.calibrateCamera(obj_points,img_points_right,gray_r.shape[::-1],None,None)
flags=0
flags|=cv2.CALIB_FIX_INTRINSIC
criteria=(cv2.TERM_CRITERIA_EPS+cv2.TERM_CRITERIA_MAX_ITER,30,0.001)
ret,M1,d1,M2,d2,R,T,E,F=cv2.stereoCalibrate(
obj_points,img_points_left,img_points_right,
mtx_l,dist_l,mtx_r,dist_r,
gray_l.shape[::-1],criteria=criteria,flags=flags)
這段代碼首先對左右相機進行單獨標定:
ret_l,mtx_l,dist_l,rvecs_l,tvecs_l=cv2.calibrateCamera(obj_points,img_points_left,gray_l.shape[::-1],None,None)
ret_r,mtx_r,dist_r,rvecs_r,tvecs_r=cv2.calibrateCamera(obj_points,img_points_right,gray_r.shape[::-1],None,None)
這里使用了OpenCV的cv2.calibrateCamera()函數對左右相機進行標定。這個函數的參數包括:
objectPoints:每幅標定圖片對應的物理坐標系下的角點坐標。
imagePoints:每幅標定圖片上檢測到的像素坐標。
imageSize:標定圖片的尺寸。
cameraMatrix:用于存儲標定結果的內參數矩陣。
distCoeffs:用于存儲標定結果的畸變系數。
rvecs:每幅標定圖片的外參數矩陣中的旋轉向量。
tvecs:每幅標定圖片的外參數矩陣中的平移向量。
這個函數的返回值包括:
ret:一個標志位,表示標定是否成功。
cameraMatrix:用于存儲標定結果的內參數矩陣。
distCoeffs:用于存儲標定結果的畸變系數。
rvecs:每幅標定圖片的外參數矩陣中的旋轉向量。
tvecs:每幅標定圖片的外參數矩陣中的平移向量。
然后對雙目攝像機進行標定:
flags=0
flags|=cv2.CALIB_FIX_INTRINSIC
criteria=(cv2.TERM_CRITERIA_EPS+cv2.TERM_CRITERIA_MAX_ITER,30,0.001)
ret,M1,d1,M2,d2,R,T,E,F=cv2.stereoCalibrate(
obj_points,img_points_left,img_points_right,
mtx_l,dist_l,mtx_r,dist_r,
gray_l.shape[::-1],criteria=criteria,flags=flags)
這里使用了OpenCV的cv2.stereoCalibrate()函數進行雙目攝像機標定。這個函數的參數包括:
objectPoints:每幅標定圖片對應的物理坐標系下的角點坐標。
imagePoints1:每幅標定圖片的左相機上檢測到的像素坐標。
imagePoints2:每幅標定圖片的右相機上檢測到的像素坐標。
cameraMatrix1:左相機的內參數矩陣。
distCoeffs1:左相機的畸變系數。
cameraMatrix2:右相機的內參數矩陣。
distCoeffs2:右相機的畸變系數。
imageSize:標定圖片的尺寸。
criteria:定義迭代停止的誤差范圍、迭代次數等標準。
flags:標定的可選標志。
這個函數的返回值包括:
ret:一個標志,表示標定是否成功。
cameraMatrix1:左相機的內參數矩陣。
distCoeffs1:左相機的畸變系數。
cameraMatrix2:右相機的內參數矩陣。
distCoeffs2:右相機的畸變系數。
R:旋轉矩陣。
T:平移向量。
E:本質矩陣。
F:基礎矩陣。
立體匹配
通過圖像標定得到的參數進行立體匹配的整個流程,如下:
首先,我們需要讀取左右兩張圖像:
img_left=cv2.imread("./left.png")
img_right=cv2.imread("./right.png")
其中,"./left.png" 和 "./right.png" 是放置左右圖像的路徑。這兩幅圖像是未經校正和矯正的圖像。
接下來,通過圖像標定得到相機的參數,根據得到的參數,將圖像進行去畸變:
img_left_undistort=cv2.undistort(img_left,M1,d1)
img_right_undistort=cv2.undistort(img_right,M2,d2)
在上述代碼中,M1、M2、d1、d2 是從雙目相機標定中獲得的參數。去畸變后的圖像 img_left_undistort 和 img_right_undistort 可供之后的操作使用。
然后,進行極線校正,以實現左右圖像在幾何上的一致性:
R1,R2,P1,P2,Q,roi1,roi2=cv2.stereoRectify(M1,d1,M2,d2,(width,height),R,T,alpha=1)
map1x,map1y=cv2.initUndistortRectifyMap(M1,d1,R1,P1,(width,height),cv2.CV_32FC1)
map2x,map2y=cv2.initUndistortRectifyMap(M2,d2,R2,P2,(width,height),cv2.CV_32FC1)
img_left_rectified=cv2.remap(img_left_undistort,map1x,map1y,cv2.INTER_LINEAR)
img_right_rectified=cv2.remap(img_right_undistort,map2x,map2y,cv2.INTER_LINEAR)
其中,R、T 是雙目相機標定得到的旋轉和平移矩陣, (width, height)是左右圖像的尺寸。R1、R2 是左右圖像的旋轉矩陣,P1、P2 是左右圖像的投影矩陣,Q 是視差轉換矩陣,roi1、roi2 是矯正后的圖像中可以使用的區域。
然后,將左右圖像拼接在一起以方便觀察:
img_stereo=cv2.hconcat([img_left_rectified,img_right_rectified])

接下來,需要計算視差圖:
minDisparity=0
numDisparities=256
blockSize=9
P1=1200
P2=4800
disp12MaxDiff=10
preFilterCap=63
uniquenessRatio=5
speckleWindowSize=100
speckleRange=32
sgbm=cv2.StereoSGBM_create(minDisparity=minDisparity,numDisparities=numDisparities,blockSize=blockSize,
P1=P1,P2=P2,disp12MaxDiff=disp12MaxDiff,preFilterCap=preFilterCap,
uniquenessRatio=uniquenessRatio,speckleWindowSize=speckleWindowSize,
speckleRange=speckleRange,mode=cv2.STEREO_SGBM_MODE_SGBM_3WAY)
disparity=sgbm.compute(img_left_rectified,img_right_rectified)
上面的代碼塊定義了使用的視差算法的參數,并使用了 SGBM(Semi Global Block Matching)算法計算了原始的視差圖。注意,由于使用的是16位的 SGBM 輸出,因此需要將它除以16。 接下來,可以對視差圖進行 WLS 濾波,減少視差空洞:
接下來,可以對視差圖進行 WLS 濾波,減少視差空洞:
#定義WLS濾波參數
lambda_val=4000
sigma_val=1.5
#運行WLS濾波
wls_filter=cv2.ximgproc.createDisparityWLSFilterGeneric(False)
wls_filter.setLambda(lambda_val)
wls_filter.setSigmaColor(sigma_val)
filtered_disp=wls_filter.filter(disparity,img_left_rectified,None,img_right_rectified)
filtered_disp_nor=cv2.normalize(filtered_disp,filtered_disp,alpha=0,beta=255,norm_type=cv2.NORM_MINMAX,dtype=cv2.CV_8U)
上述代碼塊中,WLS 濾波為視差圖降噪,并進行平滑處理。這里使用了 cv2.ximgproc.createDisparityWLSFilterGeneric 函數,創建一個生成 WLS 濾波器的對象 wls_filter,然后設置了濾波參數 lambda_val 和 sigma_val。filtered_disp 是經過濾波后的視差圖。filtered_disp_nor 是經過歸一化處理后的、用于顯示的視差圖。
最后,可以在窗口中顯示原始視差圖、預處理后的 WLS 濾波器的視差圖:
cv2.imshow("disparity",cv2.resize(disparity_nor,(disparity_nor.shape[1]//2,disparity_nor.shape[0]//2)))
cv2.imshow("filtered_disparity",cv2.resize(filtered_disp_nor,(filtered_disp_nor.shape[1]//2,filtered_disp_nor.shape[0]//2)))
cv2.waitKey()
cv2.destroyAllWindows()

-
3D
+關注
關注
9文章
2862瀏覽量
107324 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927 -
python
+關注
關注
56文章
4782瀏覽量
84451
原文標題:從雙目標定到立體匹配:Python實踐指南
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
雙目立體視覺原理大揭秘(一)
雙目立體視覺原理大揭秘(二)
維視雙目產品在高校科研應用中的實例及優點分析
雙目視覺立體匹配算法研究
基于顏色調整的立體匹配改進算法

基于HALCON的雙目是相機立體視覺系統標定
雙目立體計算機視覺的立體匹配研究綜述

一種基于PatchMatch的半全局雙目立體匹配算法

融合邊緣特征的立體匹配算法Edge-Gray
雙目標定是什么?為什么要進行雙目標定?
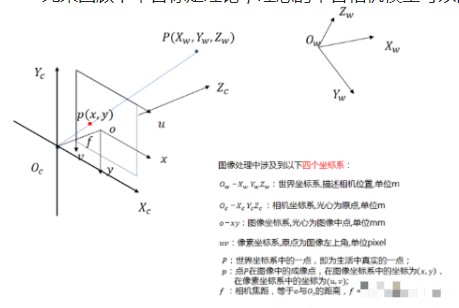
相機之間為什么要進行雙目標定呢?
雙目立體匹配的四個步驟






 工商網監
工商網監
評論